python爬虫---requests库的用法详解
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多
因为是第三方库,所以使用前需要cmd安装
pip install requests
安装完成后import一下,正常则说明可以开始使用了。
基本用法:
requests.get()用于请求目标网站,类型是一个HTTPresponse类型
import requests
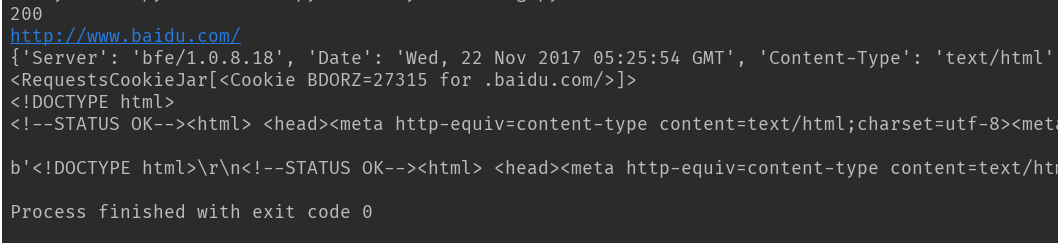
response = requests.get('http://www.baidu.com')print(response.status_code) # 打印状态码print(response.url) # 打印请求urlprint(response.headers) # 打印头信息print(response.cookies) # 打印cookie信息print(response.text) #以文本形式打印网页源码print(response.content) #以字节流形式打印
运行结果:
状态码:200
url:www.baidu.com
headers信息
各种请求方式:
import requests
requests.get('http://httpbin.org/get')
requests.post('http://httpbin.org/post')
requests.put('http://httpbin.org/put')
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
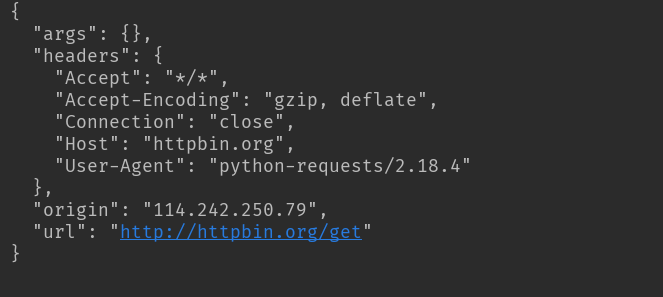
基本的get请求
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
结果
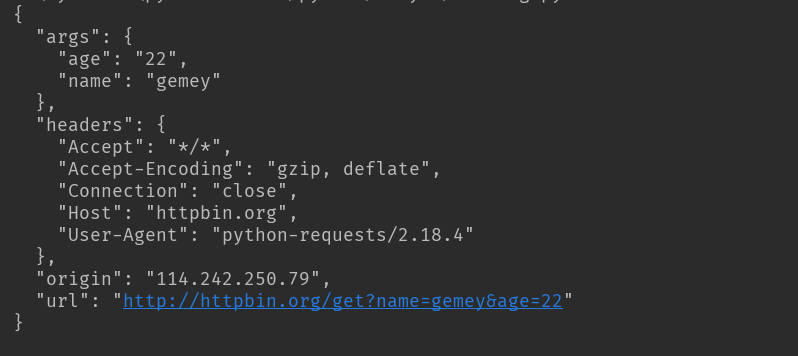
带参数的GET请求:
第一种直接将参数放在url内
import requests response = requests.get(http://httpbin.org/get?name=gemey&age=22) print(response.text)
结果
另一种先将参数填写在dict中,发起请求时params参数指定为dict
import requests
data = {
'name': 'tom',
'age': 20
}
response = requests.get('http://httpbin.org/get', params=data)
print(response.text)
结果同上
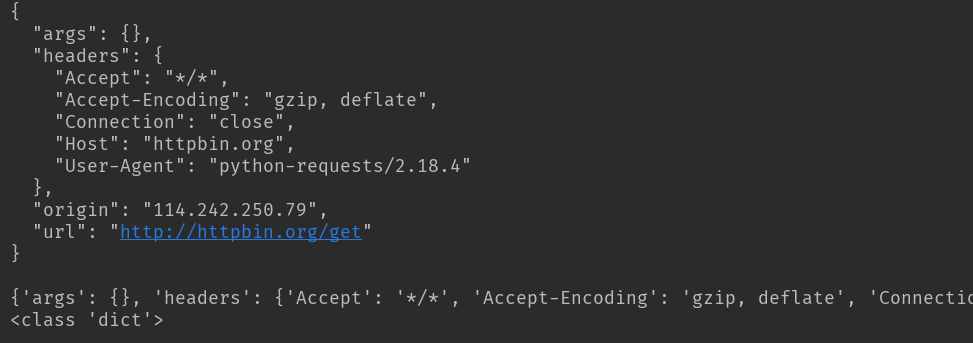
解析json
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
print(response.json()) #response.json()方法同json.loads(response.text)
print(type(response.json()))
结果
简单保存一个二进制文件
二进制内容为response.content
import requests
response = requests.get('http://img.ivsky.com/img/tupian/pre/201708/30/kekeersitao-002.jpg')
b = response.content
with open('F://fengjing.jpg','wb') as f:
f.write(b)
为你的请求添加头信息
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('http://www.baidu.com',headers=headers)
使用代理
同添加headers方法,代理参数也要是一个dict
这里使用requests库爬取了IP代理网站的IP与端口和类型
因为是免费的,使用的代理地址很快就失效了。
import requests
import re
def get_html(url):
proxy = {
'http': '120.25.253.234:812',
'https' '163.125.222.244:8123'
}
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
req = requests.get(url, headers=heads,proxies=proxy)
html = req.text
return html
def get_ipport(html):
regex = r'<td data-title="IP">(.+)</td>'
iplist = re.findall(regex, html)
regex2 = '<td data-title="PORT">(.+)</td>'
portlist = re.findall(regex2, html)
regex3 = r'<td data-title="类型">(.+)</td>'
typelist = re.findall(regex3, html)
sumray = []
for i in iplist:
for p in portlist:
for t in typelist:
pass
pass
a = t+','+i + ':' + p
sumray.append(a)
print('高匿代理')
print(sumray)
if __name__ == '__main__':
url = 'http://www.kuaidaili.com/free/'
get_ipport(get_html(url))
结果:

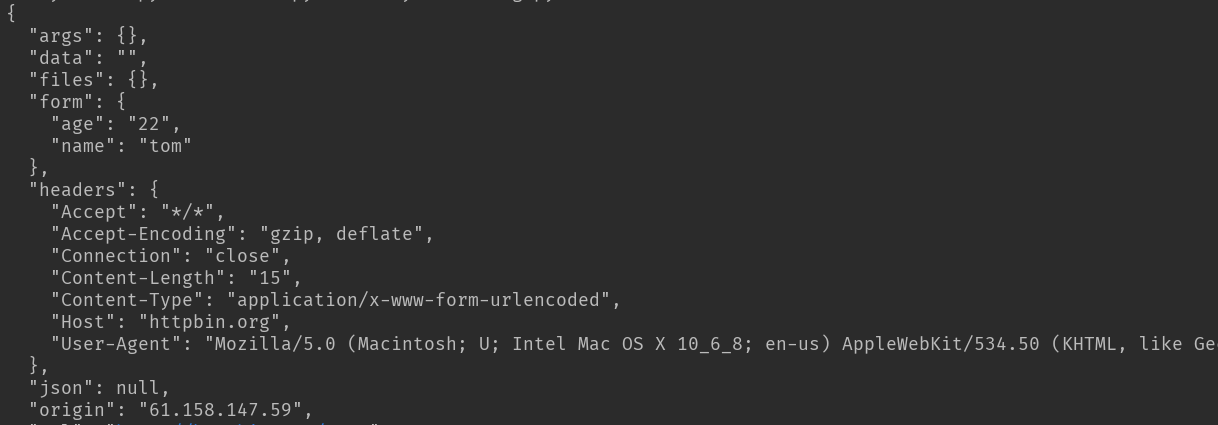
基本POST请求:
import requests
data = {'name':'tom','age':'22'}
response = requests.post('http://httpbin.org/post', data=data)
获取cookie
#获取cookie
import requests
response = requests.get('http://www.baidu.com')
print(response.cookies)
print(type(response.cookies))
for k,v in response.cookies.items():
print(k+':'+v)
结果:

会话维持
import requests
session = requests.Session()
session.get('http://httpbin.org/cookies/set/number/12345')
response = session.get('http://httpbin.org/cookies')
print(response.text)
结果:
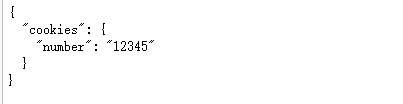
证书验证设置
import requests
from requests.packages import urllib3
urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get('https://www.12306.cn',verify=False) #证书验证设为FALSE
print(response.status_code)打印结果:200
超时异常捕获
import requests
from requests.exceptions import ReadTimeout
try:
res = requests.get('http://httpbin.org', timeout=0.1)
print(res.status_code)
except ReadTimeout:
print(timeout)
异常处理
在你不确定会发生什么错误时,尽量使用try...except来捕获异常
所有的requests exception:
Exceptions
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException
try:
response = requests.get('http://www.baidu.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')
25行代码带你爬取4399小游戏数据
import requests
import parsel
import csv
f = open('4399游戏.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['游戏地址', '游戏名字'])
csv_writer.writeheader()
for page in range(1, 106):
url = 'http://www.4399.com/flash_fl/5_{}.htm'.format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding
selector = parsel.Selector(response.text)
lis = selector.css('#classic li')
for li in lis:
dit ={}
data_url = li.css('a::attr(href)').get()
new_url = 'http://www.4399.com' + data_url.replace('http://', '/')
dit['游戏地址'] = new_url
title = li.css('img::attr(alt)').get()
dit['游戏名字'] = title
print(new_url, title)
csv_writer.writerow(dit)
f.close()
到此这篇关于python爬虫---requests库的用法详解的文章就介绍到这了,更多相关python requests库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬取微信小程序通用方法代码实例详解
背景介绍 最近遇到一个需求,大致就是要获取某个小程序上的数据.心想小程序本质上就是移动端加壳的浏览器,所以想到用Python去获取数据.在网上学习了一下如何实现后,记录一下我的实现过程以及所踩过的小坑.本文关键词:Python,小程序,Charles抓包 目标小程序: 公众号"同城商圈网"左下角"找商家"->汽车维修->小车维修->所有的商家信息,如下图所示: 环境 PC端:Windows 10 移动端:iPhone 软件:Charles Char
-
python爬取代理IP并进行有效的IP测试实现
爬取代理IP及测试是否可用 很多人在爬虫时为了防止被封IP,所以就会去各大网站上查找免费的代理IP,由于不是每个IP地址都是有效的,如果要进去一个一个比对的话效率太低了,我也遇到了这种情况,所以就直接尝试了一下去网站爬取免费的代理IP,并且逐一的测试,最后将有效的IP进行返回. 在这里我选择的是89免费代理IP网站进行爬取,并且每一个IP都进行比对测试,最后会将可用的IP进行另存放为一个列表 https://www.89ip.cn/ 一.准备工作 导入包并且设置头标签 import reques
-
Python爬取微信小程序Charles实现过程图解
一.前言 最近需要获取微信小程序上的数据进行分析处理,第一时间想到的方式就是采用python爬虫爬取数据,尝试后发现诸多问题,比如无法获取目标网址.解析网址中存在指定参数的不确定性.加密问题等等,经过一番尝试,终于使用 Charles 抓取到指定微信小程序中的数据,本文进行记录并总结. 环境配置: 电脑:Windows10,连接有线网 手机:iPhone Xr,连接无线网 注:有线网与无线网最好位于同一网段下. 本文有线网网址:192.168.131.24,无线网网址:192.168.210.2
-
Python爬虫代理池搭建的方法步骤
一.为什么要搭建爬虫代理池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑.在一段时间内禁止访问. 应对的方法有两种: 1. 降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率. 2. 搭建一个IP代理池,使用不同的IP轮流进行爬取. 二.搭建思路 1.从代理网站(如:西刺代理.快代理.云代理.无忧代理)爬取代理IP: 2.验证代理IP的可用性(使用代理IP去请求指定URL,根据响应验证
-
Python爬虫抓取论坛关键字过程解析
前言: 之前学习了用python爬虫的基本知识,现在计划用爬虫去做一些实际的数据统计功能.由于前段时间演员的诞生带火了几个年轻的实力派演员,想用爬虫程序搜索某论坛中对于某些演员的讨论热度,并按照日期统计每天的讨论量. 这个项目总共分为两步: 1.获取所有帖子的链接: 将最近一个月内的帖子链接保存到数组中 2.从回帖中搜索演员名字: 从数组中打开链接,翻出该链接的所有回帖,在回帖中查找演员的名字 获取所有帖子的链接: 搜索的范围依然是以虎扑影视区为界限.虎扑影视区一天约5000个回帖,一月下来超过
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
python爬取”顶点小说网“《纯阳剑尊》的示例代码
爬取"顶点小说网"<纯阳剑尊> 代码 import requests from bs4 import BeautifulSoup # 反爬 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, \ like Gecko) Chrome/70.0.3538.102 Safari/537.36' } # 获得请求 def open_url(url):
-
python使用bs4爬取boss直聘静态页面
思路: 1.将需要查询城市列表,通过城市接口转换成相应的code码 2.遍历城市.职位生成url 3.通过url获取列表页面信息,遍历列表页面信息 4.再根据列表页面信息的job_link获取详情页面信息,将需要的信息以字典data的形式存在列表datas里 5.判断列表页面是否有下一页,重复步骤3.4:同时将列表datas一直传递下去 6.一个城市.职位url爬取完后,将列表datas接在列表datas_list后面,重复3.4.5 7.最后将列表datas_list的数据,遍历写在Excel
-
python爬虫---requests库的用法详解
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下,正常则说明可以开始使用了. 基本用法: requests.get()用于请求目标网站,类型是一个HTTPresponse类型 import requests response = requests.get('http://www.baidu.com')print(response.status_c
-
Python中requests库的用法详解
目录 一.requests库 安装 请求 响应 二.发送get请求 1.一个带参数的get请求: 2.响应json 3.添加头信息headers 4.添加和获取cookie信息 三.发送post请求 1.一个带参数的Post请求: 2.传递JSON数据 3.文件上传 四.高级应用 1.session会话维持 2.身份验证 3.代理设置 4.证书验证 5.超时时间 6.重定向与请求历史 7.其他 五.异常处理 六.requests库和urllib包对比 1.使用urllib.request 2.使
-
Python的信号库Blinker用法详解
作为一个信号库,使用时候是支持一对一以及一对多的订阅模式,可以实现发送数据等,一般情况下,只要能够使用到Blinker的,一般都是应用在技术设计以及垃圾回收上等等,以上就是关于Blinker库的基本信息,具体的情况,小编将详细的为大家介绍讲解,好啦一起来了解看下吧. 安装环境: Python 3.6.4 安装方式: pip install blinker 使用实例: In [1]: from blinker import signal In [2]: a = signal('signal_tes
-
Python中selenium库的用法详解
selenium主要是用来做自动化测试,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题. 模拟浏览器进行网页加载,当requests,urllib无法正常获取网页内容的时候 一.声明浏览器对象 注意点一,Python文件名或者包名不要命名为selenium,会导致无法导入 from selenium import webdriver #webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器,这里以Chrome为例 browser = w
-

Python Pillow(PIL)库的用法详解
Pillow库是一个Python的第三方库. 在Python2中,PIL(Python Imaging Library)是一个非常好用的图像处理库,但PIL不支持Python3,所以有人(Alex Clark和Contributors)提供了Pillow,可以在Python3中使用. 官方文档路径:https://pillow.readthedocs.io/en/latest/ 一.安装Pillow pip install pillow Pillow库安装成功后,导包时要用PIL来导入,而不能用
-
python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基
-
Python中requests库的学习方法详解
目录 前言 一 URL,URI和URN 1. URL,URI和URN 2. URL的组成 二 请求组成 1. 请求方法 2. 请求网址 3. 请求头 4. 请求体 三 请求 1. get请求 2. get带请求头headers参数 3. post请求 四 响应 1. 响应状态码 2. 响应头 3. 响应体 总结 前言 好记性不如烂笔头!最近在接口测试,以及爬虫相关,需要用到Python中的requests库,之前用过,但是好久没有用又忘了,这次就把这块的简单整理下(个人笔记使用) 一 URL,U
-
Python 中拼音库 PyPinyin 用法详解
最近碰到了一个问题,项目中很多文件都是接手过来的中文命名的一些素材,结果在部署的时候文件名全都乱码了,导致项目无法正常运行. 后来请教了一位大佬怎么解决文件名乱码的问题,他说这个需要正面解决吗?不需要,把文件名全部改掉,文件名永远不要用中文,永远不要. 我想他这么说的话,一定也是凭经验得出来的. 这里也友情提示大家,项目里面文件永远不要用中文,永远不要! 好,那不用中文用啥?平时来看,一般我们都会用英文来命名,一般也不会出现中文,比如 resource, controller, result,
-
Python爬虫requests库多种用法实例
requests安装和使用 下载安装:pip install requests #requests模块 import requests #发送请求 content:以二进制的形式获取网页的内容 response=requests.get("http://www.baidu.com").content.decode() #response=requests.request("get","http://www.baidu.com").content.
-
python爬虫之requests库的使用详解
目录 python爬虫-requests库的用法 基本的get请求 带参数的GET请求: 解析json 使用代理 获取cookie 会话维持 证书验证设置 超时异常捕获 异常处理 总结 python爬虫-requests库的用法 requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,requests 允许你发送 HTTP/1.1 请求.指定 URL并添加查询url字符串即可开始爬取网页信息等操作 因为是第三方库,所以使用前需要cmd安装 pip install