Python深度学习之使用Pytorch搭建ShuffleNetv2
一、model.py
1.1 Channel Shuffle
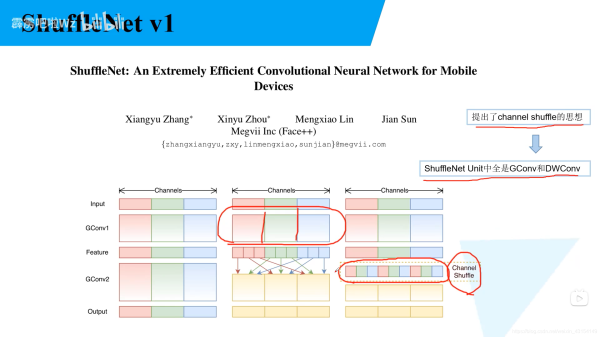

def channel_shuffle(x: Tensor, groups: int) -> Tensor:
batch_size, num_channels, height, width = x.size()
channels_per_group = num_channels // groups
# reshape
# [batch_size, num_channels, height, width] -> [batch_size, groups, channels_per_group, height, width]
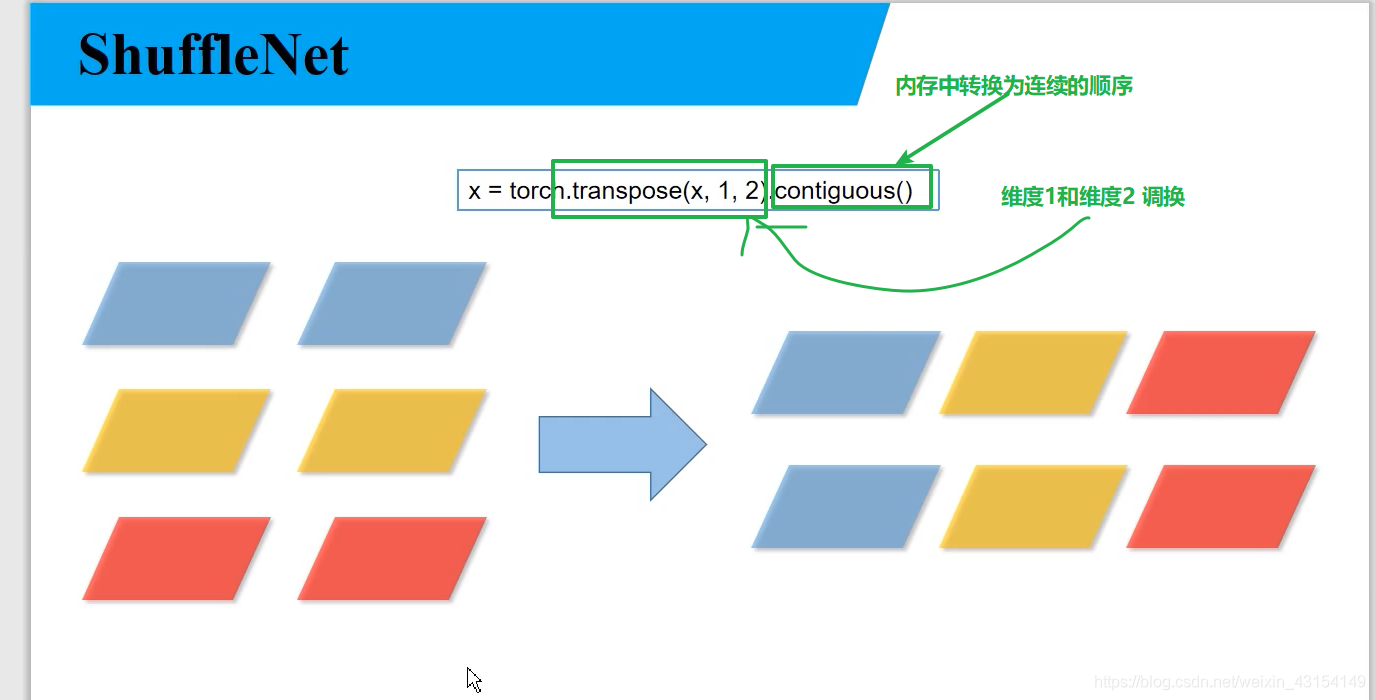
x = x.view(batch_size, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
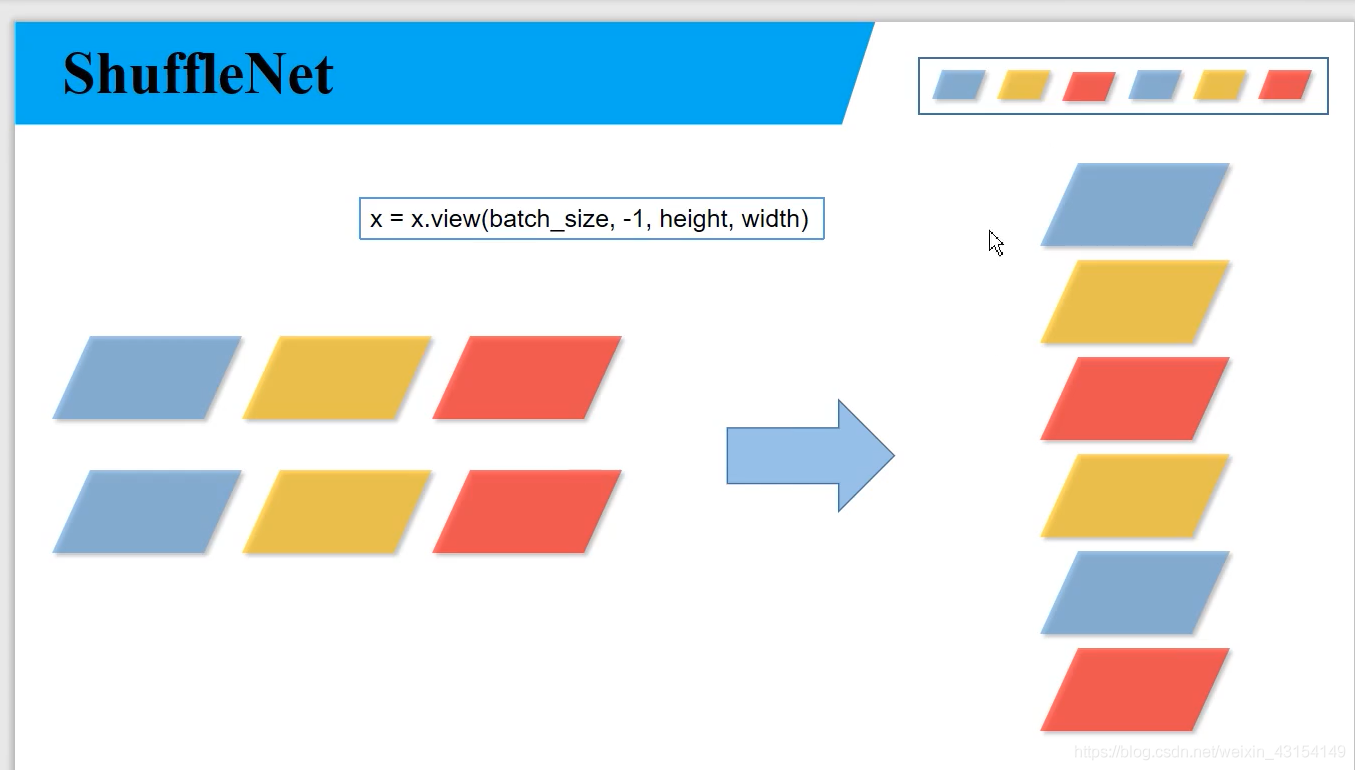
# flatten
x = x.view(batch_size, -1, height, width)
return x
1.2 block

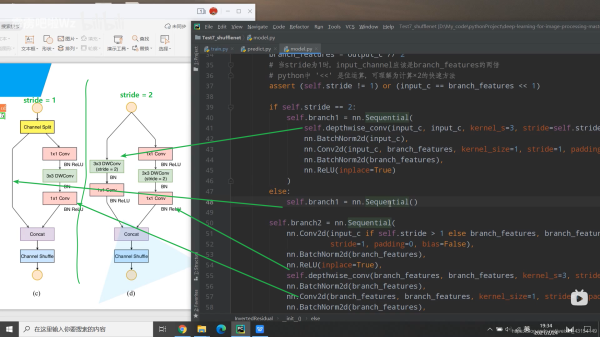
class InvertedResidual(nn.Module):
def __init__(self, input_c: int, output_c: int, stride: int):
super(InvertedResidual, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.stride = stride
assert output_c % 2 == 0
branch_features = output_c // 2
# 当stride为1时,input_channel应该是branch_features的两倍
# python中 '<<' 是位运算,可理解为计算×2的快速方法
assert (self.stride != 1) or (input_c == branch_features << 1)
if self.stride == 2:
self.branch1 = nn.Sequential(
self.depthwise_conv(input_c, input_c, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else:
self.branch1 = nn.Sequential()
self.branch2 = nn.Sequential(
nn.Conv2d(input_c if self.stride > 1 else branch_features, branch_features, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_s=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c: int,
output_c: int,
kernel_s: int,
stride: int = 1,
padding: int = 0,
bias: bool = False) -> nn.Conv2d:
return nn.Conv2d(in_channels=input_c, out_channels=output_c, kernel_size=kernel_s,
stride=stride, padding=padding, bias=bias, groups=input_c)
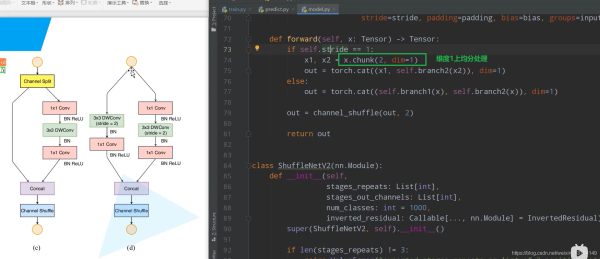
def forward(self, x: Tensor) -> Tensor:
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
1.3 shufflenet v2
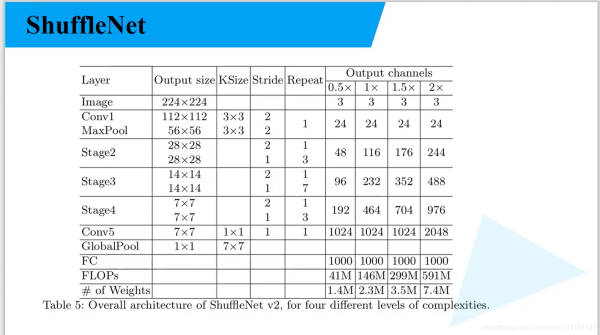
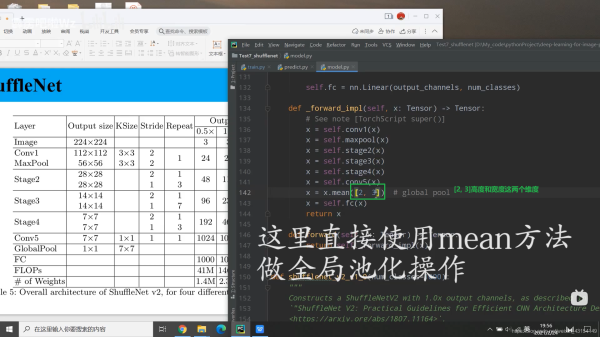
class ShuffleNetV2(nn.Module):
def __init__(self,
stages_repeats: List[int],
stages_out_channels: List[int],
num_classes: int = 1000,
inverted_residual: Callable[..., nn.Module] = InvertedResidual):
super(ShuffleNetV2, self).__init__()
if len(stages_repeats) != 3:
raise ValueError("expected stages_repeats as list of 3 positive ints")
if len(stages_out_channels) != 5:
raise ValueError("expected stages_out_channels as list of 5 positive ints")
self._stage_out_channels = stages_out_channels
# input RGB image
input_channels = 3
output_channels = self._stage_out_channels[0]
self.conv1 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels = output_channels
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Static annotations for mypy
self.stage2: nn.Sequential
self.stage3: nn.Sequential
self.stage4: nn.Sequential
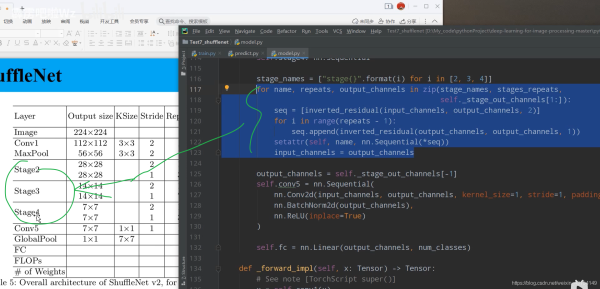
stage_names = ["stage{}".format(i) for i in [2, 3, 4]]
for name, repeats, output_channels in zip(stage_names, stages_repeats,
self._stage_out_channels[1:]):
seq = [inverted_residual(input_channels, output_channels, 2)]
for i in range(repeats - 1):
seq.append(inverted_residual(output_channels, output_channels, 1))
setattr(self, name, nn.Sequential(*seq))
input_channels = output_channels
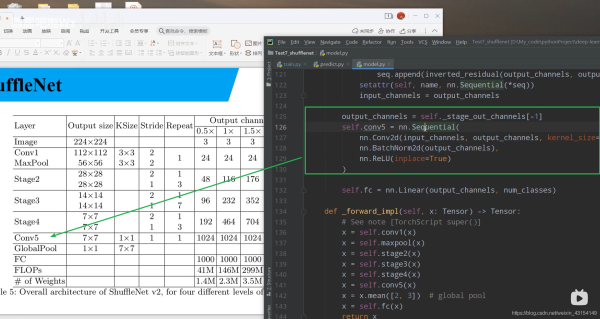
output_channels = self._stage_out_channels[-1]
self.conv5 = nn.Sequential(
nn.Conv2d(input_channels, output_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(output_channels, num_classes)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.maxpool(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = x.mean([2, 3]) # global pool
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
二、train.py
到此这篇关于Python深度学习之使用Pytorch搭建ShuffleNetv2的文章就介绍到这了,更多相关Python用Pytorch搭建ShuffleNetv2内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python PyTorch参数初始化和Finetune
前言 这篇文章算是论坛PyTorch Forums关于参数初始化和finetune的总结,也是我在写代码中用的算是"最佳实践"吧.最后希望大家没事多逛逛论坛,有很多高质量的回答. 参数初始化 参数的初始化其实就是对参数赋值.而我们需要学习的参数其实都是Variable,它其实是对Tensor的封装,同时提供了data,grad等借口,这就意味着我们可以直接对这些参数进行操作赋值了.这就是PyTorch简洁高效所在. 所以我们可以进行如下操作进行初始化,当然其实有其他的方法,但是这种方法
-
python、PyTorch图像读取与numpy转换实例
Tensor转为numpy np.array(Tensor) numpy转换为Tensor torch.Tensor(numpy.darray) PIL.Image.Image转换成numpy np.array(PIL.Image.Image) numpy 转换成PIL.Image.Image Image.fromarray(numpy.ndarray) 首先需要保证numpy.ndarray 转换成np.uint8型 numpy.astype(np.uint8),像素值[0,255]. 同时灰
-
python PyTorch预训练示例
前言 最近使用PyTorch感觉妙不可言,有种当初使用Keras的快感,而且速度还不慢.各种设计直接简洁,方便研究,比tensorflow的臃肿好多了.今天让我们来谈谈PyTorch的预训练,主要是自己写代码的经验以及论坛PyTorch Forums上的一些回答的总结整理. 直接加载预训练模型 如果我们使用的模型和原模型完全一样,那么我们可以直接加载别人训练好的模型: my_resnet = MyResNet(*args, **kwargs) my_resnet.load_state_dict(
-
浅谈pytorch、cuda、python的版本对齐问题
在使用深度学习模型训练的过程中,工具的准备也算是一个良好的开端吧.熟话说完事开头难,磨刀不误砍柴工,先把前期的问题搞通了,能为后期节省不少精力. 以pytorch工具为例: pytorch版本为1.0.1,自带python版本为3.6.2 服务器上GPU的CUDA_VERSION=9000 注意:由于GPU上的CUDA_VERSION为9000,所以至少要安装cuda版本>=9.0,虽然cuda=7.0~8.0也能跑,但是一开始可能会遇到各种各样的问题,本人cuda版本为10.0,安装cuda的
-
python 如何查看pytorch版本
看代码吧~ import torch print(torch.__version__) 补充:pytorch不同版本安装以及版本查看 一:基于conda安装 conda create --name pytorch_learn python=3.6.7#创建一个名为pytorch_learn的环境 source activate pytorch_learn #进入环境 conda install pytorch=0.3.1 cuda80 -c soumith #安装pytorch0.3.1+ cu
-
基于python及pytorch中乘法的使用详解
numpy中的乘法 A = np.array([[1, 2, 3], [2, 3, 4]]) B = np.array([[1, 0, 1], [2, 1, -1]]) C = np.array([[1, 0], [0, 1], [-1, 0]]) A * B : # 对应位置相乘 np.array([[ 1, 0, 3], [ 4, 3, -4]]) A.dot(B) : # 矩阵乘法 ValueError: shapes (2,3) and (2,3) not aligned: 3 (dim
-
简述python&pytorch 随机种子的实现
随机数广泛应用在科学研究, 但是计算机无法产生真正的随机数, 一般成为伪随机数. 它的产生过程: 给定一个随机种子(一个正整数), 根据随机算法和种子产生随机序列. 给定相同的随机种子, 计算机产生的随机数列是一样的(这也许是伪随机的原因). 随机种子是什么? 随机种子是针对随机方法而言的. 随机方法:常见的随机方法有 生成随机数,以及其他的像 随机排序 之类的,后者本质上也是基于生成随机数来实现的.在深度学习中,比较常用的随机方法的应用有:网络的随机初始化,训练集的随机打乱等. 随机种子的取值
-
Python深度学习之使用Pytorch搭建ShuffleNetv2
一.model.py 1.1 Channel Shuffle def channel_shuffle(x: Tensor, groups: int) -> Tensor: batch_size, num_channels, height, width = x.size() channels_per_group = num_channels // groups # reshape # [batch_size, num_channels, height, width] -> [batch_size
-
Python深度学习之Pytorch初步使用
一.Tensor Tensor(张量是一个统称,其中包括很多类型): 0阶张量:标量.常数.0-D Tensor:1阶张量:向量.1-D Tensor:2阶张量:矩阵.2-D Tensor:-- 二.Pytorch如何创建张量 2.1 创建张量 import torch t = torch.Tensor([1, 2, 3]) print(t) 2.2 tensor与ndarray的关系 两者之间可以相互转化 import torch import numpy as np t1 = np.arra
-
Python深度学习pyTorch权重衰减与L2范数正则化解析
下面进行一个高维线性实验 假设我们的真实方程是: 假设feature数200,训练样本和测试样本各20个 模拟数据集 num_train,num_test = 10,10 num_features = 200 true_w = torch.ones((num_features,1),dtype=torch.float32) * 0.01 true_b = torch.tensor(0.5) samples = torch.normal(0,1,(num_train+num_test,num_fe
-
Python深度学习pytorch卷积神经网络LeNet
目录 LeNet 模型训练 在本节中,我们将介绍LeNet,它是最早发布的卷积神经网络之一.这个模型是由AT&T贝尔实验室的研究院Yann LeCun在1989年提出的(并以其命名),目的是识别手写数字.当时,LeNet取得了与支持向量机性能相媲美的成果,成为监督学习的主流方法.LeNet被广泛用于自动取款机中,帮助识别处理支票的数字. LeNet 总体来看,LeNet(LeNet-5)由两个部分组成: 卷积编码器: 由两个卷积层组成 全连接层密集快: 由三个全连接层组成 每个卷积块中的基本单元
-
Python深度学习理解pytorch神经网络批量归一化
目录 训练深层网络 为什么要批量归一化层呢? 批量归一化层 全连接层 卷积层 预测过程中的批量归一化 使用批量归一化层的LeNet 简明实现 争议 训练深层神经网络是十分困难的,特别是在较短的实践内使他们收敛更加棘手.在本节中,我们将介绍批量归一化(batch normalization),这是一种流行且有效的技术,可持续加速深层网络的收敛速度.在结合之后将介绍的残差快,批量归一化使得研究人员能够训练100层以上的网络. 训练深层网络 为什么要批量归一化层呢? 让我们回顾一下训练神经网络时出现的
-
Python深度学习pytorch神经网络Dropout应用详解解
目录 扰动的鲁棒性 实践中的dropout 简洁实现 扰动的鲁棒性 在之前我们讨论权重衰减(L2正则化)时看到的那样,参数的范数也代表了一种有用的简单性度量.简单性的另一个有用角度是平滑性,即函数不应该对其输入的微笑变化敏感.例如,当我们对图像进行分类时,我们预计向像素添加一些随机噪声应该是基本无影响的. dropout在正向传播过程中,计算每一内部层同时注入噪声,这已经成为训练神经网络的标准技术.这种方法之所以被称为dropout,因为我们从表面上看是在训练过程中丢弃(drop out)一些
-
Python深度学习pytorch神经网络图像卷积运算详解
目录 互相关运算 卷积层 特征映射 由于卷积神经网络的设计是用于探索图像数据,本节我们将以图像为例. 互相关运算 严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是卷积运算.在卷积层中,输入张量和核张量通过互相关运算产生输出张量. 首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示.下图中,输入是高度为3.宽度为3的二维张量(即形状为 3 × 3 3\times3 3×3).卷积核的高度和宽度都是2. 注意,
-
Python深度学习pytorch神经网络填充和步幅的理解
目录 填充 步幅 上图中,输入的高度和宽度都为3,卷积核的高度和宽度都为2,生成的输出表征的维度为 2 × 2 2\times2 2×2.从上图可看出卷积的输出形状取决于输入形状和卷积核的形状. 填充 以上面的图为例,在应用多层卷积时,我们常常丢失边缘像素. 解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是0). 例如,在上图中我们将 3 × 3 3\times3 3×3输入填充到 5 × 5 5\times5 5×5,那么它的输出就增加为 4 × 4
-
Python深度学习pytorch神经网络多输入多输出通道
目录 多输入通道 多输出通道 1 × 1 1\times1 1×1卷积层 虽然每个图像具有多个通道和多层卷积层.例如彩色图像具有标准的RGB通道来指示红.绿和蓝.但是到目前为止,我们仅展示了单个输入和单个输出通道的简化例子.这使得我们可以将输入.卷积核和输出看作二维张量. 当我们添加通道时,我们的输入和隐藏的表示都变成了三维张量.例如,每个RGB输入图像具有 3 × h × w 3\times{h}\times{w} 3×h×w的形状.我们将这个大小为3的轴称为通道(channel)维度.在本节
-
Python深度学习pytorch神经网络汇聚层理解
目录 最大汇聚层和平均汇聚层 填充和步幅 多个通道 我们的机器学习任务通常会跟全局图像的问题有关(例如,"图像是否包含一只猫呢?"),所以我们最后一层的神经元应该对整个输入的全局敏感.通过逐渐聚合信息,生成越来越粗糙的映射,最终实现学习全局表示的目标,同时将卷积图层的所有有时保留在中间层. 此外,当检测较底层的特征时(例如之前讨论的边缘),我们通常希望这些特征保持某种程度上的平移不变性.例如,如果我们拍摄黑白之间轮廓清晰的图像X,并将整个图像向右移动一个像素,即Z[i, j] = X[