Python3爬虫教程之利用Python实现发送天气预报邮件
前言
此次的目标是爬取指定城市的天气预报信息,然后再用Python发送邮件到指定的邮箱。
下面话不多说了,来一起看看详细的实现过程吧
一、爬取天气预报
1、首先是爬取天气预报的信息,用的网站是中国天气网,网址是http://www.weather.com.cn/static/html/weather.shtml,任意选择一个城市(比如武汉),然后要爬取的内容为下面的部分:

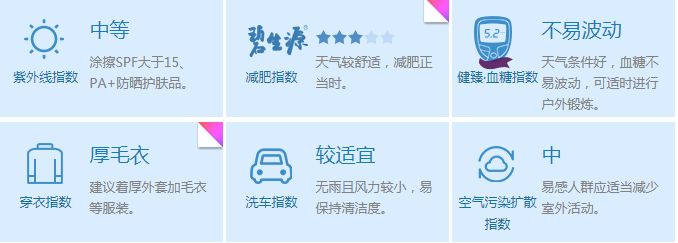
先查看网页源代码,并没有找到第一张图中的内容,说明是这些天气信息是通过别的方式加载出来的。我们打开开发者工具,点击XHR选项,发现没有任何内容,但是点击JS选项后可以找到如下内容:

然后就是把URL复制下来进行爬取,不过要注意加上User-Agent和Referer字段,而且如果一直用一个User-Agent的话就会被识别出来,所以我们需要定义一个函数来返回随机的User-Agent以供使用。
def get_agent(): import random user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] return random.choice(user_agent_list)
爬取后的结果如下:
{'PM2.5': '158',
'城市': '武汉',
'天气': '多云',
'日期': '12月16日(星期日)',
'洗车指数': '无雨且风力较小,易保持清洁度。',
'温度': '12℃',
'相对湿度': '47%',
'穿衣指数': '建议着厚外套加毛衣等服装。',
'紫外线指数': '涂擦SPF大于15、PA+防晒护肤品。',
'风力等级': '2级',
'风向': '西南风'}
2、我们已经能爬取天气预报的内容了,但是如果我们想要爬取任意城市的天气预报,又要怎么办呢?
先找几个城市对应的链接看一下:武汉(http://www.weather.com.cn/weather1d/101200101.shtml)、广州(http://www.weather.com.cn/weather/101280101.shtml?)、杭州(http://www.weather.com.cn/weather1d/101210101.shtml),很明显每个城市有一个对应的编码,而我们只要获得全国主要城市的编码信息,也就能得到这些城市的天气预报了。
这一步花费了我不少时间,问题就在于从哪里得到这些编码信息,最后找到了一个办法。首先是查看国内天气预报,当我们的鼠标移到某个省的地图上的时候,就会显示其省会的天气情况:
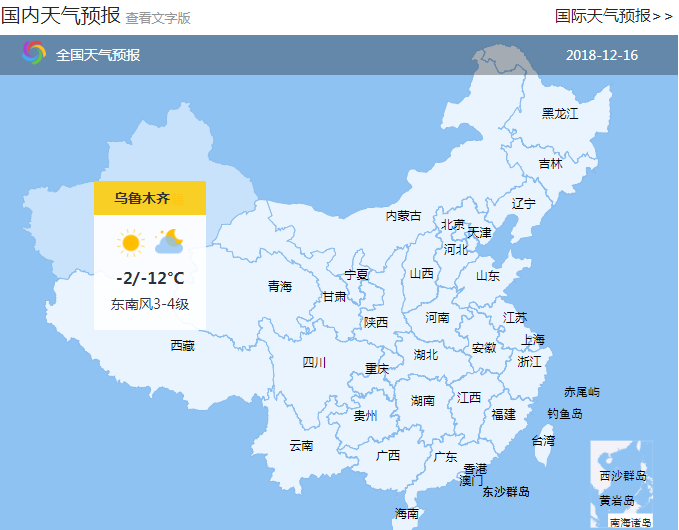
而当我们用鼠标左键点击的时候,就能够查看这个省的整体天气情况:
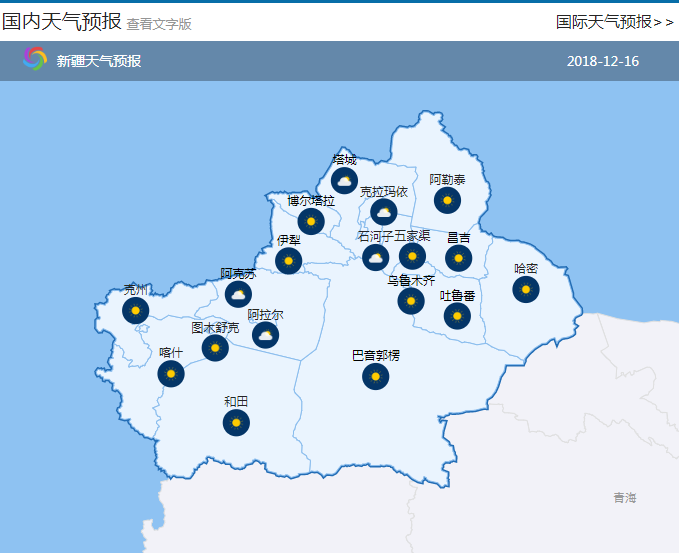
打开开发者工具,点击XHR选项,可以发现有如下内容,而这些数据里就包含着我们需要的编码信息:

做到这一步我们就可以获得全国主要城市的编码信息了,不过要注意的是,这些编码并不都是能直接添加到我们的代码中进行使用的,通过观察可以发现,四个直辖市的编码是不需要做改变的,其余的省需要在得到的编码后面加上一个01。
二、发送邮件
要使用Python来发送邮件,需要使用两个模块:smtplib和email。这两个模块是Python自带的,只需import即可使用,其中smtplib模块主要负责发送邮件,email模块主要负责构造邮件。
我使用的是163邮箱,用别的邮箱也可以,不过方法会有所不同。在发送邮件之前,需要先设置授权码,在设置完之后,要记住你的授权码,在后面会用到的:
一个测试的例子如下:
import smtplib
from email.header import Header
from email.mime.text import MIMEText
sender = "xxx@163.com" # 发件人的邮箱
password = "xxx" # 这里的密码不是登陆邮箱的密码,而是授权码
receiver = "xxx@163.com" # 收件人的邮箱,可以是同一个
mail = MIMEText("这是邮件内容", 'plain', 'utf-8') # 邮件内容
mail['Subject'] = Header('这是邮件主题', 'utf-8') # 邮件主题
mail['From'] = sender # 发件人
mail['To'] = receiver # 收件人
smtp = smtplib.SMTP()
smtp.connect('smtp.163.com', 25) # 连接邮箱服务器
smtp.login(sender, password) # 登录邮箱
smtp.sendmail(sender, receiver, mail.as_string()) # 第三个是把邮件内容变成字符串
smtp.quit() # 发送完毕,退出
print('邮件已成功发送!')
有几点要注意的是:
(1)mail['From']和mail['To']是一定要加上的,不能省略;
(2)由于使用的是163邮箱,所以连接服务器的时候使用的是smtp.163.com;
(3)邮件主题里不要使用“test”,不然会被标记为垃圾邮件。
三、运行结果
首先是程序运行的结果截图:

然后打开邮箱查看:

完整代码已上传到GitHub:https://github.com/QAQ112233/Weather(本地下载)
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
相关推荐
-
Python3爬虫之urllib携带cookie爬取网页的方法
如下所示: import urllib.request import urllib.parse url = 'https://weibo.cn/5273088553/info' #正常的方式进行访问 # headers = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36' # } # 携带
-
Python3爬虫使用Fidder实现APP爬取示例
之前爬取都是网页上的数据,今天要来说一下怎么借助Fidder来爬取手机APP上的数据. 一.环境配置 1.Fidder的安装和配置 没有安装Fidder软件的可以进入 这个网址 下载,然后就是傻瓜式的安装,安装步骤很简单.在安装完成后,打开软件,进行如下设置: 这里使用默认的8888端口就好了,如果要修改的话,要避免和其他端口冲突. 2.手机的配置 首先打开cmd,输入ipconfig查看IP地址,记录下这个IP地址: 想要使用FIdder进行手机抓包,要让手机和PC处在同一个内网中,方法就是连
-
python爬虫获取新浪新闻教学
一提到python,大家经常会提到爬虫,爬虫近来兴起的原因我觉得主要还是因为大数据的原因,大数据导致了我们的数据不在只存在于自己的服务器,而python语言的简便也成了爬虫工具的首要语言,我们这篇文章来讲下爬虫,爬取新浪新闻 1. 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 大家知道,爬虫实际上就是模拟浏览器请求,然后把请求到的数据,经过我们的分析,提取出我们想要的内容,这也就是爬虫的实现 2.首先,我们要写爬虫,可以借鉴
-

Nginx利用Lua+Redis实现动态封禁IP的方法
一.背景 我们在日常维护网站中,经常会遇到这样一个需求,为了封禁某些爬虫或者恶意用户对服务器的请求,我们需要建立一个动态的 IP 黑名单.对于黑名单之内的 IP ,拒绝提供服务. 本文给大家介绍的是Nginx利用Lua+Redis实现动态封禁IP的方法,下面话不多说了,来一起看看详细的介绍吧 二.架构 实现 IP 黑名单的功能有很多途径: 1.在操作系统层面,配置 iptables,拒绝指定 IP 的网络请求: 2.在 Web Server 层面,通过 Nginx 自身的 deny 选项 或者
-
Python数据抓取爬虫代理防封IP方法
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息,一般来说,Python爬虫程序很多时候都要使用(飞猪IP)代理的IP地址来爬取程序,但是默认的urlopen是无法使用代理的IP的,我就来分享一下Python爬虫怎样使用代理IP的经验.(推荐飞猪代理IP注册可免费使用,浏览器搜索可找到) 1.划重点,小编我用的是Python3哦,所以要导入urllib的request,然后我们调用ProxyHandler,它可以接收代理IP的参数.代理可以根据自己需要选择,当然免费的也是有
-
Python3爬虫学习入门教程
本文实例讲述了Python3爬虫相关入门知识.分享给大家供大家参考,具体如下: 在网上看到大多数爬虫教程都是Python2的,但Python3才是未来的趋势,许多初学者看了Python2的教程学Python3的话很难适应过来,毕竟Python2.x和Python3.x还是有很多区别的,一个系统的学习方法和路线非常重要,因此我在联系了一段时间之后,想写一下自己的学习过程,分享一下自己的学习经验,顺便也锻炼一下自己. 一.入门篇 这里是Python3的官方技术文档,在这里需要着重说一下,语言的技术文
-
Python3爬虫学习之应对网站反爬虫机制的方法分析
本文实例讲述了Python3爬虫学习之应对网站反爬虫机制的方法.分享给大家供大家参考,具体如下: 如何应对网站的反爬虫机制 在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别该访问是否为爬虫,用来作为反爬取的一种策略. 例如打开搜狐首页,先来看一下Chrome的头信息(F12打开开发者模式)如下: 如图,访问头信息中显示了浏览器以及系统的信息(headers所含信息众多,具体可自行查询) Python中urllib中的request模块提供了模拟浏览器访问的功能,代码如下: from
-
详解Linux防火墙iptables禁IP与解封IP常用命令
在Linux服务器被攻击的时候,有的时候会有几个主力IP.如果能拒绝掉这几个IP的攻击的话,会大大减轻服务器的压力,说不定服务器就能恢复正常了. 在Linux下封停IP,有封杀网段和封杀单个IP两种形式.一般来说,现在的攻击者不会使用一个网段的IP来攻击(太招摇了),IP一般都是散列的.于是下面就详细说明一下封杀单个IP的命令,和解封单个IP的命令. Linux防火墙:iptables禁IP与解封IP常用命令 在Linux下,使用ipteables来维护IP规则表.要封停或者是解封IP,其实就是
-
Python3爬虫全国地址信息
PHP方式写的一团糟所以就用python3重写了一遍,所以因为第二次写了,思路也更清晰了些. 提醒:可能会有502的错误,所以做了异常以及数据库事务处理,暂时没有想到更好的优化方法,所以就先这样吧.待更懂python再进一步优化哈 欢迎留言赐教~ #!C:\Users\12550\AppData\Local\Programs\Python\Python37\python.exe # -*- coding: utf-8 -*- from urllib.request import urlopen
-
python爬虫获取小区经纬度以及结构化地址
本文实例为大家分享了python爬虫获取小区经纬度.地址的具体代码,供大家参考,具体内容如下 通过小区名称利用百度api可以获取小区的地址以及经纬度,但是由于api返回的值中的地址形式不同,所以可以首先利用小区名称进行一轮爬虫,获取小区的经纬度,然后再利用经纬度Reverse到小区的结构化的地址.另外小区名称如果是'...号',可以在爬虫开始之前在'号'之后加一个'院',得到的精确度更高.这次写到程序更加便于二次利用,只需要给程序传递一个dataframe就可以坐等结果了.现在程序已经写好了,就
-
Python反爬虫技术之防止IP地址被封杀的讲解
在使用爬虫爬取别的网站的数据的时候,如果爬取频次过快,或者因为一些别的原因,被对方网站识别出爬虫后,自己的IP地址就面临着被封杀的风险.一旦IP被封杀,那么爬虫就再也爬取不到数据了. 那么常见的更改爬虫IP的方法有哪些呢? 1,使用动态IP拨号器服务器. 动态IP拨号服务器的IP地址是可以动态修改的.其实动态IP拨号服务器并不是什么高大上的服务器,相反,属于配置很低的一种服务器.我们之所以使用动态IP拨号服务器,不是看中了它的计算能力,而是能够实现秒换IP. 动态IP拨号服务器有一个特点,就是每