记一次公司JVM堆溢出抽丝剥茧定位的过程解析
背景
公司线上有个tomcat服务,里面合并部署了大概8个微服务,之所以没有像其他微服务那样单独部署,其目的是为了节约服务器资源,况且这8个服务是属于边缘服务,并发不高,就算宕机也不会影响核心业务。
因为并发不高,所以线上一共部署了2个tomcat进行负载均衡。
这个tomcat刚上生产线,运行挺平稳。大概过了大概1天后,运维同事反映2个tomcat节点均挂了。无法接受新的请求了。CPU飙升到100%。
排查过程一
接手这个问题后。首先大致看了下当时的JVM监控。
CPU的确居高不下
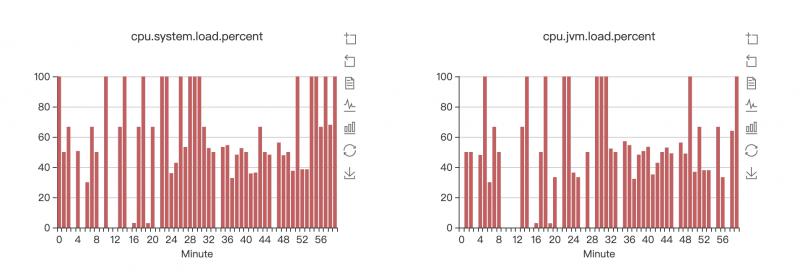
FULL GC从大概这个小时的22分开始,就开始频繁的进行FULL GC,一分钟最高能进行10次FULL GC

minor GC每分钟竟然接近60次,相当于每秒钟都有minor GC

从老年代的使用情况也反应了这一点

随机对线上应用分析了线程的cpu占用情况,用top -H -p pid命令

可以看到前面4条线程,都占用了大量的CPU资源。随即进行了jstack,把线程栈信息拉下来,用前面4条线程的ID转换16进制后进行搜索。发现并没有找到相应的线程。所以判断为不是应用线程导致的。
第一个结论
通过对当时JVM的的监控情况,可以发现。这个小时的22分之前,系统 一直保持着一个比较稳定的运行状态,堆的使用率不高,但是22分之后,年轻代大量的minor gc后,老年代在几分钟之内被快速的填满。导致了FULL GC。同时FULL GC不停的发生,导致了大量的STW,CPU被FULL GC线程占据,出现CPU飙高,应用线程由于STW再加上CPU过高,大量线程被阻塞。同时新的请求又不停的进来,最终tomcat的线程池被占满,再也无法响应新的请求了。这个雪球终于还是滚大了。
分析完了案发现场。要解决的问题变成了:
是什么原因导致老年代被快速的填满?
拉了下当时的JVM参数
-Djava.awt.headless=true -Dfile.encoding=UTF-8 -server -Xms2048m -Xmx4096m -Xmn2048m -Xss512k -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+DisableExx
plicitGC -XX:MaxTenuringThreshold=5 -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly -XX:+UseCMSCompactAtFullCollection
-XX:+PrintGCDetails -Xloggc:/data/logs/gc.log
总共4个G的堆,年轻代单独给了2个G,按照比率算,JVM内存各个区的分配情况如下:

所以开始怀疑是JVM参数设置的有问题导致的老年代被快速的占满。
但是其实这参数已经是之前优化后的结果了,eden区设置的挺大,大部分我们的方法产生的对象都是朝生夕死的对象,应该大部分都在年轻代会清理了。存活的对象才会进入survivor区。到达年龄或者触发了进入老年代的条件后才会进入老年代。基本上老年代里的对象大部分应该是一直存活的对象。比如static修饰的对象啊,一直被引用的 缓存啊,spring容器中的bean等等。
我看了下垃圾回收进入老年代的触发条件后(关注公众号后回复“JVM”获取JVM内存分配和回收机制的资料),发现这个场景应该是属于大对象直接进老年代的这种,也就是说年轻代进行minor GC后,存活的对象足够大,不足以在survivor区域放下了,就直接进入老年代了。
但是一次minor GC应该超过90%的对象都是无引用对象,只有少部分的对象才是存活的。而且这些个服务的并发一直不高,为什么一次minor GC后有那么大量的数据会存活呢。
随即看了下当时的jmap -histo 命令产生的文件

发现String这个这个对象的示例竟然有9000多w个,占用堆超过2G。这肯定有问题。但是tomcat里有8个应用 ,不可能通过分析代码来定位到。还是要从JVM入手来反推。
第二次结论
程序并发不高,但是在几分钟之内,在eden区产生了大量的对象,并且这些对象无法被minor GC回收 ,由于太大,触发了大对象直接进老年代机制,老年代会迅速填满,导致FULL GC,和后面CPU的飙升,从而导致tomcat的宕机。
基本判断是,JVM参数应该没有问题,很可能问题出在应用本身不断产生无法被回收的对象上面。但是我暂时定位不到具体的代码位置。
排查过程二
第二天,又看了下当时的JVM监控,发现有这么一个监控数据当时漏看了

这是FULL GC之后,老年代的使用率。可以看到。FULL GC后,老年代依然占据80%多的空间。full gc就根本清理不掉老年代的对象。这说明,老年代里的这些对象都是被程序引用着的。所以清理不掉。但是平稳的时候,老年代一直维持着大概300M的堆。从这个小时的22分开始,之后就狂飙到接近2G。这肯定不正常。更加印证了我前面一个观点。这是因为应用程序产生的无法回收的对象导致的。
但是当时我并没有dump下来jvm的堆。所以只能等再次重现问题。
终于,在晚上9点多,这个问题又重现了,熟悉的配方,熟悉的味道。
直接jmap -dump,经过漫长的等待,产生了4.2G的一个堆快照文件dump.hprof,经过压缩,得到一个466M的tar.gz文件
然后download到本地,解压。
运行堆分析工具JProfile,装载这个dump.hprof文件。
然后查看堆当时的所有类占比大小的信息

发现导致堆溢出,就是这个String对象,和之前Jmap得出的结果一样,超过了2个G,并且无法被回收
随即看大对象视图,发现这些个String对象都是被java.util.ArrayList引用着的,也就是有一个ArrayList里,引用了超过2G的对象

然后查看引用的关系图,往上溯源,源头终于显形:

这个ArrayList是被一个线程栈引用着,而这个线程栈信息里面,可以直接定位到相应的服务,相应的类。具体服务是Media这个微服务。
看来已经要逼近真相了!
第三次结论
本次大量频繁的FULL GC是因为应用程序产生了大量无法被回收的数据,最终进入老年代,最终把老年代撑满了导致的。具体的定位通过JVM的dump文件已经分析出,指向了Media这个服务的ImageCombineUtils.getComputedLines这个方法,是什么会产生尚不知道,需要具体分析代码。
最后
得知了具体的代码位置, 直接进去看。经过小伙伴提醒,发现这个代码有一个问题。
这段代码为一个拆词方法,具体代码就不贴了,里面有一个循环,每一次循环会往一个ArrayList里加一个String对象,在循环的某一个阶段,会重置循环计数器i,在普通的参数下并没有问题。但是某些特定的条件下。就会不停的重置循环计数器i,导致一个死循环。
以下是模拟出来的结果,可以看到,才运行了一会,这个ArrayList就产生了322w个对象,且大部分Stirng对象都是空值。

至此,水落石出。
最终结论
因为Media这个微服务的程序在某一些特殊场景下的一段程序导致了死循环,产生了一个超大的ArrayList。导致了年轻代的快速被填满,然后触发了大对象直接进老年代的机制,直接往老年代里面放。老年代被放满之后。触发FULL GC。但是这些ArrayList被GC ROOT根引用着,无法回收。导致回收不掉。老年代依旧满的,随机马上又触发FULL GC。同时因为老年代无法被回收,导致minor GC也没法清理,不停的进行minor GC。大量GC导致STW和CPU飙升,导致应用线程卡顿,阻塞,直至最后整个服务无法接受请求。
到此这篇关于记一次公司JVM堆溢出抽丝剥茧定位的过程的文章就介绍到这了,更多相关JVM堆溢出抽丝剥茧定位内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

JVM 心得 OOM时的堆信息获取方法与分析
JVM的框架知识了解之后,实际的项目里发生了OOM异常的话,怎么获取以及分析异常信息后怎么分析呢. 这里稍微做一下归纳. 第一步,首先通过下面两个方法的任何一种,把发生OOM时的heap信息dump下来. 有两个方法,通过设置可以把OOM时的dump信息获取到: 1)方法1:在JVM的启动参数里添加如下命令 -XX:+HeapDumpOnOutOfMemoryError 2)方法2:在JDK的安装目录下,找到bin目录,然后双击执行"jvisualvm.exe" 执行程序之后,在视图里
-
JVM堆内存溢出后,其他线程是否可继续工作的问题解析
最近网上出现一个美团面试题:"一个线程OOM后,其他线程还能运行吗?".我看网上出现了很多不靠谱的答案.这道题其实很有难度,涉及的知识点有jvm内存分配.作用域.gc等,不是简单的是与否的问题. 由于题目中给出的OOM,java中OOM又分很多类型:比如:堆溢出("java.lang.OutOfMemoryError: Java heap space").永久带溢出("java.lang.OutOfMemoryError:Permgen space&quo
-
JVM 堆和栈的区别
栈内存: 程序在栈内存中运行 栈中存的是基本数据类型和堆中对象的引用 栈是运行时的单元 栈解决程序的运行问题,即程序如何执行,或者说如何处理数据 一个线程一个独立的线程栈 堆内存: 程序运行所需的大部分数据保存在栈内存中 堆中存的是对象 堆是存储的单元,堆只是一块共享的内存 堆解决的是数据存储的问题,即数据怎么放,放在哪儿 所有线程共享堆内存 Java中的参数传递( 传值呢?还是传引用? ): 程序运行永远都是在栈中进行的,因而参数传递时,只存在传递基本类型和对象引用的问题,不会直接传递对象本
-
JVM中堆内存和栈内存的区别
Java把内存分成两种,一种叫做栈内存,一种叫做堆内存 在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配.当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用. 堆内存用于存放由new创建的对象和数组.在堆中分配的内存,由java虚拟机自动垃圾回收器来管理.在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中
-
浅谈Java堆外内存之突破JVM枷锁
对于有Java开发经验的朋友都知道,Java中不需要手动的申请和释放内存,JVM会自动进行垃圾回收:而使用的内存是由JVM控制的. 那么,什么时机会进行垃圾回收,如何避免过度频繁的垃圾回收?如果JVM给的内存不够用,怎么办? 此时,堆外内存登场!利用堆外内存,不仅可以随意操控内存,还能提高网络交互的速度. 背景1:JVM内存的分配 对于JVM的内存规则,应该是老生常谈的东西了,这里我就简单的说下: 新生代:一般来说新创建的对象都分配在这里. 年老代:经过几次垃圾回收,新生代的对象就会放在年老代里
-
深入JVM剖析Java的线程堆栈
在这篇文章里我将教会你如何分析JVM的线程堆栈以及如何从堆栈信息中找出问题的根因.在我看来线程堆栈分析技术是Java EE产品支持工程师所必须掌握的一门技术.在线程堆栈中存储的信息,通常远超出你的想象,我们可以在工作中善加利用这些信息. 我的目标是分享我过去十几年来在线程分析中积累的知识和经验.这些知识和经验是在各种版本的JVM以及各厂商的JVM供应商的深入分析中获得的,在这个过程中我也总结出大量的通用问题模板. 那么,准备好了么,现在就把这篇文章加入书签,在后续几周中我会给大家带来这一系列的专
-
记一次公司JVM堆溢出抽丝剥茧定位的过程解析
背景 公司线上有个tomcat服务,里面合并部署了大概8个微服务,之所以没有像其他微服务那样单独部署,其目的是为了节约服务器资源,况且这8个服务是属于边缘服务,并发不高,就算宕机也不会影响核心业务. 因为并发不高,所以线上一共部署了2个tomcat进行负载均衡. 这个tomcat刚上生产线,运行挺平稳.大概过了大概1天后,运维同事反映2个tomcat节点均挂了.无法接受新的请求了.CPU飙升到100%. 排查过程一 接手这个问题后.首先大致看了下当时的JVM监控. CPU的确居高不下 FULL
-
详解JVM栈溢出和堆溢出
一.栈溢出StackOverflowError 栈是线程私有的,生命周期与线程相同,每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口等信息. 栈溢出:方法执行时创建的栈帧个数超过了栈的深度. 原因举例:方法递归 [示例]: public class StackError { private int i = 0; public void fn() { System.out.println(i++); fn(); } public static void mai
-
jvm内存溢出解决方法(jvm内存溢出怎么解决)
java.lang.OutOfMemoryError: PermGen space 发现很多人把问题归因于: spring,hibernate,tomcat,因为他们动态产生类,导致JVM中的permanent heap溢出 .然后解决方法众说纷纭,有人说升级 tomcat版本到最新甚至干脆不用tomcat.还有人怀疑spring的问题,在spring论坛上讨论很激烈,因为spring在AOP时使用CBLIB会动态产生很多类. 但问题是为什么这些王牌的开源会出现同一个问题呢,那么是不是更基础的原
-
解决jmap命令打印JVM堆信息异常的问题
jmap命令可以打印java进程的JVM堆信息,今天在某台机器上运行该命令查看 19560进程的堆信息 jmap -heap 19560 出现以下异常 Attaching to process ID 19560, please wait... Debugger attached successfully. Server compiler detected. JVM version is 24.79-b02 using thread-local object allocation. Paralle
-
简单说说JVM堆区的相关知识
一.堆概述 一个jvm实例(进程)只存在一个堆内存,堆也是java内存管理的核心区域. java 堆区在jvm启动时即被创建,其空间大小也就被确定了 <java虚拟机规范>规定,堆可以处于物理上不连续的内存空间,但在逻辑上它应该被称为连续的 所有线程共享java堆,在这里和可以划分线程私有的缓冲区(tlab) 所有对象实例以及数组都应在运行时分配在堆中 方法结束后,堆中的对象不会马上被移除,仅仅在垃圾收集时候才会被移除 堆是gc执行垃圾回收的重点区域 1.1 堆内存细分 现代垃圾收集器大部分基
-
浅谈JVM内存溢出原因和解决思路
目录 栈溢出(虚拟机栈和本地方法栈) 产生原因 解决思路 堆溢出 产生原因 解决思路 方法区和运行时常量池溢出 产生原因 解决思路 本机直接内存溢出 产生原因 解决思路 栈溢出(虚拟机栈和本地方法栈) 产生原因 在HotSpot中,只能由-Xss参数来设定.因为在HotSpot中不区分虚拟机栈和本地方法栈的. 栈溢出时会出现两种异常:StackOverflowError异常和OutOfMemoryError异常. StackOverflowError异常因为线程请求的栈深度大于虚拟机允许的最大深
-
JVM堆外内存源码完全解读分析
概述 广义的堆外内存 说到堆外内存,那大家肯定想到堆内内存,这也是我们大家接触最多的,我们在jvm参数里通常设置-Xmx来指定我们的堆的最大值,不过这还不是我们理解的Java堆,-Xmx的值是新生代和老生代的和的最大值,我们在jvm参数里通常还会加一个参数-XX:MaxPermSize来指定持久代的最大值,那么我们认识的Java堆的最大值其实是-Xmx和-XX:MaxPermSize的总和,在分代算法下,新生代,老生代和持久代是连续的虚拟地址,因为它们是一起分配的,那么剩下的都可以认为是堆外内存
-
java内存溢出示例(堆溢出、栈溢出)
堆溢出: 复制代码 代码如下: /** * @author LXA * 堆溢出 */ public class Heap { public static void main(String[] args) { ArrayList list=new ArrayList(); while(true) { list.add(new Heap()); } } } 报错: java.lang.OutOfMemoryError: Java heap space 栈溢出: 复制代码 代码如下: /** * @a
-
记一次pyinstaller打包pygame项目为exe的过程(带图片)
一段简单的pygame代码,只在pygame界面背景绘制了一个背景图片 # -*- coding=utf-8 -*- import sys import pygame pygame.init() screen = pygame.display.set_mode((400,300)) bg_image = pygame.image.load('bg.jpeg') bg_image = pygame.transform.scale(bg_image, (400, 300)) while True: