滴滴二面之Kafka如何读写副本消息的
目录
- 前言
- appendRecords-副本写入
- 副本读取:fetchMessages
- 总结
前言
无论是读取副本还是写入副本,都是通过底层的Partition对象完成的,而这些分区对象全部保存在上节课所学的allPartitions字段中。可以说,理解这些字段的用途,是后续我们探索副本管理器类功能的重要前提。
现在,我们就来学习下副本读写功能。整个Kafka的同步机制,本质上就是副本读取+副本写入,搞懂了这两个功能,你就知道了Follower副本是如何同步Leader副本数据的。
appendRecords-副本写入
向副本底层日志写入消息的逻辑就实现在ReplicaManager#appendRecords。
Kafka需副本写入的场景:
- 生产者向Leader副本写入消息
- Follower副本拉取消息后写入副本
仅该场景调用Partition对象的方法,其余3个都是调用appendRecords完成 - 消费者组写入组信息
- 事务管理器写入事务信息(包括事务标记、事务元数据等)
appendRecords方法将给定的一组分区的消息写入对应Leader副本,并根据PRODUCE请求中acks的设置,有选择地等待其他副本写入完成。然后,调用指定回调逻辑。

appendRecords向副本日志写入消息的过程:
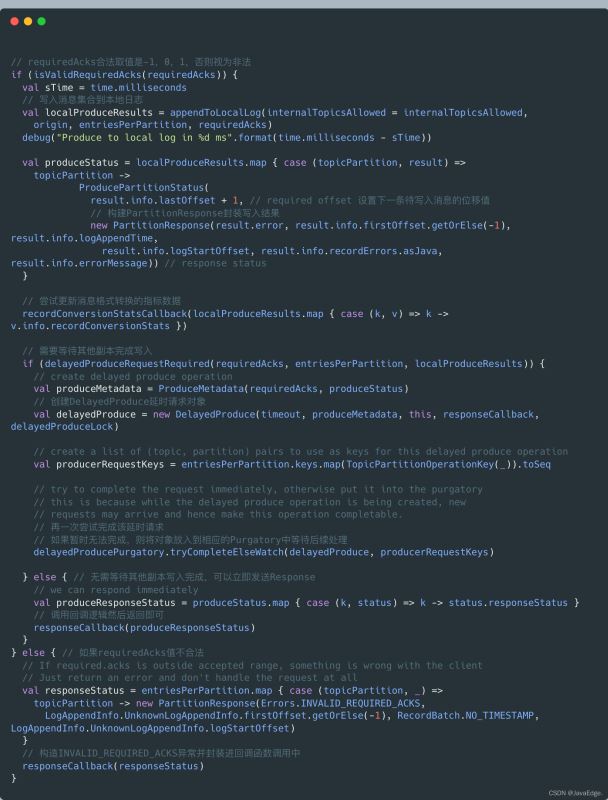
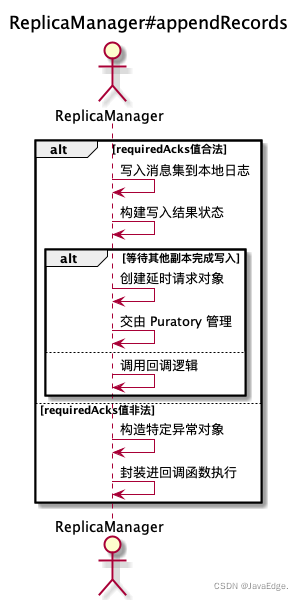
执行流程
可见,appendRecords:
实现消息写入的方法是appendToLocalLog
判断是否需要等待其他副本写入的方法delayedProduceRequestRequired
appendToLocalLog写入副本本地日志
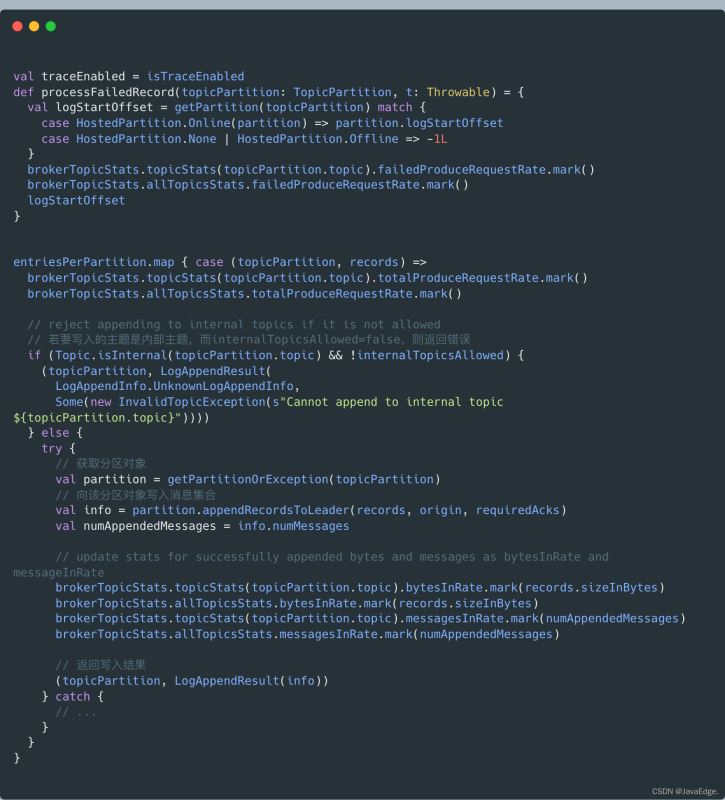
利用Partition#appendRecordsToLeader写入消息集合,就是利用appendAsLeader方法写入本地日志的。
delayedProduceRequestRequired
判断消息集合被写入到日志之后,是否需要等待其它副本也写入成功:
private def delayedProduceRequestRequired(
requiredAcks: Short,
entriesPerPartition: Map[TopicPartition, MemoryRecords],
localProduceResults: Map[TopicPartition, LogAppendResult]): Boolean = {
requiredAcks == -1 && entriesPerPartition.nonEmpty &&
localProduceResults.values.count(_.exception.isDefined) < entriesPerPartition.size
}
若等待其他副本的写入,须同时满足:
- requiredAcks==-1
- 依然有数据尚未写完
- 至少有一个分区的消息,已成功被写入本地日志
2和3可结合来看。若所有分区的数据写入都不成功,则可能出现严重错误,此时应不再等待,而是直接返回错误给发送方。
而有部分分区成功写入,部分分区写入失败,则可能偶发的瞬时错误导致。此时,不妨将本次写入请求放入Purgatory,给个重试机会。
副本读取:fetchMessages
ReplicaManager#fetchMessages负责读取副本数据。无论:
- Java消费者
- APIFollower副本
拉取消息的主途径都是向Broker发FETCH请求,Broker端接收到该请求后,调用fetchMessages从底层的Leader副本取出消息。
fetchMessages也可能会延时处理FETCH请求,因Broker端必须要累积足够多数据后,才会返回Response给请求发送方。

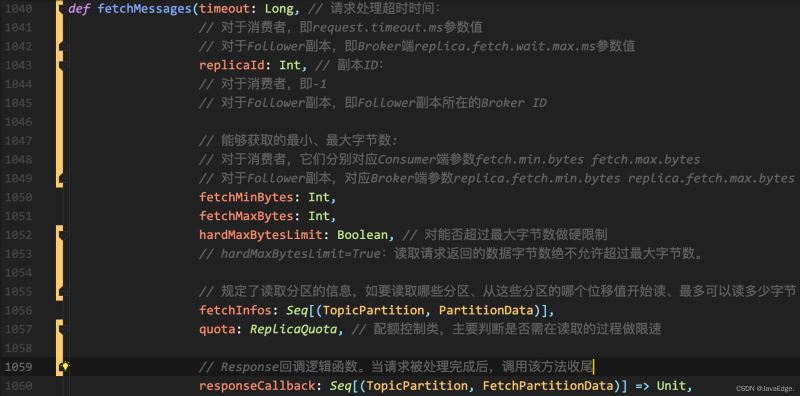
整个方法分为:
读取本地日志
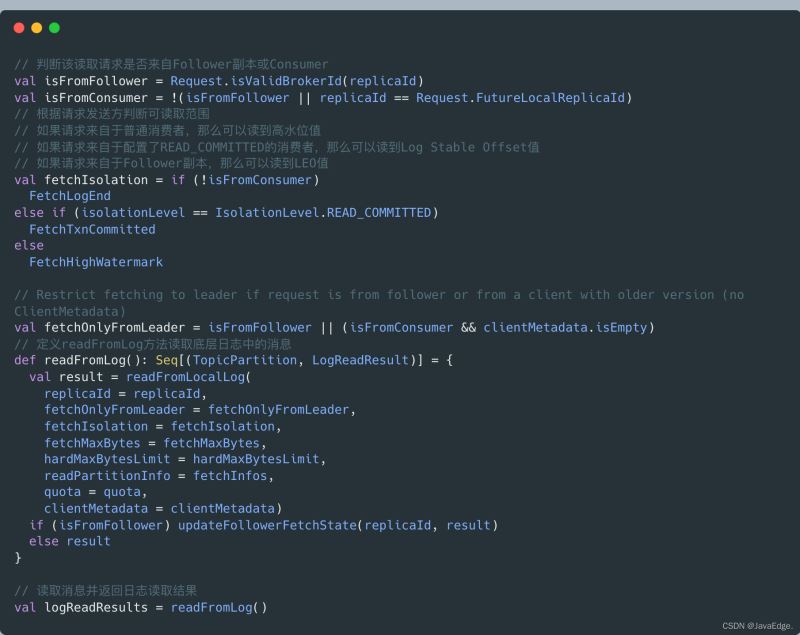
首先判断,读取消息的请求方,就能确定可读取的范围了。
fetchIsolation,读取隔离级别:
- 对Follower副本,它能读取到Leader副本LEO值以下的所有消息
- 普通Consumer,只能“看到”Leader副本高水位值以下的消息
确定可读取范围后,调用readFromLog读取本地日志上的消息数据,并将结果赋给logReadResults变量。readFromLog调用readFromLocalLog,在待读取分区上依次调用其日志对象的read方法执行实际的消息读取。
根据读取结果确定Response
根据上一步读取结果创建对应Response:
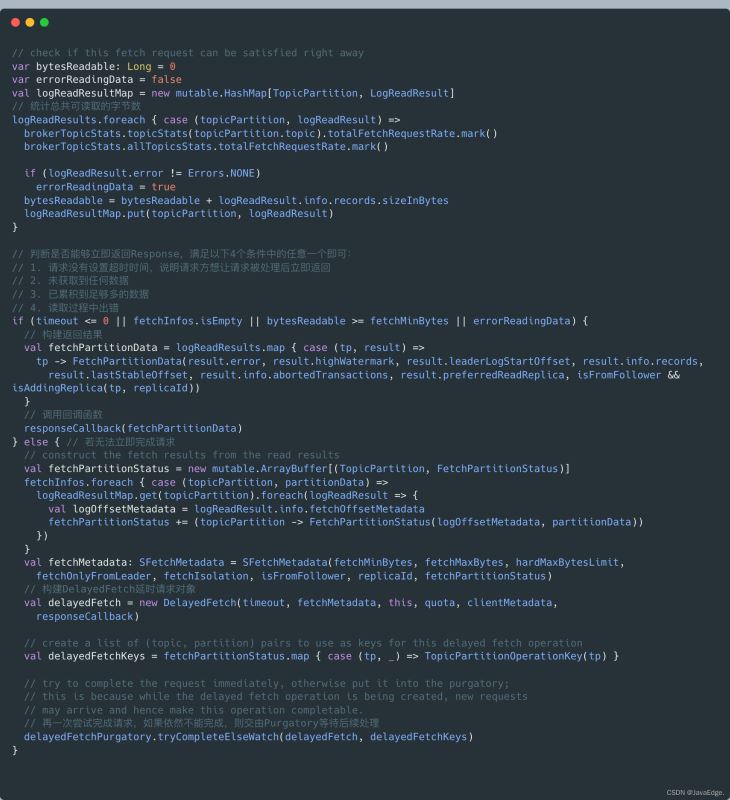
根据上一步得到的读取结果,统计可读取的总字节数,然后判断此时是否能够立即返回Reponse。
副本管理器读写副本的两个方法appendRecords和fetchMessages本质上在底层分别调用Log的append和read方法,以实现本地日志的读写操作。完成读写操作后,这两个方法还定义了延时处理的条件。一旦满足延时处理条件,就交给对应Purgatory处理。
从这俩方法可见单个组件融合一起的趋势。虽然我们学习单个源码文件的顺序是自上而下,但串联Kafka主要组件功能的路径却是自下而上。
如副本写入操作,日志对象append方法被上一层的Partition对象中的方法调用,而后者又进一步被副本管理器中的方法调用。我们按自上而下阅读了副本管理器、日志对象等单个组件的代码,了解了各自的独立功能。
现在开始慢慢地把它们融合一起,构建Kafka操作分区副本日志对象的完整调用路径。同时采用这两种方式来阅读源码,就能更高效弄懂Kafka原理。
总结
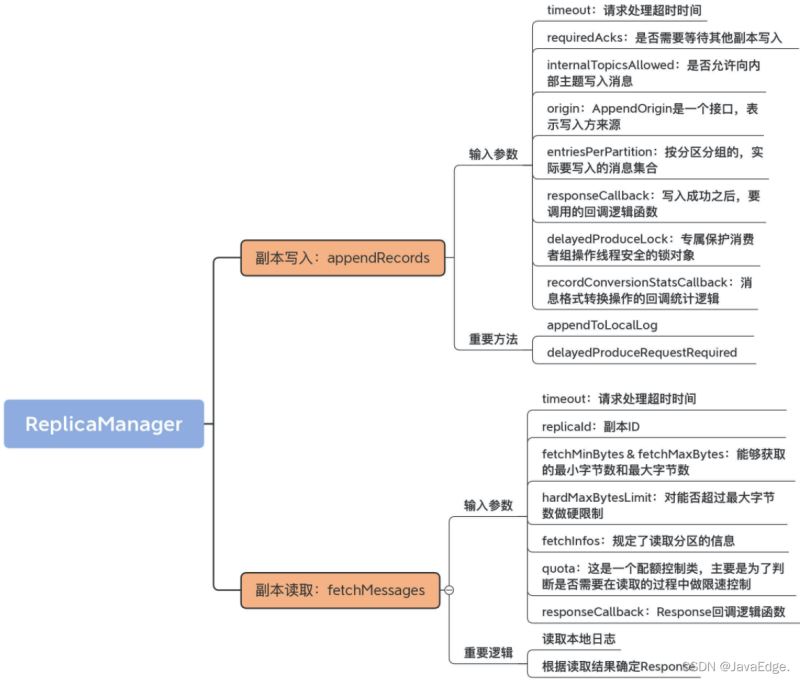
Kafka副本状态机类ReplicaManager读写副本的核心方法:
- appendRecords:向副本写入消息,利用Log#append方法和Purgatory机制实现Follower副本向Leader副本获取消息后的数据同步操作
- fetchMessages:从副本读取消息,为普通Consumer和Follower副本所使用。当它们向Broker发送FETCH请求时,Broker上的副本管理器调用该方法从本地日志中获取指定消息
到此这篇关于滴滴二面之Kafka如何读写副本消息的文章就介绍到这了,更多相关Kafka读写副本消息内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

在springboot中对kafka进行读写的示例代码
springboot对kafka的client很好的实现了集成,使用非常方便,本文也实现了一个在springboot中实现操作kafka的demo. 1.POM配置 只需要在dependencies中增加 spring-kafka的配置即可.完整效果如下: <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifa
-
滴滴二面之Kafka如何读写副本消息的
目录 前言 appendRecords-副本写入 副本读取:fetchMessages 总结 前言 无论是读取副本还是写入副本,都是通过底层的Partition对象完成的,而这些分区对象全部保存在上节课所学的allPartitions字段中.可以说,理解这些字段的用途,是后续我们探索副本管理器类功能的重要前提. 现在,我们就来学习下副本读写功能.整个Kafka的同步机制,本质上就是副本读取+副本写入,搞懂了这两个功能,你就知道了Follower副本是如何同步Leader副本数据的. append
-
kafka并发写大消息异常TimeoutException排查记录
目录 前言 定位异常点 分析抛异常的逻辑 真实原因-解决方案 结语 前言 先简单介绍下我们的使用场景,线上5台Broker节点的kafka承接了所有binlog订阅的数据,用于Flink组件接收数据做数据中台的原始数据.昨儿开发反馈,线上的binlog大量报错,都是kafka的异常,而且都是同一条topic抛的错,特征也很明显,发送的消息体非常大,主观判断肯定是写入大消息导致的超时了,异常详情如下: thread: kafka-producer-network-thread | producer
-
Kafka Producer中的消息缓存模型图解详解
目录 前言 什么是消息累加器RecordAccumulator 消息缓存模型 ProducerBatch的内存大小 内存分配 Batch的创建和释放 问题和答案 总结 前言 在阅读本文之前, 希望你可以思考一下下面几个问题, 带着问题去阅读文章会获得更好的效果. 发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗? 当消息还存储在缓存中的时候, 假如Producer客户端挂掉了,消息是不是就丢失了? 当最新的ProducerBatch还有空余的内存,但是接下来的一条消息很大,不
-
Java使用kafka发送和生产消息的示例
1. maven依赖包 <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.9.0.1</version> </dependency> 2. 生产者代码 package com.lnho.example.kafka; import org.apache.kafka.c
-
大数据Kafka:消息队列和Kafka基本介绍
目录 一.什么是消息队列 二.消息队列的应用场景 异步处理 应用耦合 限流削峰 消息驱动系统 三.消息队列的两种方式 点对点模式 发布/订阅模式 四.常见的消息队列的产品 1) RabbitMQ 2) activeMQ: 3) RocketMQ 4) kafka 五.Kafka的基本介绍 一.什么是消息队列 消息队列,英文名:Message Queue,经常缩写为MQ.从字面上来理解,消息队列是一种用来存储消息的队列 .来看一下下面的代码 上述代码,创建了一个队列,先往队列中添加了一个消息,然后
-
如何基于sqlite实现kafka延时消息详解
目录 1.需求 2.实现思路 2.1 整体实现思路 2.2 程序业务逻辑 2.3 实现细节 2.4 依赖框架 3.性能测试 4.部署 4.1 系统环境依赖 4.2 安装 4.3 程序迁移 4.4 排查日志 5.注意事项 6.闲聊 总结 1.需求 延时消息(或者说定时消息)是业务系统里一个常见的功能点.常用业务场景如: 1) 订单超时取消 2) 离线超过指定时间的用户,召回通知 3) 手机消失多久后通知监护人…… 现流行的实现方案主要有: 1)数据库定时轮询,扫描到达到延时时间的记录,业务处理,删
-
关于Kafka消息队列原理的总结
目录 Kafka消息队列原理 Kafka的逻辑数据模型 Kafka的分发策略 Kafka的物理存储模型和查找数据的设计 Kafka的持久化策略设计 Kafka的节点间的数据一致性策略设计 Kafka的备份和负载均衡 Kafka消息队列内部实现原理 Kafka消息队列原理 最近在测试kafka的读写性能,所以借这个机会了解了kafka的一些设计原理,既然作为分布式系统,我们还是按照分布式的套路进行分析. Kafka的逻辑数据模型 生产者发送数据给服务端时,构造的是ProducerRecord<In
-
spring boot整合kafka过程解析
这篇文章主要介绍了spring boot整合kafka过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.启动kafka 启动kafka之前一定要启动zookeeper,因为要使用kafka必须要使用zookeeper. windows环境下启动,直接使用kafka自带的zookeeper: E:\kafka_2.12-2.4.0\bin\windows zookeeper-server-start.bat ..\..\config\z
-
Kafka producer端开发代码实例
一.producer工作流程 producer使用用户启动producer的线程,将待发送的消息封装到一个ProducerRecord类实例,然后将其序列化之后发送给partitioner,再由后者确定目标分区后一同发送到位于producer程序中的一块内存缓冲区中.而producer的另外一个线程(Sender线程)则负责实时从该缓冲区中提取出准备就绪的消息封装进一个批次(batch),统一发送给对应的broker,具体流程如下图: 二.producer示例程序开发 首先引入kafka相关依赖