为什么说Python可以实现所有的算法
今天推荐一个Python学习的干货。
几个印度小哥,在GitHub上建了一个各种Python算法的新手入门大全,现在标星已经超过2.6万。
这个项目主要包括两部分内容:一是各种算法的基本原理讲解,二是各种算法的代码实现。
传送门在此:
https://github.com/TheAlgorithms/Python
简单介绍下。
算法的基本原理讲解部分,包括排序算法、搜索算法、插值算法、跳跃搜索算法、快速选择算法、禁忌搜索算法、加密算法等。
这部分内容,主要介绍各种不同算法的原理,其中不少介绍还给出了动态示意图,以更初学者能够更直观的理解。搬运几个示例:
鸡尾酒排序算法

鸡尾酒(Cocktail shaker)排序,也叫双向冒泡排序(Bidirectional Bubble Sort)等。这是冒泡排序的一种变体。不同之处在于,冒泡排序是从低到高比较序列里的每个元素,而鸡尾酒排序从两个方向(低到高、高到低)来回排序,效率更高。
快速选择算法
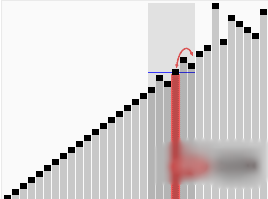
快速选择(Quick Select)算法,用于查找无序列表中的第k个最小元素。这种算法及其变体,是实践中最常用的高效选择算法。
快速选择算法与快速排序算法类似,选择一个元素作为基准来对元素进行分区,将小于和大于基准的元素分在基准左边和右边的两个区域。不同的是,快速选择并不递归访问双边,而是只递归进入一边的元素中继续寻找。
ROT13加密算法
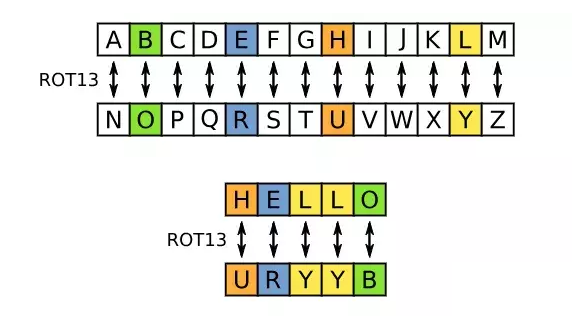
Rot13(rotate by 13 places)是一种非常简单的替换加密算法,用于加密26个英语字母。方法是:把每个字母用其后第13个字母代替。
当然这种算法破解起来也很简单,只需要反向替换就行,所以这种算法几乎提供不了什么加密安全性,并且经常作为弱加密的典型案例。
此外,这个项目还给出了多种Python算法的代码实现。
包括二叉树(Binary Tree)、动态规划(Dynamic Programming)、散列(Hashes)、线性代数、机器学习、神经网络等。

比方在机器学习这个类别里,给出了随机森林分类、随机森林回归、朴素贝叶斯、决策树、k值聚类、线性回归、逻辑回归、感知机等。
这里截个梯度下降代码实现的图,做个示意:

希望这个项目对你学习有帮助,再给一次传送门:
https://github.com/TheAlgorithms/Python
还有一事。
这几个印度小哥,不仅仅搞了一个学Python的项目,类似的资源收集项目还包括:Java、C、C++、Scala、C#等……

以上就是一个Python就可以实现所有的算法的详细内容,更多请关注我们其它相关文章!
相关推荐
-
python Dijkstra算法实现最短路径问题的方法
本文借鉴于张广河教授主编的<数据结构>,对其中的代码进行了完善. 从某源点到其余各顶点的最短路径 Dijkstra算法可用于求解图中某源点到其余各顶点的最短路径.假设G={V,{E}}是含有n个顶点的有向图,以该图中顶点v为源点,使用Dijkstra算法求顶点v到图中其余各顶点的最短路径的基本思想如下: 使用集合S记录已求得最短路径的终点,初始时S={v}. 选择一条长度最小的最短路径,该路径的终点w属于V-S,将w并入S,并将该最短路径的长度记为Dw. 对于V-S中任一顶点是s,将源点到顶点
-
python实现H2O中的随机森林算法介绍及其项目实战
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator H2ORandomForestEstimator 的常用方法和参数介绍: (一)建模方法: model =H2ORandomForestEstimator(ntrees=n,max_depth =m) model.train(x=random_pv.names,y='Catrgory',train
-
决策树剪枝算法的python实现方法详解
本文实例讲述了决策树剪枝算法的python实现方法.分享给大家供大家参考,具体如下: 决策树是一种依托决策而建立起来的一种树.在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某个可能的属性值,而每一个叶子节点则对应从根节点到该叶子节点所经历的路径所表示的对象的值.决策树仅有单一输出,如果有多个输出,可以分别建立独立的决策树以处理不同的输出. ID3算法:ID3算法是决策树的一种,是基于奥卡姆剃刀原理的,即用尽量用
-
Python 经典算法100及解析(小结)
1:找出字符串s="aaabbbccceeefff111144444"中,字符出现次数最多的字符 (1)考虑去重,首先将字符串进行过滤去重,这样在根据这些字符进行循环查询时,将会减少循环次数,提升效率.但是本人写的代码较为臃肿,有更好的希望留言评论 str = 'a1fsfs111bbbcccccvvvvvnnnnboooooosssnb' class Countvalue(): def countvalue(self, str1): ''' 利用set自身的去重功能 :param s
-
Python 实现大整数乘法算法的示例代码
我们平时接触的长乘法,按位相乘,是一种时间复杂度为 O(n ^ 2) 的算法.今天,我们来介绍一种时间复杂度为 O (n ^ log 3) 的大整数乘法(log 表示以 2 为底的对数). 介绍原理 karatsuba 算法要求乘数与被乘数要满足以下几个条件,第一,乘数与被乘数的位数相同:第二,乘数与被乘数的位数应为 2 次幂,即为 2 ^ 2, 2 ^ 3, 2 ^ 4, 2 ^ n 等数值. 下面我们先来看几个简单的例子,并以此来了解 karatsuba 算法的使用方法. 两位数相乘 我
-

Python实现的数据结构与算法之双端队列详解
本文实例讲述了Python实现的数据结构与算法之双端队列.分享给大家供大家参考.具体分析如下: 一.概述 双端队列(deque,全名double-ended queue)是一种具有队列和栈性质的线性数据结构.双端队列也拥有两端:队首(front).队尾(rear),但与队列不同的是,插入操作在两端(队首和队尾)都可以进行,删除操作也一样. 二.ADT 双端队列ADT(抽象数据类型)一般提供以下接口: ① Deque() 创建双端队列 ② addFront(item) 向队首插入项 ③ addRe
-
Python实现曲线点抽稀算法的示例
本文介绍了Python实现曲线点抽稀算法的示例,分享给大家,具体如下: 目录 何为抽稀 道格拉斯-普克(Douglas-Peuker)算法 垂距限值法 最后 正文 何为抽稀 在处理矢量化数据时,记录中往往会有很多重复数据,对进一步数据处理带来诸多不便.多余的数据一方面浪费了较多的存储空间,另一方面造成所要表达的图形不光滑或不符合标准.因此要通过某种规则,在保证矢量曲线形状不变的情况下, 最大限度地减少数据点个数,这个过程称为抽稀. 通俗的讲就是对曲线进行采样简化,即在曲线上取有限个点,将其变为折
-
Python实现的最近最少使用算法
本文实例讲述了Python实现的最近最少使用算法.分享给大家供大家参考.具体如下: # lrucache.py -- a simple LRU (Least-Recently-Used) cache class # Copyright 2004 Evan Prodromou <evan@bad.dynu.ca> # Licensed under the Academic Free License 2.1 # Licensed for ftputil under the revised BSD
-
Python中实现的RC4算法
闲暇之时,用Python实现了一下RC4算法 编码 UTF-8 class 方式 #/usr/bin/python #coding=utf-8 import sys,os,hashlib,time,base64 class rc4: def __init__(self,public_key = None,ckey_lenth = 16): self.ckey_lenth = ckey_lenth self.public_key = public_key or 'none_public_key'
-
Python实现的数据结构与算法之队列详解
本文实例讲述了Python实现的数据结构与算法之队列.分享给大家供大家参考.具体分析如下: 一.概述 队列(Queue)是一种先进先出(FIFO)的线性数据结构,插入操作在队尾(rear)进行,删除操作在队首(front)进行. 二.ADT 队列ADT(抽象数据类型)一般提供以下接口: ① Queue() 创建队列 ② enqueue(item) 向队尾插入项 ③ dequeue() 返回队首的项,并从队列中删除该项 ④ empty() 判断队列是否为空 ⑤ size() 返回队列中项的个数 队
-
Python最长公共子串算法实例
本文实例讲述了Python最长公共子串算法.分享给大家供大家参考.具体如下: #!/usr/bin/env python # find an LCS (Longest Common Subsequence). # *public domain* def find_lcs_len(s1, s2): m = [ [ 0 for x in s2 ] for y in s1 ] for p1 in range(len(s1)): for p2 in range(len(s2)): if s1[p1] =
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
Python实现的数据结构与算法之基本搜索详解
本文实例讲述了Python实现的数据结构与算法之基本搜索.分享给大家供大家参考.具体分析如下: 一.顺序搜索 顺序搜索 是最简单直观的搜索方法:从列表开头到末尾,逐个比较待搜索项与列表中的项,直到找到目标项(搜索成功)或者 超出搜索范围 (搜索失败). 根据列表中的项是否按顺序排列,可以将列表分为 无序列表 和 有序列表.对于 无序列表,超出搜索范围 是指越过列表的末尾:对于 有序列表,超过搜索范围 是指进入列表中大于目标项的区域(发生在目标项小于列表末尾项时)或者指越过列表的末尾(发生在目标项
-
Python实现的数据结构与算法之快速排序详解
本文实例讲述了Python实现的数据结构与算法之快速排序.分享给大家供大家参考.具体分析如下: 一.概述 快速排序(quick sort)是一种分治排序算法.该算法首先 选取 一个划分元素(partition element,有时又称为pivot):接着重排列表将其 划分 为三个部分:left(小于划分元素pivot的部分).划分元素pivot.right(大于划分元素pivot的部分),此时,划分元素pivot已经在列表的最终位置上:然后分别对left和right两个部分进行 递归排序. 其中
-
Python实现的数据结构与算法之链表详解
本文实例讲述了Python实现的数据结构与算法之链表.分享给大家供大家参考.具体分析如下: 一.概述 链表(linked list)是一组数据项的集合,其中每个数据项都是一个节点的一部分,每个节点还包含指向下一个节点的链接. 根据结构的不同,链表可以分为单向链表.单向循环链表.双向链表.双向循环链表等.其中,单向链表和单向循环链表的结构如下图所示: 二.ADT 这里只考虑单向循环链表ADT,其他类型的链表ADT大同小异.单向循环链表ADT(抽象数据类型)一般提供以下接口: ① SinCycLin