基于python爬取链家二手房信息代码示例
基本环境配置
- python 3.6
- pycharm
- requests
- parsel
- time
相关模块pip安装即可
确定目标网页数据
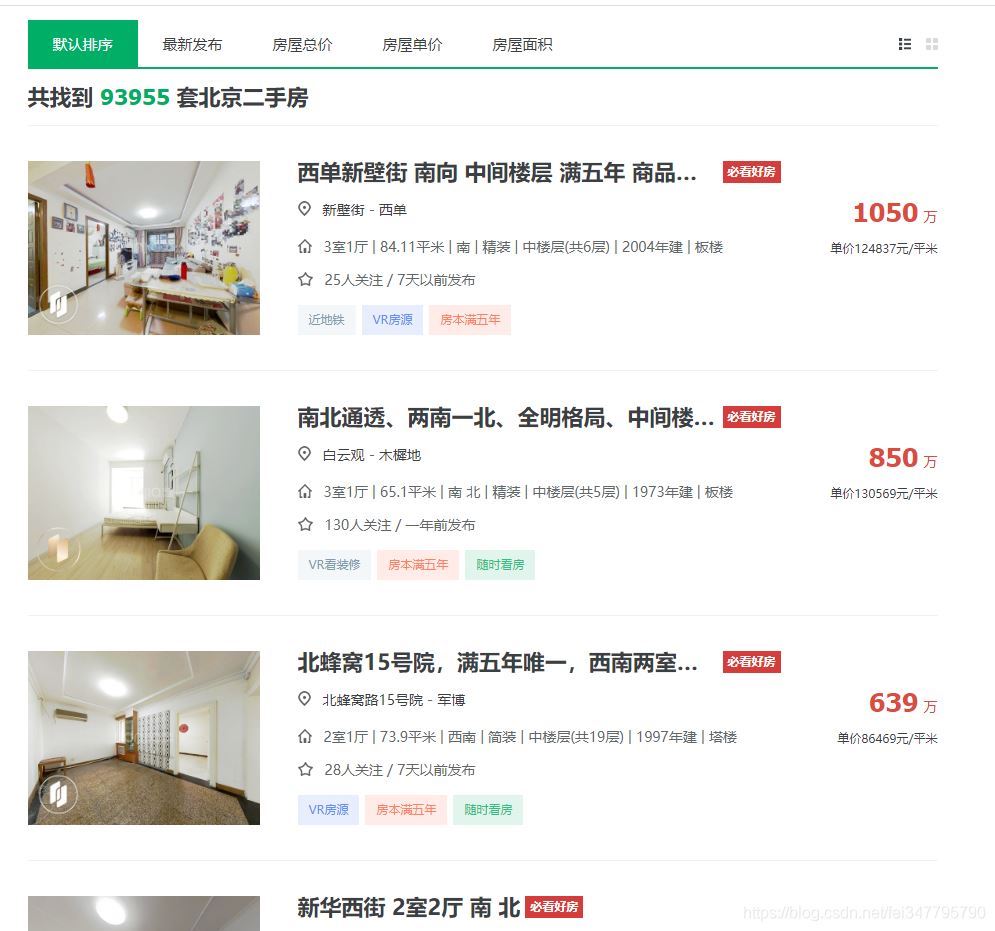
哦豁,这个价格..................看到都觉得脑阔疼
通过开发者工具,可以直接找到网页返回的数据~
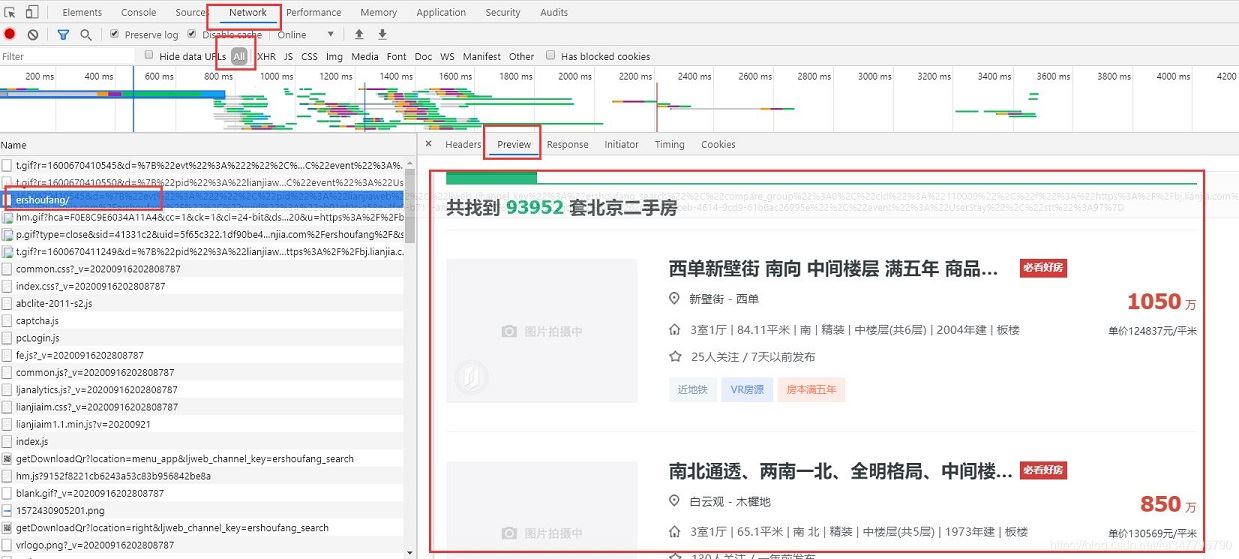
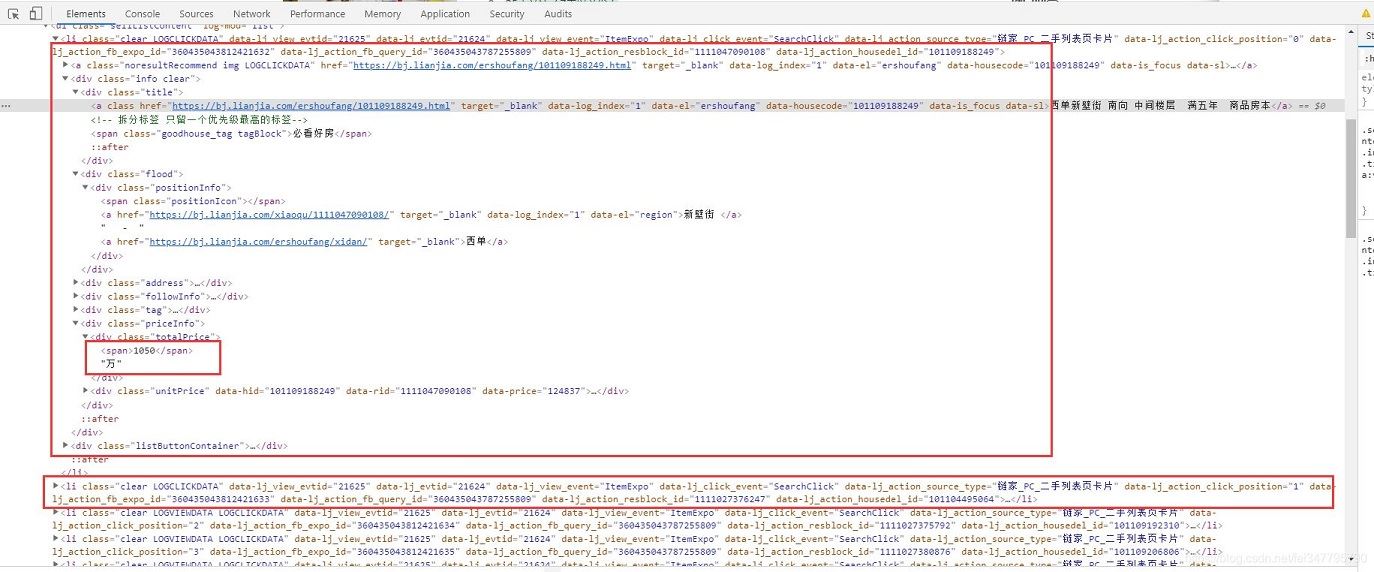
每一个二手房的数据,都在网页的 li 标签里面,咱们可以获取网页返回的数据,然后通过解析,就可以获取到自己想要的数据了~
获取网页数据
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
解析网页数据
import parsel
selector = parsel.Selector(response.text)
lis = selector.css('.sellListContent li')
dit = {}
for li in lis:
title = li.css('.title a::text').get()
dit['标题'] = title
positionInfo = li.css('.positionInfo a::text').getall()
info = '-'.join(positionInfo)
dit['开发商'] = info
houseInfo = li.css('.houseInfo::text').get()
dit['房子信息'] = houseInfo
followInfo = li.css('.followInfo::text').get()
dit['发布周期'] = followInfo
Price = li.css('.totalPrice span::text').get()
dit['售价/万'] = Price
unitPrice = li.css('.unitPrice span::text').get()
dit['单价'] = unitPrice
csv_writer.writerow(dit)
print(dit)

保存数据
import csv
f = open('二手房信息.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '开发商', '房子信息', '发布周期', '售价/万', '单价'])
csv_writer.writeheader()
csv_writer.writerow(dit)
f.close()
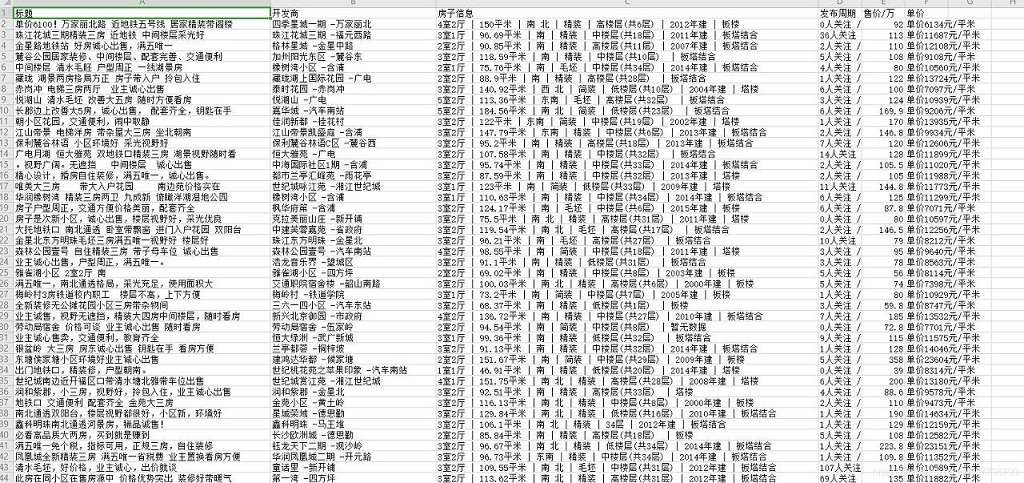
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python CSS选择器爬取京东网商品信息过程解析
CSS选择器 目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup使用的技术书籍和博客软文并不多,而在这仅有的资料中介绍CSS选择器的少之又少.在网络爬虫的页面解析中,CCS选择器实际上是一把效率甚高的利器.虽然资料不多,但官方文档却十分详细,然而美中不足的是需要一定的基础才能看懂,而且没有小而精的演示实例. 京东商品图 首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求.在这里小编仍以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://s
-

Python如何使用BeautifulSoup爬取网页信息
这篇文章主要介绍了Python如何使用BeautifulSoup爬取网页信息,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 简单爬取网页信息的思路一般是 1.查看网页源码 2.抓取网页信息 3.解析网页内容 4.储存到文件 现在使用BeautifulSoup解析库来爬取刺猬实习Python岗位薪资情况 一.查看网页源码 这部分是我们需要的内容,对应的源码为: 分析源码,可以得知: 1.岗位信息列表在<section class="widg
-
Python爬虫实例——scrapy框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏可以看到搜索结果页的url为: 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=', 尝试将?后的参数删除, 发现访问结果相同. 打开Chrome网页调试工具(F12), 分析每条搜索结果
-
Python爬取12306车次信息代码详解
详情查看下面的代码: 如果被识别就要添加一个cookie如果没有被识别的话就要一个user-agent就好了.如果出现乱码就设置编码格式为utf-8 #静态的数据一般在elements中(复制文字到sources按ctrl+f搜索.找到的为静态),而动态去network中去寻找相关的信息 import requests import re def send_request(): headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win6
-
Python利用Xpath选择器爬取京东网商品信息
HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树:XPath 使用路径表达式在 XML 文档中选取节点.节点是通过沿着路径或者 step 来选取的. 首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求.在这里小编仍以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参
-
python爬取本站电子书信息并入库的实现代码
入门级爬虫:只抓取书籍名称,信息及下载地址并存储到数据库 数据库工具类:DBUtil.py import pymysql class DBUtils(object): def connDB(self): #连接数据库 conn=pymysql.connect(host='192.168.251.114',port=3306, user='root',passwd='b6f3g2',db='yangsj',charset='utf8'); cur=conn.cursor(); return (co
-
Python爬取爱奇艺电影信息代码实例
这篇文章主要介绍了Python爬取爱奇艺电影信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一,使用库 1.requests 2.re 3.json 二,抓取html文件 def get_page(url): response = requests.get(url) if response.status_code == 200: return response.text return None 三,解析html文件 我们需要的电影信
-
用Python爬取LOL所有的英雄信息以及英雄皮肤的示例代码
实现思路:分为两部分,第一部分,获取网页上数据并使用xlwt生成excel(当然你也可以选择保存到数据库),第二部分获取网页数据使用IO流将图片保存到本地 一.爬取所有英雄属性并生成excel 1.代码 import json import requests import xlwt # 设置头部信息,防止被检测出是爬虫 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (
-
Python爬取网页信息的示例
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初始网址,逐层查找链接,直到找到需要获取的内容. 在打开的界面中,点击鼠标右键,在弹出的对话框中,选择"检查",则在界面会显示该网页的源代码,在具体内容处点击查找,可以定位到需要查找的内容的源码. 注意:代码显示的方式与浏览器有关,有些浏览器不支持显示源代码功能(360浏览器,谷歌浏览器,火
-
基于Python爬取51cto博客页面信息过程解析
介绍 提到爬虫,互联网的朋友应该都不陌生,现在使用Python爬取网站数据是非常常见的手段,好多朋友都是爬取豆瓣信息为案例,我不想重复,就使用了爬取51cto博客网站信息为案例,这里以我的博客页面为教程,编写的Python代码! 实验环境 1.安装Python 3.7 2.安装requests, bs4模块 实验步骤 1.安装Python3.7环境 2.安装requests,bs4 模块 打开cmd,输入:pip install requests -i https://pypi.tuna.tsi