利用ImageAI库只需几行python代码实现目标检测
什么是目标检测
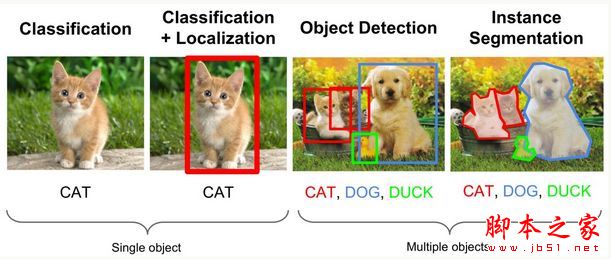
目标检测关注图像中特定的物体目标,需要同时解决解决定位(localization) + 识别(Recognition)。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
通俗的说,Object Detection的目的是在目标图中将目标用一个框框出来,并且识别出这个框中的是啥,而且最好的话是能够将图片的所有物体都框出来。
目标检测算法
目前目标检测领域的深度学习方法主要分为两类:两阶段(Two Stages)的目标检测算法;一阶段(One Stage)目标检测算法。
Two Stages
首先由算法(algorithm)生成一系列作为样本的候选框,再通过卷积神经网络进行样本(Sample)分类。也称为基于候选区域(Region Proposal)的算法。常见的算法有R-CNN、Fast R-CNN、Faster R-CNN等等。
One Stage
不需要产生候选框,直接将目标框定位的问题转化为回归(Regression)问题处理,也称为基于端到端(End-to-End)的算法。常见的算法有YOLO、SSD等等。
python实现
本文主要讲述如何实现目标检测,至于背后的原理不过多赘述,可以去看相关的论文。
ImageAI是一个简单易用的计算机视觉Python库,使得开发者可以轻松的将最新的最先进的人工智能功能整合进他们的应用。
ImageAI本着简洁的原则,支持最先进的机器学习算法,用于图像预测,自定义图像预测,物体检测,视频检测,视频对象跟踪和图像预测训练。
依赖
•Python 3.5.1(及更高版本)
•pip3
•Tensorflow 1.4.0(及更高版本)
•Numpy 1.13.1(及更高版本)
•SciPy 0.19.1(及更高版本)
•OpenCV
•pillow
•Matplotlib
•h5py
•Keras 2.x
安装
•命令行安装
pip3 install https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whl
•下载imageai-2.1.0-py3-none-any.whl 安装文件并在命令行中指定安装文件的路径
pip3 install .\imageai-2.1.0-py3-none-any.whl
使用
Image支持的深度学习的算法有RetinaNet,YOLOv3,TinyYoLOv3。ImageAI已经在COCO数据集上预先训练好了对应的三个模型,根据需要可以选择不同的模型。可以通过下面的链接进行下载使用:
•Download RetinaNet Model - resnet50_coco_best_v2.0.1.h5
•Download YOLOv3 Model - yolo.h5
•Download TinyYOLOv3 Model - yolo-tiny.h5
以上模型可以检测并识别以下80种不同的目标:
person, bicycle, car, motorcycle, airplane,
bus, train, truck, boat, traffic light, fire hydrant, stop_sign,
parking meter, bench, bird, cat, dog, horse, sheep, cow,
elephant, bear, zebra, giraffe, backpack, umbrella,
handbag, tie, suitcase, frisbee, skis, snowboard,
sports ball, kite, baseball bat, baseball glove, skateboard,
surfboard, tennis racket, bottle, wine glass, cup, fork, knife,
spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot,
hot dog, pizza, donot, cake, chair, couch, potted plant, bed,
dining table, toilet, tv, laptop, mouse, remote, keyboard,
cell phone, microwave, oven, toaster, sink, refrigerator,
book, clock, vase, scissors, teddy bear, hair dryer,
toothbrush
先来看看完整的代码,使用YOLOv3算法对13张照片进行目标识别。
from imageai.Detection import ObjectDetection
import os
detector = ObjectDetection()
detector.setModelTypeAsYOLOv3()
detector.setModelPath("./model/yolo.h5")
detector.loadModel()
path = os.getcwd()
input_image_list = os.listdir(path+"\pic\input")
input_image_list = sorted(input_image_list, key = lambda i:len(i),reverse = False)
size = len(input_image_list)
for i in range(size):
input_image_path = os.path.join(path+"\pic\input", input_image_list[i])
output_image_path = os.path.join(path+"\pic\output", input_image_list[i])
detections, extract_detected_objects = detector.detectObjectsFromImage(input_image=input_image_path,
output_image_path=output_image_path,
extract_detected_objects=True)
print('------------------- %d -------------------' % int(i + 1))
for eachObject in detections:
print(eachObject["name"], " : ", eachObject["percentage_probability"], " : ", eachObject["box_points"])
print('------------------- %d -------------------' % int(i + 1))
首先第一行导入ImageAI Object Detection类,在第二行导入os库。
然后创建了ObjectDetection类的新实例,接着就可以选择要使用的算法。分别有以下三个函数:
.setModelTypeAsRetinaNet()
.setModelTypeAsYOLOv3()
.setModelTypeAsTinyYOLOv3()
选择好算法之后就要设置模型文件路径,这里给出的路径必须要和选择的算法一样。
.setModelPath()
- 参数path(必须):模型文件的路径
载入模型。
.loadModel()
- 参数detection_speed(可选):最多可以减少80%的时间,单身会导致精确度的下降。可选的值有: “normal”, “fast”, “faster”, “fastest” 和 “flash”。默认值是 “normal”。
通过os库的函数得到输入输出文件的路径等,这不是本文重点,跳过不表。
开始对图像进行目标检测。
.detectObjectsFromImage()
- 参数input_image(必须):待检测图像的路径
- 参数output_image(必须):输出图像的路径
- 参数parameter minimum_percentage_probability(可选):能接受的最低预测概率。默认值是50%。
- 参数display_percentage_probability(可选):是否展示预测的概率。默认值是True。
- 参数display_object_name(可选):是否展示识别物品的名称。默认值是True。
- 参数extract_detected_objects(可选):是否将识别出的物品图片保存。默认是False。
返回值根据不同的参数也有不同,但都会返回一个an array of dictionaries。字典包括以下几个属性:
* name (string)
* percentage_probability (float)
* box_points (tuple of x1,y1,x2 and y2 coordinates)
前面说过可以识别80种目标,在这里也可以选择只识别自己想要的目标。
custom = detector.CustomObjects(person=True, dog=True) detections = detector.detectCustomObjectsFromImage( custom_objects=custom, input_image=os.path.join(execution_path , "image3.jpg"), output_image_path=os.path.join(execution_path , "image3new-custom.jpg"), minimum_percentage_probability=30)
首先用定义自己想要的目标,其余的目标会被设置为False。然后配合.detectCustomObjectsFromImage()进行目标检测。
主要的代码基本如上所述,接下来看结果。先看看图片中只有一个目标的效果。


------------------- 10 -------------------
dog : 98.83476495742798 : (117, 91, 311, 360)
dog : 99.24255609512329 : (503, 133, 638, 364)
dog : 99.274742603302 : (338, 38, 487, 379)
------------------- 10 -------------------
效果还是不错的。再看看如果图片中有多个目标识别的结果如何。


------------------- 4 ------------------- book : 55.76887130737305 : (455, 74, 487, 146) book : 82.22097754478455 : (466, 11, 482, 69) tv : 99.34800863265991 : (25, 40, 182, 161) bed : 88.7190580368042 : (60, 264, 500, 352) cat : 99.54025745391846 : (214, 125, 433, 332) ------------------- 4 -------------------
识别度还是很高的,背后人眼都看不清的书本都能被识别。
附录
GitHub:https://github.com/Professorchen/Computer-Vision/tree/master/object-detection
总结
以上所述是小编给大家介绍的利用ImageAI库只需几行python代码超简实现目标检测,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python+opencv+caffe+摄像头做目标检测的实例代码
首先之前已经成功的使用Python做图像的目标检测,这回因为项目最终是需要用摄像头的, 所以实现摄像头获取图像,并且用Python调用CAFFE接口来实现目标识别 首先是摄像头请选择支持Linux万能驱动兼容V4L2的摄像头, 因为之前用学ARM的时候使用的Smart210,我已经确认我的摄像头是支持的, 我把摄像头插上之後自然就在 /dev 目录下看到多了一个video0的文件, 这个就是摄像头的设备文件了,所以我就没有额外处理驱动的部分 一.检测环境 再来在开始前因为之前按着国嵌的指导手册安
-
10 行Python 代码实现 AI 目标检测技术【推荐】
只需10行Python代码,我们就能实现计算机视觉中目标检测. from imageai.Detection import ObjectDetection import os execution_path = os.getcwd() detector = ObjectDetection() detector.setModelTypeAsRetinaNet() detector.setModelPath( os.path.join(execution_path , "resnet50_coco_b
-

Python Opencv任意形状目标检测并绘制框图
opencv 进行任意形状目标识别,供大家参考,具体内容如下 工作中有一次需要在简单的图上进行目标识别,目标的形状不固定,并且存在一定程度上的噪声影响,但是噪声影响不确定.这是一个简单的事情,因为图像并不复杂,现在将代码公布如下: import cv2 def otsu_seg(img): ret_th, bin_img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) return ret_th, bin_img d
-
python开启摄像头以及深度学习实现目标检测方法
最近想做实时目标检测,需要用到python开启摄像头,我手上只有两个uvc免驱的摄像头,性能一般.利用python开启摄像头费了一番功夫,主要原因是我的摄像头都不能用cv2的VideCapture打开,这让我联想到原来opencv也打不开Android手机上的摄像头(后来采用QML的Camera模块实现的).看来opencv对于摄像头的兼容性仍然不是很完善. 我尝了几种办法:v4l2,v4l2_capture以及simpleCV,都打不开.最后采用pygame实现了摄像头的采集功能,这里直接给大
-
利用ImageAI库只需几行python代码实现目标检测
什么是目标检测 目标检测关注图像中特定的物体目标,需要同时解决解决定位(localization) + 识别(Recognition).相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示). 通俗的说,Object Detection的目的是在目标图中将目标用一个框框出来,并且识别出这个框中的是啥,而且最好的话是能够将图片的所
-
python opencv检测目标颜色的实例讲解
实例如下所示: # -*- coding:utf-8 -*- __author__ = 'kingking' __version__ = '1.0' __date__ = '14/07/2017' import cv2 import numpy as np import time if __name__ == '__main__': Img = cv2.imread('example.png')#读入一幅图像 kernel_2 = np.ones((2,2),np.uint8)#2x2的卷积核
-
Python+OpenCV目标跟踪实现基本的运动检测
目标跟踪是对摄像头视频中的移动目标进行定位的过程,有着非常广泛的应用.实时目标跟踪是许多计算机视觉应用的重要任务,如监控.基于感知的用户界面.增强现实.基于对象的视频压缩以及辅助驾驶等. 有很多实现视频目标跟踪的方法,当跟踪所有移动目标时,帧之间的差异会变的有用:当跟踪视频中移动的手时,基于皮肤颜色的均值漂移方法是最好的解决方案:当知道跟踪对象的一方面时,模板匹配是不错的技术. 本文代码是做一个基本的运动检测 考虑的是"背景帧"与其它帧之间的差异 这种方法检测结果还是挺不错的,但是需要
-
只需7行Python代码玩转微信自动聊天
本代码将用到wxpy模块,使用前请确保已成功安装.我喜欢命令行安装: 接着就可以开始码啦: 开头的红色部分为注释,去掉仍然可以运行,有效代码仅七行,是不是很简洁?赶紧呼朋唤友试一试吧-- 比人还会聊天的图灵机器人-- 群聊也十分积极-- 但可怕的是,它竟然和公众号们聊了一百多条消息-- 如果,恰巧,这时候领导也给你发了一条消息-- 显然,Python应该做到指定聊天对象: 指定聊天的群: 甚至指定群里的BOSS: 再也不用担心错失老板的重要信息了-- 嗯,这个操作是不是和"已读"一样遭
-
只需要100行Python代码就可以实现的贪吃蛇小游戏
图示 基本准备 首先,我们需要安装pygame库,小编通过pip install pygame,很快就安装好了.在完成贪吃蛇小游戏的时候,我们需要知道整个游戏分为四部分: 1.游戏显示:游戏界面.结束界面 2.贪吃蛇:头部.身体.食物判断.死亡判断 3.树莓:随机生成 4.按键控制:上.下.左.右 游戏显示 首先,我们来初始化pygame,定义颜色.游戏界面的窗口大小.标题和图标等. 游戏结束界面,我们会显示"Game Over!"和该局游戏所得分数,相关代码如下: 贪吃蛇和树莓 我们
-
50行Python代码实现人脸检测功能
现在的人脸识别技术已经得到了非常广泛的应用,支付领域.身份验证.美颜相机里都有它的应用.用iPhone的同学们应该对下面的功能比较熟悉 iPhone的照片中有一个"人物"的功能,能够将照片里的人脸识别出来并分类,背后的原理也是人脸识别技术. 这篇文章主要介绍怎样用Python实现人脸检测.人脸检测是人脸识别的基础.人脸检测的目的是识别出照片里的人脸并定位面部特征点,人脸识别是在人脸检测的基础上进一步告诉你这个人是谁. 好了,介绍就到这里.接下来,开始准备我们的环境. 准备工作 本文的人
-
5行Python代码实现图像分割的步骤详解
众所周知图像是由若干有意义的像素组成的,图像分割作为计算机视觉的基础,对具有现有目标和较精确边界的图像进行分割,实现在图像像素级别上的分类任务. 图像分割可分为语义分割和实例分割两类,区别如下: 语义分割:将图像中每个像素赋予一个类别标签,用不同的颜色来表示: 实例分割:无需对每个像素进行标记,只需要找到感兴趣物体的边缘轮廓. 图像分割通常应用如下所示: 专业检测:应用于专业场景的图像分析,比如在卫星图像中识别建筑.道路.森林,或在医学图像中定位病灶.测量面积等: 智能交通:识别道路信息,包括车
-
10行Python代码就能实现的八种有趣功能详解
目录 一.生成二维码 二.生成词云 三.批量抠图 四.文字情绪识别 五.识别是否带了口罩 六.简易信息轰炸 七.识别图片中的文字 八.简单的小游戏 Python凭借其简洁的代码,赢得了许多开发者的喜爱.因此也就促使了更多开发者用Python开发新的模块,从而形成良性循环,Python可以凭借更加简短的代码实现许多有趣的操作.下面我们来看看,我们用不超过10行代码能实现些什么有趣的功能. 一.生成二维码 二维码又称二维条码,常见的二维码为QR Code,QR全称Quick Response,是一个
-
python只需30行代码就能记录键盘的一举一动
目录 先看看效果 一.公共WiFi 公用电脑什么的 二.键盘记录器 三.python代码实现 1.安装pynput模块 2.脚本完整代码 3.启动脚本 4.登录126邮箱 抓取用户信息 四.安全提示 先看看效果 Like This↓ 一.公共WiFi 公用电脑什么的 在我们日常在线上工作.玩耍时,不论开电脑.登录淘宝.玩网游 统统都会用到键盘输入 在几乎所有网站,例如淘宝.百度.126邮箱等等 为了保护用户信息 登录时,输入框都是不可见的. 但是,输入框都在界面上隐藏,让我们看不到,就能真正的确
-
利用4行Python代码监测每一行程序的运行时间和空间消耗
Python是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言,其具有高可扩展性和高可移植性,具有广泛的标准库,受到开发者的追捧,广泛应用于开发运维(DevOps).数据科学.网站开发和安全.然而,它没有因速度和空间而赢得任何称赞,主要原因是Python是一门动态类型语言,每一个简单的操作都需要大量的指令才能完成. 所以这更加需要开发者在使用Python语言开发项目时协调好程序运行的时间和空间. 1.分析时间耗时 分析项目消耗的时间消耗,依托于line_profiler模块,其可以计
-
利用20行Python 代码实现加密通信
目录 一.引言 二.加密技术 三.普通锁:简单的对称加密 四.不可篡改的指纹:哈希函数 五.矛与盾:非对称加密 六.真言:数字签名 七.总结 一.引言 网络上充满了窃听,我们的信息很容易被不怀好意的人获得,给我们造成不好的影响.如果你需要在网络上传输机密或者敏感的隐私信息,为了防备别有用心的人窃听,可能需要加密.而使用在线或者手机上的加密软件,可能不良软件更是泄露信息的温床.所以作为程序员的我们,完全可以自己来实现一个加密系统. 本文用 20 行 Python 代码来演示加密.解密.签名.验证的