Python实现二叉堆
优先队列的二叉堆实现
在前面的章节里我们学习了“先进先出”(FIFO)的数据结构:队列(Queue)。队列有一种变体叫做“优先队列”(Priority Queue)。优先队列的出队(Dequeue)操作和队列一样,都是从队首出队。但在优先队列的内部,元素的次序却是由“优先级”来决定:高优先级的元素排在队首,而低优先级的元素则排在后面。这样,优先队列的入队(Enqueue)操作就比较复杂,需要将元素根据优先级尽量排到队列前面。我们将会发现,对于下一节要学的图算法中的优先队列是很有用的数据结构。
我们很自然地会想到用排序算法和队列的方法来实现优先队列。但是,在列表里插入一个元素的时间复杂度是O(n),对列表进行排序的时间复杂度是O(nlogn)。我们可以用别的方法来降低时间复杂度。一个实现优先队列的经典方法便是采用二叉堆(Binary Heap)。二叉堆能将优先队列的入队和出队复杂度都保持在O(logn)。
二叉堆的有趣之处在于,其逻辑结构上像二叉树,却是用非嵌套的列表来实现。二叉堆有两种:键值总是最小的排在队首称为“最小堆(min heap)”,反之,键值总是最大的排在队首称为“最大堆(max heap)”。在这一节里我们使用最小堆。
二叉堆的操作
二叉堆的基本操作定义如下:
BinaryHeap():创建一个空的二叉堆对象insert(k):将新元素加入到堆中findMin():返回堆中的最小项,最小项仍保留在堆中delMin():返回堆中的最小项,同时从堆中删除isEmpty():返回堆是否为空size():返回堆中节点的个数buildHeap(list):从一个包含节点的列表里创建新堆
下面所示代码是二叉堆的示例。可以看到无论我们以哪种顺序把元素添加到堆里,每次都是移除最小的元素。我们接下来要来实现这个过程。
from pythonds.trees.binheap import BinHeap bh = BinHeap() bh.insert(5) bh.insert(7) bh.insert(3) bh.insert(11) print(bh.delMin()) print(bh.delMin()) print(bh.delMin()) print(bh.delMin())
为了更好地实现堆,我们采用二叉树。我们必须始终保持二叉树的“平衡”,就要使操作始终保持在对数数量级上。平衡的二叉树根节点的左右子树的子节点个数相同。在堆的实现中,我们采用“完全二叉树”的结构来近似地实现“平衡”。完全二叉树,指每个内部节点树均达到最大值,除了最后一层可以只缺少右边的若干节点。图 1 所示是一个完全二叉树。
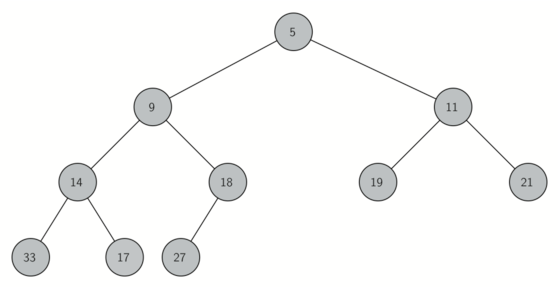
图 1:完全二叉树
有意思的是我们用单个列表就能实现完全树。我们不需要使用节点,引用或嵌套列表。因为对于完全二叉树,如果节点在列表中的下标为 p,那么其左子节点下标为 2p,右节点为 2p+1。当我们要找任何节点的父节点时,可以直接使用 python 的整除。如果节点在列表中下标为n,那么父节点下标为n//2.图 2 所示是一个完全二叉树和树的列表表示法。注意父节点与子节点之间 2p 与 2p+1 的关系。完全树的列表表示法结合了完全二叉树的特性,使我们能够使用简单的数学方法高效地遍历一棵完全树。这也使我们能高效实现二叉堆。
堆次序的性质
我们在堆里储存元素的方法依赖于堆的次序。所谓堆次序,是指堆中任何一个节点 x,其父节点 p 的键值均小于或等于 x 的键值。图 2 所示是具备堆次序性质的完全二叉树。
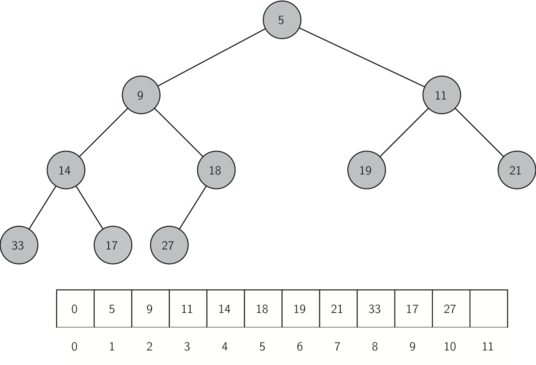
图 2:完全树和它的列表表示法
二叉堆操作的实现
接下来我们来构造二叉堆。因为可以采用一个列表保存堆的数据,构造函数只需要初始化一个列表和一个currentSize来表示堆当前的大小。Listing 1 所示的是构造二叉堆的 python 代码。注意到二叉堆的heaplist并没有用到,但为了后面代码可以方便地使用整除,我们仍然保留它。
Listing 1
class BinHeap:
def __init__(self):
self.heapList = [0]
self.currentSize = 0
我们接下来要实现的是insert方法。首先,为了满足“完全二叉树”的性质,新键值应该添加到列表的末尾。然而新键值简单地添加在列表末尾,显然无法满足堆次序。但我们可以通过比较父节点和新加入的元素的方法来重新满足堆次序。如果新加入的元素比父节点要小,可以与父节点互换位置。图 3 所示的是一系列交换操作来使新加入元素“上浮”到正确的位置。
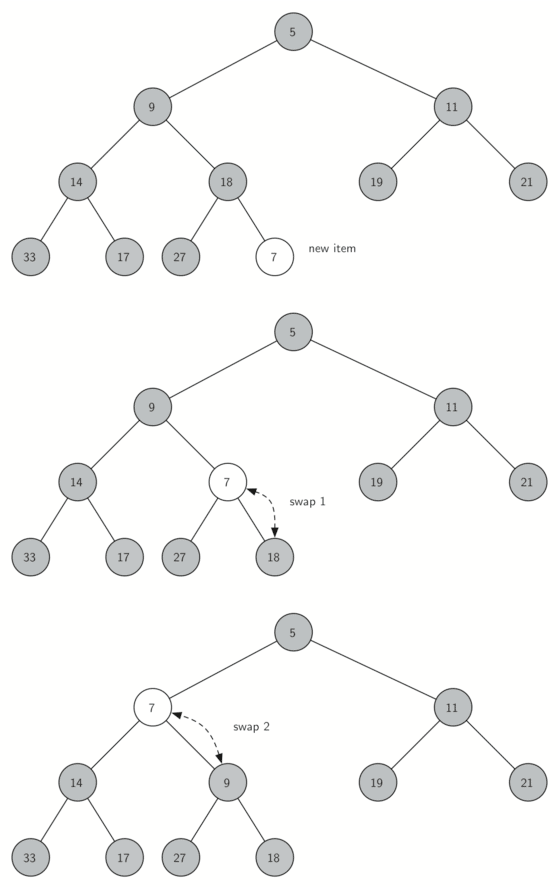
图 3:新节点“上浮”到其正确位置
当我们让一个元素“上浮”时,我们要保证新节点与父节点以及其他兄弟节点之间的堆次序。当然,如果新节点非常小,我们仍然需要将它交换到其他层。事实上,我们需要不断交换,直到到达树的顶端。Listing 2 所示的是“上浮”方法,它把一个新节点“上浮”到其正确位置来满足堆次序。这里很好地体现了我们之前在headlist中没有用到的元素 0 的重要性。这样只需要做简单的整除,将当前节点的下标除以 2,我们就能计算出任何节点的父节点。
在Listing 3 中,我们已经可以写出insert方法的代码。insert里面很大一部分工作是由percUp函数完成的。当树添加新节点时,调用percUp就可以将新节点放到正确的位置上。
Listing 2
def percUp(self,i):
while i // 2 > 0:
if self.heapList[i] < self.heapList[i // 2]:
tmp = self.heapList[i // 2]
self.heapList[i // 2] = self.heapList[i]
self.heapList[i] = tmp
i = i // 2
Listing 3
def insert(self,k): self.heapList.append(k) self.currentSize = self.currentSize + 1 self.percUp(self.currentSize)
我们已经写好了insert方法,那再来看看delMin方法。堆次序要求根节点是树中最小的元素,因此很容易找到最小项。比较困难的是移走根节点的元素后如何保持堆结构和堆次序,我们可以分两步走。首先,用最后一个节点来代替根节点。移走最后一个节点保持了堆结构的性质。这么简单的替换,还是会破坏堆次序。那么第二步,将新节点“下沉”来恢复堆次序。图 4 所示的是一系列交换操作来使新节点“下沉”到正确的位置。
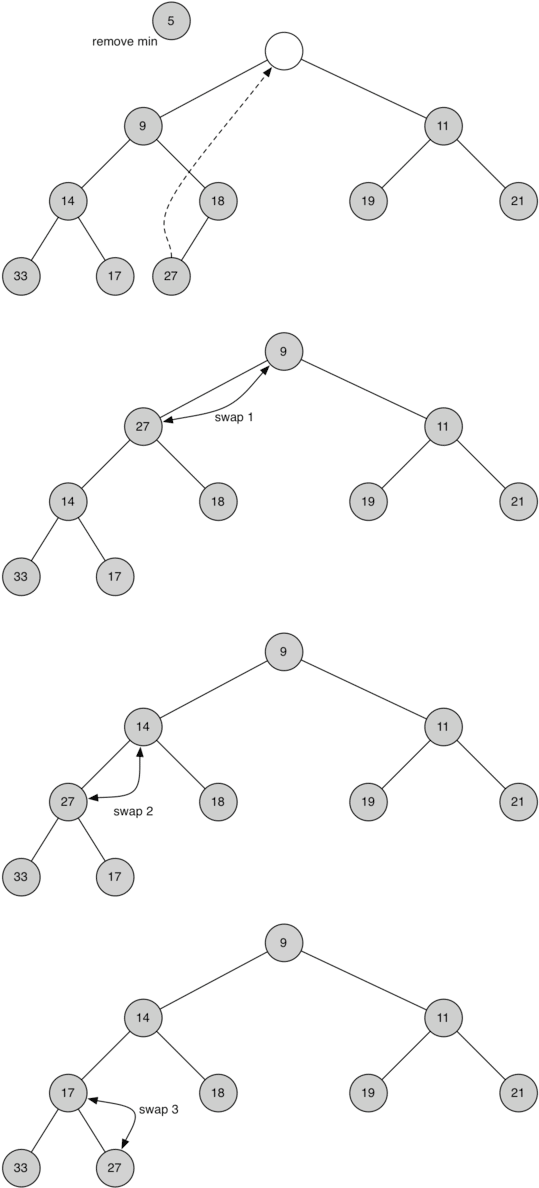
图 4:替换后的根节点下沉
为了保持堆次序,我们需将新的根节点沿着一条路径“下沉”,直到比两个子节点都小。在选择下沉路径时,如果新根节点比子节点大,那么选择较小的子节点与之交换。Listing 4 所示的是新节点下沉所需的percDown和minChild方法的代码。
Listing 4
def percDown(self,i):
while (i * 2) <= self.currentSize:
mc = self.minChild(i)
if self.heapList[i] > self.heapList[mc]:
tmp = self.heapList[i]
self.heapList[i] = self.heapList[mc]
self.heapList[mc] = tmp
i = mc
def minChild(self,i):
if i * 2 + 1 > self.currentSize:
return i * 2
else:
if self.heapList[i*2] < self.heapList[i*2+1]:
return i * 2
else:
return i * 2 + 1
Listing 5 所示的是delMin操作的代码。可以看到比较麻烦的地方由一个辅助函数来处理,即percDown。
Listing 5
def delMin(self): retval = self.heapList[1] self.heapList[1] = self.heapList[self.currentSize] self.currentSize = self.currentSize - 1 self.heapList.pop() self.percDown(1) return retval
关于二叉堆的最后一部分便是找到从无序列表生成一个“堆”的方法。我们首先想到的是,将无序列表中的每个元素依次插入到堆中。对于一个排好序的列表,我们可以用二分搜索找到合适的位置,然后在下一个位置插入这个键值到堆中,时间复杂度为O(logn)。另外插入一个元素到列表中需要将列表的一些其他元素移动,为新节点腾出位置,时间复杂度为O(n)。因此用insert方法的总开销是O(nlogn)。其实我们能直接将整个列表生成堆,将总开销控制在O(n)。Listing 6 所示的是生成堆的操作。
Listing 6
def buildHeap(self,alist):
i = len(alist) // 2
self.currentSize = len(alist)
self.heapList = [0] + alist[:]
while (i > 0):
self.percDown(i)
i = i - 1
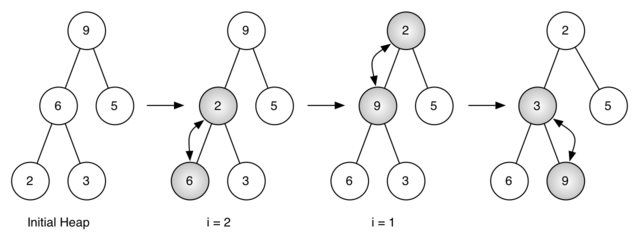
图 5:将列表[ 9, 6, 5, 2, 3]生成一个二叉堆
图 5 所示的是利用buildHeap方法将最开始的树[ 9, 6, 5, 2, 3]中的节点移动到正确的位置时所做的交换操作。尽管我们从树中间开始,然后回溯到根节点,但percDown方法保证了最大子节点总是“下沉”。因为堆是完全二叉树,任何在中间的节点都是叶节点,因此没有子节点。注意,当i=1时,我们从根节点开始下沉,这就需要进行大量的交换操作。可以看到,图 5 最右边的两颗树,首先 9 从根节点的位置移走,移到下一层级之后,percDown进一步检查它此时的子节点,保证它下降到不能再下降为止,即下降到正确的位置。然后进行第二次交换,9 和 3 的交换。由于 9 已经移到了树最底层的层级,便无法进一步交换了。比较一下列表表示法和图 5 所示的树表示法进行的一系列交换还是很有帮助的。
i = 2 [0, 9, 5, 6, 2, 3] i = 1 [0, 9, 2, 6, 5, 3] i = 0 [0, 2, 3, 6, 5, 9]
下列所示的代码是完全二叉堆的实现。
def insert(self,k):
self.heapList.append(k)
self.currentSize = self.currentSize + 1
self.percUp(self.currentSize)
def percDown(self,i):
while (i * 2) <= self.currentSize:
mc = self.minChild(i)
if self.heapList[i] > self.heapList[mc]:
tmp = self.heapList[i]
self.heapList[i] = self.heapList[mc]
self.heapList[mc] = tmp
i = mc
def minChild(self,i):
if i * 2 + 1 > self.currentSize:
return i * 2
else:
if self.heapList[i*2] < self.heapList[i*2+1]:
return i * 2
else:
return i * 2 + 1
def delMin(self):
retval = self.heapList[1]
self.heapList[1] = self.heapList[self.currentSize]
self.currentSize = self.currentSize - 1
能在O(n)的开销下能生成二叉堆看起来有点不可思议,其证明超出了本书的范围。但是,要理解用O(n)的开销能生成堆的关键是因为logn因子基于树的高度。而对于buildHeap里的许多操作,树的高度比logn要小。
相关推荐
-

详解Python中heapq模块的用法
heapq 模块提供了堆算法.heapq是一种子节点和父节点排序的树形数据结构.这个模块提供heap[k] <= heap[2*k+1] and heap[k] <= heap[2*k+2].为了比较不存在的元素被人为是无限大的.heap最小的元素总是[0]. 打印 heapq 类型 import math import random from cStringIO import StringIO def show_tree(tree, total_width=36, fill=' '): ou
-
python实现堆栈与队列的方法
本文实例讲述了python实现堆栈与队列的方法.分享给大家供大家参考.具体分析如下: 1.python实现堆栈,可先将Stack类写入文件stack.py,在其它程序文件中使用from stack import Stack,然后就可以使用堆栈了. stack.py的程序: 复制代码 代码如下: class Stack(): def __init__(self,size): self.size=size; self.stack=[];
-
Python实现堆排序的方法详解
本文实例讲述了Python实现堆排序的方法.分享给大家供大家参考,具体如下: 堆排序作是基本排序方法的一种,类似于合并排序而不像插入排序,它的运行时间为O(nlogn),像插入排序而不像合并排序,它是一种原地排序算法,除了输入数组以外只占用常数个元素空间. 堆(定义):(二叉)堆数据结构是一个数组对象,可以视为一棵完全二叉树.如果根结点的值大于(小于)其它所有结点,并且它的左右子树也满足这样的性质,那么这个堆就是大(小)根堆. 我们假设某个堆由数组A表示,A[1]为树的根,给定某个结点的下标i,
-
python 实现堆排序算法代码
复制代码 代码如下: #!/usr/bin/python import sys def left_child(node): return node * 2 + 1 def right_child(node): return node * 2 + 2 def parent(node): if (node % 2): return (i - 1) / 2 else: return (i - 2) / 2 def max_heapify(array, i, heap_size): l = left_c
-
Python记录详细调用堆栈日志的方法
本文实例讲述了Python记录详细调用堆栈日志的方法.分享给大家供大家参考.具体实现方法如下: import sys import os def detailtrace(info): retStr = "" curindex=0 f = sys._getframe() f = f.f_back # first frame is detailtrace, ignore it while hasattr(f, "f_code"): co = f.f_code retSt
-
Python实现二叉堆
优先队列的二叉堆实现 在前面的章节里我们学习了"先进先出"(FIFO)的数据结构:队列(Queue).队列有一种变体叫做"优先队列"(Priority Queue).优先队列的出队(Dequeue)操作和队列一样,都是从队首出队.但在优先队列的内部,元素的次序却是由"优先级"来决定:高优先级的元素排在队首,而低优先级的元素则排在后面.这样,优先队列的入队(Enqueue)操作就比较复杂,需要将元素根据优先级尽量排到队列前面.我们将会发现,对于下一
-
python下实现二叉堆以及堆排序的示例
堆是一种特殊的树形结构, 堆中的数据存储满足一定的堆序.堆排序是一种选择排序, 其算法复杂度, 时间复杂度相对于其他的排序算法都有很大的优势. 堆分为大头堆和小头堆, 正如其名, 大头堆的第一个元素是最大的, 每个有子结点的父结点, 其数据值都比其子结点的值要大.小头堆则相反. 我大概讲解下建一个树形堆的算法过程: 找到N/2 位置的数组数据, 从这个位置开始, 找到该节点的左子结点的索引, 先比较这个结点的下的子结点, 找到最大的那个, 将最大的子结点的索引赋值给左子结点, 然后将最大的子结点
-
理解二叉堆数据结构及Swift的堆排序算法实现示例
二叉堆的性质 1.二叉堆是一颗完全二叉树,最后一层的叶子从左到右排列,其它的每一层都是满的 2.最小堆父结点小于等于其每一个子结点的键值,最大堆则相反 3.每个结点的左子树或者右子树都是一个二叉堆 下面是一个最小堆: 堆的存储 通常堆是通过一维数组来实现的.在起始数组为 0 的情形中: 1.父节点i的左子节点在位置 (2*i+1); 2.父节点i的右子节点在位置 (2*i+2); 3.子节点i的父节点在位置 floor((i-1)/2); 维持堆的性质 我们以最大堆来介绍(后续会分别给出最大堆和
-
PHP利用二叉堆实现TopK-算法的方法详解
前言 在以往工作或者面试的时候常会碰到一个问题,如何实现海量TopN,就是在一个非常大的结果集里面快速找到最大的前10或前100个数,同时要保证内存和速度的效率,我们可能第一个想法就是利用排序,然后截取前10或前100,而排序对于量不是特别大的时候没有任何问题,但只要量特别大是根本不可能完成这个任务的,比如在一个数组或者文本文件里有几亿个数,这样是根本无法全部读入内存的,所以利用排序解决这个问题并不是最好的,所以我们这里就用php去实现一个小顶堆来解决这个问题. 二叉堆 二叉堆是一种特殊的堆,二
-
java编程实现优先队列的二叉堆代码分享
这里主要介绍的是优先队列的二叉堆Java实现,代码如下: package practice; import edu.princeton.cs.algs4.StdRandom; public class TestMain { public static void main(String[] args) { int[] a = new int[20]; for (int i = 0; i < a.length; i++) { int temp = (int)(StdRandom.random()*1
-
Java语言实现二叉堆的打印代码分享
二叉堆是一种特殊的堆,二叉堆是完全二元树(二叉树)或者是近似完全二元树(二叉树).二叉堆有两种:最大堆和最小堆.最大堆:父结点的键值总是大于或等于任何一个子节点的键值:最小堆:父结点的键值总是小于或等于任何一个子节点的键值. 打印二叉堆:利用层级关系 我这里是先将堆排序,然后在sort里执行了打印堆的方法printAsTree() public class MaxHeap<T extends Comparable<? super T>> { private T[] data; pr
-
Python实现二叉搜索树BST的方法示例
二叉排序树(BST)又称二叉查找树.二叉搜索树 二叉排序树(Binary Sort Tree)又称二叉查找树.它或者是一棵空树:或者是具有下列性质的二叉树: 1.若左子树不空,则左子树上所有结点的值均小于根结点的值: 2.若右子树不空,则右子树上所有结点的值均大于根节点的值: 3.左.右子树也分别为二叉排序树. 求树深度 按序输出节点值(使用中序遍历) 查询二叉搜索树中一个具有给点关键字的结点,返回该节点的位置.时间复杂度是O(h),h是树的高度. 递归/迭代求最大关键字元素 递归/迭代求最小关
-
彻底搞定堆排序:二叉堆
目录 二叉堆 插入 删除 构建 二叉堆代码实现 总结 二叉堆 什么是二叉堆 二叉堆本质上是一种完全二叉树,它分为两个类型 最大堆:最大堆的任何一个父节点的值,都大于等于它的左.右孩子节点的值(堆顶就是整个堆的最大元素) 最小堆:最小堆的任何一个父节点的值,都小于等于它的左.右孩子节点的值(堆顶就是整个堆的最小元素) 二叉堆的根节点叫做堆顶 二叉堆的基本操作 插入节点 删除节点 构建二叉堆 这几种操作都基于堆的自我调整,所谓堆自我调整,就是把一个不符合堆的完全二叉树,调整成一个堆,下面以最小堆为例
-
C语言每日练习之二叉堆
目录 一.堆的概念 1.概述 2.定义 3.性质 4.作用 二.堆的存储结构 1.根结点编号 2.孩子结点编号 3.父结点编号 4.数据域 5.堆的数据结构 三.堆的常用接口 1.元素比较 2.交换元素 3.空判定 4.满判定 5.上浮操作 6.下沉操作 四.堆的创建 1.算法描述 2.动画演示 3.源码详解 五.堆元素的插入 1.算法描述 2.动画演示 3.源码详解 五.堆元素的删除 1.算法描述 2.动画演示 3.源码详解 总结 一.堆的概念 1.概述 堆是计算机科学中一类特殊的数据结构的统
-
Java实现二叉堆、大顶堆和小顶堆
目录 什么是二叉堆 什么是大顶堆.小顶堆 建堆 程序实现 建立大顶堆 逻辑过程 程序实现 建立小顶堆 逻辑过程 程序实现 从堆顶取数据并重构大小顶堆 什么是二叉堆 二叉堆就是完全二叉树,或者是靠近完全二叉树结构的二叉树.在二叉树建树时采取前序建树就是建立的完全二叉树.也就是二叉堆.所以二叉堆的建堆过程理论上讲和前序建树一样. 什么是大顶堆.小顶堆 二叉堆本质上是一棵近完全的二叉树,那么大顶堆和小顶堆必然也是满足这个结构要求的.在此之上,大顶堆要求对于一个节点来说,它的左右节点都比它小:小顶堆要求