C和C++的区别详解
目录
- 通过程序来介绍
- 1.iostream文件
- 2.头文件名的区别
- C语言
- C++
- 3.名称空间namespace
- 封装性
- 4.使用cout进行C++的输出
- 指针和数组名的区别
- 反汇编查看区别
- 结论
- 解引用
- 结论
- const的区别
- C语言中为常变量
- C++中的const
- 声明时const位置不同的区别
- const修饰形参
- 引用的原理
- 引用变量
- 常问问题
- 动态申请空间的区别
- C语言
- C++
- 面向过程和面向对象
- C语言
- C++
- 总结
通过程序来介绍
//c++ program
#include<iostream>
using namespace std;
int main(void)
{
cout << "This is a c++ program." << endl;
return 0;
}
1.iostream文件
iostream中的io指的是输入(进入程序的信息)和输出(从程序中发送出去的信息)。
并且c++的输入、输出方案涉及iostream文件中的多个定义。比如用来输出信息的cout就在其中。
2.头文件名的区别
C语言
C语言的传统是头文件使用扩展名 h,将其作为一种通过名称标识文件类型的简单方式。例如 math.h支持一些数学函数。
C++
C++头文件没有扩展名。
有些C头文件被转换成C++头文件,这些文件被重新命名,去掉了扩展名h,并在文件名称前面加上前缀c(表示来自C语言)
3.名称空间namespace
如果使用的是iostream,而不是iostream.h,则应使用名称空间编译指令来使iostream中的定义对程序可用,即
using namespace std;
有了这句using编译指令,才能使用cout、cin等,或者用第二种方式:
using std::cout; using std::cin; using std::endl;
名称空间是C++的特性之一,简单理解为:可以将自己的产品封装起来。
示例
封装性
示例:
首先定义一个头文件

在里面写上我们自己编的东西:
#pragma once
namespace AA
{
typedef int INT;
typename char CHAR;
};
然后在cpp文件中引入该头文件,但我们却无法使用之前写好的东西。

INT a会报错,因为我们只引入了头文件,没有使用里面的名称空间。
正确做法:
//c++ program
#include<iostream>
#include"AA.h"
using namespace std;
using namespace AA;
//using AA::INT;
int main(void)
{
INT a = 10;
cout << a << endl;
return 0;
}
需要第六行的该名称空间才可以使用其中的产品。或者可以用第七行这种写法来确定自己只需要哪个产品。
运行结果:

4.使用cout进行C++的输出
上面的程序有这条C++语句:
cout << "This is a C++ program." << endl;
<<符号表示该语句将把这个字符串发送给cout,该符号指出了信息流动路径。 cout是一个预定义的对象。
从概念上看,输出是一个流,即从程序流出的一系列字符。cout对象表示这种流,其属性是在iostream文件中定义的。
cout的对象属性包括一个插入运算符(<<),它可以将其右侧的信息插入到流中。
图示

指针和数组名的区别
程序示例:
#include<iostream>
using namespace std;
int main(void)
{
int a = 10;
int* p = &a;
int arr[] = { 0,1,2,3,4 };
cout << p << endl;
cout << arr << endl;
return 0;
}
这里定义了一个指针p和一个数组arr。
运行结果都是地址

反汇编查看区别
cout << p << endl;
cout << p << endl; 008F52AF mov esi,esp 008F52B1 push offset std::endl<char,std::char_traits<char> > (08F103Ch) 008F52B6 mov edi,esp 008F52B8 mov eax,dword ptr [p] 008F52BB push eax
cout << arr << endl;
cout << arr << endl; 008F52DE mov esi,esp 008F52E0 push offset std::endl<char,std::char_traits<char> > (08F103Ch) 008F52E5 mov edi,esp 008F52E7 lea eax,[arr] 008F52EA push eax
区别

在输出指针时,需要先从p里面取出四字节,再放到寄存器里push;
在输出arr时,直接把arr放到寄存器里再push。
结论
指针是变量;
数组名是一个地址——常量。
解引用
在C语言中学到,对指针解引用后得到的值就是它寸的地址对应的变量值。
可以来探索原理
程序示例
#include<iostream>
using namespace std;
int main(void)
{
int a = 10;
int* p = &a;
*p = 20;
return 0;
}
反汇编代码:
int a = 10; 000D18FF mov dword ptr [a],0Ah int* p = &a; 000D1906 lea eax,[a] 000D1909 mov dword ptr [p],eax *p = 20; 000D190C mov eax,dword ptr [p] 000D190F mov dword ptr [eax],14h
对于*p = 20
先从p的内存中取四个字节,即变量a的地址放入寄存器,再将20给到寄存器所存的的四字节中。完成对变量a的改变。
所以解引用的意思就是从地址中把值取出来,这里是去p的地址里取出所存的变量a的地址。
程序示例2:
#include<iostream>
using namespace std;
int main(void)
{
int a = 10, b = 20;
int* p = &a;
b = *p;
return 0;
}
反汇编代码:
int a = 10, b = 20; 000818FF mov dword ptr [a],0Ah 00081906 mov dword ptr [b],14h int* p = &a; 0008190D lea eax,[a] 00081910 mov dword ptr [p],eax b = *p; 00081913 mov eax,dword ptr [p] 00081916 mov ecx,dword ptr [eax] 00081918 mov dword ptr [b],ecx
对于 b = *p;
1.先去p里取出四字节放入寄存器
2.再从寄存器eax取出四字节放入寄存器ecx再把ecx
3.的内容放入到变量b的四字节中。
也可以看出:解引用这一步其实是去地址里取值的。
这样也可以得出:用一个变量赋值给另一个变量,其实也是在解引用。
示例:
#include<iostream>
using namespace std;
int main(void)
{
int a = 10;
int b;
b = a;
return 0;
}
反汇编:
int a = 10; 002D18F5 mov dword ptr [a],0Ah int b; b = a; 002D18FC mov eax,dword ptr [a] 002D18FF mov dword ptr [b],eax
对于 b = a;
也是从a地址里取出四字节放到寄存器,再通过寄存器给入b。
结论
解引用:到地址里去取值。
const的区别
C语言中为常变量
示例:
//const
#include<stdio.h>
int main(void)
{
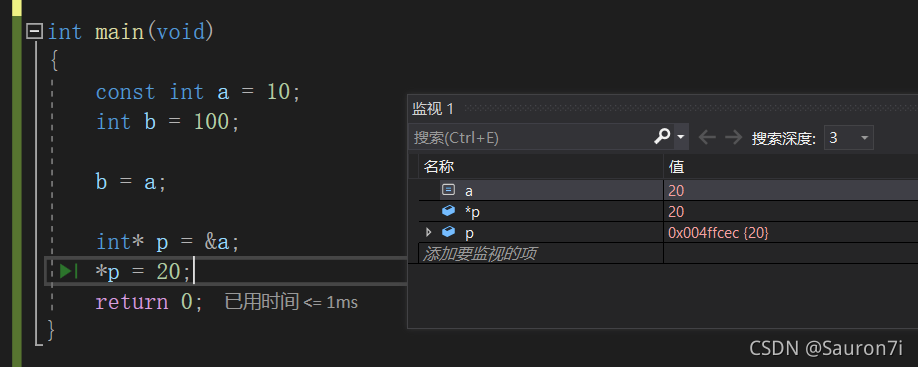
const int a = 10;
int b = 100; //常量赋值
b = a; //常变量赋值
return 0;
}
两次赋值的区别:
const int a = 10; 00311825 mov dword ptr [a],0Ah int b = 100; 0031182C mov dword ptr [b],64h b = a; 00311833 mov eax,dword ptr [a] 00311836 mov dword ptr [b],eax
常量赋值时,是直接把值给到b的四字节中;
用const修饰的a赋值时,还是需要从a里取出四字节再赋给b。
所以C语言中const修饰的变量叫做常变量——不能作为左值。
甚至可以用指针改变它的值:
#include<stdio.h>
int main(void)
{
const int a = 10;
int b = 100;
b = a;
int* p = &a;
*p = 20;
return 0;
}
a的变化:const修饰的变量a居然能被改变
C++中的const
在C++中,const修饰的变量就是常量,和常量性质一样:
在编译期间直接将常量的值替换到常量的使用点。
示例:
int main(void)
{
const int a = 10;
int b, c;
b = 16;
c = a;
return 0;
}
反汇编代码:
const int a = 10; 00B917F5 mov dword ptr [a],0Ah int b, c; b = 16; 00B917FC mov dword ptr [b],10h c = a; 00B91803 mov dword ptr [c],0Ah
可以看出,对b赋值常量是直接赋值;
对c赋值const修饰的变量a,同样是用常量赋值的。所以:
在C++中, const修饰的变量和常量性质一样,都是在编译期将常量值替换到常量的使用点。
另外
1.而且const修饰的变量必须初始化,同样因为编译期间就会替换为常量,不初始化,后面也没有机会再对其赋值。
2.如果用变量对const修饰的变量赋值,则会使其退化成常变量。
声明时const位置不同的区别
示例:
const可在不同位置修饰变量
int main(void)
{
int a = 10;
int* p1 = &a;
const int* p2 = &a;
int const* p3 = &a;
int* const p4 = &a;
int* q1 = &a;
const int* q2 = &a;
int const* q3 = &a;
int* const q4 = &a;
return 0;
}
要注意的是:
const与离他最近的类型结合,是该变量的类型,除了最近的类型,剩下的就是const修饰的内容。
const修饰的内容是不可作为左值。
根据上面的原理,来判断以下内容:
p1 = q1; p1 = q2; p1 = q3; p1 = q4; p2 = q1; p2 = q2; p2 = q3; p2 = q4; p3 = q1; p3 = q2; p3 = q3; p3 = q4; p4 = q1; p4 = q2; p4 = q3; p4 = q4;
p1是普通指针。
对于
const int* p2和int const* p3
const修饰的类型是离他最近的类型,即int,剩下的为const所修饰的内容,所以它们两个所修饰的内容为 *p2 、*p3。
对于int* const p4
const修饰的类型为int*,那修饰的内容就是p4。
下面的四个q同理。
可以推出错误的是:
p1 = q2; p1 = q3; p4 = q1; p4 = q2; p4 = q3; p4 = q4;
因为 *q2 和 *q3不能改变,所以把 q2/q3赋值给普通指针时,会造成普通指针来改变其中内容的后果,即 泄露常量地址给非常量指针 ,所以不能这样赋值。
p4为const修饰的内容,不能被改变。
const修饰形参
这里主要说能否形成函数重载的问题
程序示例:
int fun(int a)
{
return a;
}
int fun(const int a)
{
return a;
}
编译器并没有报错,但编译无法通过,原因如下

结论:如果const修饰的内容不包括指针,则不参与类型问题。
引用变量
之前C语言学到,&符号用来指示变量的地址。
C++给该符号赋予了另一个含义,将其用来声明引用。
示例,若我想用 A作为变量 a的别名,可以这样用:
#include<iostream>
using namespace std;
int main(void)
{
int a = 10;
int& A = a;
A = 20;
cout << a << endl;
cout << A << endl;
return 0;
}
运行示例:

通过A可以改变a的值,这就是引用。A相当于a的别名,就和鲁迅和周树人一样。。。
引用的原理
示例:
int a = 10; int& A = a; int* p = &a;
反汇编代码:
int& A = a; 00ED5326 lea eax,[a] 00ED5329 mov dword ptr [A],eax int* p = &a; 00ED532C lea eax,[a] 00ED532F mov dword ptr [p],eax
可以看出:引用的实现居然和指针是一样的。
所以引用的底层是一个指针。
结论:在使用到引用的地方,编译期会自动替换成底层指针的解引用。
常问问题
1.引用为什么必须初始化?
2.引用为什么一经过初始化,就无法改变引用的方向?
答:因为只有在初始化的时候能给它赋值,其他使用到它的地方都替换成了底层指针
无法改变底层指针的指向,所以无法改变引用的方向。
3.不能将const限定的变量赋给普通引用变量:
原因是将常量的地址赋给了普通指针。
const int a = 10; int& b = a; //错误
4.当引用一个不可以取地址的量的时候,使用常引用。
会生成一个临时量,然后常引用临时量,临时量都有常属性。
示例:
int& a = 10; //错误 const int& a = 10; //正确
动态申请空间的区别
C语言
使用malloc和free
示例:
int main(void)
{
//申请一维数组与释放
int* arr = (int*)malloc(sizeof(int) * 10);
if (arr == NULL)
return -1;
free(arr);
//申请二维数组与释放
int** brr = (int**)malloc(sizeof(int*) * 10);
if (brr == NULL)
return -1;
for (int i = 0; i < 10; ++i)
{
free(brr[i]);
}
return 0;
}
C++
int main(void)
{
//申请int类型变量
int* p = new int;
*p = 10;
delete p;
//申请int类型数组
int* arr = new int[10];
arr[0] = 10;
delete[]arr;
//申请二维数组
int** brr = new int* [5];
for (int i = 0; i < 5; ++i)
{
brr[i] = new int[10];
}
for (int i = 0; i < 5; ++i)
{
delete[]brr[i];
}
return 0;
}
new后面跟的类型就表示申请的大小。
面向过程和面向对象
C语言
面向过程语言
示例
void echo()
{
if (flag == 0)
{
printf("printf screen\n");
}
else if (flag == 1)
{
printf("printf file\n");
}
}
void Set_flag_file()
{
flag = 1;
}
void Set_flag_screen()
{
flag = 0;
}
对于这个打印函数,可以通过改变flag的值来控制其打印的结果。
但如果改变flag,也会改变其他地方调用的打印函数的结果。
所以C语言没有封装性。
C++
面向对象语言
class Note
{
public:
Note()
{
flag = 0;
}
void echo()
{
if (flag == 0)
{
printf("printf screen\n");
}
else if (flag == 1)
{
printf("printf file\n");
}
}
void Set_flag_file()
{
flag = 1;
}
void Set_flag_screen()
{
flag = 0;
}
private:
int flag;
};
使用示例:
int main(void)
{
Note n;
n.echo();
n.Set_flag_file();
n.echo();
return 0;
}
运行结果:

C语言作为面向过程语言,如果示例中的flag做出改变,会影响全局的改变。
C++作为半面向对象语言,具有封装性,若想改变示例中想打印的值,只会影响到这个模块。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
C++、C语言和JAVA开发的区别
1.面向对象没有java彻底. 由于C++要兼容C的内容,而C是面向过程的,所以C++不可避免地出现过程影子,并不算是完全的面向对象的程序设计语言.例如总得要有main或winmain之类的过程吧. 2.C++的移植能力没有java好. 由于C++的事实标准的存在,即各个编译器总存在差异,所以或多或少存 在不兼容.而且各个软件平台的C++启动代码和硬件指令不同,编译后的C++程序一般是不能跨平台的.而java从娘胎里出来就是为了跨平台执行的,不采 用二进制机器码作为最终代码,所以在移植方面较好.
-
C语言中const和C++中的const 区别详解
C语言中const和C++中的const 区别详解 C++的const和C语言的#define都可以用来定义常量,二者是有区别的,const是有数据类型的常量,而宏常量没有,编译器可以对前者进行静态类型安全检查,对后者仅是字符替换,没有类型安全检查. 而C语言中的const与C++也有很大的不同,在C语言中用const修饰的变量仍是一个变量,表示这个变量是只读的,不可显示地更改,而在C++中用const修饰过后,就变成常量了.例如下面的代码: const int n=10; int a[n];
-
详解C++中的const关键字及与C语言中const的区别
const对象默认为文件的局部变量,与其他变量不同,除非特别说明,在全局作用域的const变量时定义该对象的文件局部变量.此变量只存在于那个文件中中,不能别其他文件访问.要是const变量能在其他文件中访问,必须显示的指定extern(c中也是) 当你只在定义该const常量的文件中使用该常量时,c++不给你的const常量分配空间--这也是c++的一种优化措施,没有必要浪费内存空间来存储一个常量,此时const int c = 0:相当于#define c 0: 当在当前文件之外使用
-

面试常见问题之C语言与C++的区别问题
目录 C和C++的区别 关键字static在C和C++区别 1. 定义局部静态变量 2.限定访问区域 答案 结构体在C语言和C++的区别 C中malloc和C++的new区别 C++引用和C的指针有何区别 1.作为函数的参数 2.引用作为函数的返回值 C和C++的区别 C语言是一种结构化语言,其偏重于数据结构和算法,属于过程性语言 C++是面向对象的编程语言,其偏重于构造对象模型,并让这个模型能够契合与之对应的问题.其本质区别是解决问题的思想方法不同 虽然在语法上C++完全兼容C语言,但是两者还
-
C语言和C++的6点区别
C语言和C++的区别 (1)面向过程语言和面向对象语言 C语言是面向过程语言,即先分析出解决问题的步骤然后再将这些步骤一一实现 C++是面向对象语言,即把问题分成若干个对象,目的是为了描述某个事物在解决整个问题的步骤中的行为 (2)关键字不同 C语言中有32个关键字,而C++有63个关键字.另外在C语言中struct关键字定义的变量不能有函数,而在C++中可以有函数 (3)文件后缀名不同 C语言中源文件的后缀名是.c,C++源文件后缀名是.cpp (4)函数返回值不同 C语言中如果一个函数没有指
-
JS处理数据四舍五入(tofixed与round的区别详解)
1 .tofixed方法 toFixed() 方法可把 Number 四舍五入为指定小数位数的数字.例如将数据Num保留2位小数,则表示为:toFixed(Num):但是其四舍五入的规则与数学中的规则不同,使用的是银行家舍入规则,银行家舍入:所谓银行家舍入法,其实质是一种四舍六入五取偶(又称四舍六入五留双)法.具体规则如下: 简单来说就是:四舍六入五考虑,五后非零就进一,五后为零看奇偶,五前为偶应舍去,五前为奇要进一. 显然这种规则不符合我们平常在数据中处理的方式.为了解决这样的问题,可以自定义
-
AngularJS constant和value区别详解
angularJS可以通过constant(name,value)和value(name,value)对于创建服务也是很重要的. 相同点是:都可以接受两个参数,name和value. 区别: 1.constant(name,value)可以将一个已经存在的变量值注册为服务,并将其注入到应用的其他部分中.其中,name为注册的常量的名字,value为注册的常量的值或对象. 举例: (1)value为值时: angular.module('myApp') .constant('apiKey','12
-
基于python中staticmethod和classmethod的区别(详解)
例子 class A(object): def foo(self,x): print "executing foo(%s,%s)"%(self,x) @classmethod def class_foo(cls,x): print "executing class_foo(%s,%s)"%(cls,x) @staticmethod def static_foo(x): print "executing static_foo(%s)"%x a=A(
-
Oracle10个分区和Mysql分区区别详解
Oracle10g分区常用的是:range(范围分区).list(列表分区).hash(哈希分区).range-hash(范围-哈希分区).range-list(列表-复合分区). Range分区:Range分区是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,将记录存放到列值所在的range分区中. 如按照时间划分,2010年1月的数据放到a分区,2月的数据放到b分区,在创建的时候,需要指定基于的列,以及分区的范围值. 在按时间分区时,如果某些记录暂无法预测范围,可以创建m
-
基于DOM节点删除之empty和remove的区别(详解)
要移除页面上节点是开发者常见的操作,jQuery提供了几种不同的方法用来处理这个问题,这里我们开仔细了解下empty和remove方法 empty 顾名思义,清空方法,但是与删除又有点不一样,因为它只移除了 指定元素中的所有子节点. 这个方法不仅移除子元素(和其他后代元素),同样移除元素里的文本.因为,根据说明,元素里任何文本字符串都被看做是该元素的子节点.请看下面的HTML: <div class="hello"><p>这是p标签</p></
-
node.js中grunt和gulp的区别详解
node.js中grunt和gulp的区别详解 自nodeJS登上前端舞台,自动化构建变得越来越流行.目前最流行的当属grunt和gulp,这两个光看名字挺像,功能也差不多,不过gulp能在grunt这位大哥如日中天的境况下开辟出自己的一片天地,有着她独到的优点. 易用 Gulp相比Grunt更简洁,而且遵循代码优于配置策略,维护Gulp更像是写代码. 高效 Gulp相比Grunt更有设计感,核心设计基于Unix流的概念,通过管道连接,不需要写中间文件. 高质量 Gulp的每个插件只完成一个功能
-
基于js中this和event 的区别(详解)
今天在看javascript入门经典-事件一章中看到了 this 和 event 两种传参形式.因为作为一个初级的前端开发人员平时只用过 this传参,so很想弄清楚,this和event的区别是什么,什么情况下用什么比较合适. onclick = changeImg(this) vs onclick = changeImg(event) <img src='usa.gif' onclick="changeImg(event)" /> <scrip
-
python dict.get()和dict['key']的区别详解
先看代码: In [1]: a = {'name': 'wang'} In [2]: a.get('age') In [3]: a['age'] --------------------------------------------------------------------------- KeyError Traceback (most recent call last) <ipython-input-3-a620cb7b172a> in <module>() ----&g
-
java 中同步、异步、阻塞和非阻塞区别详解
java 中同步.异步.阻塞和非阻塞区别详解 简单点说: 阻塞就是干不完不准回来,一直处于等待中,直到事情处理完成才返回: 非阻塞就是你先干,我先看看有其他事没有,一发现事情被卡住,马上报告领导. 我们拿最常用的send和recv两个函数来说吧... 比如你调用send函数发送一定的Byte,在系统内部send做的工作其实只是把数据传输(Copy)到TCP/IP协议栈的输出缓冲区,它执行成功并不代表数据已经成功的发送出去了,如果TCP/IP协议栈没有足够的可用缓冲区来保存你Copy过来的数据的话
-
iOS中setValue和setObject的区别详解
网上关于setValue和setObject的区别的文章很多,说的并不准确,首先我们得知道: setObject:ForKey: 是NSMutableDictionary特有的:setValue:ForKey:是KVC的主要方法 话不多说,上代码: - (void)viewDidLoad { [super viewDidLoad]; //setObject和setvalue的区别 NSMutableDictionary *dic = [NSMutableDictionary dictionary