Python无损音乐搜索引擎实现代码

研究了一段时间酷狗音乐的接口,完美破解了其vip音乐下载方式,想着能更好的追求开源,故写下此篇文章,本文仅供学习参考。虽然没什么技术含量,但都是自己一点一点码出来,一点一点抓出来的。
一、综述:
根据酷狗的搜索接口以及无损音乐下载接口,做出爬虫系统。采用flask框架,前端提取搜索关键字,后端调用爬虫系统采集数据,并将数据前端呈现;
运行环境:windows/linux python2.7
二、爬虫开发:
通过抓包的方式对酷狗客户端进行抓包,抓到两个接口:
1、搜索接口:
http://songsearch.kugou.com/song_search_v2?keyword={关键字}page=1
这个接口通过传递关键字,其返回的是一段json数据,数据包含音乐名称、歌手、专辑、总数据量等信息,当然最重要的是数据包含音乐各个品质的hash。

默认接口返回的数据只包含30首音乐,为了能拿到所有的数据,只需要把pagesize更改就可以,所以我提取了总数据数量,然后再次发动一次数据请求,拿到全部的数据。当然,这个总数据量也就是json中的total也是作为搜索结果的依据,如果total == 0 则判断无法搜索到数据。
搜索到数据后,我就要提取无损音乐的hash,这个hash是音乐下载的关键,无损音乐hash键名:SQFileHash,提取到无损hash(如果是32个0就表示None),我把他的名称、歌手、hash以字典形式传递给下一个模块。
代码实现:
a.请求模块(复用率高):
# coding=utf-8
import requests
import json
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/63.0.3239.132 Safari/537.36',
}
def parse(url):
ret = json.loads(requests.get(url, headers=headers, timeout=5).text)
# 返回的是已经转换过后的字典数据
return ret
if __name__ == '__main__':
parse()
b.搜索模块
# coding=utf-8
import copy
import MusicParse
def search(keyword):
search_url = 'http://songsearch.kugou.com/song_search_v2?keyword={}page=1'.format(keyword)
# 这里需要判断一下,ip与搜索字段可能会限制搜索,total进行判断
total = MusicParse.parse(search_url)['data']['total']
if total != 0:
search_total_url = search_url + '&pagesize=%d' % total
music_list = MusicParse.parse(search_total_url)['data']['lists']
item, items = {}, []
for music in music_list:
if music['SQFileHash'] != '0'*32:
item['Song'] = music['SongName'] # 歌名
item['Singer'] = music['SingerName'] # 歌手
item['Hash'] = music['SQFileHash'] # 歌曲无损hash
items.append(copy.deepcopy(item))
return items
else:
return None
if __name__ == '__main__':
search()
到这步,音乐搜索接口以及利用完了,下面就是无损音乐搜索了。
2、音乐下载接口:
# V2版系统,pc版 Music_api_1 = 'http://trackercdnbj.kugou.com/i/v2/?cmd=23&pid=1&behavior=download' # V2版系统,手机版(备用) Music_api_2 = 'http://trackercdn.kugou.com/i/v2/?appid=1005&pid=2&cmd=25&behavior=play' # 老版系统(备用) Music_api_3 = 'http://trackercdn.kugou.com/i/?cmd=4&pid=1&forceDown=0&vip=1'
我这里准备三个接口,根据酷狗系统版本不同,采用不同加密方式,酷狗音乐下载的关键就是音乐接口处提交的key的加密方式,key是由hash加密生成的,不同的酷狗版本,加密方式不同:
酷狗v2版key的生成:md5(hash +”kgcloudv2″)
酷狗老版key的生成:md5(hash +”kgcloud”)
只要将音乐的hash+key添加到api_url ,get提交过去,就能返回一段json数据,数据中就包括了音乐的下载链接,然后在提取其download_url。下面我将采用酷狗的第一个接口完成代码的实现,当然,酷狗存在地区的限制,接口有效性也带检测,如果第一个不行就换一个,你懂得!!!然后我把数据做成字典进行传递。
代码实现:
# coding=utf-8
import copy
import hashlib
import MusicParse
import MusicSearch
# V2版系统,pc版,加密方式为md5(hash +"kgcloudv2")
Music_api_1 = 'http://trackercdnbj.kugou.com/i/v2/?cmd=23&pid=1&behavior=download'
# V2版系统,手机版,加密方式为md5(hash +"kgcloudv2") (备用)
Music_api_2 = 'http://trackercdn.kugou.com/i/v2/?appid=1005&pid=2&cmd=25&behavior=play'
# 老版系统,加密方式为md5(hash +"kgcloud")(备用)
Music_api_3 = 'http://trackercdn.kugou.com/i/?cmd=4&pid=1&forceDown=0&vip=1'
def V2Md5(Hash): # 用于生成key,适用于V2版酷狗系统
return hashlib.md5((Hash + 'kgcloudv2').encode('utf-8')).hexdigest()
def Md5(Hash): # 用于老版酷狗系统
return hashlib.md5((Hash + 'kgcloud').encode('utf-8')).hexdigest()
def HighSearch(keyword):
music_list = MusicSearch.search(keyword)
if music_list is not None:
item, items = {}, []
for music in music_list:
Hash = str.lower(music['Hash'].encode('utf-8'))
key_new = V2Md5(Hash) # 生成v2系统key
try:
DownUrl = MusicParse.parse(Music_api_1 + '&hash=%s&key=%s' % (Hash, key_new))['url']
item['Song'] = music['Song'].encode('utf-8') # 歌名
item['Singer'] = music['Singer'].encode('utf-8') # 歌手
item['url'] = DownUrl
items.append(copy.deepcopy(item))
except KeyError:
pass
return items
if __name__ == '__main__':
HighSearch()
酷狗的爬虫系统就设计完毕了,下面开始使用flask框架搭建前后端了。
三、引擎搭建
这个搜索引擎是基于flask框架的,设计思路比较简单,就是前端传递post数据(keyword)传递到后端,后端拿着这个keyword传递给爬虫,爬虫把数据返回给系统,系统在前端渲染出来。
代码实现:
# coding=utf-8
import sys
from flask import Flask
from flask import request, render_template
from KgSpider import HighMusicSearch
reload(sys)
sys.setdefaultencoding('utf-8')
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def search():
if request.method == 'GET':
return render_template('index.html')
elif request.method == 'POST':
keyword = request.form.get('keyword')
items = HighMusicSearch.HighSearch(keyword)
if items != None:
return render_template('list.html', list=items)
else:
return '找不到!!!不支持英文'
else:
return render_template('404.html')
if __name__ == '__main__':
app.run(debug=True)
四、调试
整改引擎系统,也就设计完毕,然我们试试效果:
1.启动脚本:python run.py
2.输入关键字进行搜索
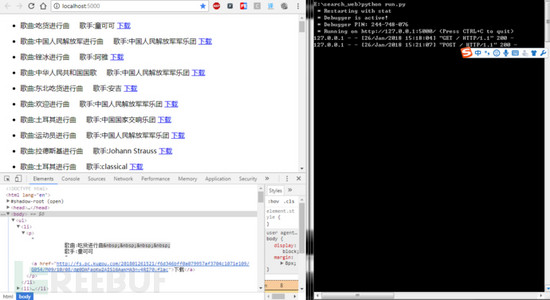
五、总结
引擎搭建完毕,也能正常的运行了,但是这只是一个模型,完全没有考虑,多用户访问带来的压力,很容易崩溃,当然经过我的测试,发现只能搜索中文,英文完全无效,why?别问我,我也不知道!!!当然在这里我也想说一下,请尊重版权!!!虽然我是口是心非!!!!!
项目地址: 码云项目地址
总结
以上所述是小编给大家介绍的Python无损音乐搜索引擎实现代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- 浅谈用Python实现一个大数据搜索引擎
- Python搜索引擎实现原理和方法
- Python中使用haystack实现django全文检索搜索引擎功能
- 用python做一个搜索引擎(Pylucene)的实例代码
- 以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法
相关推荐
-
Python中使用haystack实现django全文检索搜索引擎功能
前言 django是python语言的一个web框架,功能强大.配合一些插件可为web网站很方便地添加搜索功能. 搜索引擎使用whoosh,是一个纯python实现的全文搜索引擎,小巧简单. 中文搜索需要进行中文分词,使用jieba. 直接在django项目中使用whoosh需要关注一些基础细节问题,而通过haystack这一搜索框架,可以方便地在django中直接添加搜索功能,无需关注索引建立.搜索解析等细节问题. haystack支持多种搜索引擎,不仅仅是whoosh,使用solr.elas
-
以Python的Pyspider为例剖析搜索引擎的网络爬虫实现方法
在这篇文章中,我们将分析一个网络爬虫. 网络爬虫是一个扫描网络内容并记录其有用信息的工具.它能打开一大堆网页,分析每个页面的内容以便寻找所有感兴趣的数据,并将这些数据存储在一个数据库中,然后对其他网页进行同样的操作. 如果爬虫正在分析的网页中有一些链接,那么爬虫将会根据这些链接分析更多的页面. 搜索引擎就是基于这样的原理实现的. 这篇文章中,我特别选了一个稳定的."年轻"的开源项目pyspider,它是由 binux 编码实现的. 注:据认为pyspider持续监控网络,它假定网页在一
-

Python搜索引擎实现原理和方法
如何在庞大的数据中高效的检索自己需要的东西?本篇内容介绍了Python做出一个大数据搜索引擎的原理和方法,以及中间进行数据分析的原理也给大家做了详细介绍. 布隆过滤器 (Bloom Filter) 第一步我们先要实现一个布隆过滤器. 布隆过滤器是大数据领域的一个常见算法,它的目的是过滤掉那些不是目标的元素.也就是说如果一个要搜索的词并不存在与我的数据中,那么它可以以很快的速度返回目标不存在. 让我们看看以下布隆过滤器的代码: class Bloomfilter(object): ""&
-
浅谈用Python实现一个大数据搜索引擎
搜索是大数据领域里常见的需求.Splunk和ELK分别是该领域在非开源和开源领域里的领导者.本文利用很少的Python代码实现了一个基本的数据搜索功能,试图让大家理解大数据搜索的基本原理. 布隆过滤器 (Bloom Filter) 第一步我们先要实现一个布隆过滤器. 布隆过滤器是大数据领域的一个常见算法,它的目的是过滤掉那些不是目标的元素.也就是说如果一个要搜索的词并不存在与我的数据中,那么它可以以很快的速度返回目标不存在. 让我们看看以下布隆过滤器的代码: class Bloomfilter(
-
用python做一个搜索引擎(Pylucene)的实例代码
1.什么是搜索引擎? 搜索引擎是"对网络信息资源进行搜集整理并提供信息查询服务的系统,包括信息搜集.信息整理和用户查询三部分".如图1是搜索引擎的一般结构,信息搜集模块从网络采集信息到网络信息库之中(一般使用爬虫):然后信息整理模块对采集的信息进行分词.去停用词.赋权重等操作后建立索引表(一般是倒排索引)构成索引库:最后用户查询模块就可以识别用户的检索需求并提供检索服务啦. 图1 搜索引擎的一般结构 2. 使用python实现一个简单搜索引擎 2.1 问题分析 从图1看,一个完整的搜索
-
Python无损音乐搜索引擎实现代码
研究了一段时间酷狗音乐的接口,完美破解了其vip音乐下载方式,想着能更好的追求开源,故写下此篇文章,本文仅供学习参考.虽然没什么技术含量,但都是自己一点一点码出来,一点一点抓出来的. 一.综述: 根据酷狗的搜索接口以及无损音乐下载接口,做出爬虫系统.采用flask框架,前端提取搜索关键字,后端调用爬虫系统采集数据,并将数据前端呈现: 运行环境:windows/linux python2.7 二.爬虫开发: 通过抓包的方式对酷狗客户端进行抓包,抓到两个接口: 1.搜索接口: http://son
-
基于python实现音乐播放器代码实例
核心播放模块(pygame内核) import time import pygame import easygui as gui file = r'D:\CloudMusic\G.E.M.邓紫棋,艾热 - 光年之外 (热爱版).mp3' #这里为音乐文件路径 pygame.mixer.init() gui.msgbox("正在播放"+file) track = pygame.mixer.music.load(file) pygame.mixer.music.play() time.sl
-
python基于tkinter制作无损音乐下载工具(附源码)
继续写GUI,本次依然使用Tkinter设计一款图形界面,使用Tkinter做一款音乐下载软件,听起来听平常的,但是我这款软件能够下载 无损音乐下载软件,听起来不错吧,Let`s go! 一.准备工作 python Tkinter 二.预览 1.搜索 2.下载 3.结果 无损音乐就这样下载完了. 三.详细设计 这里仅展示我设计的整体思路. 四.源代码 4.1 Music_Search-v1.0.py from tkinter import * from tkinter import ttk fr
-
python爬取网易云音乐排行榜实例代码
目录 网易云音乐排行榜歌曲及评论爬取 一.模拟登录 二.排行榜数据爬取 三.排行榜评论获取 总结 网易云音乐排行榜歌曲及评论爬取 主要注意问题:selenium 模拟登录.iframe标签定位.页面元素提取. 在利用selenium定位元素并取值的过程中遇到问题.比如xpath正确但无法定位,在进行翻页提取评论的过程中,利用selenium似乎不能提取不同页的数据,比如,明明定位的第三页的评论数据,而只能返回第一页的评论数据. 一.模拟登录 selenium 定位元素模拟人的操作进行登录,直接上
-
基于Python实现音乐播放器的实现示例代码
目录 一.环境设置 二.播放功能 三.停止功能 四.暂停与恢复 五.关闭 六.完整代码 七.改进 一.环境设置 第一步引入必须的各类包 import os import tkinter import tkinter.filedialog import random import time import threading import pygame 特别是pygame需要手动安装 pip install pygame 二.播放功能 首先选择音乐目录,然后创建播放现成,播放音乐. # 播放按钮 d
-
python实现音乐播放器 python实现花框音乐盒子
本文实例为大家分享了python实现音乐播放器的具体代码,供大家参考,具体内容如下 """这是一个用海龟画图模块和pygame的混音模块制作的简易播放器. 作者:李兴球,日期:2018/8/26""" from turtle import * def init_screen(): """初始化屏幕""" screen = Screen() screen.setup(width,heigh
-
python实现音乐播放和下载小程序功能
(本篇部分代码综合整理自B站,B站有手把手说明的教程) 1.网易云非付费内容爬取器(声明:由于技术十分简单,未到触犯软件使用规则的程度)驱动Edge浏览器(自己写驱动会更高端)进入界面,爬取列表中第一个音频地址并存入相应文件夹中.这里有一个最简单的爬虫程序和一个最简单的tkinter GUI编程. 注意,要先在网易云音乐网页中将第一个对应音频链接的位置定位: 对于以上定位可通过如下方式获得(定位器): req = driver.find_element_by_id('m-search') a_i
-
python 无损批量压缩图片(支持保留图片信息)的示例
由于云盘空间有限,照片尺寸也是很大,所以写个Python程序压缩一下照片,腾出一些云盘空间 1.批量压缩照片 新建 photo_compress.py 代码如下 # -*- coding: utf-8 -*- """脚本功能说明:使用 tinypng api,一键批量压缩指定文件(夹)所有文件""" import os import sys from concurrent.futures import ThreadPoolExecutor, Pr
-
用Python制作音乐海报
前言 前段时间在一个朋友那么得到的灵感,想到可以用音乐播放页面作为一张海报图片.其实接下来要讲的和海报还是有差距的,而具体实现也只是简单的图片粘贴,但是在效果上还是不错的.效果图如下,希望大家喜欢: 左边是原图,右边是需要添加到中间的图,也是图的主角.其实如果直接用ps实现上面的图是非常简单的,反倒是用代码实现有点曲折,不过实现过程还是非常有趣的,希望这篇博客可以可以让你学到知识. 用Pillow创建圆形图 在上面的图片中,中间是一个圆形图片,而Pillow本身是没有提供生成圆形图片的方法(也可