如何使用Python处理HDF格式数据及可视化问题
原文链接:https://blog.csdn.net/Fairy_Nan/article/details/105914203
HDF也是一种自描述格式文件,主要用于存储和分发科学数据。气象领域中卫星数据经常使用此格式,比如MODIS,OMI,LIS/OTD等卫星产品。对HDF格式细节感兴趣的可以Google了解一下。
这一次呢还是以Python为主,来介绍如何处理HDF格式数据。Python中有不少库都可以用来处理HDF格式数据,比如h5py可以处理HDF5格式(pandas中 read_hdf 函数),pyhdf可以用来处理HDF4格式。此外,gdal也可以处理HDF(NetCDF,GRIB等)格式数据。
安装
首先安装相关库

上述库均可以通过conda包管理器进行安装,如果conda包管理器无法安装,对于windows系统,可以查找是否存在已打包的安装包,而unix系统可以通过源码编译安装。
数据处理和可视化
以LIS/OTD卫星闪电成像数据为例,处理HDF4格式数据并进行绘图:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm, colors
import seaborn as sns
import cartopy.crs as ccrs
from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter
from pyhdf.SD import SD, SDC
sns.set_context('talk', font_scale=1.3)
data = SD('LISOTD_LRMTS_V2.3.2014.hdf', SDC.READ)
lon = data.select('Longitude')
lat = data.select('Latitude')
flash = data.select('LRMTS_COM_FR')
# 设置colormap
collev= ['#ffffff', '#ab18b0', '#07048f', '#1ba01f', '#dfdf18', '#e88f14', '#c87d23', '#d30001', '#383838']
levels = [0, 0.01, 0.02, 0.04, 0.06, 0.1, 0.12, 0.15, 0.18, 0.2]
cmaps = colors.ListedColormap(collev, 'indexed')
norm = colors.BoundaryNorm(levels, cmaps.N)
proj = ccrs.PlateCarree()
fig, ax = plt.subplots(figsize=(16, 9), subplot_kw=dict(projection=proj))
LON, LAT= np.meshgrid(lon[:], lat[:])
con = ax.contourf(LON, LAT, flash[:, :, 150], cmap=cmaps, norm=norm, levels=levels, extend='max')
cb = fig.colorbar(con, shrink=0.75, pad=0.02)
cb.cmap.set_over('#000000')
cb.ax.tick_params(direction='in', length=5)
ax.coastlines()
ax.set_xticks(np.linspace(-180, 180, 5), crs=proj)
ax.set_yticks(np.linspace(-90, 90, 5), crs=proj)
lon_formatter= LongitudeFormatter(zero_direction_label=True)
lat_formatter= LatitudeFormatter()
ax.xaxis.set_major_formatter(lon_formatter)
ax.yaxis.set_major_formatter(lat_formatter)
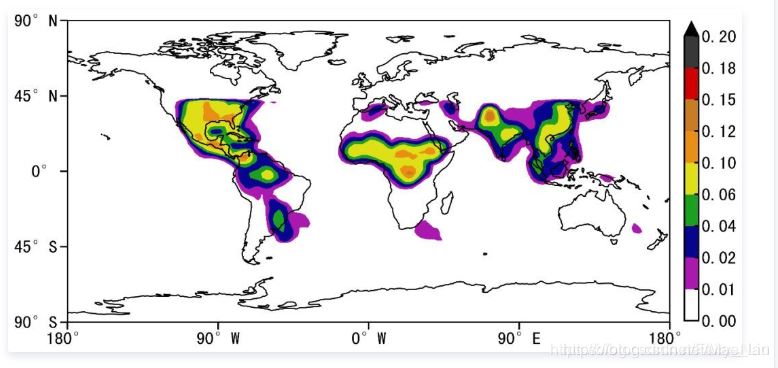
某月全球闪电密度分布
上述示例基于pyhdf进行HDF4格式数据处理和可视化,HDF4文件中包含的变量和属性获取方式见文末的Notebook,其中给出了 更详细的示例。
以下基于h5py读取HDF5格式数据,以OMI卫星O3数据为例:
import h5py
data = h5py.File('TES-Aura_L3-O3-M2005m07_F01_10.he5')
lon = data.get('/HDFEOS/GRIDS/NadirGrid/Data Fields/Longitude').value
lat = data.get('/HDFEOS/GRIDS/NadirGrid/Data Fields/Latitude').value
o3 = data.get('/HDFEOS/GRIDS/NadirGrid/Data Fields/O3').value
proj = ccrs.PlateCarree()
fig, ax = plt.subplots(figsize=(16, 9), subplot_kw=dict(projection=proj))
LON, LAT = np.meshgrid(lon[:], lat[:])
con = ax.contourf(LON, LAT, o3[10, :, :]*1e6, np.arange(0, 8.01, 0.1), vmin=0, vmax=8, cmap=cm.RdGy_r)
ax.coastlines()
ax.set_xticks(np.linspace(-180, 180, 5), crs=proj)
ax.set_yticks(np.linspace(-90, 90, 5), crs=proj)
lon_formatter = LongitudeFormatter(zero_direction_label=True)
lat_formatter = LatitudeFormatter()
ax.xaxis.set_major_formatter(lon_formatter)
ax.yaxis.set_major_formatter(lat_formatter)
cb = fig.colorbar(con, shrink=0.75, pad=0.02)
cb.set_ticks(np.arange(0, 8.01, 1))
cb.ax.tick_params(direction='in', length=5)
上述示例中使用类似unix中路径的方式获取相关变量,这在HDF格式数据中称为Groups。不同的组可以包含子组,从而形成类似嵌套的形式。详细的介绍可Google了解。

总结
到此这篇关于如何使用Python处理HDF格式数据及可视化问题的文章就介绍到这了,更多相关Python处理HDF格式数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python:HDF和CSV存储优劣对比分析
小数据用csv,大数据用h5 结论1:几百KB以上的数据都用h5比较好 结论2:几KB的数据h5反而很慢 程序 import pandas as pd import numpy as np from wja.wja_tool import test_time as tt from wja import wja_tool as tool df = tool.generate_sampleDF(row, col) tt().run() df.to_csv('try.csv') tt().end()
-
完美解决python针对hdfs上传和下载的问题
当我们使用python的hdfs包进行上传和下载文件的时候,总会出现如下问题 requests.packages.urllib3.exceptions.NewConnectionError:<requests.packages.urllib3.connection.HTTPConnection object at 0x7fe87cc37c50>: Failed to establish a new connection: [Errno -2] Name or service not known
-
python 读取txt,json和hdf5文件的实例
一.python读取txt文件 最简单的open函数: # -*- coding: utf-8 -*- with open("test.txt","r",encoding="gbk",errors='ignore') as f: print(f.read()) 这里用open函数读取了一个txt文件,"encoding"表明了读取格式是"gbk",还可以忽略错误编码. 另外,使用with语句操作文件IO是个
-
python使用hdfs3模块对hdfs进行操作详解
之前一直使用hdfs的命令进行hdfs操作,比如: hdfs dfs -ls /user/spark/ hdfs dfs -get /user/spark/a.txt /home/spark/a.txt #从HDFS获取数据到本地 hdfs dfs -put -f /home/spark/a.txt /user/spark/a.txt #从本地覆盖式上传 hdfs dfs -mkdir -p /user/spark/home/datetime=20180817/ .... 身为一个python程
-
python读取hdfs上的parquet文件方式
在使用python做大数据和机器学习处理过程中,首先需要读取hdfs数据,对于常用格式数据一般比较容易读取,parquet略微特殊.从hdfs上使用python获取parquet格式数据的方法(当然也可以先把文件拉到本地再读取也可以): 1.安装anaconda环境. 2.安装hdfs3. conda install hdfs3 3.安装fastparquet. conda install fastparquet 4.安装python-snappy. conda install python-s
-
如何使用Python处理HDF格式数据及可视化问题
原文链接:https://blog.csdn.net/Fairy_Nan/article/details/105914203 HDF也是一种自描述格式文件,主要用于存储和分发科学数据.气象领域中卫星数据经常使用此格式,比如MODIS,OMI,LIS/OTD等卫星产品.对HDF格式细节感兴趣的可以Google了解一下. 这一次呢还是以Python为主,来介绍如何处理HDF格式数据.Python中有不少库都可以用来处理HDF格式数据,比如h5py可以处理HDF5格式(pandas中 read_hdf
-
Python 存取npy格式数据实例
数据处理的时候主要通过两个函数 (1):np.save("test.npy",数据结构) ----存数据 (2):data =np.load('test.npy") ----取数据 给2个例子如下(存列表) 1. z = [[[1, 2, 3], ['w']], [[1, 2, 3], ['w']]] np.save('test.npy', z) x = np.load('test.npy') x: ->array([[list([1, 2, 3]), list(['w
-
Python处理XML格式数据的方法详解
本文实例讲述了Python处理XML格式数据的方法.分享给大家供大家参考,具体如下: 这里的操作是基于Python3平台. 在使用Python处理XML的问题上,首先遇到的是编码问题. Python并不支持gb2312,所以面对encoding="gb2312"的XML文件会出现错误.Python读取的文件本身的编码也可能导致抛出异常,这种情况下打开文件的时候就需要指定编码.此外就是XML中节点所包含的中文. 我这里呢,处理就比较简单了,只需要修改XML的encoding头部. #!/
-
python中json格式数据输出的简单实现方法
主要使用json模块,直接导入import json即可. 小例子如下: #coding=UTF-8 import json info={} info["code"]=1 info["id"]=1900 info["name"]='张三' info["sex"]='男' list=[info,info,info] data={} data["code"]=1 data["id"]=190
-

Python中json格式数据的编码与解码方法详解
本文实例讲述了Python中json格式数据的编码与解码方法.分享给大家供大家参考,具体如下: python从2.6版本开始内置了json数据格式的处理方法. 1.json格式数据编码 在python中,json数据格式编码使用json.dumps方法. #!/usr/bin/env python #coding=utf8 import json users = [{'name': 'tom', 'age': 22}, {'name': 'anny', 'age': 18}] #元组对象也可以
-
Python爬取股票交易数据并可视化展示
目录 开发环境 第三方模块 爬虫案例的步骤 爬虫程序全部代码 分析网页 导入模块 请求数据 解析数据 翻页 保存数据 实现效果 数据可视化全部代码 导入数据 读取数据 可视化图表 效果展示 开发环境 解释器版本: python 3.8 代码编辑器: pycharm 2021.2 第三方模块 requests: pip install requests csv 爬虫案例的步骤 1.确定url地址(链接地址) 2.发送网络请求 3.数据解析(筛选数据) 4.数据的保存(数据库(mysql\mong
-
python数据封装json格式数据
最简单的使用方法是: >>> import simplejson as json >>> json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}]) '["foo", {"bar": ["baz", null, 1.0, 2]}]' >>> print(json.dumps("\"foo\bar")) "\&q
-
端午节将至,用Python爬取粽子数据并可视化,看看网友喜欢哪种粽子吧!
一.前言 本文就从数据爬取.数据清洗.数据可视化,这三个方面入手,但你简单完成一个小型的数据分析项目,让你对知识能够有一个综合的运用. 整个思路如下: 爬取网页:https://www.jd.com/ 爬取说明: 基于京东网站,我们搜索网站"粽子"数据,大概有100页.我们爬取的字段,既有一级页面的相关信息,还有二级页面的部分信息: 爬取思路: 先针对某一页数据的一级页面做一个解析,然后再进行二级页面做一个解析,最后再进行翻页操作: 爬取字段: 分别是粽子的名称(标题).价格.品牌(店
-
Python使用内置json模块解析json格式数据的方法
本文实例讲述了Python使用内置json模块解析json格式数据的方法.分享给大家供大家参考,具体如下: Python中解析json字符串非常简单,直接用内置的json模块就可以,不需要安装额外的模块. 一.json字符串转为python值 json字符串: 复制代码 代码如下: {"userAccount":"54321","date":"2016-12-06 10:26:17","ClickTime"
-
使用 Python 处理 JSON 格式的数据
如果你不希望从头开始创造一种数据格式来存放数据,JSON 是一个很好的选择.如果你对 Python 有所了解,就更加事半功倍了.下面就来介绍一下如何使用 Python 处理 JSON 数据. JSON的全称是 JavaScript 对象表示法 JavaScript Object Notation .这是一种以键值对的形式存储数据的格式,并且很容易解析,因而成为了一种被广泛使用的数据格式.另外,不要因为 JSON 名称而望文生义,JSON 并不仅仅在 JavaScript 中使用,它也可以在其它语