R语言中时间序列分析浅析
时间序列是将统一统计值按照时间发生的先后顺序来进行排列,时间序列分析的主要目的是根据已有数据对未来进行预测。
一个稳定的时间序列中常常包含两个部分,那么就是:有规律的时间序列+噪声。所以,在以下的方法中,主要的目的就是去过滤噪声值,让我们的时间序列更加的有分析意义。
语法
时间序列分析中ts()函数的基本语法是
timeseries.object.name <- ts(data, start, end, frequency)
以下是所使用的参数的描述
- data是包含在时间序列中使用的值的向量或矩阵。
- start以时间序列指定第一次观察的开始时间。
- end指定时间序列中最后一次观测的结束时间。
- frequency指定每单位时间的观测数。
除了参数“data”,所有其他参数是可选的。
时间序列的预处理:
- 平稳性检验:
拿到一个时间序列之后,我们首先要对其稳定性进行判断,只有非白噪声的稳定性时间序列才有分析的意义以及预测未来数据的价值。
所谓平稳,是指统计值在一个常数上下波动并且波动范围是有界限的。如果有明显的趋势或者周期性,那么就是不稳定的。一般判断有三种方法:
- 画出时间序列的趋势图,看趋势判断
- 画自相关图和偏相关图,平稳时间序列的自相关图和偏相关图,要么拖尾,要么截尾。
- 检验序列中是否存在单位根,如果存在单位根,就是非平稳时间序列。
在R语言中,DF检测是一种检测稳定性的方法,如果得出的P值小于临界值,则认为是序列是稳定的。
- 白噪声检验
白噪声序列,又称为纯随机性序列,序列的各个值之间没有任何的相关关系,序列在进行无序的随机波动,可以终止对该序列的分析,因为从白噪声序列中是提取不到任何有价值的信息的。 - 平稳时间序列的参数特点
均值和方差为常数,并且具有与时间无关的自协方差。
时间序列建模步骤:
- 拿到被分析的时间序列数据集。
- 对数据绘图,观测其平稳性。若为非平稳时间序列要先进行 d 阶差分运算后化为平稳时间序列,此处的 d 即为 ARIMA(p,d,q) 模型中的 d ;若为平稳序列,则用 ARMA(p,q) 模型。所以 ARIMA(p,d,q) 模型区别于 ARMA(p,q) 之处就在于前者的自回归部分的特征多项式含有d个单位根。
- 对得到的平稳时间序列分别求得其自相关系数 ACF 和偏自相关系数 PACF ,通过对自相关图和偏自相关图的分析,得到最佳的阶层 p 和阶数 q。由以上得到的 d、q、p ,得到 ARIMA 模型。
- 模型诊断。进行诊断分析,以证实所得模型确实与所观察到的数据特征相符。若不相符,重新回到第(3)步。
例
考虑从2012年1月开始的一个地方的年降雨量细节。我们创建一个R时间序列对象为期12个月并绘制它。
# Get the data points in form of a R vector. rainfall <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071) # Convert it to a time series object. rainfall.timeseries <- ts(rainfall,start = c(2012,1),frequency = 12) # Print the timeseries data. print(rainfall.timeseries) # Give the chart file a name. png(file = "rainfall.png") # Plot a graph of the time series. plot(rainfall.timeseries) # Save the file. dev.off()
当我们执行上面的代码,它产生以下结果及图表
Jan Feb Mar Apr May Jun Jul Aug Sep
2012 799.0 1174.8 865.1 1334.6 635.4 918.5 685.5 998.6 784.2
Oct Nov Dec
2012 985.0 882.8 1071.0
时间序列图
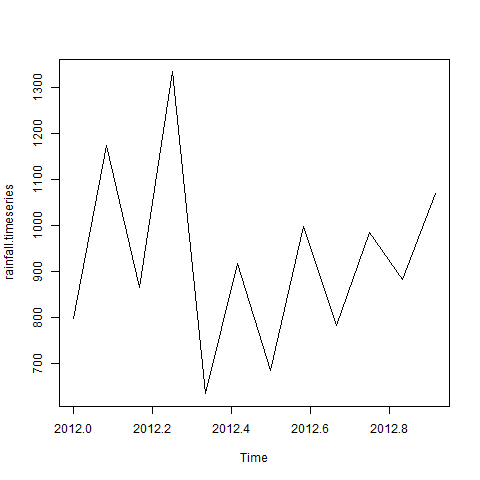
不同的时间间隔
ts()函数中的频率参数值决定了测量数据点的时间间隔。 值为12表示时间序列为12个月。 其他值及其含义如下
- 频率= 12指定一年中每个月的数据点。
- 频率= 4每年的每个季度的数据点。
- 频率= 6每小时的10分钟的数据点。
- 频率= 24 * 6将一天的每10分钟的数据点固定。
多时间序列
我们可以通过将两个系列组合成一个矩阵,在一个图表中绘制多个时间序列。
# Get the data points in form of a R vector.
rainfall1 <- c(799,1174.8,865.1,1334.6,635.4,918.5,685.5,998.6,784.2,985,882.8,1071)
rainfall2 <-
c(655,1306.9,1323.4,1172.2,562.2,824,822.4,1265.5,799.6,1105.6,1106.7,1337.8)
# Convert them to a matrix.
combined.rainfall <- matrix(c(rainfall1,rainfall2),nrow = 12)
# Convert it to a time series object.
rainfall.timeseries <- ts(combined.rainfall,start = c(2012,1),frequency = 12)
# Print the timeseries data.
print(rainfall.timeseries)
# Give the chart file a name.
png(file = "rainfall_combined.png")
# Plot a graph of the time series.
plot(rainfall.timeseries, main = "Multiple Time Series")
# Save the file.
dev.off()
当我们执行上面的代码,它产生以下结果及图表
Series 1 Series 2
Jan 2012 799.0 655.0
Feb 2012 1174.8 1306.9
Mar 2012 865.1 1323.4
Apr 2012 1334.6 1172.2
May 2012 635.4 562.2
Jun 2012 918.5 824.0
Jul 2012 685.5 822.4
Aug 2012 998.6 1265.5
Sep 2012 784.2 799.6
Oct 2012 985.0 1105.6
Nov 2012 882.8 1106.7
Dec 2012 1071.0 1337.8
多时间序列图

到此这篇关于R语言中时间序列分析浅析的文章就介绍到这了,更多相关R语言时间序列分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

利用R语言绘制时间序列图的操作
数据 GDP.csv文件,存储1879~2019年河南省GDP数据 绘图 # 读取数据, 首先将excel 格式的转化为 csv 格式 再读取 h <- read.table(file = "C:/Users/PYY/Desktop/GDP.csv",sep = ",",header = T) # 转化为时间序列数据 GDP=ts(h$GDP,start = 1978,frequency = 1) # 绘图 plot(GDP) 补充:ts函数 ts() 函数:
-
R语言时间序列知识点总结
时间序列对象:变量随着时间变化 时间序列的回归函数(例如ar或arima)通常以时间序列作为参数 许多绘图函数都有针对时间序列对象的特殊方法 ts函数创建时间序列对象 ts(data = NA, start = 1, end = numeric(0), frequency = 1, deltat = 1, ts.eps = getOption("ts.eps"), class = , names = ) data参数指定时间序列的观测值,其他参数指定观测值的起始区间 ts函数参数的含义
-
R语言时间序列TAR阈值自回归模型示例详解
为了方便起见,这些模型通常简称为TAR模型.这些模型捕获了线性时间序列模型无法捕获的行为,例如周期,幅度相关的频率和跳跃现象.Tong和Lim(1980)使用阈值模型表明,该模型能够发现黑子数据出现的不对称周期性行为. 一阶TAR模型的示例: σ是噪声标准偏差,Yt-1是阈值变量,r是阈值参数, {et}是具有零均值和单位方差的iid随机变量序列. 每个线性子模型都称为一个机制.上面是两个机制的模型. 考虑以下简单的一阶TAR模型: #低机制参数 i1 = 0.3 p1 = 0.5 s1 = 1
-
R语言时间序列中时间年、月、季、日的处理操作
1.年 pt<-ts(p, freq = 1, start = 2011) 2.月 pt<-ts(p,frequency=12,start=c(2011,1)) frequency=12表示以月份为单位,start 表示时间开始点,start=c(2011,1) 表示从2011年1月开始 3.季度 pt <- ts(p, frequency = 4, start = c(2011, 1)) 4.天 pt<-ts(p,frequency=7,start=c(2011,1)) 用 ts
-
R语言中时间序列分析浅析
时间序列是将统一统计值按照时间发生的先后顺序来进行排列,时间序列分析的主要目的是根据已有数据对未来进行预测. 一个稳定的时间序列中常常包含两个部分,那么就是:有规律的时间序列+噪声.所以,在以下的方法中,主要的目的就是去过滤噪声值,让我们的时间序列更加的有分析意义. 语法 时间序列分析中ts()函数的基本语法是 timeseries.object.name <- ts(data, start, end, frequency) 以下是所使用的参数的描述 data是包含在时间序列中使用的值的向量或矩
-
详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该
-
R语言日期时间的使用
目录 1.日期和日期时间类型 2.从字符串生成日期数据 3.日期显示格式 4.访问日期时间的组成值 5.日期舍入计算 6.日期计算 6.1 时间长度 6.2 时间周期 6.3 时间区间 7.基本R软件的日期功能 7.1 生成日期和日期时间型数据 7.2 取出日期时间的组成值 7.3 日期计算 练习 1.日期和日期时间类型 R 中日期可以保存为 Date 类型,一般用整数保存,数值为从 1970-1-1 经过的天数. R 中用一种叫做 POSIXct 和 POSIXlt 的特殊数据类型保存日期和
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
R语言中向量和矩阵简单运算的实现
一.向量运算 向量是有相同基本类型的元素序列,一维数组,定义向量的最常用办法是使用函数c(),它把若干个数值或字符串组合为一个向量. 1.R语言向量的产生方法 > x <- c(1,2,3) > x [1] 1 2 3 2.向量加减乘除都是对其对应元素进行的,例如下面 > x <- c(1,2,3) > y <- x*2 > y [1] 2 4 6 (注:向量的整数除法是%/%,取余是%%.) 3.向量的内积,有两种方法. 第一种方法:%*% > x
-
R语言中对数据框的列名重命名的实现
报错类型 Error: All arguments must be named plyr中的rename和dplyr中的rename用法是不同的. plyr::rename rename(data, c(old=new)) dplyr::rename rename(data, new = old) Example 比如, 默认的是plyr的rename, 运行下面命令, 会报错: d <- data.frame(old1=1:3, old2=4:6, old3=7:9) d library(ti
-
详解R语言中的表达式、数学公式、特殊符号
在R语言的绘图函数中,如果文本参数是合法的R语言表达式,那么这个表达式就被用Tex类似的规则进行文本格式化. y <- function(x) (exp(-(x^2)/2))/sqrt(2*pi) plot(y, -5, 5, main = expression(f(x) == frac(1,sqrt(2*pi))*e^(-frac(x^2,2))), lwd = 3, col = "blue") library(ggplot2) x <- seq(0, 2*pi, b
-
R语言中矩阵matrix和数据框data.frame的使用详解
本文主要介绍了R语言中矩阵matrix和数据框data.frame的一些使用,分享给大家,具体如下: "一,矩阵matrix" "创建向量" x_1=c(1,2,3) x_1=c(1:3) x_2=1:3 typeof(x_1)==typeof(x_2)#查看目标类型 x_3=seq(1,6,length=3)#将1--6分为3个数 a<-rep(1:3,each=3) #1到3依次重复 c<-rep(1:3,times=3) #1到3重复3次 d<
-
R语言中常见的几种创建矩阵形式总结
矩阵概述 R语言的实质实质上是与matlab差不多的,都是以矩阵为基础的 在R语言中,矩阵(matrix)是将数据按行和列组织数据的一种数据对象,相当于二维数组,可以用于描述二维的数据.与向量相似,矩阵的每个元素都拥有相同的数据类型.通常用列来表示来自不同变量的数据,用行来表示相同的数据. R中创建矩阵的语法格式 在R语言中可以使用matrix()函数来创建矩阵,其语法格式如下: matrix(data=NA, nrow = 1, ncol = 1, byrow = FALSE, dimname
-
R语言中字符串的拼接操作实例讲解
在R语言中 paste 是一个很有用的字符串处理函数,可以连接不同类型的变量及常量. 函数paste的一般使用格式为: paste(..., sep = " ", collapse = NULL) 其 中-表示一个或多个R可以被转化为字符型的对象:参数sep表示分隔符,默认为空格:参数collapse可选,如果不指定值,那么函数paste的返回值是自变量之间通过sep指定的分隔符连接后得到的一个字符型向量:如果为其指定了特定的值,那么自变量连接后的字符型向量会再被连接成一个字符串,之间