关于关系数据库如何快速查询表的记录数详解
前言
在数据库中,很多人员习惯使用SELECT COUNT(*) 、SELECT COUNT(1) 、SELECT COUNT(COL)来查询一个表有多少记录,对于小表,这种SQL的开销倒不是很大,但是对于大表,这种查询表记录数的做法就是一个非常消耗资源了,而且效率很差。下面介绍一下SQL Server、 Oracle、MySQL中如何快速获取表的记录数。
SQL SERVER 数据库
在SQL Server数据库中, 对象目录视图sys.partitions中有一个字段rows会记录表的记录数。我们以AdventureWorks2014为测试数据库。

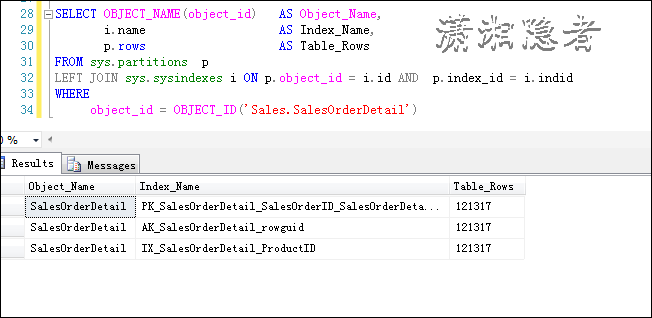
SELECT OBJECT_NAME(object_id) AS Object_Name,
i.name AS Index_Name,
p.rows AS Table_Rows
FROM sys.partitions p
LEFT JOIN sys.sysindexes i ON p.object_id = i.id AND p.index_id = i.indid
WHERE
object_id = OBJECT_ID('TableName')
那么我们还有一些疑问,我们先来看看这些问题吧!
1:没有索引的表是否也可以使用上面脚本?
2:只有非聚集索引的堆表是否可以使用上面脚本?
3:有多个索引的表,是否记录数会存在不一致的情况?
4:统计信息不准确的表,是否rows也会不准确
5: 分区表的情况又是怎么样?
6:对象目录视图sys.partitions与sp_spaceused获取的表记录函数是否准确。
如下所示,我们先构造测试案例:
IF EXISTS(SELECT 1 FROM sys.objects WHERE type='U' AND name='TEST_TAB_ROW') BEGIN DROP TABLE TEST_TAB_ROW; END IF NOT EXISTS(SELECT 1 FROM sys.objects WHERE type='U' AND name='TEST_TAB_ROW') BEGIN CREATE TABLE TEST_TAB_ROW ( ID INT, NAME CHAR(200) ) END GO SET NOCOUNT ON; BEGIN TRAN DECLARE @Index INT =1; WHILE @Index <= 100000 BEGIN INSERT INTO TEST_TAB_ROW VALUES(@Index, NEWID()); SET @Index+=1; IF (@Index % 5000) = 0 BEGIN IF @@TRANCOUNT > 0 BEGIN COMMIT; BEGIN TRAN END END END IF @@TRANCOUNT > 0 BEGIN COMMIT; END GO
关于问题1、问题2,都可以使用上面脚本, 如下测试所示:
SELECT OBJECT_NAME(object_id) AS Object_Name,
i.name AS Index_Name,
p.rows AS Table_Rows
FROM sys.partitions p
LEFT JOIN sys.sysindexes i ON p.object_id = i.id AND p.index_id = i.indid
WHERE
object_id = OBJECT_ID('dbo.TEST_TAB_ROW')

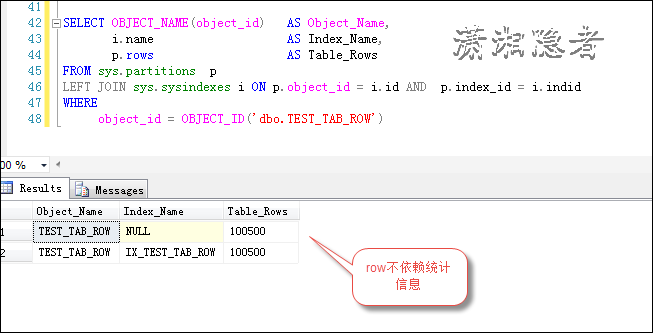
在表dbo.TEST_TAB_ROW 上创建非聚集索引后,查询结果如下所示:
CREATE INDEX IX_TEST_TAB_ROW ON TEST_TAB_ROW(ID);

我们插入500条记录,此时,这个数据量不足以触发统计信息更新,如下所示, Rows Sampled还是1000000
DECLARE @Index INT =1; WHILE @Index <= 500 BEGIN INSERT INTO TEST_TAB_ROW VALUES(100000 +@Index, NEWID()); SET @Index+=1; END

如下所示,发现sys.partitions中的记录变成了100500了,可见rows这个值的计算不依赖统计信息。
当然,如果你用sp_spaceused,发现这里面的记录也是100500
sp_spaceused 'dbo.TEST_TAB_ROW'

关于问题3:有多个索引的表,是否记录数会存在不一致的情况?
答案:个人测试以及统计来看,暂时发现多个索引的情况下,sys.partitions中的rows记录数都是一致的。暂时没有发现不一致的情况,当然也不排除有特殊情况。
关于问题5: 分区表的情况又是怎么样?
答案:分区表和普通表没有任何区别。
关于问题6:对象目录视图sys.partitions与sp_spaceused获取的表记录函数是否准确?
答案:对象目录视图sys.partitions与sp_spaceused获取的表记录数是准确的。
ORACLE 数据库
在ORACLE数据库中,可以通过DBA_TABLES、ALL_TABLES、USER_TABLES视图查看表的记录数,不过这个值(NUM_ROWS)跟统计信息有很大的关系,有时候统计信息没有更新或采样比例会导致这个值不是很准确。
SELECT OWNER , TABLE_NAME, NUM_ROWS , LAST_ANALYZED FROM DBA_TABLES WHERE OWNER = '&OWNER' AND TABLE_NAME = '&TABLE_NAME'; SELECT OWNER, TABLE_NAME, NUM_ROWS , LAST_ANALYZED FROM ALL_TABLES WHERE OWNER ='&OWNER' AND TABLE_NAME='&TABLE_NAME'; SELECT TABLE_NAME, NUM_ROWS , LAST_ANALYZED FROM USER_TABLES WHERE TABLE_NAME='&TABLE_NAME'
更新统计信息后,就能得到准确的行数。所以如果需要得到正确的数据,最好更新目标表的统计信息,进行100%采样分析。对于分区表,那么就需要从dba_tab_partitions里面查询相关数据了。
SQL>execute dbms_stats.gather_table_stats(ownname => 'username', tabname =>'tablename', estimate_percent =>100, cascade=>true);
MySQL数据库
在MySQL中比较特殊,虽然INFORMATION_SCHEMA.TABLES也可以查到表的记录数,但是非常不准确。如下所示,即使使用ANALYZE TABLE更新了统计信息,从INFORMATION_SCHEMA.TABLES中获取的记录依然不准确
SELECT TABLE_ROWS FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME='table_name'
mysql> SELECT TABLE_ROWS -> FROM INFORMATION_SCHEMA.TABLES -> WHERE TABLE_NAME='jiraissue' -> ; +------------+ | TABLE_ROWS | +------------+ | 36487 | +------------+ 1 row in set (0.01 sec) mysql> select count(*) from jiraissue; +----------+ | count(*) | +----------+ | 36973 | +----------+ 1 row in set (0.05 sec) mysql> analyze table jiraissue; +----------------+---------+----------+----------+ | Table | Op | Msg_type | Msg_text | +----------------+---------+----------+----------+ | jira.jiraissue | analyze | status | OK | +----------------+---------+----------+----------+ 1 row in set (1.41 sec) mysql> SELECT TABLE_ROWS -> FROM INFORMATION_SCHEMA.TABLES -> WHERE TABLE_NAME='jiraissue'; +------------+ | TABLE_ROWS | +------------+ | 34193 | +------------+ 1 row in set (0.00 sec) mysql>

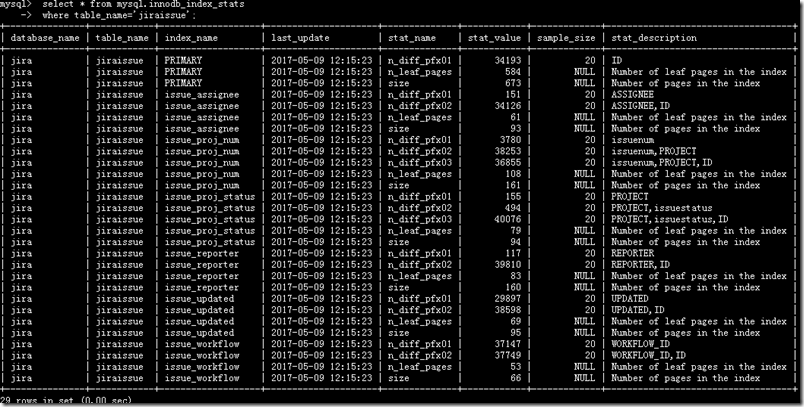
如上所示,MySQL这种查询表记录数的方法看来还是有缺陷的。当然如果不是要求非常精确的值,这个方法也是不错的。
当然,上面介绍的SQL Server、Oracle、MySQL数据库中的方法,还是有一些局限性的。例如,只能查询整张表的记录数,对于那些查询记录数带有查询条件(WHERE)这类SQL。还是必须使用SELECT COUNT(*)这种方法。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对我们的支持。
相关推荐
-
sql 查询记录数结果集某个区间内记录
以查询前20到30条为例,主键名为id 方法一: 先正查,再反查 select top 10 * from (select top 30 * from tablename order by id asc) A order by id desc 方法二: 使用left join select top 10 A.* from tablename A left outer join (select top 20 * from tablename order by id asc) B on A.id =
-
SQL Server数据库按百分比查询出表中的记录数
SQL Server数据库查询时,能否按百分比查询出记录的条数呢?答案是肯定的.本文我们就介绍这一实现方法. 实现该功能的代码如下: create procedure pro_topPercent ( @ipercent [int] =0 --默认不返回 ) as begin select top (@ipercent ) percent * from books end 或 create procedure pro_topPercent ( @ipercent [int] =0 ) as be
-
mysql实现查询最接近的记录数据示例
本文实例讲述了mysql实现查询最接近的记录数据.分享给大家供大家参考,具体如下: 查询场景:现在的需求是查询年龄最接近20岁的用户,获取前5个 我现在的数据库记录用户年龄的字段记录格式是"1995-05-20",字段名称birthday 解决思路: 1.首先查询时转换成用户年龄 日期格式转年龄的方法: (1)当前年份 - 日期格式中的年份 date_format(now(), '%Y') - from_unixtime(unix_timestamp(birthday), '%Y')
-
关于关系数据库如何快速查询表的记录数详解
前言 在数据库中,很多人员习惯使用SELECT COUNT(*) .SELECT COUNT(1) .SELECT COUNT(COL)来查询一个表有多少记录,对于小表,这种SQL的开销倒不是很大,但是对于大表,这种查询表记录数的做法就是一个非常消耗资源了,而且效率很差.下面介绍一下SQL Server. Oracle.MySQL中如何快速获取表的记录数. SQL SERVER 数据库 在SQL Server数据库中, 对象目录视图sys.partitions中有一个字段rows会记录表的记录数
-
Oracle 如何规范清理v$archived_log记录实例详解
Oracle 如何规范清理v$archived_log记录实例详解 单机实例上面,v$archived_log 很多,有上万条记录了,所以得清理一下,不然每次查询都直接滚屏幕了 SQL> select sequence#,applied from v$archived_log order by sequence# ; SEQUENCE# APPLIED .................... SEQUENCE# APPLIED ---------- --------- 9376 NO 9377
-
Java语言实现快速幂取模算法详解
快速幂取模算法的引入是从大数的小数取模的朴素算法的局限性所提出的,在朴素的方法中我们计算一个数比如5^1003%31是非常消耗我们的计算资源的,在整个计算过程中最麻烦的就是我们的5^1003这个过程 缺点1:在我们在之后计算指数的过程中,计算的数字不都拿得增大,非常的占用我们的计算资源(主要是时间,还有空间) 缺点2:我们计算的中间过程数字大的恐怖,我们现有的计算机是没有办法记录这么长的数据的,所以说我们必须要想一个更加高效的方法来解决这个问题 当我们计算AB%C的时候,最便捷的方法就是调用Ma
-
Golang实现快速求幂的方法详解
今天讲个有趣的算法:如何快速求nm,其中n和m都是整数. 为方便起见,此处假设m>=0,对于m< 0的情况,求出n|m|后再取倒数即可. 另外此处暂不考虑结果越界的情况(超过 int64 范围). 当然不能用编程语言的内置函数,我们只能用加减乘除来实现. n的m次方的数学含义是:m个n相乘:n*n*n...*n,也就是说最简单的方式是执行 m 次乘法. 直接用乘法实现的问题是性能不高,其时间复杂度是 O(m),比如 329要执行29次乘法,而乘法运算是相对比较重的,我们看看能否采用什么方法将时
-
Go语言框架快速集成限流中间件详解
目录 前言 分布式版 简介 算法 实现 注意 单机版 简介 算法 实现 结语 前言 在我们的日常开发中, 常用的中间件有很多, 今天来讲一下怎么集成限流中间件, 它可以很好地用限制并发访问数来保护系统服务, 避免系统服务崩溃, 资源占用过大甚至服务器崩溃进而影响到其他应用! 分布式版 简介 通常我们的服务会同时存在多个进程, 也就是负载来保证服务的性能和稳定性, 那么就需要走一个统一的限流, 这个时候就需要借助我们的老朋友-redis, 来进行分布式限流; 算法 漏桶算法 即一个水桶, 进水(接
-
Nest.js快速启动API项目过程详解
目录 快速启动 使用nest自带的命令行工具 直接使用starter项目 用npm安装所需的包 创建controller 创建service 结构和命名 HTTP请求 处理Axios对象 配置 全局添加headers API文档 快速启动 最近上了一个新项目,这个客户管理一个庞大的任务和团队集群,而不同流程所适用的系统也不太一样,比如salesforce,hubspots之类的.这次的新项目需要在另外两个平台之间做一些事情.目前只需要先封装其中之一的API,因此我们选定使用NodeJS的框架Ne
-
VC List Control控件如何删除选中的记录实例详解
VC List Control控件如何删除选中的记录实例详解 实例代码: OnButtonDelete() { POSITION pos = m_list.GetFirstSelectedItemPosition(); int idx = m_list.GetNextSelectedItem(pos); while (idx != -1){ LVITEM lvi; lvi.iItem = idx; lvi.iSubItem = 0; lvi.mask = LVIF_IMAGE; if (m_li
-
Laravel5.5+ 使用API Resources快速输出自定义JSON方法详解
从Laravel 5.5+开始,加入了API Resources这个概念. 我们先来看一下官网如何定义这个概念的: When building an API, you may need a transformation layer that sits between your Eloquent models and the JSON responses that are actually returned to your application's users. Laravel's resour
-

Git远程删除某个历史提交记录方法详解
目录 引言 一.删除最后一次提交 二.删除指定commit提交(非最后一次提交) 引言 在开发中经常会遇到在本地测试的代码或者隐私信息,一不小心提交到了远程仓库,即便立即删除了再提交,但是上次的提交记录在远程依旧可以查看. 特别是像账号密码.key文件这种,很可能造成隐私泄露. 分两种情况: 一.删除最后一次提交 这种情况比较简单,主要操作分两步: 第一步:回滚上一次提交 git reset --hard HEAD^ 第二步:强制提交本地代码 git push origin master -f
-
Python中更优雅的日志记录方案详解
目录 常见使用 loguru 安装 基本使用 详细使用 在 Python 中,一般情况下我们可能直接用自带的 logging 模块来记录日志,包括我之前的时候也是一样.在使用时我们需要配置一些 Handler.Formatter 来进行一些处理,比如把日志输出到不同的位置,或者设置一个不同的输出格式,或者设置日志分块和备份.但其实个人感觉 logging 用起来其实并不是那么好用,其实主要还是配置较为繁琐. 常见使用 首先看看 logging 常见的解决方案吧,我一般会配置输出到文件.控制台和