python机器学习混淆矩阵及confusion matrix函数使用
目录
- 1.混淆矩阵
- 2.confusion_matrix函数的使用
- 实现例子:
- 运行结果:
关于混淆矩阵的概念,可参考此篇博文混淆矩阵
1.混淆矩阵
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型作出的分类判断两个标准进行汇总。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)
下图是混淆矩阵的一个例子

其中灰色部分是真实分类和预测分类结果相一致的,绿色部分是真实分类和预测分类不一致的,即分类错误的。
2.confusion_matrix函数的使用
官方文档中给出的用法是
sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None)
y_true: 是样本真实分类结果,y_pred: 是样本预测分类结果
labels:是所给出的类别,通过这个可对类别进行选择
sample_weight : 样本权重
实现例子:
from sklearn.metrics import confusion_matrix y_true=[2,1,0,1,2,0] y_pred=[2,0,0,1,2,1] C=confusion_matrix(y_true, y_pred)
运行结果:
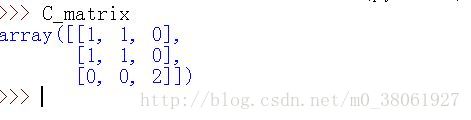
这儿没有标注类别:下图是标注类别以后,更加好理解

关于类别顺序可由 labels参数控制调整,例如 labels=[2,1,0],则类别将以这个顺序自上向下排列。
默认数字类别是从小到大排列,英文类别是按首字母顺序排列
下面是官方文档上的一个例子
y_true = ["cat", "ant", "cat", "cat", "ant", "bird"] y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"] confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"])
运行结果
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])
以上是关于confusion_matrix函数的用法,更多关于python混淆矩阵confusion matrix的资料请关注我们其它相关文章!
相关推荐
-

详解使用python绘制混淆矩阵(confusion_matrix)
Summary 涉及到分类问题,我们经常需要通过可视化混淆矩阵来分析实验结果进而得出调参思路,本文介绍如何利用python绘制混淆矩阵(confusion_matrix),本文只提供代码,给出必要注释. Code # -*-coding:utf-8-*- from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt import numpy as np #labels表示你不同类别的代号,比如这里的de
-
利用python中的matplotlib打印混淆矩阵实例
前面说过混淆矩阵是我们在处理分类问题时,很重要的指标,那么如何更好的把混淆矩阵给打印出来呢,直接做表或者是前端可视化,小编曾经就尝试过用前端(D5)做出来,然后截图,显得不那么好看.. 代码: import itertools import matplotlib.pyplot as plt import numpy as np def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cma
-
python sklearn包——混淆矩阵、分类报告等自动生成方式
preface:做着最近的任务,对数据处理,做些简单的提特征,用机器学习算法跑下程序得出结果,看看哪些特征的组合较好,这一系列流程必然要用到很多函数,故将自己常用函数记录上.应该说这些函数基本上都会用到,像是数据预处理,处理完了后特征提取.降维.训练预测.通过混淆矩阵看分类效果,得出报告. 1.输入 从数据集开始,提取特征转化为有标签的数据集,转为向量.拆分成训练集和测试集,这里不多讲,在上一篇博客中谈到用StratifiedKFold()函数即可.在训练集中有data和target开始. 2.
-
Python实现两种多分类混淆矩阵
目录 1.什么是混淆矩阵 2.分类模型评价指标 3.两种多分类混淆矩阵 3.1直接打印出每一个类别的分类准确率. 3.2打印具体的分类结果的数值 4.总结 1.什么是混淆矩阵 深度学习中,混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法.它可以直观地了解分类模型在每一类样本里面表现,常作为模型评估的一部分.它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class). 首先要明确几个概念: T或者F:该样本 是否被正确分类
-
使用Python和scikit-learn创建混淆矩阵的示例详解
目录 一.混淆矩阵概述 1.示例1 2.示例2 二.使用Scikit-learn 创建混淆矩阵 1.相应软件包 2.生成示例数据集 3.训练一个SVM 4.生成混淆矩阵 5.可视化边界 一.混淆矩阵概述 在训练了有监督的机器学习模型(例如分类器)之后,您想知道它的工作情况. 这通常是通过将一小部分称为测试集的数据分开来完成的,该数据用作模型以前从未见过的数据. 如果它在此数据集上表现良好,那么该模型很可能在其他数据上也表现良好 - 当然,如果它是从与您的测试集相同的分布中采样的. 现在,当您测试
-
python机器学习混淆矩阵及confusion matrix函数使用
目录 1.混淆矩阵 2.confusion_matrix函数的使用 实现例子: 运行结果: 关于混淆矩阵的概念,可参考此篇博文混淆矩阵 1.混淆矩阵 混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型作出的分类判断两个标准进行汇总.这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class) 下图是混淆矩阵的一个例子 其中灰色部分是真实分类和预测分类结果相一致的,绿色部分是真实分类和预测分类不一致的,即
-
混淆矩阵Confusion Matrix概念分析翻译
Confusion Matrix 在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵.它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix). 其每一列代表预测值,每一行代表的是实际的类别.这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class). Example 假设有一个用来对猫(cats).狗(dogs).兔子(rabbits)进行分类的
-
Python利用Seaborn绘制多标签的混淆矩阵
Seaborn - 绘制多标签的混淆矩阵.召回.精准.F1 导入seaborn\matplotlib\scipy\sklearn等包: import seaborn as sns from matplotlib import pyplot as plt from scipy.special import softmax from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_sco
-
Python的numpy库中将矩阵转换为列表等函数的方法
这篇文章主要介绍Python的numpy库中的一些函数,做备份,以便查找. (1)将矩阵转换为列表的函数:numpy.matrix.tolist() 返回list列表 Examples >>> >>> x = np.matrix(np.arange(12).reshape((3,4))); x matrix([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) >>> x.tolist() [[0, 1, 2
-
Python机器学习应用之决策树分类实例详解
目录 一.数据集 二.实现过程 1 数据特征分析 2 利用决策树模型在二分类上进行训练和预测 3 利用决策树模型在多分类(三分类)上进行训练与预测 三.KEYS 1 构建过程 2 划分选择 3 重要参数 一.数据集 小企鹅数据集,提取码:1234 该数据集一共包含8个变量,其中7个特征变量,1个目标分类变量.共有150个样本,目标变量为 企鹅的类别 其都属于企鹅类的三个亚属,分别是(Adélie, Chinstrap and Gentoo).包含的三种种企鹅的七个特征,分别是所在岛屿,嘴巴长度,