使用Cython中prange函数实现for循环的并行
目录
- 楔子
- 使用 prange
- prange 的其它参数
- 在reductions操作上使用prange
- 并行编程的局限性
- 小结
楔子
上一篇文章我们探讨了 GIL 的原理,以及如何释放 GIL 实现并行,做法是将函数声明为 nogil,然后使用 with nogil 上下文管理器即可。在使用上非常简单,但如果我们想让循环也能够并行执行,那么该方式就不太方便了,为此 Cython 提供了一个 prange 函数,专门用于循环的并行执行。
这个 prange 的特殊功能是 Cython 独一无二的,并且 prange 只能与 for 循环搭配使用,不能独立存在。
Cython 使用 OpenMP API 实现 prange,用于多平台共享内存的处理。但 OpenMP 需要 C 或者 C++ 编译器支持,并且编译时需要指定特定的编译参数来启动。例如:当我们使用 gcc 时,必须在编译和链接二进制文件的时候指定一个 -fopenmp,以确保启用 OpenMP。
许多编译器均支持 OpenMP ,包括免费的和商业的。但 Clang/LLVM 则是一个最显著的例外,它只在一个单独的分支中得到了初步的支持,而为它完全实现的 OpenMP 还在开发当中。
而使用 prange,需要从 cython.parallel 中进行导入。但是在这之前,我们先来看一个例子:
import numpy as np from cython cimport boundscheck, wraparound cdef inline double norm2(double complex z) nogil: """ 接收一个复数 z, 计算它的模的平方 由于 norm2 要被下面的 escape 函数多次调用 这里通过 inline 声明成内联函数 :param z: :return: """ return z.real * z.real + z.imag * z.imag cdef int escape(double complex z, double complex c, double z_max, int n_max) nogil: """ 这个函数具体做什么, 不是我们的重点 我们不需要关心 """ cdef: int i = 0 double z_max2 = z_max * z_max while norm2(z) < z_max2 and i < n_max: z = z * z + c i += 1 return i @boundscheck(False) @wraparound(False) def calc_julia(int resolution, double complex c, double bound=1.5, double z_max=4.0, int n_max=1000): """ 我们将要在 Python 中调用的函数 """ cdef: double step = 2.0 * bound / resolution int i, j double complex z double real, imag int[:, :: 1] counts counts = np.zeros((resolution + 1, resolution + 1), dtype="int32") for i in range(resolution + 1): real = -bound + i * step for j in range(resolution + 1): imag = -bound + j * step z = real + imag * 1j counts[i, j] = escape(z, c, z_max, n_max) return np.array(counts, copy=False)
我们手动编译一下,然后调用 calc_julia 函数,这个函数做什么不需要关心,我们只需要将注意力放在那两层 for 循环(准确的说是外层循环)上即可,这里我们采用手动编译的形式。
import cython_test import numpy as np import matplotlib.pyplot as plt arr = cython_test.calc_julia(1000, 0.322 + 0.05j) plt.imshow(np.log(arr)) plt.show()
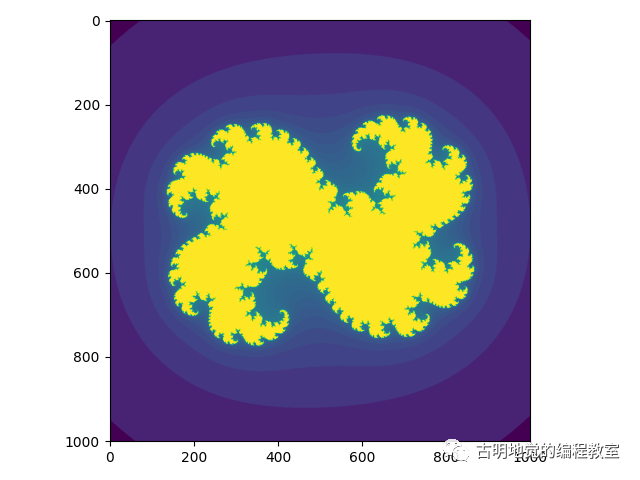
那么 calc_julia 这个函数耗时多少呢?我们来测试一下:

使用 prange
对于上面的代码来说,外层循环里面的逻辑是彼此独立的,即当前循环不依赖上一层循环的结果,因此这非常适合并行执行。所以 prange 便闪亮登场了,我们只需要做简单的修改即可:
import numpy as np
from cython cimport boundscheck, wraparound
from cython.parallel cimport prange
cdef inline double norm2(double complex z) nogil:
return z.real * z.real + z.imag * z.imag
cdef int escape(double complex z,
double complex c,
double z_max,
int n_max) nogil:
cdef:
int i = 0
double z_max2 = z_max * z_max
while norm2(z) < z_max2 and i < n_max:
z = z * z + c
i += 1
return i
@boundscheck(False)
@wraparound(False)
def calc_julia(int resolution,
double complex c,
double bound=1.5,
double z_max=4.0,
int n_max=1000):
cdef:
double step = 2.0 * bound / resolution
int i, j
double complex z
double real, imag
int[:, :: 1] counts
counts = np.zeros((resolution + 1, resolution + 1), dtype="int32")
# 只需要将外层的 range 换成 prange
for i in prange(resolution + 1, nogil=True):
real = -bound + i * step
for j in range(resolution + 1):
imag = -bound + j * step
z = real + imag * 1j
counts[i, j] = escape(z, c, z_max, n_max)
return np.array(counts, copy=False)
我们只需要将外层循环的 range 换成 prange 即可,里面指定 nogil=True,便可实现并行的效果,至于这个函数的其它参数以及用法后面会说。而且一旦使用了 prange,那么在编译的时候,必须启用 OpenMP,下面看一下编译脚本。
from distutils.core import setup, Extension
from Cython.Build import cythonize
ext = [Extension("cython_test",
sources=["cython_test.pyx"],
extra_compile_args=["-fopenmp"],
extra_link_args=["-fopenmp"])]
setup(ext_modules=cythonize(ext, language_level=3))
编译测试一下:

我们看到效率大概是提升了两倍,因为我 Windows 上使用的不是 gcc,所以这里是在 CentOS 上演示的。而我的 CentOS 服务器只有两个核,因此效率提升大概两倍左右。
所以只是做了一些非常简单的修改,便可带来如此巨大的性能提升,简直妙啊。prange 是要搭配 for 循环来使用的,如果 for 循环内部的逻辑彼此独立,即第二层循环不依赖第一层循环的某些结果,那么不妨使用 prange 吧。
注意还没完,我们还能做得更好,下面就来看看 prange 里面的其它的参数,这样我们能更好利用 prange 的并行特性。
prange 的其它参数
prange 函数的原型如下:
# 第一个参数 self 我们不需要管 # prange 实际上是类 CythonDotParallel 的成员函数 # 因为 Cython 内部执行了下面这行逻辑 # sys.modules['cython.parallel'] = CythonDotParallel() # 所以它将一个实例对象变成了一个模块 def prange(self, start=0, stop=None, step=1, nogil=False, schedule=None, chunksize=None, num_threads=None):
我们先来看前三个参数,start、stop、step。
- prange(3): 相当于 start=0、stop=3;
- prange(1, 3): 相当于 start=1、stop=3;
- prange(1, 3, 2): 相当于 start=1、stop=3、step=2;
类似于 range,同样不包含结尾 stop。
然后是第四个参数 nogil,它默认是 False,但事实上我们必须将其设置为 True,否则会报出编译错误。
然后剩下的三个参数,如果我们不指定的话,那么 Cython 编译器采取的策略是将整个循环分成多个大小相同的连续块,然后给每一个可用线程一个块。然而这个策略实际上并不是最好的,因为每一层循环用的时间不一定一样,如果一个线程很快就完成了,那么不就造成资源上的浪费了吗?
我们修改一下,将 schedule 指定为 "static",chunksize 指定为 1:
for i in prange(resolution + 1, nogil=True, schedule="static", chunksize=1):
其它地方不变,只是加两个参数,然后重新测试一下。
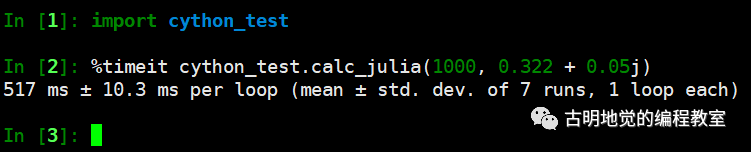
我们看到效率上是差不多的,原因是我的机器只有两个核,如果核数再多一些的话,那么速度就会明显地提升。
下面来解释一下剩余的三个参数的含义,首先是 schedule,它有以下几个选项:
"static"
整个循环在编译时会以一种固定的方式分配给多个线程,如果 chunksize 没有指定,那么会分成 num_threads 个连续块,一个线程一个块。如果指定了 chunksize,那么每一块会以轮询调度算法(Round Robin)交给线程进行处理,适用于任务均匀分布的情况。
"dynamic"
线程在运行时动态地向调度器申请下一个块,chunksize 默认为 1,当任务负载不均时,动态调度是最佳的选择。
"guided"
块是动态分布的,就像 dynamic 一样,但这与 dynamic 还不同,chunksize 的比例不是固定的,而是和 剩余迭代次数 / 线程数 成比例关系。
"runtime"
不常用。
控制 schedule 和 chunksize 可以方便地探索不同的并行执行策略、以及工作负载分配,通常指定 schedule 为 "static",加上设置一个合适的 chunksize 是最好的选择。而 dynamic 和 guided 适用于动态变化的执行上下文,但会导致运行时开销。
当然还有最后一个参数 num_threads,很明显不需要解释,就是使用的线程数量。如果不指定,那么 prange 会使用尽可能多的线程。所以我们只是做了一点修改,便可以带来巨大的性能提升,这种性能提升与 Cython 在纯 Python 上带来的性能提升成倍增关系。
在reductions操作上使用prange
我们经常会循环遍历数组计算它们的累和、累积等等,这种数据量减少的操作我们称之为 reduction 操作。而 prange 对这样的操作也是支持并行执行的,我们举个例子:
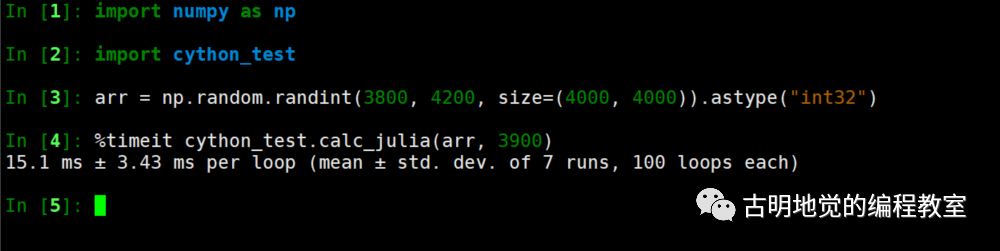
from cython cimport boundscheck, wraparound @boundscheck(False) @wraparound(False) def calc_julia(int [:, :: 1] counts, int val): cdef: int total = 0 int i, j, M, N N, M = counts.shape[: 2] for i in range(M): for j in range(N): if counts[i, j] == val: total += 1 return total / float(counts.size)
显然我们是希望计算一个数组中值 val 的元素的个数,下面测试一下:
如果改成 prange 的话,会有什么效果呢?代码的其它部分不变,只需要导入 prange,然后将 range(M) 改成 prange(M, nogil=True) 即可。
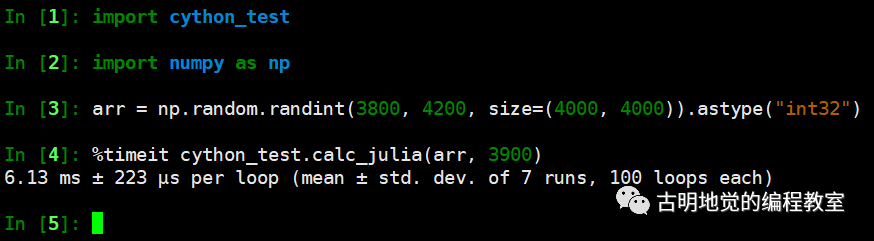
速度比原来快了两倍多,还是很可观的,如果你的 CPU 是多核的,那么效率提升会更明显。
这里我们没有使用 schedule 和 chunksize 参数,你也可以加上去。当然啦,如果占用内存过大的话,它可能无法像预期的一样显著地提升性能,因为 prange 的优化重点是在 CPU 上面。
但是可能有人会有疑问,多个线程同时对 total 变量进行自增操作,这么做不会造成冲突吗?答案是不会的,因为加法是可交换的,即无论是 a + b 还是 b + a,结果都是相同的。Cython(通过 OpenMP)生成线程代码,每个线程计算循环子集的和,然后所有线程再将各自的和汇总在一起。
如果是交给 Numpy 来做的话,那么等价于如下:
np.sum(counts == val) / float(counts.size)
但是效率如何呢?我们来对比一下:
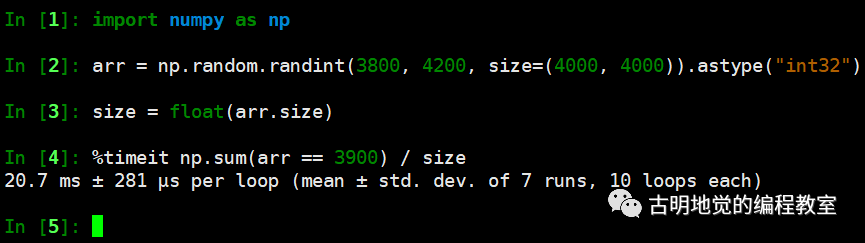
我们采用并行计算用的是 6.13 毫秒,Numpy 用的是 20 毫秒,看样子是我们赢了,并且 CPU 核心数越多,差距越明显,这便是并行计算的威力。当然对于这种算法来说,还是直接交给 Numpy 吧,毕竟人家都帮你封装好了,一个函数调用就可以解决了。
因此有效利用计算机硬件资源确实是最直接的办法。
并行编程的局限性
虽然 Cython 的 prange 容易使用,但其实还是有局限性的,当然这个局限性和 Cython无关,因为理想化的并行扩展本身就是一个难以实现的事情。我们举个例子:
def filter(nrows, ncols): for i in range(nrows): for j in range(ncols): b[i, j] = (a[i, j] + a[i - 1, j] + a[i + 1, j] + a[i, j - 1] + a[i, j + 1]) / 5.0)
假设我们要做一个过滤器,计算每一个点加上它周围的四个点的平均值。但如果这里将外层的 range 换成 prange,那么它的整体性能不会明显提升。因为内层循环访问的是不连续的数组元素,由于缺乏数据本地性,CPU 的缓存无法生效,反而导致 prange 变慢。
那么我们什么时候使用 prange 呢?遵循以下法则即可:
- 1. prange 能够很好的利用 CPU 并行操作, 这一点我们已经说过了;
- 2. 非本地读写的那些和内存绑定的操作很难提高速度;
- 3. 用较少的线程更容易实现加速, 因为对于 CPU 密集而言, 即便指定了超越核心数的线程也是没有意义的;
- 4. 使用优化的线程并行库是将 CPU 所有核心都用于常规计算的最佳方式;
当然,其实我们在开发的时候是可以随时使用 prange 的,只要循环体不和 Python 对象进行交互即可。
小结
Cython 允许我们绕过全局解释器锁,只要我们把和 Python 无关的代码分离出来即可。对于那些不需要和 Python 交互的 C 代码,可以轻松地使用 prange 实现基于线程的并行。
在其它语言中,基于线程的并行很容易出错,并且难以正确处理。而 Cython 的 prange 则不需要我们在这方面费心,能够轻松地处理很多性能瓶颈。
到此这篇关于使用Cython中prange函数实现for循环的并行的文章就介绍到这了,更多相关Cython prange for循环并行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python通过cython加密代码
#coding=utf-8 import getopt import os, sys import zipfile from Crypto.Cipher import AES import random, struct #加密python3的代码 def transfer3(dir_pref): os.system('cython -2 %s.py;' 'gcc -c -fPIC -I/usr/include/python3.5/ %s.c -o %s.o'
-

能让Python提速超40倍的神器Cython详解
让Python提速超过40倍的神器:Cython 人工智能最火的语言,自然是被誉为迄今为止最容易使用的代码之一的Python.Python代码素来以直观.高可读性著称. 然而,易用的背后,是Python无法逾越的障碍:慢.尤其是C程序员,这群快枪手简直无法忍受Python的慢. 所以有人就想了各种方法去解决这个问题,本文就介绍其中的一种.如果你的代码是纯Python,或者你必须用一个大的for循环却无法放入矩阵因为数据必须按顺序处理,那么就可以使用Cython来加速Python. 1.什么是Cy
-
用Cython加速Python到“起飞”(推荐)
事先声明,标题没有把"Python"错打成"Cython",因为要讲的就是名为"Cython"的东西. Cython是让Python脚本支持C语言扩展的编译器,Cython能够将Python+C混合编码的.pyx脚本转换为C代码,主要用于优化Python脚本性能或Python调用C函数库.由于Python固有的性能差的问题,用C扩展Python成为提高Python性能常用方法,Cython算是较为常见的一种扩展方式. 我们可以对比一下业界主流的几
-
Cython 三分钟入门教程
作者:perrygeo译者:赖勇浩(http://laiyonghao.com)原文:http://www.perrygeo.net/wordpress/?p=116 我最喜欢的是Python,它的代码优雅而实用,可惜纯粹从速度上来看它比大多数语言都要慢.大多数人也认为的速度和易于使用是两极对立的--编写C代码的确非常痛苦.而 Cython 试图消除这种两重性,并让你同时拥有 Python 的语法和 C 数据类型和函数--它们两个都是世界上最好的.请记住,我绝不是我在这方面的专家,这是我的第一次
-
详解如何利用Cython为Python代码加速
引言 通常,在 Python 中写循环(特别是多重循环)非常的慢,在文章 //www.jb51.net/article/133807.htm中,我们的元胞自动机的状态更新函数 update_state 使用了两重循环,所以我们尝试用 Cython 重构该方法. 代码 我们在同文件夹下新建一个 update.pyx 文件,写入如下内容 import numpy as np cimport numpy as np cimport cython DTYPE = np.float ctypedef np
-
Cython编译python为so 代码加密示例
1. 编译出来的so比网上流传的其他方法小很多. 2. language_level 是python的主版本号,如果python版本是2.x,目前的版本Cython需要人工指定language_level. 3. python setup.py build_ext --inplace 执行脚本 4. 以下是代码片段 from distutils.core import Extension, setup from Cython.Build import cythonize from Cytho
-
利用Numba与Cython结合提升python运行效率详解
目录 Numba Numba 模式 什么是LLVM? Numba的优势: Numba的劣势: Cython Cython的优势: Cython的劣势: Numba 对 Cython Numba Numba是一个即时(JIT)编译器,它将Python代码转换为用于CPU和GPU的本地机器指令.代码可以在导入时.运行时或提前编译. 通过使用jit装饰器,使用Numba非常容易: 正如你所知道的,在Python中,所有代码块都被编译成字节码: 代码优化 为了优化Python代码,Numba从提供的函数
-
使用Cython中prange函数实现for循环的并行
目录 楔子 使用 prange prange 的其它参数 在reductions操作上使用prange 并行编程的局限性 小结 楔子 上一篇文章我们探讨了 GIL 的原理,以及如何释放 GIL 实现并行,做法是将函数声明为 nogil,然后使用 with nogil 上下文管理器即可.在使用上非常简单,但如果我们想让循环也能够并行执行,那么该方式就不太方便了,为此 Cython 提供了一个 prange 函数,专门用于循环的并行执行. 这个 prange 的特殊功能是 Cython 独一无二的,
-
详解WordPress中调用评论模板和循环输出评论的PHP函数
comments_template comments_template 函数是一个调用评论模板的函数,使用起来很简单,与get_header()等函数一样,是一个include文件类函数,今天来讲一下他的使用. 描述 上面已经讲过了,就是调用评论模板的一个函数. 使用 <?php comments_template( $file, $separate_comments ); ?> 其中 $file 需要调用的文件名 默认值: /comments.php $separate_comments 是
-
Swift中的条件判断、循环、跳转语句基础学习笔记
一.引言 一种编程语言的强大与否,很大程度上取决于其提供的程序流程控制方案,就如使用汇编语言实现复杂的程序流程是一件痛苦的事情.Swift中提供了许多强大的流程控制语句,例如快速遍历for-in,while循环,repeat-while循环,switch选择等,需要注意的是,在Swift2.2中,for(a;b;c)循环已经被弃用掉,并且Swift中的Switch语句也更加强大,可以处理任意数据类型. 二.for-in循环 配合范围运算符,for-in循环可以用来执行确定次数的循环,示例如下:
-
Python 3中print函数的使用方法总结
前言 Python 思想:"一切都是对象!",最近发现python3和python2中print的用法有很多不同,python3中需要使用括号,缩进要使用4个空格(这不是必须的,但你最好这么做),缩进表示一个代码块的开始,非缩进表示一个代码的结束.没有明确的大括号.中括号.或者关键字.这意味着空白很重要,而且必须要是一致的.第一个没有缩进的行标记了代码块,意思是指函数,if 语句. for 循环. while 循环等等的结束.所以就想着给大家总结一下Python3中print函数用法的
-
python中Genarator函数用法分析
本文实例讲述了python中Genarator函数用法.分享给大家供大家参考.具体如下: Generator函数的定义与普通函数的定义没有什么区别,只是在函数体内使用yield生成数据项即可.Generator函数可以被for循环遍历,而且可以通过next()方法获得yield生成的数据项. def func(n): for i in range(n): yield i for i in func(3): print i r=func(3) print r.next() print r.next
-
谈谈JavaScript中的函数与闭包
闭包这东西,说难也难,说不难也不难,下面我就以自己的理解来说一下闭包 一.闭包的解释说明 对于函数式语言来说,函数可以保存内部的数据状态.对于像C#这种编译型命令式语言来说,由于代码总是在代码段中执行,而代码段是只读的,因此函数中的数据只能是静态数据.函数内部的局部变量存放在栈上,在函数执行结束以后,所占用的栈被释放,因此局部变量是不能保存的. Javascript采用词法作用域,函数的执行依赖于变量作用域,这个作用域是在定义函数时确定的.因此Javascript中函数对象不仅保存代码逻辑,还必
-
Python中zip()函数用法实例教程
本文实例讲述了Python中zip()函数的定义及用法,相信对于Python初学者有一定的借鉴价值.详情如下: 一.定义: zip([iterable, ...]) zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些tuples组成的list(列表).若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同.利用*号操作符,可以将list unzip(解压). 二.用法示例: 读者看看下面的例子,
-
C++中strcpy函数的实现
我们先来看个例子 char * strcpy(char * strDest,const char * strSrc) { if ((NULL==strDest) || (NULL==strSrc)) throw "Invalid argument(s)"; char * strDestCopy = strDest; while ((*strDestCopy++ = *strSrc++) != '\0'); return strDest; } 突然想到之前做过的一个试题 题目:
-
JavaScript中的函数嵌套使用
在JavaScript1.2之前,函数定义是只允许在顶层全局代码,但1.2的JavaScript可以嵌套函数定义其他函数中也是可以的. 仍然存在的函数定义可以循环或条件之内不会出现限制.在函数定义这些限制只适用于函数声明与函数语句. 函数文本(在JavaScript1.2引入的另一个功能)可能出现在任何JavaScript表达式,这意味着它们可以出现在if else语句内. 示例: 下面就是我们两个嵌套函数的例子.这可能会有点混乱,但它的工作原理完全正常: <script type="te
-
php中simplexml_load_file函数用法实例
本文实例讲述了php中simplexml_load_file函数用法.分享给大家供大家参考.具体用法分析如下: 在php中simplexml_load_file() 函数把 XML 文档载入对象中之后我们就可以利用由此函数返回的对象进行相关的操作了,下面我们看几个测试实例. 例子,XML文件代码如下: 复制代码 代码如下: <?xml version="1.0" encoding="ISO-8859-1"?> <note> <to&g