python爬取王者荣耀全皮肤的简单实现代码
相信现在很多人都喜欢玩王者荣耀这款手游,里面好看的皮肤令人爱不释手。那么你有没有想过把王者荣耀高清皮肤设置为壁纸,像下面这样

今天就来教大家如何利用python16行代码,实现王者荣耀全部高清皮肤的下载。
具体的操作分为两步:
1. 找到皮肤图片的地址
2. 下载图片
1. 寻找皮肤图片的地址 1. 找到英雄列表
百度"王者荣耀"进入官网 https://pvp.qq.com/。这里以Goole Chrome浏览器为例,在更多工具中选择开发者工具,或直接按F12进入调试界面,然后按F5刷新界面

图中标识的herolist.json文件就是我们所需要的英雄列表,其中包括英雄编号、英雄名称、英雄类型、皮肤的名称等信息,在文件上右击复制链接,http://pvp.qq.com/web201605/js/herolist.json

接下来验证一下我们寻找的是否正确,代码1:
import urllib.request
import json
import os
response = urllib.request.urlopen("http://pvp.qq.com/web201605/js/herolist.json")
hero_json = json.loads(response.read())
hero_num = len(hero_json)
print(hero_json)
print("hero_num : " , str(hero_num))
以上代码读取英雄列表并存入hero_json,并获取英雄数量,运行效果如下图

2. 找到英雄皮肤地址
点击首页的“游戏资料”标签页,进入新的页面后随意点击一个英雄头像进入英雄资料页面,以李白为例。同样的F12然后F5,将鼠标在李白的几个皮肤上一次扫过,
来看调试窗口
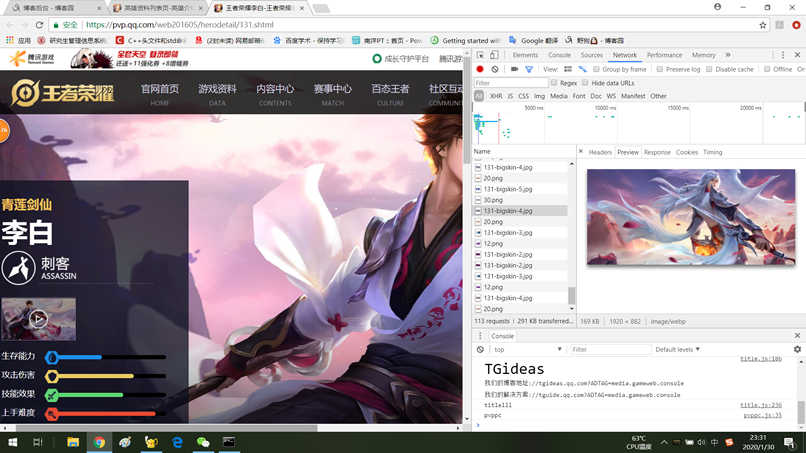
可以看到李白的高清皮肤一共有5个,同样我们在一个皮肤上右键复制链接得到:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/131/131-bigskin-5.jpg
这就是我们想要得到的英雄皮肤链接。
分析这个链接我们可以发现,其中‘131'是英雄的编号,最后的'-5'是该英雄的皮肤编号。到这里,浏览器上所需要的信息我们已经全部获得。
2. 下载图片 1. 英雄有几个皮肤
在第一步获取到的herolist.json文件中有'skin_name'字段,我们只要解析这个字段就可以获取皮肤数量与名称。测试代码接代码1,代码2如下:
hero_name = hero_json[0]['cname']
skin_names = hero_json[0]['skin_name'].split('|')
skin_num = len(skin_names)
print('hero_name: ', hero_name)
print('skin_names :', skin_names)
print('skin_num: ' + str(skin_num))
测试后的运行结果如下:

可以看到廉颇一共两个皮肤,皮肤名称分别为:正义爆轰和地狱岩魂。
2. 下载文件
下载文件用到urlretrieve接口,并且考虑两个问题:
1. 检查文件夹是否存在,不存在则创建;
save_dir = 'D:\heroskin\\' if not os.path.exists(save_dir): os.mkdir(save_dir)
2. 检查图片文件是否存在,如果存在则跳过下载。
if not os.path.exists(save_file_name): urllib.request.urlretrieve(skin_url, save_file_name)
代码三如下:
save_dir = 'D:\heroskin\\'
if not os.path.exists(save_dir):
os.mkdir(save_dir)
for i in range(hero_num):
# 获取英雄皮肤列表
skin_names = hero_json[i]['skin_name'].split('|')
for cnt in range(len(skin_names)):
save_file_name = save_dir + str(hero_json[i]['ename']) + '-' +hero_json[i]['cname']+ '-' +skin_names[cnt] + '.jpg'
skin_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(hero_json[i]['ename'])+ '/' +str(hero_json[i]['ename'])+'-bigskin-' + str(cnt+1) +'.jpg'
print(skin_url)
if not os.path.exists(save_file_name):
urllib.request.urlretrieve(skin_url, save_file_name)
总结
最后完整代码如下,除去注释和空行一共16行代码,实现了下载王者荣耀全部高清皮肤的功能:
import urllib.request
import json
import os
response = urllib.request.urlopen("http://pvp.qq.com/web201605/js/herolist.json")
hero_json = json.loads(response.read())
hero_num = len(hero_json)
save_dir = 'D:\heroskin\\'
if not os.path.exists(save_dir):
os.mkdir(save_dir)
for i in range(hero_num):
# 获取英雄皮肤列表
skin_names = hero_json[i]['skin_name'].split('|')
for cnt in range(len(skin_names)):
save_file_name = save_dir + str(hero_json[i]['ename']) + '-' +hero_json[i]['cname']+ '-' +skin_names[cnt] + '.jpg'
skin_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'+str(hero_json[i]['ename'])+ '/' +str(hero_json[i]['ename'])+'-bigskin-' + str(cnt+1) +'.jpg'
print(skin_url)
if not os.path.exists(save_file_name):
urllib.request.urlretrieve(skin_url, save_file_name)
实现后的效果如图所示:

哈哈,看来掌握一门语言是多么的重要。
以上知识点不难,大家如果有任何补充可以联系我们小编。
相关推荐
-
Python 实现王者荣耀中的敏感词过滤示例
王者荣耀的火爆就不用说了,但是一局中总会有那么几个挂机的,总能看到有些人在骂人,我们发现,当你输入一些常见的辱骂性词汇时,系统会自动将该词变成"*",作为python初学者,就想用python来实现这一功能. 步骤很简单所以就用交互式演示 首先我们要知道王者荣耀有哪些敏感词汇,然后放到一个元组, 第二步用户接收输入的消息 第三步处理敏感词汇 最后输出处理后的消息. >>> words=('金币', '挂', '傻逼', '猪', '你妈') #创建一个敏感词汇库 &g
-

用python的requests第三方模块抓取王者荣耀所有英雄的皮肤实例
本文使用python的第三方模块requests爬取王者荣耀所有英雄的图片,并将图片按每个英雄为一个目录存入文件夹中,方便用作桌面壁纸 下面时具体的代码,已通过python3.6测试,可以成功运行: 对于所要爬取的网页连接可以通过王者荣耀官网找到, # -*- coding: utf-8 -*- """ Created on Wed Dec 13 13:49:52 2017 @author:KillerTwo """ import request
-
用Python写王者荣耀刷金币脚本
王者荣耀很多朋友都想买脚本和挂之类的,想更加容易的获得金币等可以在游戏里买英雄等,今天我们发挥程序员的优势教给大家用Python语言自己写一个可以刷金币的脚本,以下是全部内容. 王者荣耀的冒险模式里有个挑战模式,第一次过关可以获得比较多的金币,后面重新挑战还是会获得少量金币,这不算是bug,只有你不嫌烦手动蛮力也可以刷金币. 推荐关卡:陨落的废都 - 魔女回忆 此关卡使用纯输出英雄20秒左右可以打BOSS,50秒左右可以通关,每次重复通关可以获得奖励19金币.在开挂前建议你手动通关体验一下.此为
-
python爬取王者荣耀全皮肤的简单实现代码
相信现在很多人都喜欢玩王者荣耀这款手游,里面好看的皮肤令人爱不释手.那么你有没有想过把王者荣耀高清皮肤设置为壁纸,像下面这样 今天就来教大家如何利用python16行代码,实现王者荣耀全部高清皮肤的下载. 具体的操作分为两步: 1. 找到皮肤图片的地址 2. 下载图片 1. 寻找皮肤图片的地址 1. 找到英雄列表 百度"王者荣耀"进入官网 https://pvp.qq.com/.这里以Goole Chrome浏览器为例,在更多工具中选择开发者工具,或直接按F12进入调试界面,然后按F5
-
教你如何用python爬取王者荣耀月收入流水线
前言 王者荣耀是最近几年包括现在一直都是最热销的手游,收益主要来源是游戏里面人物皮肤.今天就来爬取展示王者荣耀近一年收入流水线动图,看看王者荣耀有多赚钱(哈哈哈哈) 主要可视化内容: 一.App收入排行流水线 1.1.获取数据 数据来源于:七麦数据,里面数据都是通过异步加载,因此只需要找到异步链接,修改参数就可以直接获取到数据. 备注:需要cookie才可以获取数据. 请求链接 https://api.qimai.cn/pred/appMonthPred?analysis=eEcbRhNVVB9
-
Python通过requests模块实现抓取王者荣耀全套皮肤
目录 开发工具 环境搭建 思路分析 代码实现 前言 今天带大家爬取王者荣耀全套皮肤,废话不多说,直接开始~ 开发工具 Python版本: 3.6.4 相关模块: requests模块: urllib模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 思路分析 1.打开官方王者荣耀壁纸网站 网站地址:https://pvp.qq.com/web201605/wallpaper.shtml 2.快捷键F12,调出控制台进行抓包 3.找
-
用Python爬取英雄联盟的皮肤详细示例
目录 一.推理原理 二.推理代码 第一步:获取js字典 第二步:从 js字典中提取到key值生成url列表 第三步:从 js字典中提取到value值生成name列表 第四步:下载并保存数据 第五步:执行主程序 一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: lol.qq.com 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中. 这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.j
-
python爬取网易云音乐热歌榜实例代码
首先找到要下载的歌曲排行榜的链接,这里用的是: https://music.163.com/discover/toplist?id=3778678 然后更改你要保存的目录,目录要先建立好文件夹,例如我的是保存在D盘-360下载-网易云热歌榜文件夹内,就可以完成下载. 如果文件夹没有提前建好,会报错[Errno 2] No such file or directory. 代码实现: from urllib import request from bs4 import BeautifulSoup i
-
利用Python爬取微博数据生成词云图片实例代码
前言 在很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,一年一度的虐汪节,是继续蹲在角落默默吃狗粮还是主动出击告别单身汪加入散狗粮的行列就看你啦,七夕送什么才有心意,程序猿可以试试用一种特别的方式来表达你对女神的心意.有一个创意是把她过往发的微博整理后用词云展示出来.本文教你怎么用Python快速创建出有心意词云,即使是Python小白也能分分钟做出来.下面话不多说了,来一起看看详细的介绍吧. 准备工作
-
python爬取本站电子书信息并入库的实现代码
入门级爬虫:只抓取书籍名称,信息及下载地址并存储到数据库 数据库工具类:DBUtil.py import pymysql class DBUtils(object): def connDB(self): #连接数据库 conn=pymysql.connect(host='192.168.251.114',port=3306, user='root',passwd='b6f3g2',db='yangsj',charset='utf8'); cur=conn.cursor(); return (co
-
简单实现Python爬取网络图片
本文实例为大家分享了Python爬取网络图片的具体代码,供大家参考,具体内容如下 代码: import urllib import urllib.request import re #打开网页,下载器 def open_html ( url): require=urllib.request.Request(url) reponse=urllib.request.urlopen(require) html=reponse.read() return html #下载图片 def load_imag
-
使用Python爬取最好大学网大学排名
本文实例为大家分享了Python爬取最好大学网大学排名的具体代码,供大家参考,具体内容如下 源代码: #-*-coding:utf-8-*- ''''' Created on 2017年3月17日 @author: lavi ''' import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url) r.raise_for_status r.encodi