详解Python 定时框架 Apscheduler原理及安装过程
在我们的日常工作自动化测试当中,几乎超过一半的功能都需要利用定时的任务来推动触发,例如在我们项目中有一个定时监控模块,根据自己设置的频率定时跑测试用例,定时检测是否存在线上紧急任务等等,这些都涉及到了有关定时任务的问题,很多情况下,大多数人会选择window的任务计划程序,但如果程序不在window平台下运行,就不能定时启动了;当然也可利用time模块的time.sleep()方法使程序休眠来达到定时任务的目的,但定时任务多了,代码可能看起来不太那么友好且有很大的局限性,因此,此时的 Apscheduler 框架是你的不二选择。
Apscheduler
Apscheduler基于Quartz的一个python定时任务框架,实现Quart的所有功能,相关的接口调用起来比较方便,目前其提供了基于日期、固定时间间隔以及corntab类型的任务,并且同时可进行持久化任务;同时它提供了多种不同的调用器,方便开发者根据自己的需求进行使用,也方便与数据库等第三方的外部持久化储存机制进行协同工作,非常强大。
基本原理
总的来说,主要是利用python threading Event和Lock锁来写的。scheduler在主循环(main_loop)中, 反复检查是否有需要执行的任务,完成任务的检查函数为 _process_jobs,主要有那个几个步骤:
1、 询问储存的每个 jobStore ,是否有到期要执行的任务。

2、 due_jobs 不为空,则计算这些jobs中每个job需要运行的时间点,时间一到就提交给submit作任务调度。

3、在主循环中,如果不间断地调用,而实际上没有要执行的job,这会造成资源浪费。因此在程序中,如果每次掉用 _process_jobs 后,进行了预先判断,判断下一次要执行的job(离现在最近的)还要多长时间,作为返回值告诉main_loop, 这时主循环就可以去睡一觉,等大约这么长时间后再唤醒,执行下一次 _process_jobs 。
安装
1、可以直接使用pip进行安装
2、源码安装

### 基础概念
在Apscheduler中主要有以下几个非常重要的概念,主要如下:
触发器(trigger):
某一个工作到来时引发的事件,包含调度的逻辑,每一个作业都有它自己的触发器,用于决定哪个作业任务会执行,除了它们初始化配置之外,其完全是无状态的。总的来说就是 一个任务应该在什么时候执行
执行器(executor):
主要是处理作业的运行,它将要执行的作业放在新的线程或者线程池中运行。执行完毕之后,再通知调度器。基于线程池的操作,可以针对不同类型的作业任务,更为高效的使用CPU的计算资源。
作业存储(job stores)
保存要调度的任务,其中除了默认的作业存储是把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据将在保存在持久化的作业存储之前,会对作业执行序列化操作,当重新读取作业时,再执行反序列化操作。同时,调度器不能分享同一个作业存储。作业存储支持主流的存储机制:如redis,mongodb,关系型数据库,内存等等。
调度器(scheduler):
负责将上面几个组件联系在一起,一般在应用中只有一个调度器,程序开发者不会直接操作触发器、作业存储或执行器,而是利用调度器提供了处理这些合适的接口,作业存储和执行器的配置都是通过在调度器中完成的。
在我们的使用过程中,选择合适的 调度器 是根据我们的开发环境以及实际应用来决定的,根据IO模型的不同,主要有下面一些常见的调度器:
- BlockingScheduler:适合于只在进程中运行单个任务的情况
- BackgroundScheduler: 适合于不运行使用其他框架时,并希望在程序后台执行的情况
- AsyncIOScheduler:适合于使用asyncio框架的情况
- GeventScheduler: 适合于使用gevent框架的情况
- TornadoScheduler: 适合于使用Tornado框架的应用
- TwistedScheduler: 适合使用Twisted框架的应用
- QtScheduler: 适合使用QT的情况
而对于 作业存储 ,如果是非持久性作业,使用默认的 MemoryStore 就行了,若是持久性任务,那么就需要根据应用环境来进行选择。
大多数情况下, 执行器 选择 ThreadPoolExecutor 就够用了,但如果涉及到比较消耗CPU的作业,就可以选择ProcessPoolExecutor* ,以充分利用多核CPU。当然也可以同时配置使用两个执行器,将进程池 ProcessPoolExecutor 调度器作为你的第二个执行器。
配置调度器
Apscheduler框架提供了许多调度器的配置方法,既可以使用配置字典,也可以直接传递配置参数给调度器使用; 同时支持先初始化调度器,添加完作业任务后,再来配置调度器等。
说了这么多,我们可以来先举个简单的例子:

上面的代码生成一个默认的调度器,默认使用名为 default 的 MemoryJobStore,以及使用默认名为 default 的 ThreadPoolExecutor ,最大线程数为10 。
下面进行一个复杂的配置,同时使用两个作业存储和两个执行器,在这个配置中,修改默认的配置参数,jobstored指的是job持久化,默认job运行在内存中,可持久化在数据库,指定为mongo的MongoDBJobStore或者是使用sqlite的SQLAlchemyJobStore,同时可指定多种jobstore。
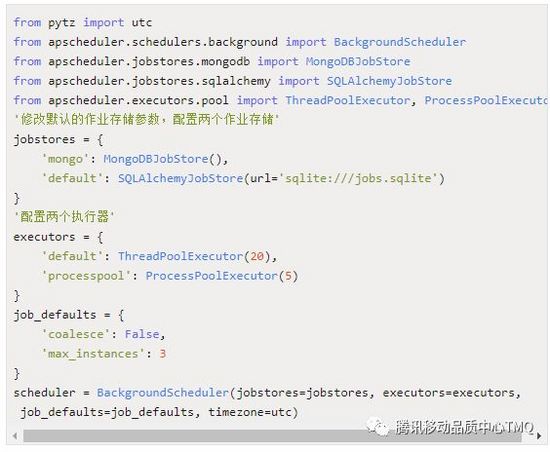
coalesce :当由于某种原因导致某个job积攒了好几次没有实际运行(比如说系统挂了5分钟后恢复,有一个任务是每分钟跑一次的,按道理说这5分钟内本来是“计划”运行5次的,但实际没有执行),如果coalesce为True,下次这个job被submit给executor时,只会执行1次,也就是最后这次,如果为False,那么会执行5次(不一定,因为还有其他条件,看后面misfiregracetime的解释)。
max_instance :每个job在同一时刻能够运行的最大实例数,默认情况下为1个,可以指定为更大值,这样即使上个job还没运行完同一个job又被调度的话也能够再开一个线程执行。
misfire_grace_time :单位为秒,假设有这么一种情况,当某一job被调度时刚好线程池都被占满,调度器会选择将该job排队不运行,misfiregracetime参数则是在线程池有可用线程时会比对该job的应调度时间跟当前时间的差值,如果差值<misfiregracetime时,调度器会再次调度该job.反之该job的执行状态为EVENTJOBMISSED了,即错过运行.</misfire。
启动/关闭调度器
使用 start() 方法来启动调度器,其中须注意的是 BlockingScheduler 需要在初始化之后才能执行 start() ,对于其他的调度器,调用 start() 方法都会直接返回,然后可以继续执行后面的初始化操作。同时,调度器启动之后,就不能再更改它的配置了。
在默认情况下,调度器会等所有的作业任务完成后,自动关闭所有的调度器及作业存储。若在使用过程中不想等待,可以将 wait 参数选项设为 False ,则表示直接关闭:

调度器监听事件
可以给调度器添加事件监听器,调度器事件只有在某些情况下才会被触发,并且可以携带某些有用的信息。通过给 add_listener() 传递合适的 mask 参数,可以只监听几种特定的事件类型,具体类型可看源码中的 event.exception 或者 event.code 值来做识别判断。

作业及作业存储
jobstore提供给scheduler一个序列化jobs的统一抽象,提供对scheduler中job的增删改查接口,根据存储backend的不同,分以下几种:
MemoryJobStore :没有序列化,jobs就存在内存里,增删改查也都是在内存中操作
SQLAlchemyJobStore :所有sqlalchemy支持的数据库都可以做为backend,增删改查操作转化为对应backend的sql语句
MongoDBJobStore :用mongodb作backend
RedisJobStore : 用redis作backend
Job是框架承接目前需要执行的工作和任务,我们可以在系统运行过程中进行动态的增加、修改、删除、查询等操作。
1、添加作业
上面是通过 add_job() 来添加作业,另外还有一种方式是通过修饰器 scheduled_job 来动态装饰 Job 的实际函数
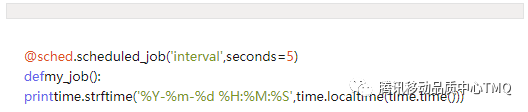
2、移除作业
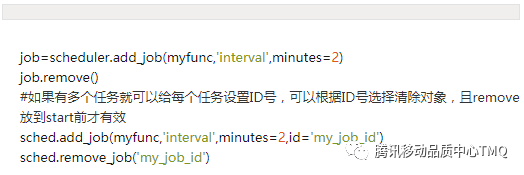
3、暂停作业

4、恢复作业

5、修改作业

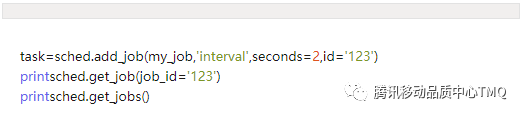
6、获取Job列表
获得调度作业的列表,可以使用 get_jobs() 来完成,它会返回所有的job实例,同时也可使用 print_jobs() 来输出所有格式化的作业列表。也可以利用 get_job(任务ID) 获取指定任务的作业列表
作业运行控制
add_job() 方法的第二个参数是trigger,它管理着作业任务的调度方式,它可以被设置为 data 、 interval 、 corn 三种类别。对于不同的设置类别,对应的参数也有所不同,具体如下:
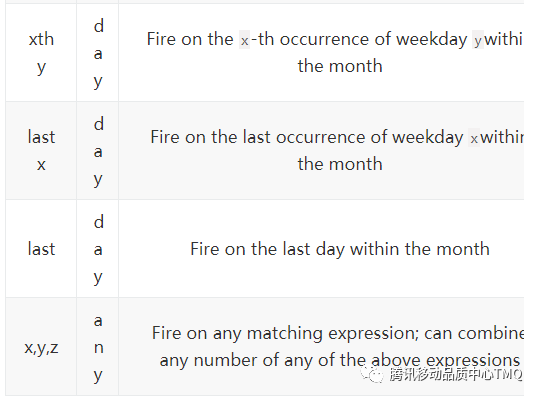
1、corn 定时调度,即规定在某一时刻执行

使用例子:


2、interval间隔调度,即每隔多久执行一次

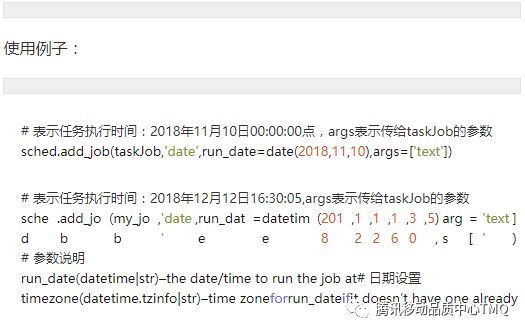
3、data定时调度,即设置后作业只会执行一次,是最基本的调度模式
总结
Apscheduler是一个非常强大且易用的类库,可以方便我们快速的搭建一些强大的定时任务或者定时监控类的调度系统,在实际工作中非常有用,同时其也提供了不少的扩展点。
以上所述是小编给大家介绍的Python 定时框架 Apscheduler,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
详解python调度框架APScheduler使用
最近在研究python调度框架APScheduler使用的路上,那么今天也算个学习笔记吧! # coding=utf-8 """ Demonstrates how to use the background scheduler to schedule a job that executes on 3 second intervals. """ from datetime import datetime import time import os
-
python编写网页爬虫脚本并实现APScheduler调度
前段时间自学了python,作为新手就想着自己写个东西能练习一下,了解到python编写爬虫脚本非常方便,且最近又学习了MongoDB相关的知识,万事具备只欠东风. 程序的需求是这样的,爬虫爬的页面是京东的电子书网站页面,每天会更新一些免费的电子书,爬虫会把每天更新的免费的书名以第一时间通过邮件发给我,通知我去下载. 一.编写思路: 1.爬虫脚本获取当日免费书籍信息 2.把获取到的书籍信息与数据库中的已有信息作比较,如果书籍存在不做任何操作,书籍不存在,执行插入数据库的操作,把数据的信息存入Mo
-
Python中定时任务框架APScheduler的快速入门指南
前言 大家应该都知道在编程语言中,定时任务是常用的一种调度形式,在Python中也涌现了非常多的调度模块,本文将简要介绍APScheduler的基本使用方法. 一.APScheduler介绍 APScheduler是基于Quartz的一个python定时任务框架,实现了Quartz的所有功能,使用起来十分方便.提供了基于日期.固定时间间隔以及crontab类型的任务,并且可以持久化任务. APScheduler提供了多种不同的调度器,方便开发者根据自己的实际需要进行使用:同时也提供了不同的存储机
-
详解Python 定时框架 Apscheduler原理及安装过程
在我们的日常工作自动化测试当中,几乎超过一半的功能都需要利用定时的任务来推动触发,例如在我们项目中有一个定时监控模块,根据自己设置的频率定时跑测试用例,定时检测是否存在线上紧急任务等等,这些都涉及到了有关定时任务的问题,很多情况下,大多数人会选择window的任务计划程序,但如果程序不在window平台下运行,就不能定时启动了:当然也可利用time模块的time.sleep()方法使程序休眠来达到定时任务的目的,但定时任务多了,代码可能看起来不太那么友好且有很大的局限性,因此,此时的 Apsch
-

详解python定时简单爬取网页新闻存入数据库并发送邮件
本人小白一枚,简单记录下学校作业项目,代码十分简单,主要是对各个库的理解,希望能给别的初学者一点启发. 一.项目要求 1.程序可以从北京工业大学首页上爬取新闻内容:http://www.bjut.edu.cn 2.程序可以将爬取下来的数据写入本地MySQL数据库中. 3.程序可以将爬取下来的数据发送到邮箱. 4.程序可以定时执行. 二.项目分析 1.爬虫部分利用requests库爬取html文本,再利用bs4中的BeaultifulSoup库来解析html文本,提取需要的内容. 2.使用pymy
-
一文详解Python中生成器的原理与使用
目录 什么是生成器 迭代器和生成器的区别 创建方式 生成器表达式 基本语法 生成器函数 yield关键字 yield和return yield的使用方法 生成器函数的基本使用 send的使用 可迭代对象的优化 总结 我们学习完推导式之后发现,推导式就是在容器中使用一个for循环而已,为什么没有元组推导式? 原因就是“元组推导式”的名字不是这样的,而是叫做生成器表达式. 什么是生成器 生成器表达式本质上就是一个迭代器,是定义迭代器的一种方式,是允许自定义逻辑的迭代器.生成器使用generator表
-
详解Python Flask框架的安装及应用
目录 1.安装 1.1 创建虚拟环境 1.2 进入虚拟环境 1.3 安装 flask 2.上手 2.1 最小 Demo 2.2 基本知识 3.解构官网指导 Demo 3.1 克隆与代码架构分析 3.2 入口文件 init.py 3.3 数据库设置 3.4 蓝图和视图 4.其他 5.跑起 DEMO 1.安装 1.1 创建虚拟环境 mkdir myproject cd myproject python3 -m venv venv 1.2 进入虚拟环境 . venv/bin/activate 1.3
-
详解Python中递归函数的原理与使用
目录 什么是递归函数 递归函数的条件 定义一个简单的递归函数 代码解析 内存栈区堆区 死递归 尾递归 实例 什么是递归函数 如果一个函数,可以自己调用自己,那么这个函数就是一个递归函数. 递归,递就是去,归就是回,递归就是一去一回的过程. 递归函数的条件 一般来说,递归需要边界条件,整个递归的结构中要有递归前进段和递归返回段.当边界条件不满足,递归前进,反之递归返回.就是说递归函数一定需要有边界条件来控制递归函数的前进和返回. 定义一个简单的递归函数 # 定义一个函数 def recursion
-
Python定时任务框架APScheduler原理及常用代码
APScheduler简介 在平常的工作中几乎有一半的功能模块都需要定时任务来推动,例如项目中有一个定时统计程序,定时爬出网站的URL程序,定时检测钓鱼网站的程序等等,都涉及到了关于定时任务的问题,第一时间想到的是利用time模块的time.sleep()方法使程序休眠来达到定时任务的目的,虽然这样也可以,但是总觉得不是那么的专业,^_^所以就找到了python的定时任务模块APScheduler: APScheduler基于Quartz的一个Python定时任务框架,实现了Quartz的所有功
-
详解Python网络框架Django和Scrapy安装指南
Windows 上的Django安装 如今Python使用的范围越来越广,所以学会关于它比较火的网络框架非常有必要.要安装Django,首先要知道你电脑上的python是哪个版本的,至于如何安装python的解释器环境此处不做介绍,网上的教程很多. Django 是一个 Python Web 框架,因此需要在您的机器上安装 Python.本文是基于Python3.6的环境安装介绍的. 要查看你电脑上的python版本,使用以下指令: python --version 要安装django,还要安装
-
详解python单元测试框架unittest
一:unittest是python自带的一个单元测试框架,类似于java的junit,基本结构是类似的. 基本用法如下: 1.用import unittest导入unittest模块 2.定义一个继承自unittest.TestCase的测试用例类,如 class abcd(unittest.TestCase): 3.定义setUp和tearDown,这两个方法与junit相同,即如果定义了则会在每个测试case执行前先执行setUp方法,执行完毕后执行tearDown方法. 4.定义测试用例,
-
Python定时任务框架APScheduler安装使用详解
目录 前言 一.APscheduler简介 二.APscheduler安装 三.APscheduler组成部分 1.Job 作业 2.Trigger 触发器 3.Jobstore 作业存储 4.Executor 执行器 5.scheduler 调度器 四.Scheduler工作流程图 1.Scheduler添加job流程 2.Scheduler调度流程 五.APscheduler使用 1.简单应用 2.操作作业 2.1 date触发器 2.2 interval触发器 2.3 cron触发器 参考