python演示解答正则为什么是最强文本处理工具
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
Python作为一门数据处理语言,经常使用正则匹配段落,比如爬虫爬取数据时。正则表达式是Python内置的模块,不需要额外安装。

今天来给大家分享一份比较全面的Python正则表达式宝典,学会之后,你将掌握正则表达式的各种应用场景。
re模块
re (Regular Expression简写),这个很好记住。
1.导入re模块
在使用正则表达式之前,需要导入re模块。
import re
2.findall()的语法:
导入了re模块之后就可以使用findall()方法了,
re.findall(pattern, string, flags=0)
参数
pattern:必填。正则表达式
string:必填,需要检索的文本, == 确保没乱码 ==
Flags:选填,功能标志位
返回数组
str='a1a2a3'
newStr=re.findall('a\d',str )
nullVlue=re.findall('b\d',str)
print('newStr匹配个数:',len(newStr))
print('newStr匹配结果',newStr)
print('nullVlue匹配个数:',len(nullVlue))
print('nullVlue匹配结果',nullVlue)
显示如下:
newStr匹配个数: 3 newStr匹配结果 ['a1', 'a2', 'a3'] nullVlue匹配个数: 0 nullVlue匹配结果 []
基本语法已经介绍完成了。
正则表达式
1.傻瓜式截取findall
import re text='aaa bbb ccc' rol='aaa (.*) ccc' rul=re.findall(rol ,text) print(rul)
显示如下:
['bbb']
直接复制原来的文本,把想要提取的文本替换成(.*)

表达式解释:
| 表示 | 意义 |
|---|---|
(pattern) |
表示匹配pattern并获取这一匹配。要匹配圆括号字符,请使用""或""或""。 |
. |
匹配除“\n"之外的任何单个字符。要匹配包括"\n"在内的任何字符,请使用像"(.|\n)"的模式。 |
* |
匹配前面的子表达式零次或多次。例如,zo*能匹配“z"以及"zoo"。*等价于{0,}。 |
增加替代
import re text = '<li><a href="/2/" rel="external nofollow" rel="external nofollow" rel="external nofollow" >动作片</a></li> <li><a href="/1/" rel="external nofollow" rel="external nofollow" rel="external nofollow" >喜剧片</a></li>' rol = r'<li><a href=".*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>' rul = re.findall(rol, text) print(rul)
显示:
['动作片', '喜剧片']
表达式解释:

| 表示 | 意义 |
|---|---|
? |
非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。 |
pattern |
不带( )表示匹配pattern匹配值不获取~~获取值不输出~~。 |
保留获取
import re text = '<li><a href="/2/" rel="external nofollow" rel="external nofollow" rel="external nofollow" >动作片</a></li> <li><a href="/1/" rel="external nofollow" rel="external nofollow" rel="external nofollow" >喜剧片</a></li>' role = r'<li><a href=".*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>' resu = re.findall(role , text) rol2=r'(<a href=".*?" rel="external nofollow" rel="external nofollow" rel="external nofollow" >.*?</a>)' rul2 = re.findall(rol2, text) print(resu )
显示:
['<a href="/2/">动作片</a>', '<a href="/1/">喜剧片</a>']
把括号写在外面就可以了
傻瓜式的讲完了,下面讲讲限定符
1 - [xyz]
字符集合。匹配所包含的任意一个字符。例如,“[abc]“可以匹配"plain"中的"a”。
import re text = 'aab 1+23 ss aac 4-56 ss' rol = r'aa(.*?)ss' rul1 = re.findall(rol, text) print(rul1) rol2 = r'aa[bc](.*?)ss' rul1 = re.findall(rol2, text) print(rul1)
输出:
['b 1+23 ', 'c 4-56 ']
[' 1+23 ', ' 4-56 ']
== 表达式解释 ==
①我们可以先把固定的截取下来,红框部分。
②再通过非截取方式把b和c过滤掉,蓝色部分。
③[ ]提供的就是包含功能

2 - {}
| 表示 | 意义 |
|---|---|
{n} |
n是一个非负整数。匹配确定的n次。例如,“o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
{n,} |
n是一个非负整数。至少匹配n次。例如,“o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
{n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}"将匹配"fooooood"中的前三个o。"o{0,1}"等价于"o?"。请注意在逗号和两个数之间不能有空格。 |
+ |
匹配前面的子表达式一次或多次。例如,“zo+"能匹配"zo"以及"zoo",但不能匹配"z"。+等价于{1,}。。 |
* |
匹配前面的子表达式零次或多次。例如,zo*能匹配“z"以及"zoo"。*等价于{0,}。 |
== 难度加大,b和c的个数不固定 ==
import re
#难度加大,b和c的个数不固定
text = 'aabbccbb 1+23 ss aaccb 4-56 ss'
rol = r'aa[bc]{3,10}(.*?)ss'
rul1 = re.findall(rol, text)
print(rul1)
rol2 = r'aa[bc](.*?)ss'
rul2 = re.findall(rol2, text)
print(rul2)
显示:
[' 1+23 ', ' 4-56 ']
['bccbb 1+23 ', 'cb 4-56 ']

3 - (?:pattern)正则断言
断言(Assertions)在正则表达式概念里面难理解,它通常指的是在目标字符串的当前匹配位置进行的一种测试但这种测试并不占用目标字符串,也即不会移动模式在目标字符串中的当前匹配位置。
| 表示 | 意义 |
|---|---|
x|y |
匹配x或y。例如,“z|food"能匹配"z"或"food"。"(z|f)ood"则匹配"zood"或"food"。 |
(?:pattern) |
匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“(|)"来组合一个模式的各个部分是很有用。 |
(?=pattern) |
正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 |
(?!pattern) |
正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 |
(?!pattern) |
正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。 |
(?<=pattern) |
反向肯定预查,与正向肯定预查类拟,只是方向相反。 |
(?<!pattern) |
反向否定预查,与正向否定预查类拟,只是方向相反。 |
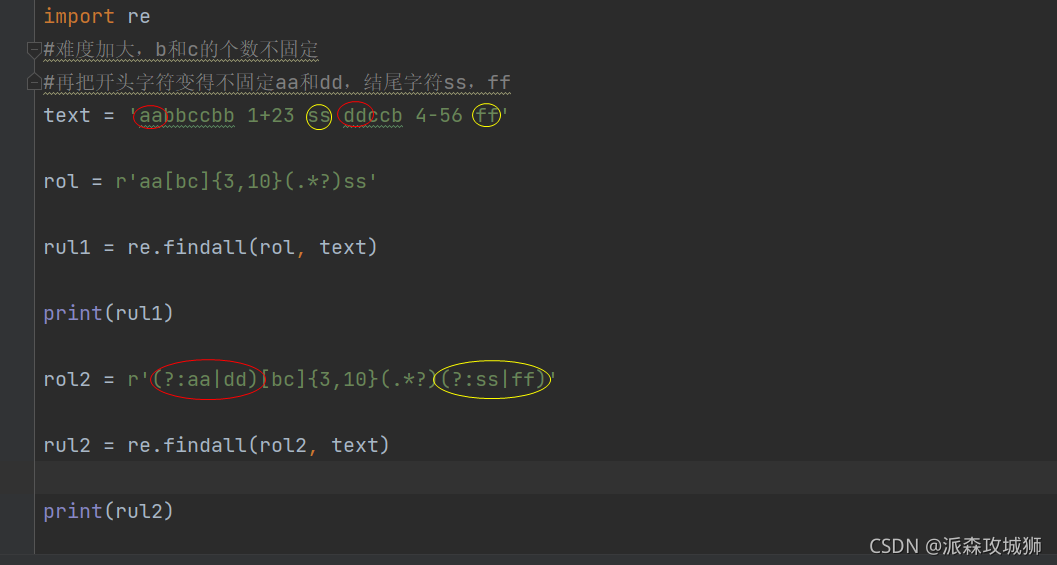
== 再把开头字符变得不固定aa和dd,结尾字符ss,ff ==
import re
#难度加大,b和c的个数不固定
#再把开头字符变得不固定aa和dd,结尾字符ss,ff
text = 'aabbccbb 1+23 ss ddccb 4-56 ff'
rol = r'aa[bc]{3,10}(.*?)ss'
rul1 = re.findall(rol, text)
print(rul1)
rol2 = r'(?:aa|dd)[bc]{3,10}(.*?)(?:ss|ff)'
rul2 = re.findall(rol2, text)
print(rul2)
显示:
[' 1+23 ']
[' 1+23 ', ' 4-56 ']
Python正则flags
编译标志让你可以修改正则表达式的一些运行方式。多个标志可以通过按位 OR-ing 它们来指定。如 re.I | re.M 。flags都有两种形式,缩写和全写都可以。
| 表示 | 意义 |
|---|---|
re.I或re.IGNORECASE |
忽略大小写 |
re.L或re.LOCALE |
使用当地locale。(python中有个locale模块,locale代表不同的语言,地区和字符集) |
re.U或re.UNICODE |
使用unicode的locale |
re.U或re.UNICODE |
使用unicode的locale |
re.M或re.MULTILINE |
使用^或$时会匹配每一行的行首或行尾 |
re.S或re.DOTALL |
使用.时能匹配换行符 |
re.X或re.VERBOX |
忽略空白字符,而且可以加入注释 |
re.I
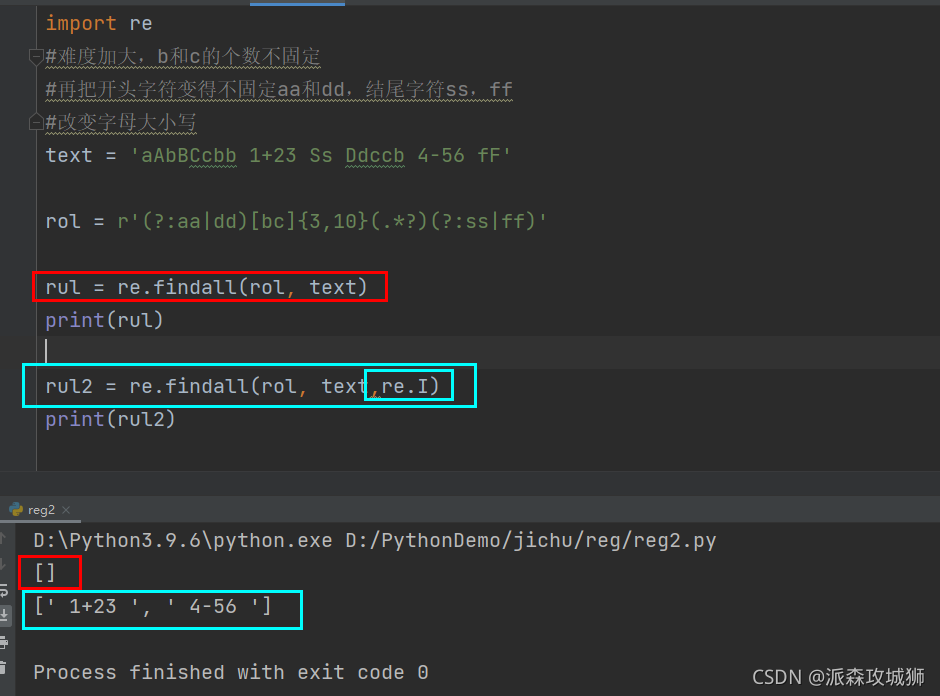
import re
#难度加大,b和c的个数不固定
#再把开头字符变得不固定aa和dd,结尾字符ss,ff
#改变字母大小写
text = 'aAbBCcbb 1+23 Ss Ddccb 4-56 fF'
rol = r'(?:aa|dd)[bc]{3,10}(.*?)(?:ss|ff)'
rul = re.findall(rol, text)
print(rul)
rul2 = re.findall(rol, text,re.I)
print(rul2)
显示:
[]
[' 1+23 ', ' 4-56 ']
re.M和re.S
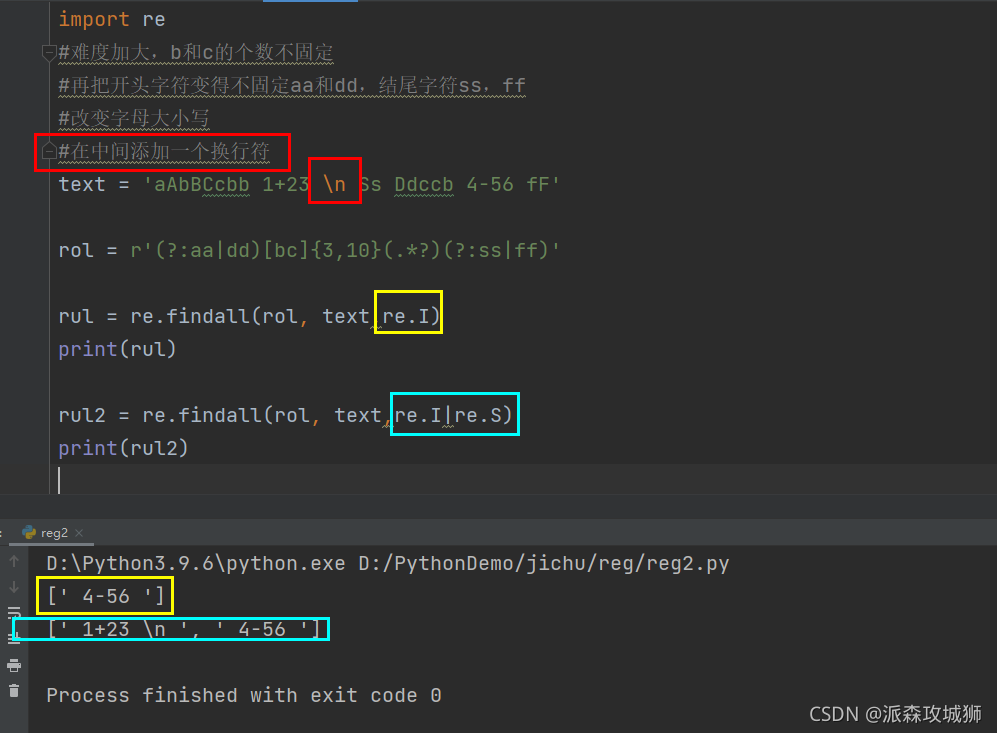
import re
#难度加大,b和c的个数不固定
#再把开头字符变得不固定aa和dd,结尾字符ss,ff
#改变字母大小写
#在中间添加一个换行符
text = 'aAbBCcbb 1+23 \n Ss Ddccb 4-56 fF'
rol = r'(?:aa|dd)[bc]{3,10}(.*?)(?:ss|ff)'
rul = re.findall(rol, text,re.I)
print(rul)
rul2 = re.findall(rol, text,re.I|re.S)
print(rul2)
显示:
[' 4-56 ']
[' 1+23 \n ', ' 4-56 ']
== 结果说明 ==
①默认re.M只会匹配在当前 行(非列) 里面进行匹配,“Ss”已经换行了,所以“1+23”没有匹配到。
②re.S表示匹配多行,并且捕获换行符
③re.S|re.I可以并行使用
# 结语 正则的匹配方法,已经写完了,号称万能的文本处理工具,下篇开始讲解,替换,追加。最后最后,感谢大家关注!
到此这篇关于python演示解答正则为什么是最强文本处理工具的文章就介绍到这了,更多相关python 正则内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python正则表达式保姆式教学详细教程
目录 一.re模块 1.导入re模块 2.findall()的语法: 二.正则表达式 1.普通字符 2.元字符 (二)正则的使用 1.编译正则 2.正则对象的使用方法 3.Match object 的操作方法 4.re模块的函数 正则作为处理字符串的一个实用工具,在Python中经常会用到,比如爬虫爬取数据时常用正则来检索字符串等等.正则表达式已经内嵌在Python中,通过导入re模块就可以使用,作为刚学Python的新手大多数都听说"正则"这个术语. 今天来给大家分享一份关于比较详细
-
python正则表达式函数match()和search()的区别
match()函数只检测RE是不是在string的开始位置匹配, search()会扫描整个string查找匹配, 也就是说match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回none 例如: #! /usr/bin/env python # -*- coding=utf-8 -*- import re text= 'pythontab' m= re.match(r"\w+", text) if m: print m.group(0) el
-
浅谈Python中的正则表达式
Python里的正则表达式 Python里的正则表达式,无需下载外部模块,只需要引入自带模块:re: import re 官方re模块文档: https://docs.python.org/zh-cn/3.9/library/re.html 同时,Python的正则表达式是PCRE标准的,相较于广泛应用在Unix上的POSIX标准,还是有些区别的(主要是简化) 基本方法 观察re源码,其主要的接口方法有: match(-):从字符串的起始位置匹配一个模式,如果无法匹配成功,则match()就返回
-
Python正则表达式中的量词符号与组问题小结
正则表达式中的符号 例子 | 是或的关系,只要存在就会被捕获 匹配到的数据只按字符串顺序返回,而不是按照匹配规则返回 In [18]: data = 'insane@loafer.com' In [19]: print(re.findall('insane|com|loafer', data)) ['insane', 'loafer', 'com'] ^ 等同于 \A In [20]: print(re.findall('^insane',data)) ['insane'] In [21]: p
-
一篇文章带你了解python正则表达式的正确用法
目录 正则表达式的介绍 re模块 匹配单个字符 1.匹配任意一个字符 2.匹配[ ]中列举的字符 3.\d匹配数字,即0-9 4.\D匹配非数字,即不是数字 5.\s匹配空白,即 空格,tab键 6.\S匹配非空白 7.\w匹配非特殊字符,即a-z.A-Z.0-9._.汉字 8.\W匹配特殊字符,即非字母.非数字.非汉字 总结 正则表达式的介绍 1)在实际开发过程中经常会有查找符合某些复杂规则的字符串的需要,比如:邮箱.手机号码等,这时候想匹配或者查找符合某些规则的字符串就可以使用正则表达式了.
-
python正则表达式re.search()的基本使用教程
1 re.search() 的作用: re.search会匹配整个字符串,并返回第一个成功的匹配.如果匹配失败,则返回None 从源码里面可以看到re.search()方法里面有3个参数 pattern: 匹配的规则, string : 要匹配的内容, flags 标志位 这个是可选的,就是可以不写,可以写, 比如要忽略字符的大小写就可以使用标志位 flags 的主要内容如下 flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为: re.I 忽略大小写 re.L 表示特殊字
-
超详细讲解python正则表达式
目录 正则表达式 1.1 正则表达式字符串 1.1.1 元字符 1.1.2 字符转义 1.1.3 开始与结束字符 1.2 字符类 1.2.1 定义字符类 1.2.2 字符串取反 1.2.3 区间 1.2.4 预定义字符类 1.3 量词 1.3.1 量词的使用 1.3.2 贪婪量词和懒惰量词 1.4 分组 1.4.1 分组的使用 1.4.2 分组命名 1.4.3 反向引用分组 1.4.4 非捕获分组 1.5 re模块 1.5.1 search()和match()函数 1.5.2 findall()
-
带你精通Python正则表达式
目录 Python正则表达式 一.re模块 1.导入re模块 2.findall()的语法: 二.正则表达式 1.字符串的匹配 2.正则的使用 Python正则表达式 正则作为处理字符串的一个实用工具,在Python中经常会用到,比如爬虫爬取数据时常用正则来检索字符串等等.正则表达式已经内嵌在Python中,通过导入re模块就可以使用,作为刚学Python的新手大多数都听说"正则"这个术语. 一.re模块 在讲正则表达式之前,我们首先得知道哪里用得到正则表达式.正则表达式是用在find
-
Python正则表达式的应用详解
目录 正则表达式的定义 Python对正则表达式的支持 示例 例1:验证输入的用户名是否有效,用户名由长度为6到20的字母.数字.下划线组成 例2:从字符串中找到与正则表达式匹配的部分 例3:从网页上获取新闻的标题和链接 例4:不良内容过滤 例5:用正则表达式拆分字符串 总结 正则表达式的定义 在编写处理字符串的程时,经常会遇到在一段文本中查找符合某些规则的字符串的需求,正则表达式就是用于描述这些规则的工具,换句话说,我们可以使用正则表达式来定义字符串的匹配模式,即如何检查一个字符串是否有跟某种
-
一篇文章彻底搞懂python正则表达式
目录 前言 1. 正则表达式的基本概念 2. python的正则表达式re模块 3. 正则表达式语法 (1)匹配单个字符 (2)匹配多个字符 (3)边界匹配 (4)分组匹配 4. re模块相关方法使用 总结 前言 有时候字符串匹配解决不了问题,这个时候就需要正则表达式来处理.因为每一次匹配(比如找以什么开头的,以什么结尾的字符串要写好多个函数)都要单独完成,我们可以给它制定一个规则. 主要应用:爬虫的时候需要爬取各种信息,使用正则表达式可以很方便的处理需要的数据. 1. 正则表达式的基本概念 使
-
一篇文章带你了解Python和Java的正则表达式对比
目录 简单批量替换 复杂模板替换 总结 参考资料: 正则表达式语法–菜鸟教程 Java正则表达式实现 简单批量替换 举例:将and 批量替换为&& Python实现 import re def transformSimple(fromRegex, toText, inText): return re.sub(fromRegex, toText,inText, flags =re.I) if __name__ == "__main__": inText = "x