详解redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value就是具体的customerid集合,后续的话,我就可以通过productid来查看该customerid是否买了此商品,如果购买了,就可以有相关的关联推荐,当然这只是系统中的一个小业务条件,这时候我就可以用到SADD操作方法,代码如下:
static void Main(string[] args)
{
ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("192.168.23.151:6379");
var db = redis.GetDatabase();
var productID = string.Format("productID_{0}", 1);
for (int i = 0; i < 10; i++)
{
var customerID = i;
db.SetAdd(productID, customerID);
}
}
一:问题
但是上面的这段代码很明显存在一个大问题,Redis本身就是基于tcp的一个Request/Response protocol模式,不信的话,可以用wireshark监视一下:

从图中可以看到,有很多次的192.168.23.1 => 192.168.23.151 之间的数据往返,从传输内容中大概也可以看到有一个叫做productid_xxx的前缀,
那如果有百万次局域网这样的round trip,那这个延迟性可想而知,肯定达不到我们预想的高性能。
二:解决方案【Batch】
刚好基于我们现有的业务,我可以定时的将批量的productid和customerid进行分组整合,然后用batch的形式插入到某一个具体的product的set中去,接下来我可以把上面的代码改成类似下面这样:
static void Main(string[] args)
{
ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("...:");
var db = redis.GetDatabase();
var productID = string.Format("productID_{}", );
var list = new List<int>();
for (int i = ; i < ; i++)
{
list.Add(i);
}
db.SetAdd(productID, list.Select(i => (RedisValue)i).ToArray());
}
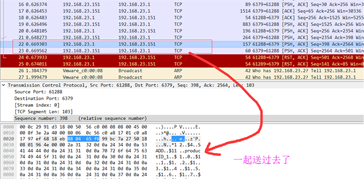
从截图中传输的request,response可以看到,这次我们一次性提交过去,极大的较少了在网络传输方面带来的尴尬性。。
三:再次提出问题
product维度的画像我们可以解决了,但是我们还有一个customerid的维度,也就是说我需要维护一个customerid为key的set集合,其中value的值为该customerid的各种平均值,比如说“总交易次数”,“总交易金额”。。。等等这样的聚合信息,然后推送过来的是批量的customerid,也就是说你需要定时维护一小嘬set集合,在这种情况下某一个set的批量操作就搞不定了。。。原始代码如下:
static void Main(string[] args)
{
ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("...:");
var db = redis.GetDatabase();
//批量过来的数据: customeridlist, ordertotalprice,具体业务逻辑省略
var orderTotalPrice = ;
var customerIDList = new List<int>();
for (int i = ; i < ; i++)
{
customerIDList.Add(i);
}
//foreach更新每个redis 的set集合
foreach (var item in customerIDList)
{
var customerID = string.Format("customerid_{}", item);
db.SetAdd(customerID, orderTotalPrice);
}
}
四:解决方案【PipeLine】
=上面这种代码在生产上当然是行不通的,不过针对这种问题,redis早已经提出了相关的解决方案,那就是pipeline机制,原理还是一样,将命令集整合起来通过一条request请求一起送过去,由redis内部fake出一个client做批量执行操作,代码如下:
static void Main(string[] args)
{
ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("...:");
var db = redis.GetDatabase();
//批量过来的数据: customeridlist, ordertotalprice,具体业务逻辑省略
var orderTotalPrice = ;
var customerIDList = new List<int>();
for (int i = ; i < ; i++)
{
customerIDList.Add(i);
}
var batch = db.CreateBatch();
foreach (var item in customerIDList)
{
var customerID = string.Format("customerid_{}", item);
batch.SetAddAsync(customerID, orderTotalPrice);
}
batch.Execute();
}
然后,我们再看下面的wireshark截图,可以看到有很多的SADD这样的小命令,这就说明有很多命令是一起过去的,大大的提升了性能。

最后可以再看一下redis,数据也是有的,是不是很爽~~~
192.168.23.151:6379> keys * 1) "customerid_0" 2) "customerid_9" 3) "customerid_1" 4) "customerid_3" 5) "customerid_8" 6) "customerid_2" 7) "customerid_7" 8) "customerid_5" 9) "customerid_6" 10) "customerid_4"
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Redis性能大幅提升之Batch批量读写详解
前言 本文主要介绍的是关于Redis性能提升之Batch批量读写的相关内容,分享出来供大家参考学习,下面来看看详细的介绍: 提示:本文针对的是StackExchange.Redis 一.问题呈现 前段时间在开发的时候,遇到了redis批量读的问题,由于在StackExchange.Redis里面我确实没有找到PipeLine命令,找到的是Batch命令,因此对其用法进行了探究一下. 下面的代码是我之前写的: public List<StudentEntity> Get(List<int&
-
详解redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value就是具体的customerid集合,后续的话,我就可以通过productid来查看该customerid是否买了此商品,如果购买了,就可以有相关的关联推荐,当然这只是系统中的一个小业务条件,这时候我就可以用到SADD操作方法,代码如下: static void Main(string[] args) { ConnectionMultip
-
一文详解Redis中的持久化
目录 1. 前言 2. RDB 2.1 手动触发 2.2 自动触发 3. bgsave大致流程 4. RDB持久化方式的优缺点 5. AOF 6. AOF的使用方式 7. AOF流程剖析 7.1 命令写入 7.2 文件同步 7.3 重写机制 7.4 重启加载 8. 问题定位与优化 8.1 关于fork操作 8.2 关于子进程开销 8.3 关于AOF追加阻塞 1. 前言 为什么要进行持久化?:持久化功能有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复. 持久
-
详解Redis中的List类型
本系列将和大家分享Redis分布式缓存,本章主要简单介绍下Redis中的List类型,以及如何使用Redis解决博客数据分页.生产者消费者模型和发布订阅等问题. Redis List的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用这个数据结构. List类型主要用于队列和栈,先进先出,后进先出等. 存储形式:key--LinkList<value> 首先先给大家Show一波Redis中与List类型相
-
详解redis分布式锁的这些坑
一.白话分布式 什么是分布式,用最简单的话来说,就是为了较低单个服务器的压力,将功能分布在不同的机器上面,本来一个程序员可以完成一个项目:需求->设计->编码->测试 但是项目多的时候,一个人也扛不住,这就需要不同的人进行分工合作了 这就是一个简单的分布式协同工作了: 二.分布式锁 首先看一个问题,如果说某个环节被终止或者别侵占,就会发生不可知的事情 这就会出现,设计好的或者设计的半成品会被破坏,导致后面环节出错: 这时候,我们就需要引入分布式锁的概念: 何为分布式锁 当在分布式模型下,
-
详解Redis单线程的正确理解
很多同学对Redis的单线程和I/O多路复用技术并不是很了解,所以我用简单易懂的语言让大家了解下Redis单线程和I/O多路复用技术的原理,对学好和运用好Redis打下基础. 一.Redis的单线程理解 Redis客户端对服务端的每次调用都经历了发送命令,执行命令,返回结果三个过程.其中执行命令阶段,由于Redis是单线程来处理命令的,所有到达服务端的命令都不会立刻执行,所有的命令都会进入一个队列中,然后逐个执行,并且多个客户端发送的命令的执行顺序是不确定的,但是可以确定的是不会有两条命令被同时
-
详解Redis瘦身指南
Redis内存回收 Redis 服务器的最大占用内存量由配置项 maxmemory 决定,我们可以通过 config set maxmemory 2GB 的格式来配置.一旦 Redis 内存满,所有引起内存增加的操作都会被返回 error.作为专业 Redis 服务器我们通常将此项设置为0,以服务器系统内存来作为限制: 那么 Redis 使用内存达到了上限怎么办?Redis 为我们提供了几种选项以自动回收内存,可以通过配置项 maxmemory-policy 来配置: noeviction 不回
-
详解C/C++性能优化背后的方法论TMAM
目录 前言 一.示例 二.CPU 流水线介绍 三.自顶向下分析(TMAM) 3.1.基础分类 3.1.1.Retiring 3.1.2.Bad Speculation 3.1.3.Front-End-Boun 3.1.4.Back-End-Bound 3.3.如何针对不同类别进行优化? 3.3.1.Front-End Bound 3.3.2.Back-End Bound 3.3.3.Bad Speculation分支预测 四.写在最后 五.CPU知识充电站 前言 性能优化的难点在于找出关键的性能
-
详解让Python性能起飞的15个技巧
目录 前言 如何测量程序的执行时间 1.使用map()进行函数映射 2.使用set()求交集 3.使用sort()或sorted()排序 4.使用collections.Counter()计数 5.使用列表推导 6.使用join()连接字符串 7.使用x,y=y,x交换变量 8.使用while1取代whileTrue 9.使用装饰器缓存 10.减少点运算符(.)的使用 11.使用for循环取代while循环 12.使用Numba.jit加速计算 13.使用Numpy矢量化数组 14.使用in检查
-
详解Redis命令和键_动力节点Java学院整理
Redis命令用于在redis服务器上执行某些操作. 要在Redis服务器上运行的命令,需要一个Redis客户端. Redis客户端在Redis的包,这已经我们前面安装使用过了. 语法 Redis客户端的基本语法如下: $redis-cli 例子 下面举例说明如何使用Redis客户端. 要启动redis客户端,打开终端,输入命令Redis命令行:redis-cli.这将连接到本地服务器,现在就可以运行各种命令了. $redis-cli redis 127.0.0.1:6379> redis 12
-
详解redis数据结构之sds
详解redis数据结构之sds 字符串在redis中使用非常广泛,在redis中,所有的数据都保存在字典(Map)中,而字典的键就是字符串类型,并且对于很大一部分字典值数据也是又字符串组成的.以下是sds的具体存储结构: 从图中可以看出,sds的属性有三个:len.free和buf数组.这里len字段是用来保存sds字符串中所包含字符数目的,free字段则是用来保存buf数组中空余的部分的长度的,而buf数组则是实际用来保存字符串的.比如如下结构保存了"Hello World!"这个字