详解Go语言运用广度优先搜索走迷宫
目录
- 一、理解广度优先算法
- 1.1、分析如何进行广度优先探索
- 1.2、我们来总结一下
- 1.3、代码分析
- 二、代码实现广度优先算法走迷宫
一、理解广度优先算法
我们要实现的是广度优先算法走迷宫
比如,我们有一个下面这样的迷宫
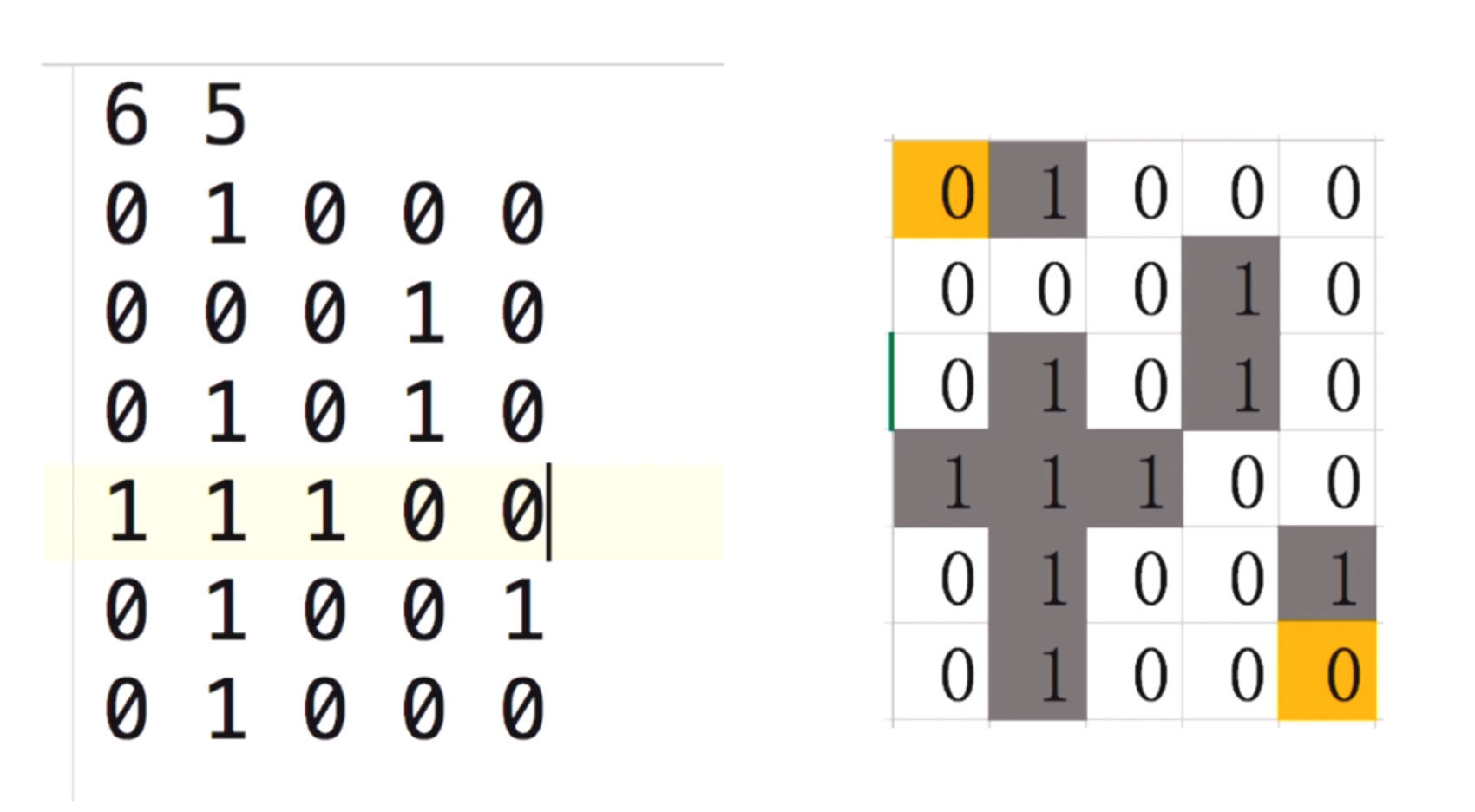
这个迷宫是6行5列
其中0代表可以走的路, 1代表一堵墙. 我们把墙标上言责, 就如右图所示. 其中(0,0)是起点, (6, 5)是终点.
我们要做的是, 从起点走到终点最近的路径.
这个例子是抛转隐喻, 介绍广度优先算法, 广度优先算法的应用很广泛, 所以, 先来看看规律
1.1、分析如何进行广度优先探索
第一步, 我们先明确起点. 这个起点有上下左右四个方向可以探索. 我们按照顺时针顺序探索, 上 左 下 右

第二步: 起始位置向外探索, 有4个方向.

如上图红色标出的位置. 也就是起始位置可以向外探索的路径有4个. 上 左 下 右
我们再来继续探索.
第三步: 再次明确探索方向是 上 左 下 右
第四步: 探索上方的红1, 上方的红1可以向外探索的路径有3个

第五步: 探索左侧红1, 左侧红1 有两条路径向外探索,
为什么是两个呢? 本来是有3个, 但上面的路径已经被上面的红1探索过了, 所以, 不重复探索的原则, 左侧红1 向外扩展的路径有2条

第六步: 下面的红1 向外探索的路径有2条

第七步: 右侧的红1向外探索的路径, 如上图可见, 只剩下1条了

第二轮探索, 得到的探索结果是:

经过第二轮探索, 一共探索出了8条路径, 也就是8个黑2
接下来进行第三轮探索. 顺序依然是顺时针方向,
1. 第一个2向外探索的路径有3条
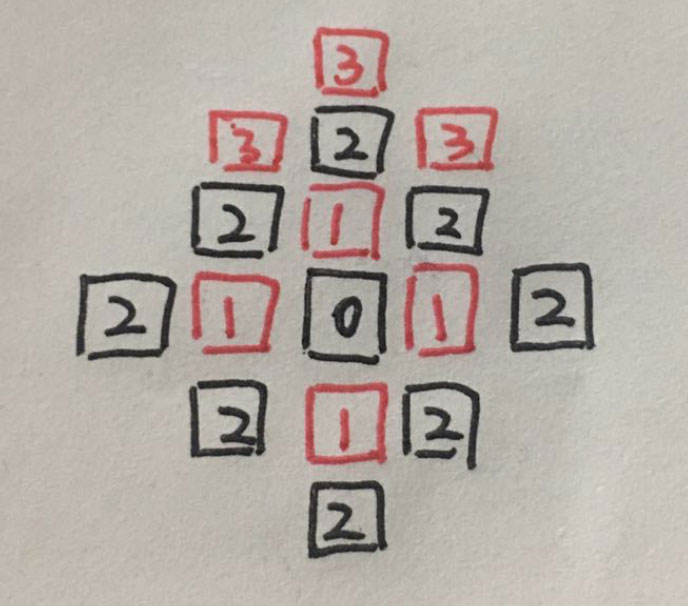
2. 第二个黑2向外探索的路径只有1条

3. 第三个黑2向外探索的路径有2条

4. 第四个黑2向外探索的路径有1条

5. 第五个黑2 向外探索的路径有两条

6. 第六个黑2向外探索的路径有1条

7. 第七个黑2向外探索的路径有两条

8. 第8个黑2向外探索的路径为0条. 已经没有路径. 所以不再向外探索
通过第三轮向外探索, 我们探索出来了12条路径.
这是有的节点可以向外探索3条路径,有的可以向外探索2条路径, 有的向外探索1条路径, 有的没有路径可以向外探索了.
总结:
通过上面的例子, 我们可以看到每个节点的3中状态. 我们来分析一下, 有哪三种状态.
刚开始, 只有一个其实位置0. 这个0是已知的, 还没有开始向外探索. 外面还有好多等待探索的节点.所以,此时的0, 是已经发现还未探索的节点
当0开始向外探索, 探索到4个1, 这时候0就变成了已经发现且已经探索的节点. 二1变成了一经发现还未探索的节点. 其实此时外面还有3, 4, 5 这些还未被发现未被探索的节点.
我们通过分析, 广度优先算法还有一个特点, 那就是循环遍历, 第一轮的红1都探索完了, 在进行黑2的探索, 不会说红1探索出来一个, 还没有全部完成,就继续向外探索.
总结规律如下:
1. 节点有三种状态
- a. 已经发现还未探索的节点
- b. 已经发现并且已经探索的节点
- c. 还未发现且未探索的节点
2. 阶段探索的顺序
按照每一轮全部探索完,在探索下一轮, 这样就形成了一个队列, 我们把已经发现还未探索的节点放到队列里
接下来我们开始探索了.
首先, 我们知道迷宫的起始位置, (0,0)点. 当前我们站在起始位置(0,0), 那么这个起点就是已经发现还未探索的节点.
我们定义一个队列来存放已经发现但还未探索的节点
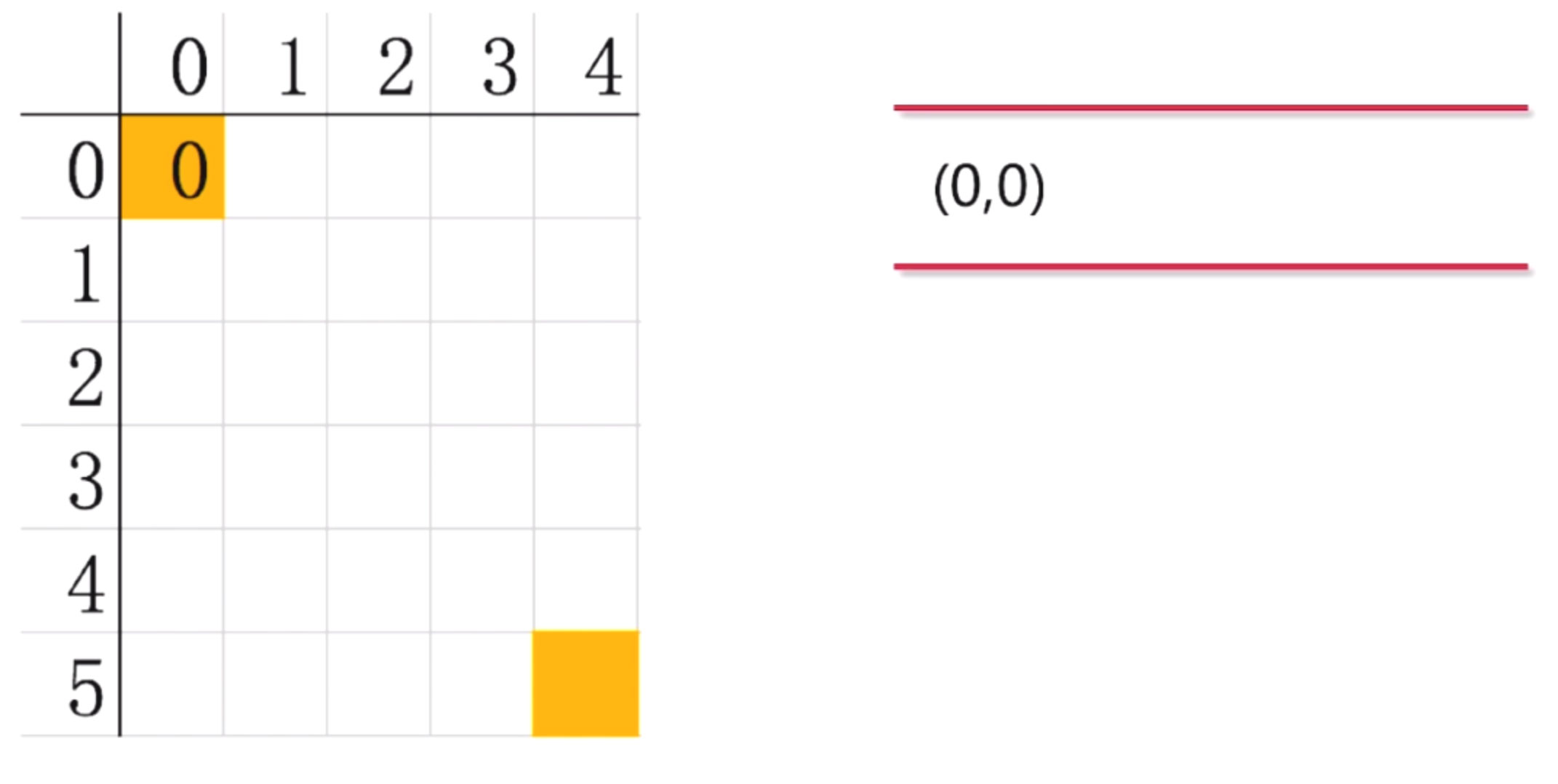
第二步: 从队列中取出节点(0,0), 开始下一步探索.我们看看迷宫最终的样子

我们看到(0,0)只能向下走, 他的右边是一堵墙, 走不了. 上面,左面也不能走. 所以, 探索出来的路径只有一个(1,0), 吧(1,0)放入到队列中
第三步: 我们在从队列中把(1,0)取出来进行探索, 这时队列就空了.
对照迷宫, (1,0)可以向下走, 可以向右走. 不能向上和向左. 因此, (1,0)探索出来两条路, (2,0) 和(1,1), 把这两个点放入到队列中

第四步: 接下来我们来探索(2,0)这个点, 对照迷宫, 我没发现(2,0)这个点下和右都是墙, 左不能走, 上就走回去了也不可以. 所以, (2,0)是个死路, 探索出来的路径是0
第五步: 继续探索(1,1), 对照迷宫, (1,1)只能向右探索到(1,2) , 因此我们把(1,2)放入队列中
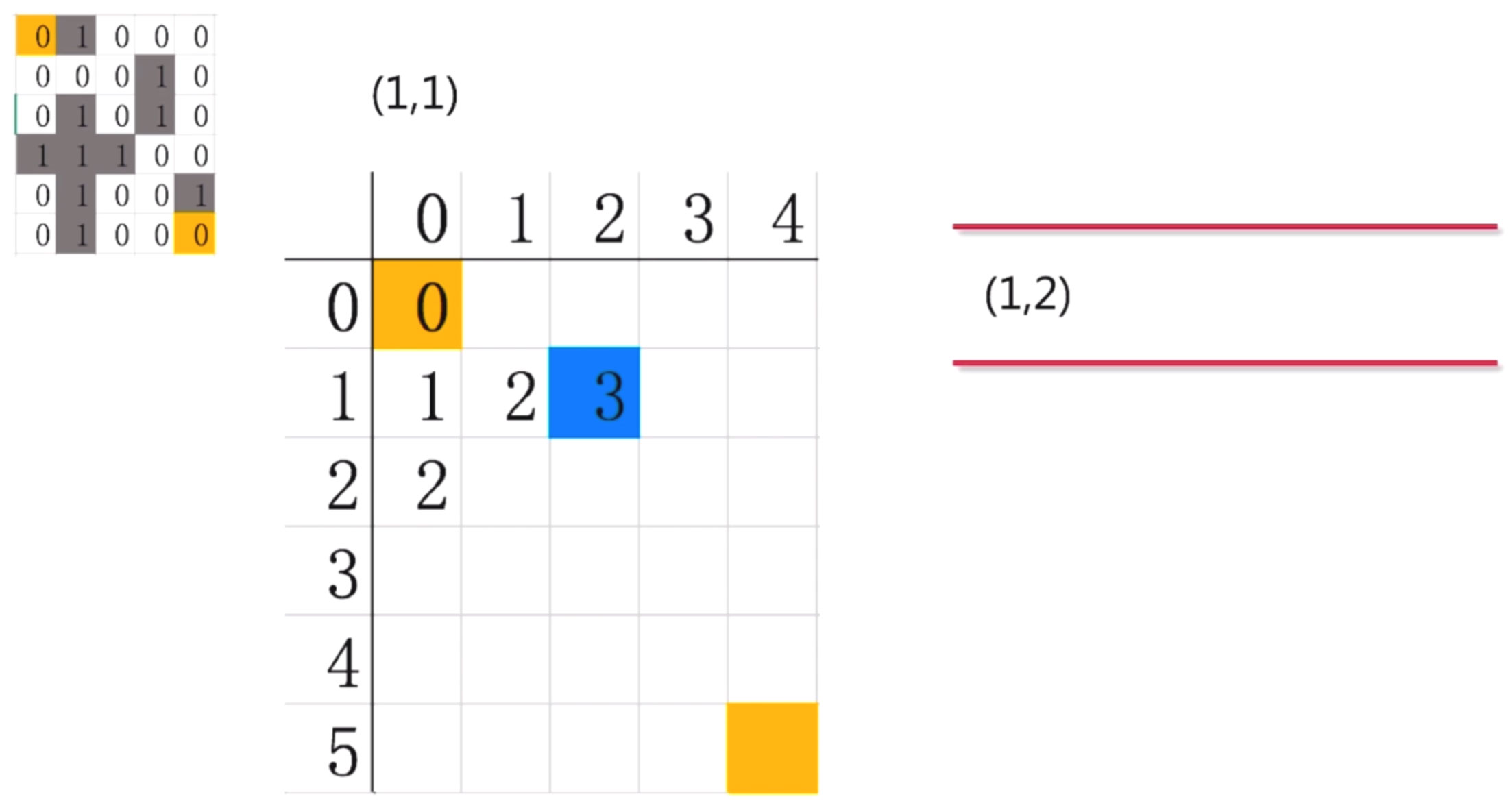
第六步:对(1,2)继续探索, 发现有两条路径可以走(2,2)和(0,2), 然后, 将这两个点放到队列中
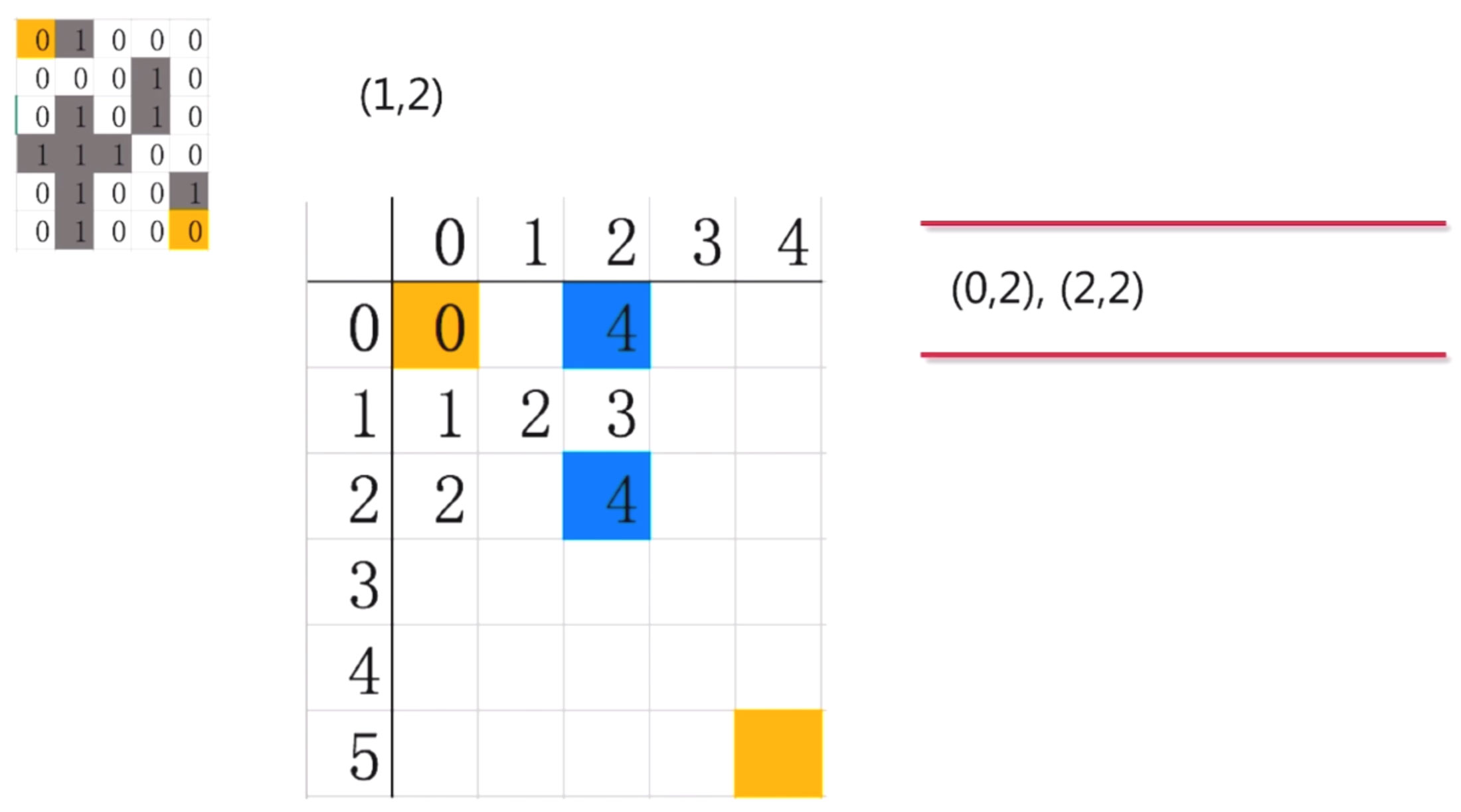
第七步: 接下来继续这样探索下去, 一直走一直走, 走到最后就是这样的
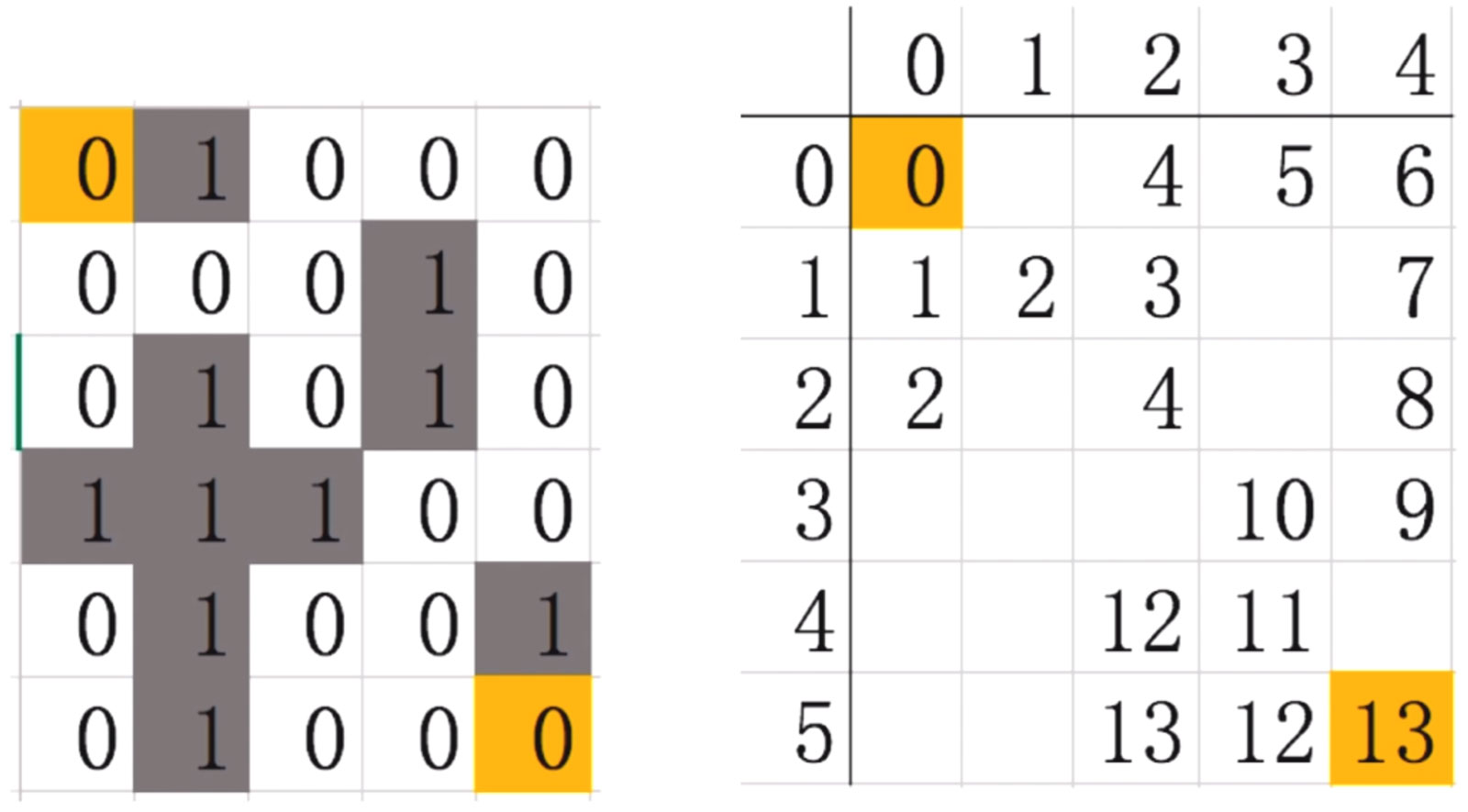
那我们要怎么来判断路径呢? 倒过来走, 从13开始, 上一个数12, 只有一个, 12上面只有一个数是11, 只有一个, 一次类推, 一直找到1, 找到0.
第八步: 广度优先算法, 什么时候结束呢? 两种情况
- 第一种: 走到最后13的位置
- 第二种: 死路, 走到一个位置, 不能再走了. 如何判断呢?队列中没有可探索的点了, 探索结束
1.2、我们来总结一下
1. 从(0,0)点开始, 将已经发现还未探索的点, 放入到队列中.
2. 从队列中取出已经发现还未探索的节点, 进行探索, 探索的方式是, 像四周探索, 然后把新发现还未探索的节点从队列中取出来.
3. 如何判断呢? 如果当前是一堵墙, 也就是他的value=0, 那么探索失败. 向左探索的时候, 如果左边是(0,*)探索失败. 向上探索的时候, 如果上面是(*,0)探索失败; 像右面探索的时候, 碰到边(*,4)探索失败. 向下探索, 碰到(5,*)探索失败. 也就是, 横向坐标的范围是 0<=x<=4, 纵坐标是 0<=y<=5
4. 已经探索过的节点不要重复探索
1.3、代码分析
1. 队列可以用一个数组来实现. 先进先出
2. 点用二维数据来表示. 但是go中的二维数组的含义是一位数组里的值又是一个数组.比如[][]int, 他是一个一维数组[]int, 里面的值又是一个一维数组.[]int.
那么用在这里就是, 纵坐标表示有6行, 那么他是一个[6]int, 横坐标表示每行里面又是一个数组, 每行有6个元素[5]int, 所以, 这就是一个[6][5]int 有6行5列的数组.
二、代码实现广度优先算法走迷宫
第一步: step代表从start开始, 走了多少步走到目标点, 最后的路径是通过这个创建出来的, 最后从后往前推就可以算出最短路径
第二步: 定义一个队列, 用来保存已经发现还未探索的点, 队列里的初始值是(0,0)点
第三步: 开始走迷宫, 走迷宫退出的条件有两个
1. 走到终点, 退出
2. 队列中没有元素, 退出
第四步: 判断坐标是否符合探索的要求
1. maze at next is 0
2. and setp at next is 0, 如果step的值不是0 ,说明曾经到过这个点了, 不能重复走
3. next != start 处理特殊点, (0,0)点
第五步: 已经找到这个点了, 计算当前的步数, 并加入队列中
package main
import (
"fmt"
"os"
)
func readFile(filename string) [][]int{
// 定义一个行和列,用来接收迷宫是几行几列的数组
var row, col int
file, e := os.Open(filename)
if e != nil {
panic("error")
}
defer file.Close()
fmt.Fscan(file, &row, &col)
// 定义一个数组
// 注意: 定义数组的时候, 我们只要传入几行就可以了.
// 二维数组的含义, 其实质是一个一维数组, 一维数组里每一个元素又是一个数组
maze := make([][]int, row)
for i := 0; i < len(maze); i++ {
maze[i] = make([]int, col)
for j := 0; j < len(maze[i]); j++ {
fmt.Fscan(file, &maze[i][j])
}
}
return maze
}
type point struct {
i, j int
}
// 当前节点, 向四个方向探索后的节点
// 这里使用的是返回新的节点的方式, 不修改原来的节点. 所以使用的是值拷贝,而不是传地址
func (p point) add(dir point) point{
return point{p.i + dir.i, p.j + dir.j }
}
// 获取某个点的坐标值
// 同时判断这个点有没有越界, 返回的是这个值是否有效
// return 第一个参数表示返回的值是否是1, 是1表示撞墙了
// 第二个参数表示返回的值是否不越界, 不越界返回true, 越界,返回false 就和你
func (p point) at(grid [][]int) (int, bool) {
if p.i < 0 || p.i >= len(grid) {
return 0, false
}
if p.j <0 || p.j >= len(grid[0]) {
return 0, false
}
return grid[p.i][p.j], true
}
// 定义要探索的方向, 上下左右四个方向
var dirs = []point {
point{-1, 0},
point{0, -1},
point{1, 0},
point{0, 1},
}
// 走迷宫
func walk(maze [][]int, start, end point) [][]int {
// 第一步: step代表从start开始, 走了多少步走到目标点, 最后的路径是通过这个创建出来的, 最后从后往前推就可以算出最短路径
// 2. 通step还可以知道哪些点是到过的, 哪些点是没到过的
step := make([][]int, len(maze))
for i := range step {
// 定义每一行有多少列, 这样就定义了一个和迷宫一样的二维数组
step[i] = make([]int, len(maze[i]))
}
// 第二步: 定义一个队列, 用来保存已经发现还未探索的点, 队列里的初始值是(0,0)点
Que := []point{start}
// 第三步: 开始走迷宫, 走迷宫退出的条件有两个
// 1. 走到终点, 退出
// 2. 队列中没有元素, 退出
for len(Que) > 0 {
// 开始探索, 依次取出队列中, 已经发现还未探索的元素
// cur 表示当前要探索的节点
cur := Que[0]
// 然后从头拿掉第一个元素
Que = Que[1:]
// 如果这个点是终点, 就不向下探索了
if cur == end {
break
}
// 当前节点怎么探索呢? 要往上下左右四个方向去探索
for _, dir := range dirs {
// 探索下一个节点, 这里获取下一个节点的坐标. 当前节点+方向
next := cur.add(dir)
// 判断坐标是否符合探索的要求
// 1. maze at next is 0
// 2. and setp at next is 0, 如果step的值不是0 ,说明曾经到过这个点了, 不能重复走
// 3. next != start 处理特殊点, (0,0)点
// 探索这个点是否是墙
val, ok := next.at(maze)
if !ok || val == 1 {
continue
}
// 探索这个点是否已经走过
val, ok = next.at(step)
if val != 0 || !ok {
continue
}
// 走到起始点了, 返回
if next == start {
continue
}
// 已经找到这个点了, 计算当前的步数
curval, _ := cur.at(step) // 当前这一步的步数
step[next.i][next.j] = curval + 1 // 下一步是当前步数+1
Que = append(Que, next) // 将下一步节点放入到队列中
}
}
return step
}
func main() {
maze := readFile("maze/maze.in")
steps := walk(maze, point{0, 0}, point{len(maze) - 1, len(maze[0]) - 1})
// len(maze)-1, len[maze[0]]-1 是终点
// 0,0是起始点
for _, row := range steps {
for _, val := range row {
fmt.Printf("%3d", val)
}
fmt.Println()
}
}
以上就是详解Go语言运用广度优先搜索走迷宫的详细内容,更多关于Go 广度优先搜索走迷宫的资料请关注我们其它相关文章!
相关推荐
-
Golang算法问题之数组按指定规则排序的方法分析
本文实例讲述了Golang算法问题之数组按指定规则排序的方法.分享给大家供大家参考,具体如下: 给出一个二维数组,请将这个二维数组按第i列(i从1开始)排序,如果第i列相同,则对相同的行按第i+1列的元素排序, 如果第i+1列的元素也相同,则继续比较第i+2列,以此类推,直到最后一列.如果第i列到最后一列都相同,则按原序排列. 样例输入: 1,2,3 2,3,4 2,3,1 1,3,1 按第2列排序,输出: 1,2,3 2,3,1 1,3,1 2,3,4 代码实现: 复制代码 代码如下: pac
-
Go语言算法之寻找数组第二大元素的方法
本文实例讲述了Go语言算法之寻找数组第二大元素的方法.分享给大家供大家参考.具体如下: 该算法的原理是,在遍历数组的时,始终记录当前最大的元素和第二大的元素.示例代码如下: 复制代码 代码如下: package demo01 import ( "fmt" ) func NumberTestBase() { fmt.Println("This is NumberTestBase") nums := []int{12, 2
-
Golang排列组合算法问题之全排列实现方法
本文实例讲述了Golang排列组合算法问题之全排列实现方法.分享给大家供大家参考,具体如下: [排列组合问题] 一共N辆火车(0<N<10),每辆火车以数字1-9编号,要求以字典序排序输出火车出站的序列号. 输入: 包括N个正整数(0<N<10),范围为1到9,数字之间用空格分割,字符串首位不包含空格. 输出: 输出以字典序排序的火车出站序列号,每个编号以空格隔开,每个输出序列换行. 样例输入: 1 2 3 样例输出: 1 2 3 1 3 2 2 1 3 2 3 1 3 1 2 3
-
Go语言实现的树形结构数据比较算法实例
本文实例讲述了Go语言实现的树形结构数据比较算法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: // Two binary trees may be of different shapes, // but have the same contents. For example: // // 4 6 // 2 6 4 7 // 1 3 5 7 2 5 //
-

详解Go语言运用广度优先搜索走迷宫
目录 一.理解广度优先算法 1.1.分析如何进行广度优先探索 1.2.我们来总结一下 1.3.代码分析 二.代码实现广度优先算法走迷宫 一.理解广度优先算法 我们要实现的是广度优先算法走迷宫 比如,我们有一个下面这样的迷宫 这个迷宫是6行5列 其中0代表可以走的路, 1代表一堵墙. 我们把墙标上言责, 就如右图所示. 其中(0,0)是起点, (6, 5)是终点. 我们要做的是, 从起点走到终点最近的路径. 这个例子是抛转隐喻, 介绍广度优先算法, 广度优先算法的应用很广泛, 所以, 先来看看规律
-
详解C语言中双指针算法的使用
目录 前言 一.最长不含重复字符的子字符串 1.题目要求 2.个人题解 二.和为S的两个数字 1.题目要求 2.个人题解 前言 双指针算法 算法思想 双指针,指的是在遍历对象的过程中,不是普通的使用单个指针进行访问,而是使用两个相同方向(快慢指针)或者相反方向(对撞指针)的指针进行扫描,从而达到相应的目的. 换言之,双指针法充分使用了数组有序这一特征,从而在某些情况下能够简化一些运算. 今天带大家来学习算法中双指针的应用场景. 一.最长不含重复字符的子字符串 1.题目要求 2.个人题解 2.1
-
详解C语言未初始化的局部变量是多少
C语言中,未初始化的局部变量到底是多少? 答案往往是: 与编译器有关. 可能但不保证初始化为0. 未确定. 总之,全部都是些一本正经的形而上答案,这很令人讨厌. 但凡一些人给你滔滔不绝地扯编译器,C库,处理器体系结构却给不出一个实际场景复现问题的时候,这人大概率在扯淡. 又是周五回家时,大巴车上作短文一篇. 其实,这个问题本身就是错误的问法,说全了能讲10万字,我们只要能在特定场景下确定其特定行为就OK了,当然,这就需要设计一个比较OK的实验. 在演示一个实际代码行为之前,先给出一个知识, CP
-
详解Go语言中关于包导入必学的 8 个知识点
1. 单行导入与多行导入 在 Go 语言中,一个包可包含多个 .go 文件(这些文件必须得在同一级文件夹中),只要这些 .go 文件的头部都使用 package 关键字声明了同一个包. 导入包主要可分为两种方式: 单行导入 import "fmt" import "sync" 多行导入 import( "fmt" "sync" ) 如你所见,Go 语言中 导入的包,必须得用双引号包含,在这里吐槽一下. 2. 使用别名 在一些场
-
详解C语言常用的一些转换工具函数
1.字符串转十六进制 代码实现: 2.十六进制转字符串 代码实现: 或者 效果:十六进制:0x13 0xAA 0x02转为字符串:"13AAA2" 3.字符串转十进制 代码实现: 第一种,如果带负号 这个就是atoi函数的实现: 效果:字符串:"-123" 转为 -123 第二种,如果不带负号: 效果:字符串:"123" 转为 123 第三种:包含转为浮点数: 效果:字符串:"123.456" 先转为 123456,然后除以1
-
详解go语言单链表及其常用方法的实现
目的 在刷算法题中经常遇到关于链表的操作,在使用go语言去操作链表时不熟悉其实现原理,目的是为了重温链表这一基础且关键的数据结构. 1.链表的特点和初始化 1.1.链表的特点 用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的) 1.2.结点 结点(node) 数据域 => 存储元素信息 指针域 => 存储结点的直接后继,也称作指针或链 首元结点 是指链表中存储的第一个数据元素的结点 头结点 是在首元结点之前附设的一个结点,其指针域指向首元结点(非必须) 头指
-
详解C语言数组越界及其避免方法
所谓的数组越界,简单地讲就是指数组下标变量的取值超过了初始定义时的大小,导致对数组元素的访问出现在数组的范围之外,这类错误也是 C 语言程序中最常见的错误之一. 在 C 语言中,数组必须是静态的.换而言之,数组的大小必须在程序运行前就确定下来.由于 C 语言并不具有类似 Java 等语言中现有的静态分析工具的功能,可以对程序中数组下标取值范围进行严格检查,一旦发现数组上溢或下溢,都会因抛出异常而终止程序.也就是说,C 语言并不检验数组边界,数组的两端都有可能越界,从而使其他变量的数据甚至程序代码
-
详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该
-
详解go语言的并发
1.启动go语言的协程 package main import ( "fmt" "runtime" ) //runtime包 func main() { //runtime.Gosched() 用于让出cpu时间片,让出这段cpu的时间片,让调度器重新分配资源 //写一个匿名函数 s := "test" go func(s string) { for i :=0;i
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y