详解python爬取弹幕与数据分析
很不幸的是,由于疫情的关系,原本线下的AWD改成线上CTF了。这就很难受了,毕竟AWD还是要比CTF难一些的,与人斗现在变成了与主办方斗。
虽然无奈归无奈,但是现在还是得打起精神去面对下一场比赛。这个开始也是线下的,决赛地点在南京,后来是由于疫情的关系也成了线上。
当然,比赛内容还是一如既往的得现学,内容是关于大数据的。
由于我们学校之前并没有开设过相关培训,所以也只能自己琢磨了。
好了,废话先不多说了,正文开始。
一.比赛介绍
大数据总体来说分为三个过程。
第一个过程是搭建hadoop环境。
这个开始我也挺懵的,不过后来看了个教程大概懂了。总的来说,hadoop就是一个集成环境,这个环境里面包含了很多软件。
这些软件的功能各不相同,比如文件分布式(原谅我也忘了叫啥),大概作用就是假设你电脑有1个g大小,但是一个文件有10个g,那么你就可以用这个系统,将文件割成10份分别储存。
总的来说,就是为了大数据而服务的一个环境。
第二个过程就是爬取数据。
这个依据比赛的要求而定,我记得初赛的时候是要求爬取一个开源的电商网站,名字好像是SHOPXO。这个有爬虫的基础的同学可以去试下。
决赛还没比,不过好像是要爬取视频的弹幕。这个要比单纯的爬取视频麻烦一点,因为每个网站对弹幕的算法不一样。
一会儿我会写两个爬虫,分别爬取B站和A站的弹幕你们就知道了。
第三个过程就是分析数据。
这个说实话我也不太清楚。分析这一步其实python就可以做,但是貌似又得在那个环境里做。。。挺懵的,所以这里就不详细写了。
在写这篇帖子之前,我还写过一篇关于awd比赛的东西。不过由于其中涉及到很多比较特殊的东西,暂时无法外传,所以我就先设置成私密的了。
关于大数据其实我和你们一样是新手,只不过以前因为一些需要刚好学过爬虫,因此我负责的就是第二块内容。接下来我也会通篇讲一些爬虫和数据分析的东西。
二.爬虫
这个可以说是大数据里面很重要的东西了,因为即使你前面分析做的再好,没有数据供你分析又有什么用呢?所以,学好爬虫。
爬虫其实是一种代称,只是功能比较特殊,所以这么叫。在没学过爬虫之前,先想想看,我们正常是如何获取一些信息呢?就比如我们想知道周杰伦的歌单都有什么的时候。
第一步肯定是去百度搜索周杰伦,然后我们就可以在qq音乐之类的音乐网站上看到周杰伦的歌单。爬虫也得这样。
它没有你想象的那么神奇,肯定是要在某些网站上操作才行。
接着,你就可以一点一点的记录下来周杰伦的信息。我们的爬虫实现的也是这样的过程,只不过你一秒钟只能访问一个页面,而爬虫一秒钟可以访问几万个页面。
好了,关于爬虫的更详细的东西就先不说了,我们不是专门讲爬虫的。csdn上面有很多写爬虫的教程,都很详细。
我们主要的目的是进行实战。
三.爬取网站弹幕
本来是想以网站视频信息作为题目的,但是那个实在是没啥难度,正好比赛用得到弹幕,干脆就讲讲弹幕怎么爬取吧。
1.A站
A站相对于B站要简单一点。我们先观察网页。比如,这个是我随便打开的一个视频。
现在网站上的这些数据大部分都是动态的,因此我们不能直接用html解析器来解析网页,得直接爬取xhr里面的数据。
先按F12抓包。然后我们在搜索栏中随便搜索一条我们的弹幕。
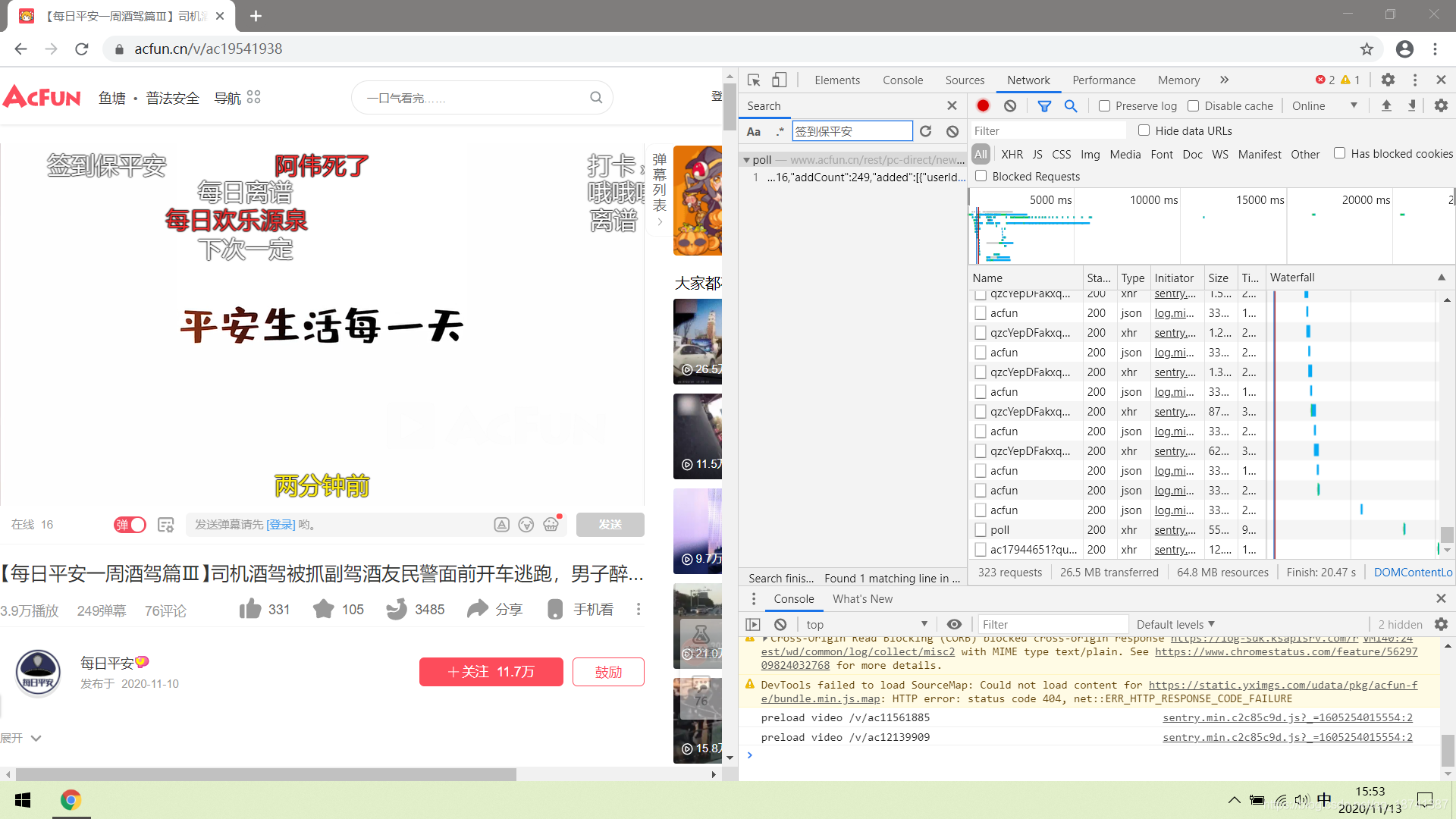
很幸运,只有一个。我们双击这个查找的结果并进行观察。点到privew,可以发现这里面包含了我们所有的弹幕。
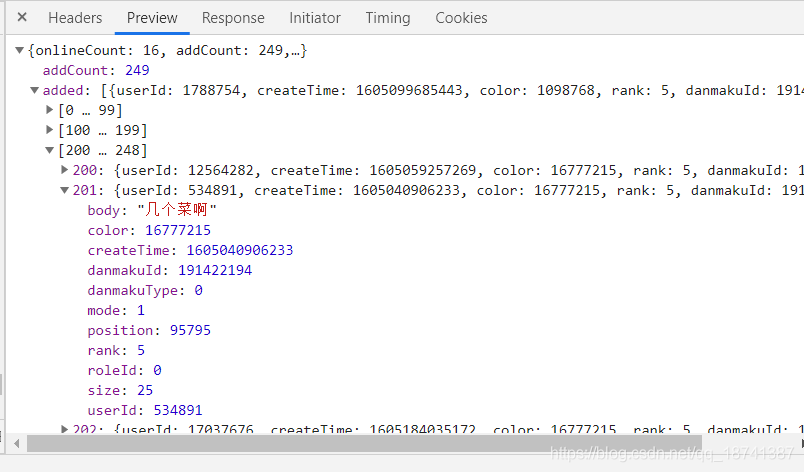
因此,这种网站直接爬取就行了。点到headers,我们观察参数以及请求方式。


ok。这些得到了以后,上脚本。
import requests
url="https://www.acfun.cn/rest/pc-direct/new-danmaku/poll"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36",
"cookie":""
#注意,cookie要填你自己的。A站有些特殊,爬取的时候需要加上cookie。
}
data={
"videoId":"15779946",
"lastFetchTime":"0",
"enableAdvanced":"true"
}
html=requests.post(url,headers=headers,data=data)
html=html.json()
html=html["added"]
for i in html:
print(i["body"])
效果如图。
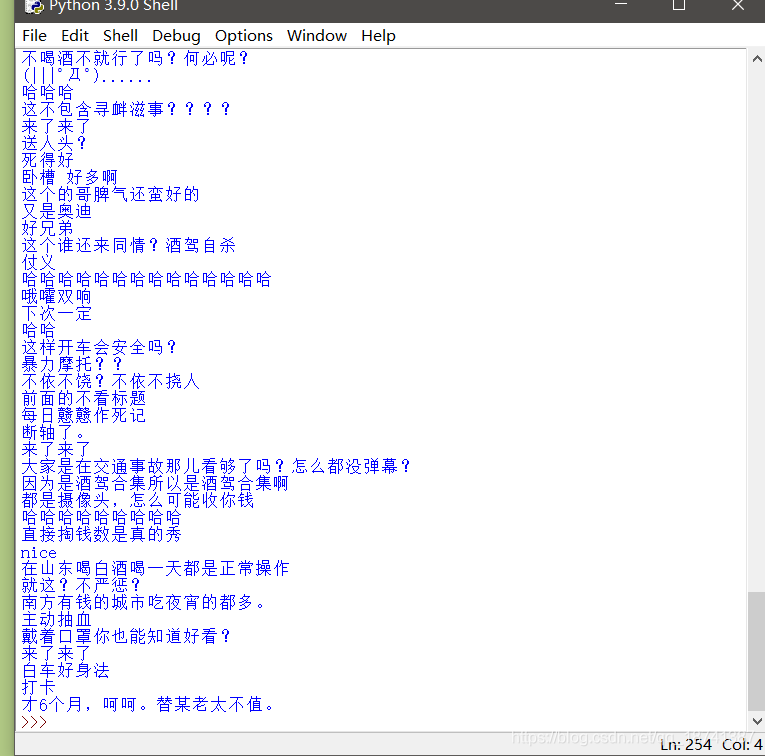
数量我数了一下,刚好是这个视频的弹幕数。你们可以添加自己的东西上去,比如增加写入文件啥的功能。
2.B站
这个有点特殊了。B站的弹幕是另一种算法。
B站将弹幕单独剥离出来到了一个网页上,需要视频对应的cid才可以获得到弹幕对应的码,然后获得视频的弹幕信息。举个例子:【哔哩哔哩2019拜年祭】
首先,我们要获取到视频的视频号以前是av号,现在是bv号。
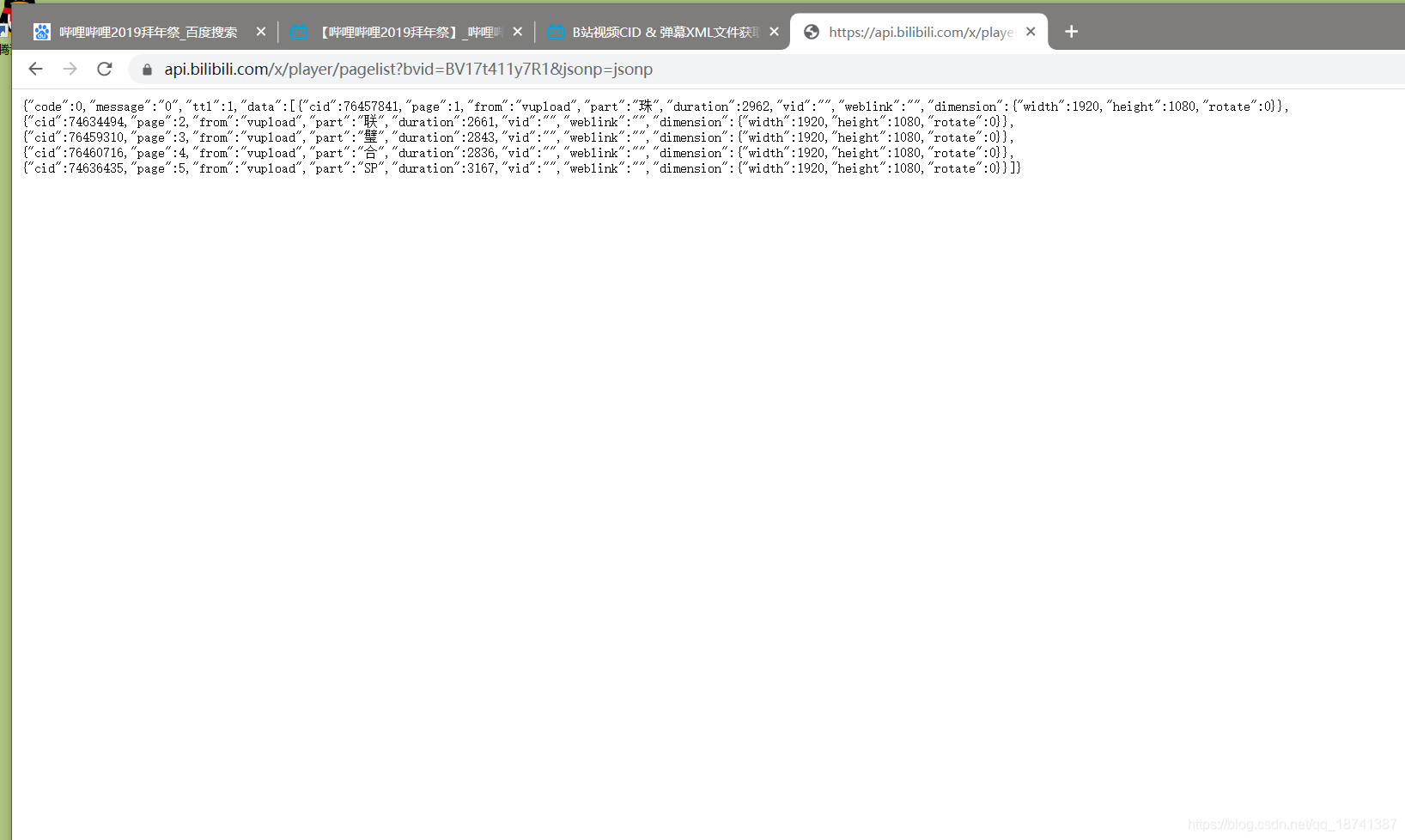
然后将这个链接加上你的bv号。这个是哔哩哔哩的一个api,可以获得cid。
https://api.bilibili.com/x/player/pagelist?bvid=BV17t411y7R1&jsonp=jsonp
将连接中的bvid换成bv号。
如图,我们发现了视频有4个cid。
接着我们使用下一个api,这样就可以获得弹幕了。
https://comment.bilibili.com/76457841.xml
将后面的数字换成刚找到的cid。
结果如图:
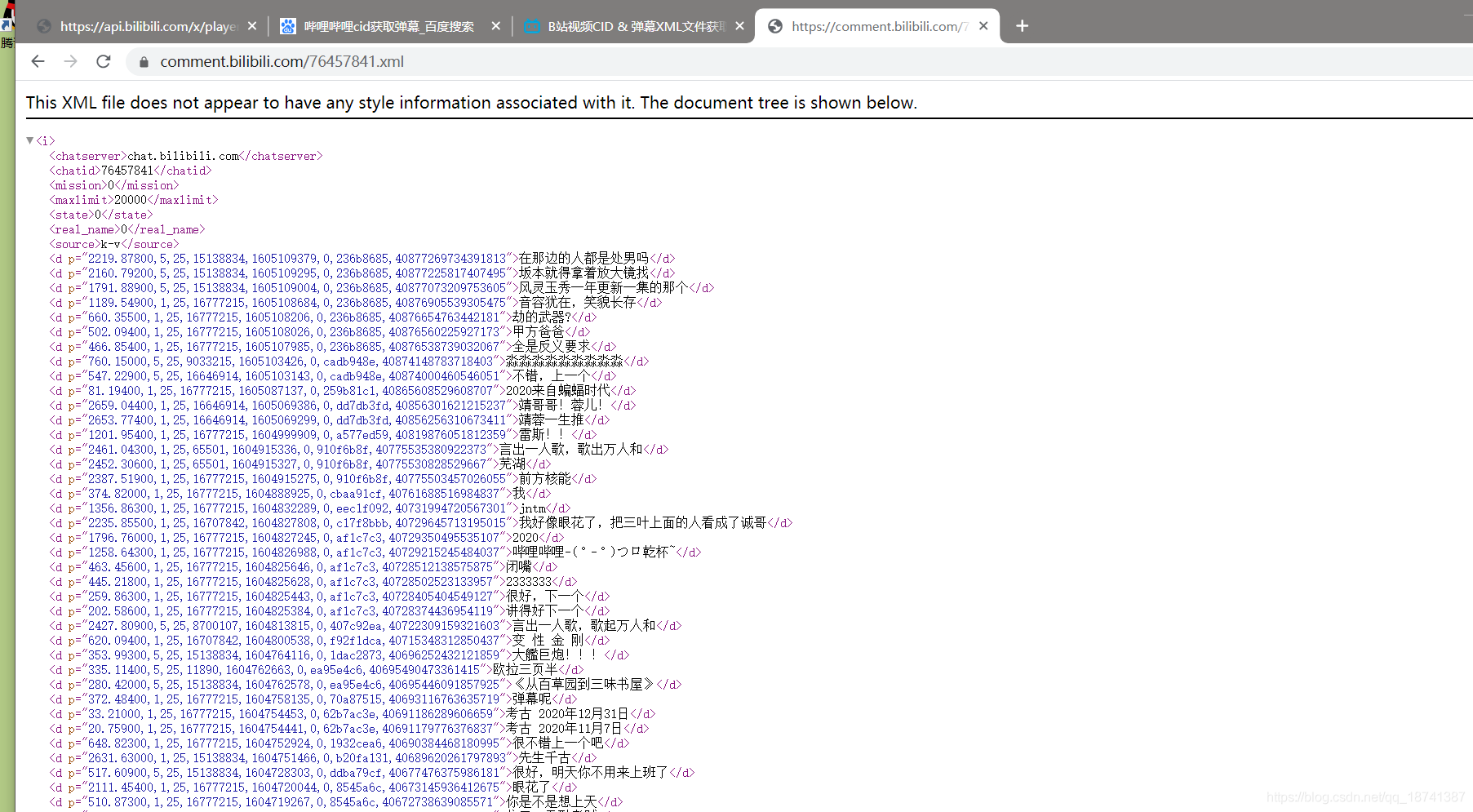
很好。这就是我们手动获得弹幕的流程,接下来就是用爬虫做出来就行了。
第一步,将bv转成av号。其实你可以直接用bv号,但是由于我做这个帖子之前的时候用的是av号找的,所以加了这么一步。
这一步直接去网上找工具就行了,有很多,就不往代码上面加了。
第二部,用刚才给的第二个api获得cid。我们使用爬虫即可,将网址构造成规定的格式。
https://www.bilibili.com/widget/getPageList?aid=?
问号换成aid。
第三步,爬取。可以看到我们最终返回的是一个xml文件,所以用爬虫里面的xml解析器解析即可。
别的就不废话了,直接上代码。有啥没看懂的评论区问。
import requests
from bs4 import BeautifulSoup
import lxml
aid=input("请输入av号:如果是bv码请转换为av号\n")
file_name=input("请输入保存文件名:\n")
f=open(file_name,"a",encoding='utf-8')
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36"
}
get_cid="https://www.bilibili.com/widget/getPageList?aid="+aid
cid_list=eval(requests.get(get_cid).text)
for cid in cid_list:
cid=cid["cid"]
xml="https://comment.bilibili.com/"+str(cid)+".xml"
html=requests.get(xml,headers=headers)
html.encoding=html.apparent_encoding
soup=BeautifulSoup(html.text,"xml").find_all("d")
for dm in soup:
f.write(dm.text+"\n")
f.close()
这个是直接将弹幕文件保存到本地了,为了方便后续的分析。结果如图。

一共是九万多条弹幕。
行了,剩下的就懒得写了。
四.数据分析
要说分析的话其实这个是很广的,得依据特定的要求来做。
先说说第一个,高频词统计。
代码是我copy的,简单但是好用。
(将上一步的文件放到和脚本同一个目录下)
import jieba.analyse f =open(r'bilibil周年庆.txt',encoding='utf-8')#打开文件 text=f.read() #读取文件 text_list=jieba.analyse.extract_tags(text,topK=40)#进行jieba分词,并且取频率出现最高的40个词 text_list=",".join(text_list)#用空格将这些字符串连接起来 print(text_list)
如图,40个出现字数最多的词汇就被统计出来了。

由于是机器识别,难免不准,所以不要在意这些莫名其妙出现的次。
在说说第二个,情感分析。这个是我猜测可能会用的到的东西。
我们这个可以直接用baiduAPI来做,要比我们自己的写的好。这个api会将所有的数据进行情感预测,并且返回积极或者消极的概率。
不过你首先得去申请一个百度api的账号。这个就不说了,百度有教程。
代码也是我copy的。首先感谢下原作者,写的真的很棒。
(原本是要两个脚本,我改进了一下,写成了一个脚本。这个脚本仅仅测试了两个词,如果想对文件进行分析,稍微改动一下就行了。)
import re
import requests
import json
# 将text按照lenth长度分为不同的几段
def cut_text(text, lenth):
textArr = re.findall('.{' + str(lenth) + '}', text)
textArr.append(text[(len(textArr) * lenth):])
return textArr # 返回多段值
def get_emotion(access_token,data): # 情感分析
# 定义百度API情感分析的token值和URL值
token = access_token
url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token={}'.format(token)
# 百度情感分析API的上限是2048字节,因此判断文章字节数小于2048,则直接调用
if (len(data.encode()) < 2048):
new_each = {
'text': data # 将文本数据保存在变量new_each中,data的数据类型为string
}
new_each = json.dumps(new_each)
res = requests.post(url, data=new_each) # 利用URL请求百度情感分析API
# print("content: ", res.content)
res_text = res.text # 保存分析得到的结果,以string格式保存
result = res_text.find('items') # 查找得到的结果中是否有items这一项
positive = 1
if (result != -1): # 如果结果不等于-1,则说明存在items这一项
json_data = json.loads(res.text)
negative = (json_data['items'][0]['negative_prob']) # 得到消极指数值
positive = (json_data['items'][0]['positive_prob']) # 得到积极指数值
print("positive:",positive)
print("negative:",negative)
# print(positive)
if (positive > negative): # 如果积极大于消极,则返回2
return 2
elif (positive == negative): # 如果消极等于积极,则返回1
return 1
else:
return 0 # 否则,返回0
else:
return 1
else:
data = cut_text(data, 1500) # 如果文章字节长度大于1500,则切分
# print(data)
sum_positive = 0.0 # 定义积极指数值总合
sum_negative = 0.0 # 定义消极指数值总和
for each in data: # 遍历每一段文字
# print(each)
new_each = {
'text': each # 将文本数据保存在变量new_each中
}
new_each = json.dumps(new_each)
res = requests.post(url, data=new_each) # 利用URL请求百度情感分析API
# print("content: ", res.content)
res_text = res.text # 保存分析得到的结果,以string格式保存
result = res_text.find('items') # 查找得到的结果中是否有items这一项
if (result != -1):
json_data = json.loads(res.text) # 如果结果不等于-1,则说明存在items这一项
positive = (json_data['items'][0]['positive_prob']) # 得到积极指数值
negative = (json_data['items'][0]['negative_prob']) # 得到消极指数值
sum_positive = sum_positive + positive # 积极指数值加和
sum_negative = sum_negative + negative # 消极指数值加和
# print(positive)
print(sum_positive)
print(sum_negative)
if (sum_positive > sum_negative): # 如果积极大于消极,则返回2
return 2
elif (sum_positive == sum_negative): # 如果消极等于于积极,则返回1
return 1
else:
return 0 # 否则,返回0
def main():
# client_id 为官网获取的API Key, client_secret 为官网获取的Secret Key
#这两个我都空出来了,你用你的填上就行了。
client_id=""
client_secret=""
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+client_id+'&client_secret='+client_secret
response = requests.get(host)
list_new=eval(response.text)
access_token=list_new["access_token"]
txt1 = "你好优秀"
txt2 = "难过!"
print("txt1测试结果:",get_emotion(access_token,txt1))
print("txt2测试结果:",get_emotion(access_token,txt2))
if __name__ == "__main__":
main()
效果如图。

剩下的比如折线图什么的就不写了,百度都有。
到此这篇关于详解python爬取弹幕与数据分析的文章就介绍到这了,更多相关pythonpython爬弹幕数据分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

使用python爬虫实现网络股票信息爬取的demo
实例如下所示: import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockUR
-
python cookie反爬处理的实现
Cookies的处理 作用 保存客户端的相关状态 在爬虫中如果遇到了cookie的反爬如何处理? 手动处理 在抓包工具中捕获cookie,将其封装在headers中 应用场景:cookie没有有效时长且不是动态变化 自动处理 使用session机制 使用场景:动态变化的cookie session对象:该对象和requests模块用法几乎一致.如果在请求的过程中产生了cookie,如果该请求使用session发起的,则cookie会被自动存储到session中. 案例 爬取
-
Python爬虫过程解析之多线程获取小米应用商店数据
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于IT共享之家 ,作者IT共享者 前言 小米应用商店给用户发现最好的安卓应用和游戏,安全可靠,可是要下载东西要一个一个地搜索太麻烦了.而且速度不是很快. 今天用多线程爬取小米应用商店的游戏模块.快速获取. 二.项目目标 目标 :应用分类 - 聊天社交 应用名称, 应用链接,显示在控制台供用户下载. 三.涉及的库和网站 1.网址:百度搜 - 小米应用商店,进入官网. 2.涉及的库:re
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
python多线程+代理池爬取天天基金网、股票数据过程解析
简介 提到爬虫,大部分人都会想到使用Scrapy工具,但是仅仅停留在会使用的阶段.为了增加对爬虫机制的理解,我们可以手动实现多线程的爬虫过程,同时,引入IP代理池进行基本的反爬操作. 本次使用天天基金网进行爬虫,该网站具有反爬机制,同时数量足够大,多线程效果较为明显. 技术路线 IP代理池 多线程 爬虫与反爬 编写思路 首先,开始分析天天基金网的一些数据.经过抓包分析,可知: ./fundcode_search.js包含所有基金的数据,同时,该地址具有反爬机制,多次访问将会失败的情况. 同时,经
-
python爬虫中PhantomJS加载页面的实例方法
PhantomJS作为常用获取页面的工具之一,我们已经讲过页面测试.代码评估和捕获屏幕这几种使用的方式.当然最厉害的还是网页方面的捕捉,这里就不再讲述了.今天我们要讲的是它加载页面的新方法,这个可能很多人不知道.其实经常会用到,感兴趣的小伙伴一起进入今天的学习之中吧~ 可以利用 phantom 来实现页面的加载,下面的例子实现了页面的加载并将页面保存为一张图片. var page = require('webpage').create();page.open('http://cuiqingcai
-
基于Python爬取股票数据过程详解
基本环境配置 python 3.6 pycharm requests csv time 相关模块pip安装即可 目标网页 分析网页 一切的一切都在图里 找到数据了,直接请求网页,解析数据,保存数据 请求网页 import requests url = 'https://xueqiu.com/service/v5/stock/screener/quote/list' response = requests.get(url=url, params=params, headers=headers, c
-
基于Python爬取搜狐证券股票过程解析
数据的爬取 我们以上证50的股票为例,首先需要找到一个网站包含这五十只股票的股票代码,例如这里我们使用搜狐证券提供的列表. https://q.stock.sohu.com/cn/bk_4272.shtml 可以看到,在这个网站中有上证50的所有股票代码,我们希望爬取的就是这个包含股票代码的表,并获取这个表的第一列. 爬取网站的数据我们使用Beautiful Soup这个工具包,需要注意的是,一般只能爬取到静态网页中的信息. 简单来说,Beautiful Soup是Python的一个库,最主要的
-
详解python爬取弹幕与数据分析
很不幸的是,由于疫情的关系,原本线下的AWD改成线上CTF了.这就很难受了,毕竟AWD还是要比CTF难一些的,与人斗现在变成了与主办方斗. 虽然无奈归无奈,但是现在还是得打起精神去面对下一场比赛.这个开始也是线下的,决赛地点在南京,后来是由于疫情的关系也成了线上. 当然,比赛内容还是一如既往的得现学,内容是关于大数据的. 由于我们学校之前并没有开设过相关培训,所以也只能自己琢磨了. 好了,废话先不多说了,正文开始. 一.比赛介绍 大数据总体来说分为三个过程. 第一个过程是搭建hadoop环境.
-
详解Python 爬取13个旅游城市,告诉你五一大家最爱去哪玩?
今年五一放了四天假,很多人不再只是选择周边游,因为时间充裕,选择了稍微远一点的景区,甚至出国游.各个景点成了人山人海,拥挤的人群,甚至去卫生间都要排队半天,那一刻我突然有点理解灭霸的行为了. 今天通过分析去哪儿网部分城市门票售卖情况,简单的分析一下哪些景点比较受欢迎,等下次假期可以做个参考. 抓取数据 通过请求https://piao.qunar.com/ticket/list.htm?keyword=北京,获取北京地区热门景区信息,再通过BeautifulSoup去分析提取出我们需要的信息.
-
详解python 爬取12306验证码
一个简单的验证码爬取程序 本文介绍了在Python2.7环境下爬取网站验证码: 思路就是获取验证码对应的url,然后发起requst请求,读取该URL对应的内容,然后写入到一个本地文件,实现一个验证码的保存.大量下载可以把以上程序写入一个死循环 代码实现部分: import ssl import urllib2 i=1 import time while(1): #不加的话,无法访问12306 ssl._create_default_https_context = ssl._create_unv
-
详解Python爬取并下载《电影天堂》3千多部电影
不知不觉,玩爬虫玩了一个多月了. 我愈发觉得,爬虫其实并不是什么特别高深的技术,它的价值不在于你使用了什么特别牛的框架,用了多么了不起的技术,它不需要.它只是以一种自动化搜集数据的小工具,能够获取到想要的数据,就是它最大的价值. 我的爬虫课老师也常跟我们强调,学习爬虫最重要的,不是学习里面的技术,因为前端技术在不断的发展,爬虫的技术便会随着改变.学习爬虫最重要的是,学习它的原理,万变不离其宗. 爬虫说白了是为了解决需要,方便生活的.如果能够在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的
-
用Python 爬取猫眼电影数据分析《无名之辈》
前言 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef 获取猫眼接口数据 作为一个长期宅在家的程序员,对各种抓包简直是信手拈来.在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&o
-
Python爬取奶茶店数据分析哪家最好喝以及性价比
目录 序篇 数据获取 数据清洗 数据可视化 热门城市奶茶店铺数量情况 特色奶茶分布情况 大众奶茶分布情况 总结 序篇 天气真的很热啊… 很想有一杯冰冰凉凉的奶茶来解渴~ 但是现在奶茶店这么多, 到底哪一家最好喝.性价比最高呢? 数据获取 本文抓取了12个热门城市的奶茶店名单, 城市包括:北京.上海.广州.深圳.天津.西安.重庆.杭州.南京.武汉.成都和长沙. 共计68614家奶茶店,3万多个奶茶品牌. 在构建抓取URL时, 需要注意将城市的维度具体到城市商圈, 因为每个URL最多只显示32页内容
-
Python爬取英雄联盟MSI直播间弹幕并生成词云图
一.环境准备 安装相关第三方库 pip install jieba pip install wordcloud 二.数据准备 爬取对象:2021年5月23号,RNG夺冠直播间的弹幕信息 爬取对象路径: 方式1.根据开发者工具(F12),获取请求url.请求头.cookie等信息: 方式2:根据直播地址url,前+字符i 我们这里演示的是,采用方式2. 三.代码如下 import requests, re import jieba, wordcloud """ # 以下是练习代
-
python爬取天气数据的实例详解
就在前几天还是二十多度的舒适温度,今天一下子就变成了个位数,小编已经感受到冬天寒风的无情了.之前对获取天气都是数据上的搜集,做成了一个数据表后,对温度变化的感知并不直观.那么,我们能不能用python中的方法做一个天气数据分析的图形,帮助我们更直接的看出天气变化呢? 使用pygal绘图,使用该模块前需先安装pip install pygal,然后导入import pygal bar = pygal.Line() # 创建折线图 bar.add('最低气温', lows) #添加两线的数据序列 b
-
用python爬取分析淘宝商品信息详解技术篇
目录 背景介绍 一.模拟登陆 二.爬取商品信息 1. 定义相关参数 2. 分析并定义正则 3. 数据爬取 三.简单数据分析 1.导入库 2.中文显示 3.读取数据 4.分析价格分布 5.分析销售地分布 6.词云分析 写在最后 Tip:本文仅供学习与交流,切勿用于非法用途!!! 背景介绍 有个同学问我:"XXX,有没有办法搜集一下淘宝的商品信息啊,我想要做个统计".于是乎,闲来无事的我,又开始琢磨起这事- 一.模拟登陆 兴致勃勃的我,冲进淘宝就准备一顿乱搜: 在搜索栏里填好关键词:&qu
-
Python爬取雪中悍刀行弹幕分析并可视化详程
目录 哔哔一下 爬虫部分 代码部分 效果展示 数据可视化 代码展示 效果展示 福利环节 哔哔一下 雪中悍刀行兄弟们都看过了吗?感觉看了个寂寞,但又感觉还行,原谅我没看过原著小说~ 豆瓣评分5.8,说明我还是没说错它的. 当然,这并不妨碍它波播放量嘎嘎上涨,半个月25亿播放,平均一集一个亿,就是每天只有一集有点难受. 我们今天就来采集一下它的弹幕,实现数据可视化,看看弹幕文化都输出了什么~ 爬虫部分 我们将它的弹幕先采集下来,保存到Excel表格~ 首先安装一下这两个模块 requests # 发