基于Python Dash库制作酷炫的可视化大屏
目录
- 介绍
- 数据
- 大屏搭建
介绍
大家好,我是小F~
在数据时代,我们每个人既是数据的生产者,也是数据的使用者,然而初次获取和存储的原始数据杂乱无章、信息冗余、价值较低。
要想数据达到生动有趣、让人一目了然、豁然开朗的效果,就需要借助数据可视化。
以前给大家介绍过使用Streamlit库制作大屏,今天给大家带来一个新方法。
通过Python的Dash库,来制作一个酷炫的可视化大屏!
先来看一下整体效果,好像还不错哦。

主要使用Python的Dash库、Plotly库、Requests库。
其中Requests爬取数据,Plotly制作可视化图表,Dash搭建可视化页面。
原始数据是小F的博客数据,数据存储在MySqL数据库中。
如此看来,和Streamlit库的搭建流程,所差不多。
关于Dash库,网上的资料不是很多,基本上只能看官方文档和案例,下面小F简单介绍一下。
Dash是一个用于构建Web应用程序的高效Python框架,特别适合使用Python进行数据分析的人。
Dash是建立在Flask,Plotly.js和React.js之上,非常适合在纯Python中,使用高度自定义的用户界面,构建数据可视化应用程序。
相关文档
说明:https://dash.plotly.com/introduction
案例:https://dash.gallery/Portal/
源码:https://github.com/plotly/dash-sample-apps/
具体的大家可以去看文档学习,多动手练习。
下面就给大家讲解下如何通过Dash搭建可视化大屏~
数据
使用的数据是博客数据,主要是下方两处红框的信息。
通过爬虫代码爬取下来,存储在MySQL数据库中。

其中MySQL的安装,大家可以自行百度,都挺简单的。
安装好后,进行启用,以及创建数据库。
# 启动MySQL, 输入密码 mysql -u root -p # 创建名为my_database的数据库 create database my_database;
其它相关的操作命令如下所示。
# 显示MySQL中所有的数据库 show databases; # 选择my_database数据库 use my_database; # 显示my_database数据库中所有的表 show tables; # 删除表 drop table info; drop table `2021-12-26`; # 显示表中的内容, 执行SQL查询语句 select * from info; select * from `2021-12-26`;
搞定上面的步骤后,就可以运行爬虫代码。
数据爬取代码如下。这里使用到了pymysql这个库,需要pip安装下。
import requests
import re
from bs4 import BeautifulSoup
import time
import random
import pandas as pd
from sqlalchemy import create_engine
import datetime as dt
def get_info():
"""获取大屏第一列信息数据"""
headers = {
'User-Agent': 'Mozilla/5.0 (MSIE 10.0; Windows NT 6.1; Trident/5.0)',
'referer': 'https: // passport.csdn.net / login',
}
# 我的博客地址
url = 'https://blog.csdn.net/river_star1/article/details/121463591'
try:
resp = requests.get(url, headers=headers)
now = dt.datetime.now().strftime("%Y-%m-%d %X")
soup = BeautifulSoup(resp.text, 'lxml')
author_name = soup.find('div', class_='user-info d-flex flex-column profile-intro-name-box').find('a').get_text(strip=True)
head_img = soup.find('div', class_='avatar-box d-flex justify-content-center flex-column').find('a').find('img')['src']
row1_nums = soup.find_all('div', class_='data-info d-flex item-tiling')[0].find_all('span', class_='count')
row2_nums = soup.find_all('div', class_='data-info d-flex item-tiling')[1].find_all('span', class_='count')
level_mes = soup.find_all('div', class_='data-info d-flex item-tiling')[0].find_all('dl')[-1]['title'].split(',')[0]
rank = soup.find('div', class_='data-info d-flex item-tiling').find_all('dl')[-1]['title']
info = {
'date': now,#时间
'head_img': head_img,#头像
'author_name': author_name,#用户名
'article_num': str(row1_nums[0].get_text()),#文章数
'fans_num': str(row2_nums[1].get_text()),#粉丝数
'like_num': str(row2_nums[2].get_text()),#喜欢数
'comment_num': str(row2_nums[3].get_text()),#评论数
'level': level_mes,#等级
'visit_num': str(row1_nums[3].get_text()),#访问数
'score': str(row2_nums[0].get_text()),#积分
'rank': str(row1_nums[2].get_text()),#排名
}
df_info = pd.DataFrame([info.values()], columns=info.keys())
return df_info
except Exception as e:
print(e)
return get_info()
def get_type(title):
"""设置文章类型(依据文章名称)"""
the_type = '其他'
article_types = ['项目', '数据可视化', '代码', '图表', 'Python', '可视化', '数据', '面试', '视频', '动态', '下载']
for article_type in article_types:
if article_type in title:
the_type = article_type
break
return the_type
def get_blog():
"""获取大屏第二、三列信息数据"""
headers = {
'User-Agent': 'Mozilla/5.0 (MSIE 10.0; Windows NT 6.1; Trident/5.0)',
'referer': 'https: // passport.csdn.net / login',
}
base_url = 'https://blog.csdn.net/river_star1/article/list/'
resp = requests.get(base_url+"1", headers=headers, timeout=3)
max_page = int(re.findall(r'var listTotal = (\d+);', resp.text)[0])//40+1
df = pd.DataFrame(columns=['url', 'title', 'date', 'read_num', 'comment_num', 'type'])
count = 0
for i in range(1, max_page+1):
url = base_url + str(i)
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'lxml')
articles = soup.find("div", class_='article-list').find_all('div', class_='article-item-box csdn-tracking-statistics')
for article in articles[1:]:
a_url = article.find('h4').find('a')['href']
title = article.find('h4').find('a').get_text(strip=True)[2:]
issuing_time = article.find('span', class_="date").get_text(strip=True)
num_list = article.find_all('span', class_="read-num")
read_num = num_list[0].get_text(strip=True)
if len(num_list) > 1:
comment_num = num_list[1].get_text(strip=True)
else:
comment_num = 0
the_type = get_type(title)
df.loc[count] = [a_url, title, issuing_time, int(read_num), int(comment_num), the_type]
count += 1
time.sleep(random.choice([1, 1.1, 1.3]))
return df
if __name__ == '__main__':
# 今天的时间
today = dt.datetime.today().strftime("%Y-%m-%d")
# 连接mysql数据库
engine = create_engine('mysql+pymysql://root:123456@localhost/my_database?charset=utf8')
# 获取大屏第一列信息数据, 并写入my_database数据库的info表中, 如若表已存在, 删除覆盖
df_info = get_info()
print(df_info)
df_info.to_sql("info", con=engine, if_exists='replace', index=False)
# 获取大屏第二、三列信息数据, 并写入my_database数据库的日期表中, 如若表已存在, 删除覆盖
df_article = get_blog()
print(df_article)
df_article.to_sql(today, con=engine, if_exists='replace', index=True)
运行成功后,就可以去数据库查询信息了。
info表,包含日期、头图、博客名、文章数、粉丝数、点赞数、评论数、等级数、访问数、积分数、排名数。

日期表,包含文章地址、标题、日期、阅读数、评论数、类型。

其中爬虫代码可设置定时运行,info表为60秒,日期表为60分钟。
尽量不要太频繁,容易被封IP,或者选择使用代理池。
这样便可以做到数据实时更新。
既然数据已经有了,下面就可以来编写页面了。
大屏搭建
导入相关的Python库,同样可以通过pip进行安装。
from spider_py import get_info, get_blog from dash import dcc import dash from dash import html import pandas as pd import plotly.graph_objs as go from dash.dependencies import Input, Output import datetime as dt from sqlalchemy import create_engine from flask_caching import Cache import numpy as np
设置一些基本的配置参数,如数据库连接、网页样式、Dash实例、图表颜色。
# 今天的时间
today = dt.datetime.today().strftime("%Y-%m-%d")
# 连接数据库
engine = create_engine('mysql+pymysql://root:123456@localhost/my_database?charset=utf8')
# 导入css样式
external_css = [
"https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css",
"https://cdnjs.cloudflare.com/ajax/libs/skeleton/2.0.4/skeleton.min.css"
]
# 创建一个实例
app = dash.Dash(__name__, external_stylesheets=external_css)
server = app.server
# 可以选择使用缓存, 减少频繁的数据请求
# cache = Cache(app.server, config={
# 'CACHE_TYPE': 'filesystem',
# 'CACHE_DIR': 'cache-directory'
# })
# 读取info表的数据
info = pd.read_sql('info', con=engine)
# 图表颜色
color_scale = ['#2c0772', '#3d208e', '#8D7DFF', '#CDCCFF', '#C7FFFB', '#ff2c6d', '#564b43', '#161d33']
这里将缓存代码注释掉了,如有频繁的页面刷新请求,就可以选择使用。
def indicator(text, id_value):
"""第一列的文字及数字信息显示"""
return html.Div([
html.P(text, className="twelve columns indicator_text"),
html.P(id=id_value, className="indicator_value"),
], className="col indicator")
def get_news_table(data):
"""获取文章列表, 根据阅读排序"""
df = data.copy()
df.sort_values('read_num', inplace=True, ascending=False)
titles = df['title'].tolist()
urls = df['url'].tolist()
return html.Table([html.Tbody([
html.Tr([
html.Td(
html.A(titles[i], href=urls[i], target="_blank",))
], style={'height': '30px', 'fontSize': '16'})for i in range(min(len(df), 100))
])], style={"height": "90%", "width": "98%"})
# @cache.memoize(timeout=3590), 可选择设置缓存, 我没使用
def get_df():
"""获取当日最新的文章数据"""
df = pd.read_sql(today, con=engine)
df['date_day'] = df['date'].apply(lambda x: x.split(' ')[0]).astype('datetime64[ns]')
df['date_month'] = df['date'].apply(lambda x: x[:7].split('-')[0] + "年" + x[:7].split('-')[-1] + "月")
df['weekday'] = df['date_day'].dt.weekday
df['year'] = df['date_day'].dt.year
df['month'] = df['date_day'].dt.month
df['week'] = df['date_day'].dt.isocalendar().week
return df
# 导航栏的图片及标题
head = html.Div([
html.Div(html.Img(src='./assets/img.jpg', height="100%"), style={"float": "left", "height": "90%", "margin-top": "5px", "border-radius": "50%", "overflow": "hidden"}),
html.Span("{}博客的Dashboard".format(info['author_name'][0]), className='app-title'),
], className="row header")
# 第一列的文字及数字信息
columns = info.columns[3:]
col_name = ['文章数', '关注数', '喜欢数', '评论数', '等级', '访问数', '积分', '排名']
row1 = html.Div([
indicator(col_name[i], col) for i, col in enumerate(columns)
], className='row')
# 第二列
row2 = html.Div([
html.Div([
html.P("每月文章写作情况"),
dcc.Graph(id="bar", style={"height": "90%", "width": "98%"}, config=dict(displayModeBar=False),)
], className="col-4 chart_div",),
html.Div([
html.P("各类型文章占比情况"),
dcc.Graph(id="pie", style={"height": "90%", "width": "98%"}, config=dict(displayModeBar=False),)
], className="col-4 chart_div"),
html.Div([
html.P("各类型文章阅读情况"),
dcc.Graph(id="mix", style={"height": "90%", "width": "98%"}, config=dict(displayModeBar=False),)
], className="col-4 chart_div",)
], className='row')
# 年数统计, 我的是2019 2020 2021
years = get_df()['year'].unique()
select_list = ['每月文章', '类型占比', '类型阅读量', '每日情况']
# 两个可交互的下拉选项
dropDowm1 = html.Div([
html.Div([
dcc.Dropdown(id='dropdown1',
options=[{'label': '{}年'.format(year), 'value': year} for year in years],
value=years[1], style={'width': '40%'})
], className='col-6', style={'padding': '2px', 'margin': '0px 5px 0px'}),
html.Div([
dcc.Dropdown(id='dropdown2',
options=[{'label': select_list[i], 'value': item} for i, item in enumerate(['bar', 'pie', 'mix', 'heatmap'])],
value='heatmap', style={'width': '40%'})
], className='col-6', style={'padding': '2px', 'margin': '0px 5px 0px'})
], className='row')
# 第三列
row3 = html.Div([
html.Div([
html.P("每日写作情况"),
dcc.Graph(id="heatmap", style={"height": "90%", "width": "98%"}, config=dict(displayModeBar=False),)
], className="col-6 chart_div",),
html.Div([
html.P("文章列表"),
html.Div(get_news_table(get_df()), id='click-data'),
], className="col-6 chart_div", style={"overflowY": "scroll"})
], className='row')
# 总体情况
app.layout = html.Div([
# 定时器
dcc.Interval(id="stream", interval=1000*60, n_intervals=0),
dcc.Interval(id="river", interval=1000*60*60, n_intervals=0),
html.Div(id="load_info", style={"display": "none"},),
html.Div(id="load_click_data", style={"display": "none"},),
head,
html.Div([
row1,
row2,
dropDowm1,
row3,
], style={'margin': '0% 30px'}),
])
上面的代码,就是网页的布局,效果如下。
网页可以划分为三列。第一列为info表中的数据展示,第二、三列为博客文章的数据展示。
相关的数据需要通过回调函数进行更新,这样才能做到实时刷新。
各个数值及图表的回调函数代码如下所示。
# 回调函数, 60秒刷新info数据, 即第一列的数值实时刷新
@app.callback(Output('load_info', 'children'), [Input("stream", "n_intervals")])
def load_info(n):
try:
df = pd.read_sql('info', con=engine)
return df.to_json()
except:
pass
# 回调函数, 60分钟刷新今日数据, 即第二、三列的数值实时刷新(爬取文章数据, 并写入数据库中)
@app.callback(Output('load_click_data', 'children'), [Input("river", "n_intervals")])
def cwarl_data(n):
if n != 0:
df_article = get_blog()
df_article.to_sql(today, con=engine, if_exists='replace', index=True)
# 回调函数, 第一个柱状图
@app.callback(Output('bar', 'figure'), [Input("river", "n_intervals")])
def get_bar(n):
df = get_df()
df_date_month = pd.DataFrame(df['date_month'].value_counts(sort=False))
df_date_month.sort_index(inplace=True)
trace = go.Bar(
x=df_date_month.index,
y=df_date_month['date_month'],
text=df_date_month['date_month'],
textposition='auto',
marker=dict(color='#33ffe6')
)
layout = go.Layout(
margin=dict(l=40, r=40, t=10, b=50),
yaxis=dict(gridcolor='#e2e2e2'),
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)',
)
return go.Figure(data=[trace], layout=layout)
# 回调函数, 中间的饼图
@app.callback(Output('pie', 'figure'), [Input("river", "n_intervals")])
def get_pie(n):
df = get_df()
df_types = pd.DataFrame(df['type'].value_counts(sort=False))
trace = go.Pie(
labels=df_types.index,
values=df_types['type'],
marker=dict(colors=color_scale[:len(df_types.index)])
)
layout = go.Layout(
margin=dict(l=50, r=50, t=50, b=50),
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)',
)
return go.Figure(data=[trace], layout=layout)
# 回调函数, 左下角热力图
@app.callback(Output('heatmap', 'figure'),
[Input("dropdown1", "value"), Input('river', 'n_intervals')])
def get_heatmap(value, n):
df = get_df()
grouped_by_year = df.groupby('year')
data = grouped_by_year.get_group(value)
cross = pd.crosstab(data['weekday'], data['week'])
cross.sort_index(inplace=True)
trace = go.Heatmap(
x=['第{}周'.format(i) for i in cross.columns],
y=["星期{}".format(i+1) if i != 6 else "星期日" for i in cross.index],
z=cross.values,
colorscale="Blues",
reversescale=False,
xgap=4,
ygap=5,
showscale=False
)
layout = go.Layout(
margin=dict(l=50, r=40, t=30, b=50),
)
return go.Figure(data=[trace], layout=layout)
# 回调函数, 第二个柱状图(柱状图+折线图)
@app.callback(Output('mix', 'figure'), [Input("river", "n_intervals")])
def get_mix(n):
df = get_df()
df_type_visit_sum = pd.DataFrame(df['read_num'].groupby(df['type']).sum())
df['read_num'] = df['read_num'].astype('float')
df_type_visit_mean = pd.DataFrame(df['read_num'].groupby(df['type']).agg('mean').round(2))
trace1 = go.Bar(
x=df_type_visit_sum.index,
y=df_type_visit_sum['read_num'],
name='总阅读',
marker=dict(color='#ffc97b'),
yaxis='y',
)
trace2 = go.Scatter(
x=df_type_visit_mean.index,
y=df_type_visit_mean['read_num'],
name='平均阅读',
yaxis='y2',
line=dict(color='#161D33')
)
layout = go.Layout(
margin=dict(l=60, r=60, t=30, b=50),
showlegend=False,
yaxis=dict(
side='left',
title='阅读总数',
gridcolor='#e2e2e2'
),
yaxis2=dict(
showgrid=False, # 网格
title='阅读平均',
anchor='x',
overlaying='y',
side='right'
),
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)',
)
return go.Figure(data=[trace1, trace2], layout=layout)
# 点击事件, 选择两个下拉选项, 点击对应区域的图表, 文章列表会刷新
@app.callback(Output('click-data', 'children'),
[Input('pie', 'clickData'),
Input('bar', 'clickData'),
Input('mix', 'clickData'),
Input('heatmap', 'clickData'),
Input('dropdown1', 'value'),
Input('dropdown2', 'value'),
])
def display_click_data(pie, bar, mix, heatmap, d_value, fig_type):
try:
df = get_df()
if fig_type == 'pie':
type_value = pie['points'][0]['label']
# date_month_value = clickdata['points'][0]['x']
data = df[df['type'] == type_value]
elif fig_type == 'bar':
date_month_value = bar['points'][0]['x']
data = df[df['date_month'] == date_month_value]
elif fig_type == 'mix':
type_value = mix['points'][0]['x']
data = df[df['type'] == type_value]
else:
z = heatmap['points'][0]['z']
if z == 0:
return None
else:
week = heatmap['points'][0]['x'][1:-1]
weekday = heatmap['points'][0]['y'][-1]
if weekday == '日':
weekday = 7
year = d_value
data = df[(df['weekday'] == int(weekday)-1) & (df['week'] == int(week)) & (df['year'] == year)]
return get_news_table(data)
except:
return None
# 第一列的数值
def update_info(col):
def get_data(json, n):
df = pd.read_json(json)
return df[col][0]
return get_data
for col in columns:
app.callback(Output(col, "children"),
[Input('load_info', 'children'), Input("stream", "n_intervals")]
)(update_info(col))
图表的数据和样式全在这里设置,两个下拉栏的数据交互也在这里完成。

需要注意右侧下拉栏的类型,需和你所要点击图表类型一致,这样文章列表才会更新。
每日情况对应热力图,类型阅读量对应第二列第三个图表,类型占比对应饼图,每月文章对应第一个柱状图的点击事件。
最后启动程序代码。
if __name__ == '__main__':
# debug模式, 端口7777
app.run_server(debug=True, threaded=True, port=7777)
# 正常模式, 网页右下角的调试按钮将不会出现
# app.run_server(port=7777)
这样就能在本地看到可视化大屏页面,浏览器打开如下地址。
http://127.0.0.1:7777
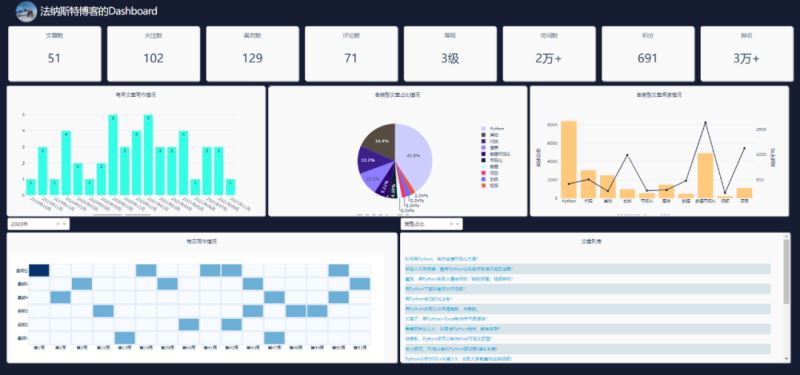
对于网页的布局、背景颜色等,主要通过CSS进行设置。
这一部分可能是大家所要花费时间去理解的。
body{
margin:0;
padding: 0;
background-color: #161D33;
font-family: 'Open Sans', sans-serif;
color: #506784;
-webkit-user-select: none; /* Chrome all / Safari all */
-moz-user-select: none; /* Firefox all */
-ms-user-select: none; /* IE 10+ */
user-select: none; /* Likely future */
}
.modal {
display: block; /*Hidden by default */
position: fixed; /* Stay in place */
z-index: 1000; /* Sit on top */
left: 0;
top: 0;
width: 100%; /* Full width */
height: 100%; /* Full height */
overflow: auto; /* Enable scroll if needed */
background-color: rgb(0,0,0); /* Fallback color */
background-color: rgba(0,0,0,0.4); /* Black w/ opacity */
}
.modal-content {
background-color: white;
margin: 5% auto; /* 15% from the top and centered */
padding: 20px;
width: 30%; /* Could be more or less, depending on screen size */
color:#506784;
}
._dash-undo-redo {
display: none;
}
.app-title{
color:white;
font-size:3rem;
letter-spacing:-.1rem;
padding:10px;
vertical-align:middle
}
.header{
margin:0px;
background-color:#161D33;
height:70px;
color:white;
padding-right:2%;
padding-left:2%
}
.indicator{
border-radius: 5px;
background-color: #f9f9f9;
margin: 10px;
padding: 15px;
position: relative;
box-shadow: 2px 2px 2px lightgrey;
}
.indicator_text{
text-align: center;
float: left;
font-size: 17px;
}
.indicator_value{
text-align:center;
color: #2a3f5f;
font-size: 35px;
}
.add{
height: 34px;
background: #119DFF;
border: 1px solid #119DFF;
color: white;
}
.chart_div{
background-color: #f9f9f9;
border-radius: 5px;
height: 390px;
margin:5px;
padding: 15px;
position: relative;
box-shadow: 2px 2px 2px lightgrey;
}
.col-4 {
flex: 0 0 32.65%;
max-width: 33%;
}
.col-6 {
flex: 0 0 49.3%;
max-width: 50%;
}
.chart_div p{
color: #2a3f5f;
font-size: 15px;
text-align: center;
}
td{
text-align: left;
padding: 0px;
}
table{
border: 1px;
font-size:1.3rem;
width:100%;
font-family:Ubuntu;
}
.tabs_div{
margin:0px;
height:30px;
font-size:13px;
margin-top:1px
}
tr:nth-child(even) {
background-color: #d6e4ea;
-webkit-print-color-adjust: exact;
}
如今低代码平台的出现,或许以后再也不用去写烦人的HTML、CSS等。拖拖拽拽,即可轻松完成一个大屏的制作。
好了,今天的分享到此结束,大家可以自行去动手练习。
参考链接:
https://github.com/ffzs/dash_blog_dashboard
https://github.com/plotly/dash-sample-apps/tree/main/apps/dash-oil-and-gas
以上就是基于Python Dash库制作酷炫的可视化大屏的详细内容,更多关于Python Dash库制作可视化大屏的资料请关注我们其它相关文章!
相关推荐
-

Python机器学习之使用Pyecharts制作可视化大屏
目录 前言 Pyecharts可视化 Map世界地图 柱状图.饼图 Pyecharts组合图表 总结 前言 ECharts是由百度开源的基于JS的商业级数据图表库,有很多现成的图表类型和实例,而Pyecharts则是为了方便我们使用Python实现ECharts的绘图.使用Pyecharts制作可视化大屏,可以分为两步: 1.使用分别Pyecharts分别制作各类图形: 2.使用Pyecharts中的组合图表功能,将所有图片拼接在一张html文件中进行展示. 小五认为影响大屏美观最重要的两个因素
-
python可视化大屏库big_screen示例详解
目录 big_screen 特点 安装环境 输入数据 本地运行 在线部署 对于从事数据领域的小伙伴来说,当需要阐述自己观点.展示项目成果时,我们需要在最短时间内让别人知道你的想法.我相信单调乏味的语言很难让别人快速理解.最直接有效的方式就是将数据如上图所示这样,进行可视化展现. 具体如下: big_screen 特点 便利性工具, 结构简单, 你只需传数据就可以实现数据大屏展示. 安装环境 pip install -i https://pypi.tuna.tsinghua.edu.cn/simp
-
基于Python Dash库制作酷炫的可视化大屏
目录 介绍 数据 大屏搭建 介绍 大家好,我是小F- 在数据时代,我们每个人既是数据的生产者,也是数据的使用者,然而初次获取和存储的原始数据杂乱无章.信息冗余.价值较低. 要想数据达到生动有趣.让人一目了然.豁然开朗的效果,就需要借助数据可视化. 以前给大家介绍过使用Streamlit库制作大屏,今天给大家带来一个新方法. 通过Python的Dash库,来制作一个酷炫的可视化大屏! 先来看一下整体效果,好像还不错哦. 主要使用Python的Dash库.Plotly库.Requests库. 其中R
-
Python+Kepler.gl轻松制作酷炫路径动画的实现示例
1. 简介 Kepler.gl相信很多人都听说过,作为Uber几年前开源的交互式地理信息可视化工具,kepler.gl依托WebGL强大的图形渲染能力,可以在浏览器端以多种形式轻松展示大规模数据集. 更令人兴奋的是Kepler.gl在去年推出了基于Python的接口库keplergl,结合jupyter notebook/jupyter lab的相关拓展插件,使得我们可以通过编写Python程序配合Kepler.gl更灵活地制作各种可视化作品. 而随着近期keplergl的更新,更多的新特性得以
-
Python 代码实现各种酷炫功能
目录 一.生成二维码 二.生成词云 三.批量抠图 四.文字情绪识别 五.识别是否带了口罩 六.简易信息轰炸 七.识别图片中的文字 八.简单的小游戏 一.生成二维码 二维码又称二维条码,常见的二维码为QR Code,QR全称Quick Response,是一个近几年来移动设备上超流行的一种编码方式,而生成一个二维码也非常简单,在Python中我们可以通过MyQR模块了生成二维码,而生成一个二维码我们只需要2行代码,我们先安装MyQR模块,这里选用国内的源下载: pip install qrcode
-
基于 Vue.js 2.0 酷炫自适应背景视频登录页面实现方式
本文讲述如何实现拥有酷炫背景视频的登录页面,浏览器窗口随意拉伸,背景视频及前景登录组件均能完美适配,背景视频可始终铺满窗口,前景组件始终居中,视频的内容始终得到最大限度的保留,可以得到最好的视觉效果.并且基于 Vue.js 2.0 全家桶.具体效果如下图所示: 最终效果可以翻到文章最后观看. 1. 背景视频 Web 页面的既有实现方式 国外有一个很好的网站 「Coverr」 ,提供了完善的教程和视频资源,帮助前端开发者构建酷炫的背景视频主页,网站效果示例如下图所示: 教程如下所示: 从图中以及我
-
基于python requests库中的代理实例讲解
直接上代码: #request代理(proxy) """ 1.启动代理服务器Heroku,相当于aliyun 2.在主机1080端口启动Socks 服务 3.将请求转发到1080端口 4.获取相应资源 首先要安装包pip install 'requests[socksv5]' """ import requests #定义一个代理服务器,所有的http及https都走socks5的协议,sock5相当于http协议,它是在会话层 #把它转到本机的
-
基于python的matplotlib制作双Y轴图
一.函数介绍 函数:twin()函数 含义:表示共享x轴,共享表示的就是x轴使用同一刻度 二.实际应用 2.1 实验数据展示 数据表的名称:600001SH.xlsx 2.2 代码实现: 文章里使用到了Subplot()函数 # 导入相关数据包 import matplotlib.pyplot as plt import pandas as pd plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体 plt.rcParams['axes.unic
-
教你如何使用Python Tkinter库制作记事本
Tkinter库制作记事本 现在为了创建这个记事本,你的系统中应该已经安装了 Python 3 和 Tkinter.您可以根据系统要求下载合适的python 包.成功安装 python 后,您需要安装 Tkinter(一个 Python 的 GUI 包). 使用此命令安装 Tkinter : pip install python-tk 导入 Tkinter : import tkinter import os from tkinter import * from tkinter.messageb
-
基于Python matplotlib库绘制箱线图
目录 1. 关于箱线图 及 plt.boxplot()方法 2. 绘制一幅简单的箱线图 3. 绘制一幅更精致的图像 4. 异常值的标准 5. 异常值的输出 1. 关于箱线图 及 plt.boxplot()方法 箱线图又称箱形图,有的地方也可以叫盒须图.使用箱线图的好处是可以以一种相对稳定的方式描述数据离散分布情况,识别数据中的异常值. 在pthon的matplotlib库中绘制箱线图使用的是plt.boxplot()方法. 该方法的主要参数如下 参数 描述 x 要绘制箱线图的数据 notch 是