分步骤教你用python一步步提取PPT中的图片
目录
- 一、实现原理
- 二、提取PPT中的图片
- 1、打开压缩包
- 2、解压文件
- 三、提取PPT中的图片
一、实现原理
其实实现原理很简单,我们的pptx文件其实是一个压缩包。我们可以直接修改pptx文件的后缀,改成zip然后解压,比如下面这个:
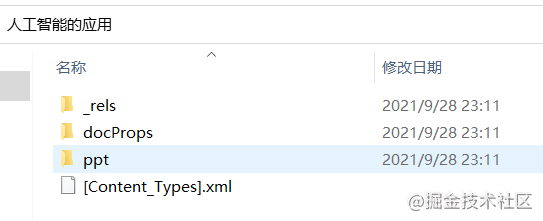
这是解压后的文件。我们可以在ppt目录下找到一个media目录,这个目录下就是我们要的图片的。这个目录包含了PPT的所有多媒体文件。
知道这点后,我们就可以选择用Python来解压出PPT中的media目录就可以提取出所有图片了。
二、提取PPT中的图片
1、打开压缩包
在Python中提供了一个zipfile模块用于处理压缩包文件。我们来看看它的简单操作:
from zipfile import ZipFile
# 打开压缩文件
f = ZipFile("test.pptx")
# 查看压缩包所有文件
for file in f.namelist():
print(file)
# 关闭压缩包文件
f.close()
输出的部分结果如下:
[Content_Types].xml _rels/.rels ppt/presentation.xml ppt/slides/_rels/slide2.xml.rels ppt/slides/slide1.xml ppt/slides/slide2.xml ppt/slides/slide3.xml
可以看到我们打印出了压缩包的文件。
2、解压文件
我们还可以通过下面的方式打开压缩包:
from zipfile import ZipFile
with ZipFile("test.pptx") as f:
for file in f.namelist():
print(file)
通过with语句,就可以不显示地调用close方法。下面我们看看解压操作:
from zipfile import ZipFile
with ZipFile("test.pptx") as f:
for file in f.namelist():
# 解压文件
f.extract(file, path="unzip")
解压文件的操作通过f.extract来实现,这里传入了两个参数,分别是压缩包文件,和解压路径,如果压缩包有密码还需要传入解压密码。
然后我们还需要判断一下,如果是媒体目录我们才解压。我们添加一点代码:
from zipfile import ZipFile
with ZipFile("test.pptx") as f:
for file in f.namelist():
# 如果是media目录下的文件就解压
if file.startswith("ppt/media/"):
f.extract(file, path="unzip")
这样我们就实现了PPT图片的提取。
三、提取PPT中的图片
我们把上面代码再完善一下:
import os
from zipfile import ZipFile
# 解压目录
unzip_path = "unzip"
# 如果解压目录不存在则创建
if not os.path.exists(unzip_path):
os.mkdir(unzip_path)
with ZipFile("test1/test.pptx") as f:
for file in f.namelist():
if file.startswith("ppt/media/"):
f.extract(file, path=unzip_path)
这里我们就是添加了一个解压目录的创建,这样我们执行的时候就不会因为目录不存在而报错了。
另外,其实我们手动解压然后提取PPT中的图片也是很方便的,也并不会比程序慢。
到此这篇关于分步骤教你用python一步步提取PPT中的图片的文章就介绍到这了,更多相关python 提取 PPT 图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python办公自动化PPT批量转换操作
目录 python-pptx 模块的安装 读取 PPT 写入 PPT 添加一张幻灯片 为幻灯片添加内容 获取幻灯片中的形状: 添加自动形状 占位符 访问占位符 将内容插入占位符 如果要插入表格: 如果要插入图表: PPT 转 Pdf 最后的话 如果你有一堆 PPT 要做,他们的格式是一样的,只是填充的内容不一样,那你就可以使用 Python 来减轻你的负担. PPT 分为内容和格式,用 Python 操作 PPT,就是利用 Python 对 PPT 的内容进行获取和填充,修改 PPT 的格式并不
-
利用Python制作PPT的完整步骤
目录 前言 步骤1: 步骤2:安装PIP3 步骤3:安装python-pptx 4.写代码测试: 总结 前言 怎么,你还没学Python吗? 此一时彼以时,什么C,JAVA,现在在求职市场都是渣渣,铺天盖地的Python学习广告,一遍又一遍地提醒着着我,你已经老了: 老板说:你很努力,但我还是想提拔会Python的人. 员工说:自从学了Python,腰不疼了,腿不酸了,颈椎不痛了,连工资都涨了... 码农说:我要偷偷学Python,惊呆所有人! ...... 所以,为了不被时代滚滚洪流淘汰,争取
-
python 实现提取PPT中所有的文字
我就废话不多说了,大家还是直接看代码吧~ # 导入pptx包 from pptx import Presentation prs = Presentation(path_to_presentation) text_runs = [] for slide in prs.slides: for shape in slide.shapes: if not shape.has_text_frame: continue for paragraph in shape.text_frame.paragraph
-
python自动化办公操作PPT的实现
1.python-pptx模块简介 使用python操作PPT,需要使用的模块就是python-pptx,下面来对该模块做一个简单的介绍.这里提前做一个说明:python操作PPT,最好是我们提前设计好自己的一套样式,然后利用进行python进行内容的获取和填充(最主要的功能!),最好是不用使用python代码操作PPT的格式,格式的修改肯定不如我们直接在PPT中修改方便. 可以创建.修改PPT(.pptx)文件 需要单独安装,不包含在Python标准模块里 python-pptx官网介绍:ht
-
python 批量将PPT导出成图片集的案例
导读 需要使用python做一个将很多个不规则PPT导出成用文件夹归纳好的图片集,所以就需要使用comtypes调用本机电脑上的ppt软件,批量打开另存为多张图片 采坑 公司电脑使用comtypes完美导出图片,系统win10 回家后使用自己的电脑就报错,系统也是win10,最后没办法放弃comtypes采用win32com,最终成功 源代码 """ 该工具函数的功能:批量将PPT导出成图片 """ import comtypes.client
-
分步骤教你用python一步步提取PPT中的图片
目录 一.实现原理 二.提取PPT中的图片 1.打开压缩包 2.解压文件 三.提取PPT中的图片 一.实现原理 其实实现原理很简单,我们的pptx文件其实是一个压缩包.我们可以直接修改pptx文件的后缀,改成zip然后解压,比如下面这个: 这是解压后的文件.我们可以在ppt目录下找到一个media目录,这个目录下就是我们要的图片的.这个目录包含了PPT的所有多媒体文件. 知道这点后,我们就可以选择用Python来解压出PPT中的media目录就可以提取出所有图片了. 二.提取PPT中的图片 1.
-
教你怎么使用hadoop来提取文件中的指定内容
一.需求 把以下txt中含"baidu"字符串的链接输出到一个文件,否则输出到另外一个文件. 二.步骤 1.LogMapper.java package com.whj.mapreduce.outputformat; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.
-
python使用正则表达式分析网页中的图片并进行替换的方法
本文实例讲述了python使用正则表达式分析网页中的图片并进行替换的方法.分享给大家供大家参考.具体分析如下: 这段代码分析网页中的所有图片表单<img>,分析后为其前后添加相应的修饰标签,并添加到图片的超级链接. 复制代码 代码如下: result = value.replace("[ page ]","").replace(' ',u' ') p=re.compile(r'''(<img\b[^<>]*?\bsrc[\s\t\r\
-
python [:3] 实现提取数组中的数
搜索答案搜索不到,自己试了一把. 首先生成一维数组 a =np.array([1,2,3,4,5,6,7,8,9]) >>> print a [1 2 3 4 5 6 7 8 9] 取数组前3个值 b =a[:3] >>> print b [1 2 3] 取前3个以后的值 b =a[3:] >>> print b [4 5 6 7 8 9] 取数组的后3个值 b =a[-3:] >>> print b [7 8 9] 取数组后3个以前
-
python 三种方法提取pdf中的图片
有时我们需要将一份或者多份PDF文件中的图片提取出来,如果采取在线的网站实现的话又担心图片泄漏,手动操作又觉得麻烦,其实用Python也可以轻松搞定! 今天就跟大家系统分享几种Python提取 PDF 图片的方法.其实没有非常完美的方法,每种方法提取效率都不是百分之百,因此可以考虑用多种方法进行互补,主要将涉及: 基于 fitz 库和正则搜索提取图片 基于 pdf2image 库的两种方法提取图片 基于 fitz 库和正则搜索 fitz 是 pymupdf 的子模块,需要先用命令行安装 pymu
-
python实现pptx批量向PPT中插入图片
目录 项目背景 基础 加亿点点细节 最终代码 项目结果图 总结 项目背景 实验结果拍摄了一组图片,数量较大,想要按顺序组合排版,比较简单的方式是在PPT中插入图片进行排版.但是PPT批量插入图片后,顺序打乱且不显示图片名称,每个图片单独调整位置和大小费时费力,于是想到使用工具批量操作.过去了解过python自动化办公模块,相对来说python也是简单易用的语言,项目预计不会耗费太大精力,故尝试学习实践一番.(非专业学习笔记分享,望各位大佬不吝指导!) 数据为16组实验,每组实验重复两次,共32个
-
Python提取PDF中的图片的实现示例
目录 1.导入相关库 2.具体实现 2.1.使用正则表达式查找PDF中的图片 2.2.打印PDF的相关信息 2.3.遍历PDF中的对象,遇到是图像才进行下一步,不然就continue 2.4.将图像存为png格式 2.5.输入pdf路径,即可运行 3.结果预览 3.1.程序结果 3.2.原本的pdf 3.3.提取出来的图片 1.导入相关库 import fitz import time import re import os 2.具体实现 为了方便和其他模块组合,我直接写了个函数完成这个功能,实
-
12个步骤教你理解Python装饰器
前言 或许你已经用过装饰器,它的使用方式非常简单但理解起来困难(其实真正理解的也很简单),想要理解装饰器,你需要懂点函数式编程的概念,python函数的定义以及函数调用的语法规则等,虽然我没法把装饰器变得简单,但是我希望可以通过下面的步骤让你由浅入深明白装饰器是什么.假定你拥有最基本的Python知识,本文阐述的东西可能对那些在工作中经常接触Python的人有很大的帮助. 1.函数(Functions) 在Python里,函数是用def关键字后跟一个函数名称和一个可选的参数表列来创建的,可以用关
-
Python使用正则表达式获取网页中所需要的信息
使用正则表达式的几个步骤: 1.用import re 导入正则表达式模块: 2.用re.compile()函数创建一个Regex对象: 3.用Regex对象的search()或findall()方法,传入想要查找的字符串,返回一个Match对象: 4.调用Match对象的group()方法,返回匹配到的字符串. 在交互式环境中简单尝试一下,查询字符串中的固话: import re text = '小明家的固话是0755-123456,而小丽家的固话时0789-654321,小王家的电话是1234