Python提取Word中图片的实现步骤
目录
- 1.思路
- 2.具体实现
- 2.1导入相关库
- 2.2定义函数
- 2.3重命名word文件,将后缀名docx改为zip
- 2.4zip还原为docx文件,并获得图片的列表
- 2.5将图片复制到需要保存的文件夹中
- 2.6删除tmp缓冲文件夹中的文件,用以存储下一次的文件
- 2.7运行程序
- 3效果预览
- 3.1源word
- 3.2提取的图片
- 4附:doc转docx
1.思路
在网上查找了半天,基本都是提取word中文字的,没有找到可以把word中的图片提取出来的方法。一个巧合的情况下,发现将word的后缀名改为zip,然后解压该zip,可以看到原来word是这样存储的:
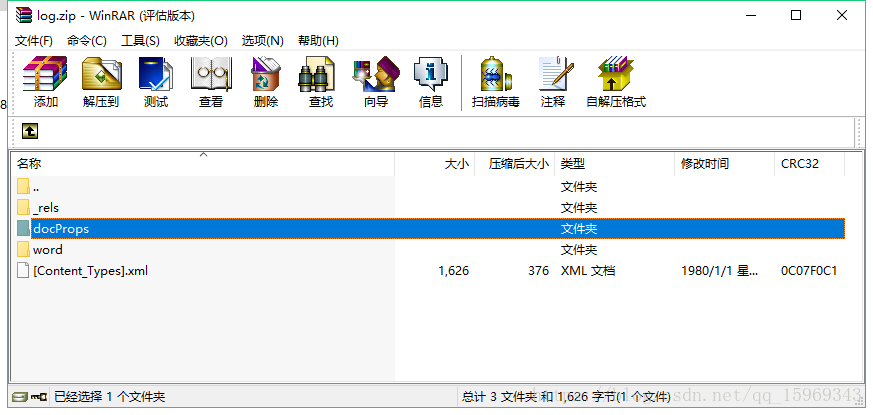
图片就存放在固定的文件夹下:/word/media/;

那么我们就只需要批量的修改文件后缀名,并且解压之后将图片拷贝到需要存放的地方,然后将该文件夹清空留作下次的路径,并且将文件从zip改回docx即可。(注意:doc不支持这个方法,如果需要提取doc格式的图片,可以先转为docx,再提取即可)
2.具体实现
2.1导入相关库
''' =========================================== @author: renjiaxin @time: 2018/8/9 0009 10:00 =========================================== ''' import zipfile import os import shutil
2.2定义函数
为了方便和其他函数调用,直接写了个函数完成这个功能,在这里,我们需要以下四个参数:
- word文档的路径
- zip压缩文件的路径
- 临时解压的tmp路径
- 最后需要保存的store_path路径
def word2pic(path, zip_path, tmp_path, store_path):
'''
:param path:源文件
:param zip_path:docx重命名为zip
:param tmp_path:中转图片文件夹
:param store_path:最后保存结果的文件夹(需要手动创建)
:return:
'''
2.3重命名word文件,将后缀名docx改为zip
# 将docx文件重命名为zip文件
os.rename(path, zip_path)
# 进行解压
f = zipfile.ZipFile(zip_path, 'r')
# 将图片提取并保存
for file in f.namelist():
f.extract(file, tmp_path)
# 释放该zip文件
f.close()
2.4zip还原为docx文件,并获得图片的列表
# 将docx文件从zip还原为docx
os.rename(zip_path, path)
# 得到缓存文件夹中图片列表
pic = os.listdir(os.path.join(tmp_path, 'word/media'))
2.5将图片复制到需要保存的文件夹中
并且我们将文件的名字命名为word所在的路径
# 将图片复制到最终的文件夹中
for i in pic:
# 根据word的路径生成图片的名称
new_name = path.replace('\\', '_')
new_name = new_name.replace(':', '') + '_' + i
shutil.copy(os.path.join(tmp_path + '/word/media', i), os.path.join(store_path, new_name))
2.6删除tmp缓冲文件夹中的文件,用以存储下一次的文件
# 删除缓冲文件夹中的文件,用以存储下一次的文件
for i in os.listdir(tmp_path):
# 如果是文件夹则删除
if os.path.isdir(os.path.join(tmp_path, i)):
shutil.rmtree(os.path.join(tmp_path, i))
2.7运行程序
if __name__ == '__main__':
# 源文件
path = r'E:\dogcat\提取图片\log.docx'
# docx重命名为zip
zip_path = r'E:\dogcat\提取图片\log.zip'
# 中转图片文件夹
tmp_path = r'E:\dogcat\提取图片\tmp'
# 最后保存结果的文件夹
store_path = r'E:\dogcat\提取图片\测试'
m = word2pic(path, zip_path, tmp_path, store_path)
3效果预览
3.1源word
3.2提取的图片

4附:doc转docx
from win32com import client
import traceback
def doc2docx(doc_name, docx_name):
'''
# doc转docx
:param doc_name: doc文档路径
:param docx_name: docx文档路径
:return:
'''
try:
# 首先将doc转换成docx
word = client.Dispatch("Word.Application")
doc = word.Documents.Open(doc_name)
# 使用参数16表示将doc转换成docx
doc.SaveAs(docx_name, 16)
doc.Close()
word.Quit()
except:
traceback.print_exc()
到此这篇关于Python提取Word中图片的实现步骤的文章就介绍到这了,更多相关Python提取Word图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python提取word文件中的图片并上传阿里云OSS
该需求是一个真实的实战需求,如果你的公司在做题库类的系统,一定会涉及该方面的内容,所以收藏起来吧. 需求简单描述如下所示: 1.提取 Word(为了便于解决,统一格式为 docx)中的题干/选项图片: 2.将其传递到云 OSS 上,并返回图片地址: 3.部分场景,需要将其拼接为 HTML 的 img 标签进行返回. 实操环节 首先你需要准备好云OSS的 AccessKeyId 和 AccessKeySecret ,这两个值一般由运维工程师提供给你,如果你的公司比较小,没有运维岗位,那就需要自己去
-
python提取word文件中的所有图片
前言 办公中,偶尔会碰到一种情况,需要提取word文档中的图片,决定写这样一款工具自动提取图片. 关于脚本的使用: 情景1:如果你拿到的是一个文件夹,所有的word文件都在这个文件夹的子目录下,深度为1层,你可以直接使用该脚本 情景2:如果你拿到的是一个文件夹,打开之后,里面杂乱无章的充斥着各种文件,你也不确定word文档都在哪,那么你需要使用Everything来手动提取出所有的word文档,虽然我也可以让脚本实现这个功能,但是使用脚本需要考虑到有可能存在同名文件,再处理起来代码量会更大,还是
-
Python提取Word中图片的实现步骤
目录 1.思路 2.具体实现 2.1导入相关库 2.2定义函数 2.3重命名word文件,将后缀名docx改为zip 2.4zip还原为docx文件,并获得图片的列表 2.5将图片复制到需要保存的文件夹中 2.6删除tmp缓冲文件夹中的文件,用以存储下一次的文件 2.7运行程序 3效果预览 3.1源word 3.2提取的图片 4附:doc转docx 1.思路 在网上查找了半天,基本都是提取word中文字的,没有找到可以把word中的图片提取出来的方法.一个巧合的情况下,发现将word的后缀名改为
-
Python提取视频中图片的示例(按帧、按秒)
一.按帧提取 #coding=utf-8 import os import cv2 def save_img(): #提取视频中图片 按照每帧提取 video_path = r'D:\\test\\' #视频所在的路径 f_save_path = 'D:\\aaa\\' #保存图片的上级目录 videos = os.listdir(video_path) #返回指定路径下的文件和文件夹列表. for video_name in videos: #依次读取视频文件 file_name = vide
-
教你使用Python提取视频中的美女图片
目录 前言 安装模块 you-get OpenCV 结束 前言 人类都是视觉动物,不管是男生还是女生看到漂亮的小姐姐.小哥哥就想截图保存下来.可是截图会对画质会产生损耗,截取的 画面不规整,像素不高等问题. 用 Python 写一个逐帧无损保存视频画面的小脚本大致可以分为三个步骤: 1.在 cmd 中使用 you-get 下载视频 2.OpenCV 读取并处理视频 3.将视频画面保存为图片 安装模块 1.you-get 模块用于下载视频,它需要 ffmpeg 模块配合使用. pip3 insta
-
Python提取PDF中的图片的实现示例
目录 1.导入相关库 2.具体实现 2.1.使用正则表达式查找PDF中的图片 2.2.打印PDF的相关信息 2.3.遍历PDF中的对象,遇到是图像才进行下一步,不然就continue 2.4.将图像存为png格式 2.5.输入pdf路径,即可运行 3.结果预览 3.1.程序结果 3.2.原本的pdf 3.3.提取出来的图片 1.导入相关库 import fitz import time import re import os 2.具体实现 为了方便和其他模块组合,我直接写了个函数完成这个功能,实
-
C#实现提取Word中插入的多媒体文件(视频,音频)
目录 dll文件安装(3种方法) 提取文件 完整代码 C# VB.NET 在Word中可将文件通过OLE对象嵌入的方式插入到文档,包括Word.excel.PDF.PPT.图片.宏文件.文件包等在内的多种文件类型.对文档中已插入的文档对象,也可通过本文中的方法提取出来另存到指定路径.本文将通过C#程序代码示例做详细介绍. dll文件安装(3种方法) 1.通过NuGet安装dll(2种方法) 1.1可以在Visual Studio中打开“解决方案资源管理器”,鼠标右键点击“引用”,“管理NuGet
-
Python提取视频帧图片实例代码
为了从视频中提取每一帧图片,编写Python脚本实现该功能 video_path为指定的视频路径 interval为指定分割视频是是否跳帧,默认不跳帧,即全部分割 width, height 为指定对分割帧图片调整大小,默认不调整 该脚本自动对帧图片编号,设置为7位编码,最多可分割9999999帧图片,即92小时的30FPS视频 # !/usr/bin/env python # -*- coding: utf-8 -*- # ===================================
-
js生成word中图片处理方法
首先功能是要求前台导出word,但是前后台是分离的,图片存在后台,所以就存在跨域问题. 导出文字都是没有问题的(jquery.wordexport.js),但是导出图片就存在问题了: 图片是以链接形式存到word中,这样如果是需要vpn的网站就会存在生成的word在没有vpn的情况下打不开,有vpn的情况下必须启用编辑才能加载出来图片. 解决办法:将图片转换成Data URL格式,再导出. 详细代码如下所示: function changeImgToDataurl(){ var charImg
-
python读取word 中指定位置的表格及表格数据
1.Word文档如下: 2.代码 # -*- coding: UTF-8 -*- from docx import Document def readSpecTable(filename, specText): document = Document(filename) paragraphs = document.paragraphs allTables = document.tables specText = specText.encode('utf-8').decode('utf-8') f