pytorch lstm gru rnn 得到每个state输出的操作
默认只返回最后一个state,所以一次输入一个step的input
# coding=UTF-8
import torch
import torch.autograd as autograd # torch中自动计算梯度模块
import torch.nn as nn # 神经网络模块
torch.manual_seed(1)
# lstm单元输入和输出维度都是3
lstm = nn.LSTM(input_size=3, hidden_size=3)
# 生成一个长度为5,每一个元素为1*3的序列作为输入,这里的数字3对应于上句中第一个3
inputs = [autograd.Variable(torch.randn((1, 3)))
for _ in range(5)]
# 设置隐藏层维度,初始化隐藏层的数据
hidden = (autograd.Variable(torch.randn(1, 1, 3)),
autograd.Variable(torch.randn((1, 1, 3))))
for i in inputs:
out, hidden = lstm(i.view(1, 1, -1), hidden)
print(out.size())
print(hidden[0].size())
print("--------")
print("-----------------------------------------------")
# 下面是一次输入多个step的样子
inputs_stack = torch.stack(inputs)
out,hidden = lstm(inputs_stack,hidden)
print(out.size())
print(hidden[0].size())
print结果:
(1L, 1L, 3L)
(1L, 1L, 3L)
--------
(1L, 1L, 3L)
(1L, 1L, 3L)
--------
(1L, 1L, 3L)
(1L, 1L, 3L)
--------
(1L, 1L, 3L)
(1L, 1L, 3L)
--------
(1L, 1L, 3L)
(1L, 1L, 3L)
--------
----------------------------------------------
(5L, 1L, 3L)
(1L, 1L, 3L)
可见LSTM的定义都是不用变的,根据input的step数目,一次输入多少step,就一次输出多少output,但只输出最后一个state
补充:pytorch中实现循环神经网络的基本单元RNN、LSTM、GRU的输入、输出、参数详细理解
前言:这篇文章是对已经较为深入理解了RNN、LSTM、GRU的数学原理以及运算过程的人而言的,如果不理解它的基本思想和过程,可能理解起来不是很简单。
一、先从一个实例看起
这是官网上面的一个例子,本次以LSTM作为例子而言,实际上,GRU、LSTM、RNN的运算过程是很类似的。
import torch import torch.nn as nn lstm = nn.LSTM(10, 20, 2) # 序列长度seq_len=5, batch_size=3, 数据向量维数=10 input = torch.randn(5, 3, 10) # 初始化的隐藏元和记忆元,通常它们的维度是一样的 # 2个LSTM层,batch_size=3,隐藏元维度20 h0 = torch.randn(2, 3, 20) c0 = torch.randn(2, 3, 20) # 这里有2层lstm,output是最后一层lstm的每个词向量对应隐藏层的输出,其与层数无关,只与序列长度相关 # hn,cn是所有层最后一个隐藏元和记忆元的输出 output, (hn, cn) = lstm(input, (h0, c0)) print(output.size(),hn.size(),cn.size()) # 分别是: # torch.Size([5, 3, 20]) # torch.Size([2, 3, 20]) # torch.Size([2, 3, 20]))
后面我会详细解释上面的运算过程,我们先看一下LSTM的定义,它是一个类
二、LSTM类的定义
class LSTM(RNNBase):
'''参数Args:
input_size: 输入数据的特征维度,比如我对时间序列建模,特征为1,我对一个句子建模,每一个单词的嵌入向量为10,则它为10
hidden_size: 即循环神经网络中隐藏节点的个数,这个是自己定义的,多少都可以,后面会详说
num_layers: 堆叠的LSTM的层数,默认是一层,也可以自己定义 Default: 1
bias: LSTM层是否使用偏置矩阵 偏置权值为 `b_ih` and `b_hh`.
Default: ``True``(默认是使用的)
batch_first: 如果设置 ``True``, then the input and output tensors are provided
as (batch, seq, feature). Default: ``False``,(seq,batch,features)
dropout: 是否使用dropout机制,默认是0,表示不使用dropout,如果提供一个非0的数字,则表示在每一个LSTM层之后默认使用dropout,但是最后一个层的LSTM层不使用dropout。
bidirectional: 是否是双向RNN,默认是否,If ``True``, becomes a bidirectional LSTM. Default: ``False``
#---------------------------------------------------------------------------------------
类的构造函数的输入为Inputs: input, (h_0, c_0)
- **input** of shape `(seq_len, batch, input_size)`: tensor containing the features of the input sequence.
- **h_0** of shape `(num_layers * num_directions, batch, hidden_size)`: tensor
containing the initial hidden state for each element in the batch.
If the LSTM is bidirectional, num_directions should be 2, else it should be 1.
- **c_0** of shape `(num_layers * num_directions, batch, hidden_size)`: tensor
containing the initial cell state for each element in the batch.
If `(h_0, c_0)` is not provided, both **h_0** and **c_0** default to zero.
#----------------------------------------------------------------------------------
输出是什么:Outputs: output, (h_n, c_n)
- **output** of shape `(seq_len, batch, num_directions * hidden_size)`: tensor
containing the output features `(h_t)` from the last layer of the LSTM,
for each `t`. If a :class:`torch.nn.utils.rnn.PackedSequence` has been
given as the input, the output will also be a packed sequence.
For the unpacked case, the directions can be separated
using ``output.view(seq_len, batch, num_directions, hidden_size)``,
with forward and backward being direction `0` and `1` respectively.
Similarly, the directions can be separated in the packed case.
- **h_n** of shape `(num_layers * num_directions, batch, hidden_size)`: tensor
containing the hidden state for `t = seq_len`.
Like *output*, the layers can be separated using
``h_n.view(num_layers, num_directions, batch, hidden_size)`` and similarly for *c_n*.
- **c_n** of shape `(num_layers * num_directions, batch, hidden_size)`: tensor
containing the cell state for `t = seq_len`.
#------------------------------------------------------------------------------------------
类的属性有Attributes:
weight_ih_l[k] : the learnable input-hidden weights of the :math:`\text{k}^{th}` layer
`(W_ii|W_if|W_ig|W_io)`, of shape `(4*hidden_size, input_size)` for `k = 0`.
Otherwise, the shape is `(4*hidden_size, num_directions * hidden_size)`
weight_hh_l[k] : the learnable hidden-hidden weights of the :math:`\text{k}^{th}` layer
`(W_hi|W_hf|W_hg|W_ho)`, of shape `(4*hidden_size, hidden_size)`
bias_ih_l[k] : the learnable input-hidden bias of the :math:`\text{k}^{th}` layer
`(b_ii|b_if|b_ig|b_io)`, of shape `(4*hidden_size)`
bias_hh_l[k] : the learnable hidden-hidden bias of the :math:`\text{k}^{th}` layer
`(b_hi|b_hf|b_hg|b_ho)`, of shape `(4*hidden_size)`
'''
上面的参数有点多,我就不一个一个翻译了,其实很好理解,每一个都比较清晰。
三、 必需参数的深入理解
1、RNN、GRU、LSTM的构造函数的三个必须参数理解——第一步:构造循环层对象
在创建循环层的时候,第一步是构造循环层,如下操作:
lstm = nn.LSTM(10, 20, 2)
构造函数的参数列表为如下:
class LSTM(RNNBase):
'''参数Args:
input_size:
hidden_size:
num_layers:
bias:
batch_first:
dropout:
bidirectional:
'''
(1)input_size:指的是每一个单词的特征维度,比如我有一个句子,句子中的每一个单词都用10维向量表示,则input_size就是10;
(2)hidden_size:指的是循环层中每一个LSTM内部单元的隐藏节点数目,这个是自己定义的,随意怎么设置都可以;
(3)num_layers:循环层的层数,默认是一层,这个根据自己的情况来定。
比如下面:


左边的只有一层循环层,右边的有两层循环层。
2、通过第一步构造的对象构造前向传播的过程——第二步:调用循环层对象,传入参数,并得到返回值
一般如下操作:
output, (hn, cn) = lstm(input, (h0, c0))
这里是以LSTM为例子来说的,
(1)输入参数
input:必须是这样的格式(seq,batch,feature)。第一个seq指的是序列的长度,这是根据自己的数据来定的,比如我的一个句子最大的长度是20个单词组成,那这里就是20,上面的例子是假设句子长度为5;第二个是batch,这个好理解,就是一次使用几条样本,比如3组样本;第三个features指的是每一个单词的向量维度,需要注意的是,这个必须要和构造函数的第一个参数input_size保持一样的,上面的例子中是10.
(h0,c0):指的是每一个循环层的初始状态,可以不指定,不指定的情况下全部初始化为0,这里因为是LSTM有两个状态需要传递,所以有两个,像普通的RNN和GRU只有一个状态需要传递,则只需要传递一个h状态即可,如下:
output, hn = rnn(input, h0) # 普通rnn output, hn = gru(input, h0) # gru
这里需要注意的是传入的状态参数的维度,依然以LSTM来说:
h0和c0的数据维度均是(num_layers * num_directions, batch, hidden_size),这是什么意思呢?
第一个num_layer指的是到底有基层循环层,这好理解,几层就应该有几个初始状态;
第二个num_directions指的是这个循环层是否是双向的(在构造函数中通过bidirectional参数指定哦),如果不是双向的,则取值为1,如果是双向的则取值为2;
第三个batch指的是每次数据的batch,和前面的batch保持一致即可;
最后一个hidden_size指的是循环层每一个节点内部的隐藏节点数,这个需要很好地理解循环神经网络的整个运算流程才行哦!
(2)输出结果
其实输出的结果和输入的是相匹配的,分别如下:
output, hn = rnn(input, h0) # 普通rnn output, hn = gru(input, h0) # gru output, (hn, cn) = lstm(input, (h0, c0)) # lstm
这里依然以lstm而言:
output的输出维度:(seq_len, batch, num_directions * hidden_size),在上面的例子中,应该为(5,3,20),我们通过验证的确如此,需要注意的是,第一个维度是seq_len,也就是说每一个时间点的输出都是作为输出结果的,这和隐藏层是不一样的;
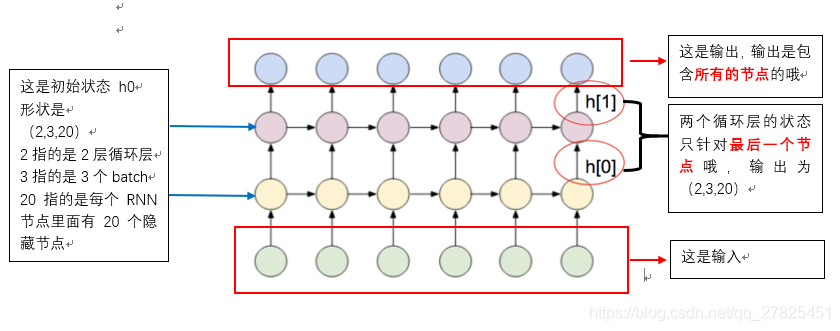
hn、cn的输出维度:为(num_layers * num_directions, batch, hidden_size),在上面的例子中为(2,3,20),也得到了验证,我们发现这个跟序列长度seq_len是没有关系的,为什么呢,输出的状态仅仅是指的是最后一个循环层节点输出的状态。
如下图所示:
下面的例子是以普通的RNN来画的,所以只有一个状态h,没有状态c。
3、几个重要的属性理解
不管是RNN,GRU还是lstm,内部可学习的参数其实就是几个权值矩阵,包括了偏置矩阵,那怎么查看这些学习到的参数呢?就是通过这几个矩阵来实现的
(1)weight_ih_l[k]:这表示的是输入到隐藏层之间的权值矩阵,其中K表示的第几层循环层,
若K=0,表示的是最下面的输入层到第一个循环层之间的矩阵,维度为(hidden_size, input_size),如果k>0则表示第一循环层到第二循环层、第二循环层到第三循环层,以此类推,之间的权值矩阵,形状为(hidden_size, num_directions * hidden_size)。
(2)weight_hh_l[k]: 表示的是循环层内部之间的权值矩阵,这里的K表示的第几层循环层,取值为0,1,2,3,4... ...。形状为(hidden_size, hidden_size)
注意:循环层的层数取值是从0开始,0代表第一个循环层,1代表第二个循环层,以此类推。
(3)bias_ih_l[k]: 第K个循环层的偏置项,表示的是输入到循环层之间的偏置,维度为 (hidden_size)
(4)bias_hh_l[k]:第K个循环层的偏置项,表示的是循环层到循环层内部之间的偏置,维度为 (hidden_size)。
# 首先导入RNN需要的相关模块
import torch
import torch.nn as nn
# 数据向量维数10, 隐藏元维度20, 2个RNN层串联(如果是1,可以省略,默认为1)
rnn = nn.RNN(10, 20, 2)
# 序列长度seq_len=5, batch_size=3, 数据向量维数=10
input = torch.randn(5, 3, 10)
# 初始化的隐藏元和记忆元,通常它们的维度是一样的
# 2个RNN层,batch_size=3,隐藏元维度20
h0 = torch.randn(2, 3, 20)
# 这里有2层RNN,output是最后一层RNN的每个词向量对应隐藏层的输出,其与层数无关,只与序列长度相关
# hn,cn是所有层最后一个隐藏元和记忆元的输出
output, hn = rnn(input, h0)
print(output.size(),hn.size()) # 分别是:torch.Size([5, 3, 20]) torch.Size([2, 3, 20])
# 查看一下那几个重要的属性:
print("------------输入--》隐藏------------------------------")
print(rnn.weight_ih_l0.size())
print(rnn.weight_ih_l1.size())
print(rnn.bias_ih_l0.size())
print(rnn.bias_ih_l1.size())
print("------------隐藏--》隐藏------------------------------")
print(rnn.weight_hh_l0.size())
print(rnn.weight_hh_l1.size())
print(rnn.bias_hh_l0.size())
print(rnn.bias_hh_l1.size())
'''输出结果为:
------------输入--》隐藏------------------------------
torch.Size([20, 10])
torch.Size([20, 20])
torch.Size([20])
torch.Size([20])
------------隐藏--》隐藏------------------------------
torch.Size([20, 20])
torch.Size([20, 20])
torch.Size([20])
torch.Size([20])
'''
通过上面的运算,发现结果和描述的是一模一样的。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
TensorFlow实现RNN循环神经网络
RNN(recurrent neural Network)循环神经网络 主要用于自然语言处理(nature language processing,NLP) RNN主要用途是处理和预测序列数据 RNN广泛的用于 语音识别.语言模型.机器翻译 RNN的来源就是为了刻画一个序列当前的输出与之前的信息影响后面节点的输出 RNN 是包含循环的网络,允许信息的持久化. RNN会记忆之前的信息,并利用之前的信息影响后面节点的输出. RNN的隐藏层之间的节点是有相连的,隐藏层的输入不仅仅包括输入层的输出,还包
-
pytorch下使用LSTM神经网络写诗实例
在pytorch下,以数万首唐诗为素材,训练双层LSTM神经网络,使其能够以唐诗的方式写诗. 代码结构分为四部分,分别为 1.model.py,定义了双层LSTM模型 2.data.py,定义了从网上得到的唐诗数据的处理方法 3.utlis.py 定义了损失可视化的函数 4.main.py定义了模型参数,以及训练.唐诗生成函数. 参考:电子工业出版社的<深度学习框架PyTorch:入门与实践>第九章 main代码及注释如下 import sys, os import torch as t fr
-

Pytorch 如何实现LSTM时间序列预测
开发环境说明: Python 35 Pytorch 0.2 CPU/GPU均可 1.LSTM简介 人类在进行学习时,往往不总是零开始,学习物理你会有数学基础.学习英语你会有中文基础等等. 于是对于机器而言,神经网络的学习亦可不再从零开始,于是出现了Transfer Learning,就是把一个领域已训练好的网络用于初始化另一个领域的任务,例如会下棋的神经网络可以用于打德州扑克. 我们这讲的是另一种不从零开始学习的神经网络--循环神经网络(Recurrent Neural Network, RNN
-
Pytorch实现LSTM和GRU示例
为了解决传统RNN无法长时依赖问题,RNN的两个变体LSTM和GRU被引入. LSTM Long Short Term Memory,称为长短期记忆网络,意思就是长的短时记忆,其解决的仍然是短时记忆问题,这种短时记忆比较长,能一定程度上解决长时依赖. 上图为LSTM的抽象结构,LSTM由3个门来控制,分别是输入门.遗忘门和输出门.输入门控制网络的输入,遗忘门控制着记忆单元,输出门控制着网络的输出.最为重要的就是遗忘门,可以决定哪些记忆被保留,由于遗忘门的作用,使得LSTM具有长时记忆的功能.对于
-
pytorch lstm gru rnn 得到每个state输出的操作
默认只返回最后一个state,所以一次输入一个step的input # coding=UTF-8 import torch import torch.autograd as autograd # torch中自动计算梯度模块 import torch.nn as nn # 神经网络模块 torch.manual_seed(1) # lstm单元输入和输出维度都是3 lstm = nn.LSTM(input_size=3, hidden_size=3) # 生成一个长度为5,每一个元素为1*3的序
-
PyTorch深度学习LSTM从input输入到Linear输出
目录 LSTM介绍 LSTM参数 Inputs Outputs batch_first 案例 LSTM介绍 关于LSTM的具体原理,可以参考: https://www.jb51.net/article/178582.htm https://www.jb51.net/article/178423.htm 系列文章: PyTorch搭建双向LSTM实现时间序列负荷预测 PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch搭建LSTM实现多变量时序负荷预测 PyTorch搭建LSTM
-
pytorch中nn.RNN()汇总
nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity=tanh, bias=True, batch_first=False, dropout=0, bidirectional=False) 参数说明 input_size输入特征的维度, 一般rnn中输入的是词向量,那么 input_size 就等于一个词向量的维度 hidden_size隐藏层神经元个数,或者也叫输出的维度(因为rnn输出为各个时间步上的隐藏状态) num_laye
-
pytorch+lstm实现的pos示例
学了几天终于大概明白pytorch怎么用了 这个是直接搬运的官方文档的代码 之后会自己试着实现其他nlp的任务 # Author: Robert Guthrie import torch import torch.autograd as autograd import torch.nn as nn import torch.nn.functional as F import torch.optim as optim torch.manual_seed(1) lstm = nn.LSTM(3, 3
-
pytorch nn.Conv2d()中的padding以及输出大小方式
我就废话不多说了,直接上代码吧! conv1=nn.Conv2d(1,2,kernel_size=3,padding=1) conv2=nn.Conv2d(1,2,kernel_size=3) inputs=torch.Tensor([[[[1,2,3], [4,5,6], [7,8,9]]]]) print("input size: ",inputs.shape) outputs1=conv1(inputs) print("output1 size: ",outp
-
Pytorch上下采样函数之F.interpolate数组采样操作详解
目录 什么是上采样 F.interpolate——数组采样操作 输入: 注意: 补充: 代码案例 一般用法 size与scale_factor的区别:输入序列时 size与scale_factor的区别:输入整数时 align_corners=True与False的区别 扩展: 总结 什么是上采样 上采样,在深度学习框架中,可以简单的理解为任何可以让你的图像变成更高分辨率的技术. 最简单的方式是重采样和插值:将输入图片input image进行rescale到一个想要的尺寸,而且计算每个点的像素
-
输出执行操作和打印日志的shell脚本实例
cat /mnt/log_function.sh #!/bin/bash #log function ####log_correct函数打印正确的输出到日志文件 function log_correct () { DATE=`date "+%Y-%m-%d %H:%M:%S"` ####显示打印日志的时间 USER=$(whoami) ####那个用户在操作 echo "${DATE} ${USER} execute $0 [INFO] $@" >>/v
-
vue.js使用v-pre与v-html输出HTML操作示例
本文实例讲述了vue.js使用v-pre与v-html输出HTML操作.分享给大家供大家参考,具体如下: <!doctype html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, user-scalable=no, initial-
-
pytorch程序异常后删除占用的显存操作
1-删除模型变量 del model_define 2-清空CUDA cache torch.cuda.empty_cache() 3-步骤2(异步)需要一定时间,设置时延 time.sleep(5) 完整代码如下: del styler torch.cuda.empty_cache() time.sleep(5) 以上这篇pytorch程序异常后删除占用的显存操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Java学习笔记:基本输入、输出数据操作实例分析
本文实例讲述了Java学习笔记:基本输入.输出数据操作.分享给大家供大家参考,具体如下: 相关内容: 输出数据: print println printf 输入数据: Scanner 首发时间:2018-03-16 16:30 输出数据: JAVA中在屏幕中打印数据可以使用: System.out.print(x):x可以是一个变量.表达式.字符串. System.out.println(x):x可以是一个变量.表达式.字符串.与print不同的是打印完后会换行 System.out.print