使用Post方法模拟登陆爬取网页的实现方法
最近弄爬虫,遇到的一个问题就是如何使用post方法模拟登陆爬取网页。
下面是极简版的代码:
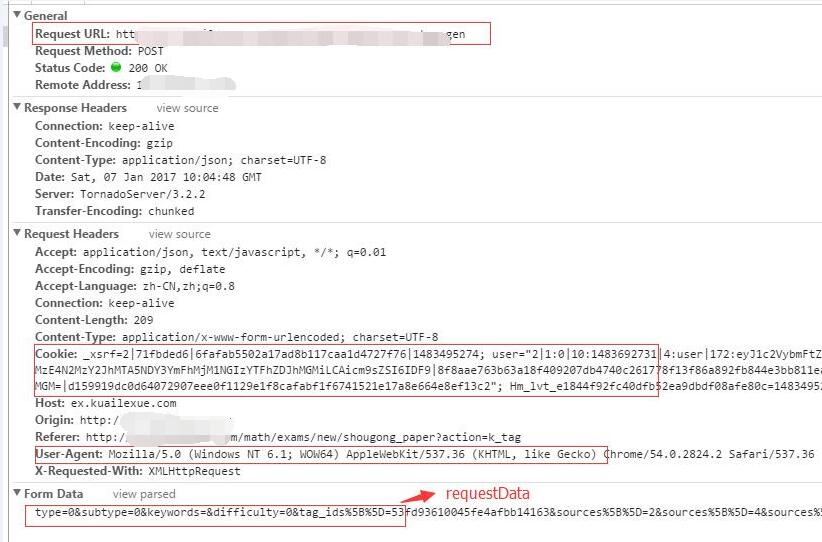
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.HashMap;
public class test {
//post请求地址
private static final String POST_URL = "";
//模拟谷歌浏览器请求
private static final String USER_AGENT = "";
//用账号登录某网站后 请求POST_URL链接获取cookie
private static final String COOKIE = "";
//用账号登录某网站后 请求POST_URL链接获取数据包
private static final String REQUEST_DATA = "";
public static void main(String[] args) throws Exception {
HashMap<String, String> map = postCapture(REQUEST_DATA);
String responseCode = map.get("responseCode");
String value = map.get("value");
while(!responseCode.equals("200")){
map = postCapture(REQUEST_DATA);
responseCode = map.get("responseCode");
value = map.get("value");
}
//打印爬取结果
System.out.println(value);
}
private static HashMap<String, String> postCapture(String requestData) throws Exception{
HashMap<String, String> map = new HashMap<>();
URL url = new URL(POST_URL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
httpConn.setDoInput(true); // 设置输入流采用字节流
httpConn.setDoOutput(true); // 设置输出流采用字节流
httpConn.setUseCaches(false); //设置缓存
httpConn.setRequestMethod("POST");//POST请求
httpConn.setRequestProperty("User-Agent", USER_AGENT);
httpConn.setRequestProperty("Cookie", COOKIE);
PrintWriter out = new PrintWriter(new OutputStreamWriter(httpConn.getOutputStream(), "UTF-8"));
out.println(requestData);
out.close();
int responseCode = httpConn.getResponseCode();
StringBuffer buffer = new StringBuffer();
if (responseCode == 200) {
BufferedReader reader = new BufferedReader(new InputStreamReader(httpConn.getInputStream(), "UTF-8"));
String line = null;
while ((line = reader.readLine()) != null) {
buffer.append(line);
}
reader.close();
httpConn.disconnect();
}
map.put("responseCode", new Integer(responseCode).toString());
map.put("value", buffer.toString());
return map;
}
}
以上这篇使用Post方法模拟登陆爬取网页的实现方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

使用Post方法模拟登陆爬取网页的实现方法
最近弄爬虫,遇到的一个问题就是如何使用post方法模拟登陆爬取网页. 下面是极简版的代码: import java.io.BufferedReader; import java.io.InputStreamReader; import java.io.OutputStreamWriter; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.URL; import java.util.Has
-
PHP 爬取网页的主要方法
主要流程就是获取整个网页,然后正则匹配(关键的). PHP抓取页面的主要方法,有几种方法是网上前辈的经验,现在还没有用到的,先存下来以后试试. 1.file()函数 2.file_get_contents()函数 3.fopen()->fread()->fclose()模式 4.curl方式 (本人主要用这个) 5.fsockopen()函数 socket模式 6.插件(如:http://sourceforge.net/projects/snoopy/) 7.file()函数 <?php
-
用C#+Selenium+ChromeDriver爬取网页(模拟真实的用户浏览行为)
以下文章来源于公众号:DotNetCore实战 1.背景 Selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.而对于爬虫来说,使用Selenium操控浏览器来爬取网上的数据那么肯定是爬虫中的杀手武器.这里,我将介绍selenium + 谷歌浏览器的一般使用. 2.需求 在平常的爬虫开发中,有时候网页是一堆js堆起来的代码,涉及很多异步计算,如果是普通的http 控制台请求,那么得到的源文件是一堆js ,需要自己在去组装数据,很费力
-
Python3爬虫之urllib携带cookie爬取网页的方法
如下所示: import urllib.request import urllib.parse url = 'https://weibo.cn/5273088553/info' #正常的方式进行访问 # headers = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36' # } # 携带
-
如何在scrapy中集成selenium爬取网页的方法
1.背景 我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium.requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化). 在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦. 尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面后台发生了怎样的请求,也不需要分析整
-
Python爬取网页的所有内外链的代码
项目介绍 采用广度优先搜索方法获取一个网站上的所有外链. 首先,我们进入一个网页,获取网页的所有内链和外链,再分别进入内链中,获取该内链的所有内链和外链,直到访问完所有内链未知. 代码大纲 1.用class类定义一个队列,先进先出,队尾入队,队头出队: 2.定义四个函数,分别是爬取网页外链,爬取网页内链,进入内链的函数,以及调函数: 3.爬取百度图片(https://image.baidu.com/),先定义两个队列和两个数组,分别来存储内链和外链:程序开始时,先分别爬取当前网页的内链和外链,再
-
python爬取网页版QQ空间,生成各类图表
github源码地址: https://github.com/kuishou68/python 各类图表的实现效果 爬取的说说内容 个性化说说内容词云图 每年发表说说总数柱状图.每年点赞和评论折线图 7天好友动态柱状图.饼图 使用方法 按照你的谷歌浏览器下载指定版本的驱动 http://chromedriver.storage.googleapis.com/index.html 驱动跟两个python脚本放入同目录,我的版本是90.0.4430的,查看你自己的版本,下载后把我的chromedri
-
详解Java两种方式简单实现:爬取网页并且保存
对于网络,我一直处于好奇的态度.以前一直想着写个爬虫,但是一拖再拖,懒得实现,感觉这是一个很麻烦的事情,出现个小错误,就要调试很多时间,太浪费时间. 后来一想,既然早早给自己下了保证,就先实现它吧,从简单开始,慢慢增加功能,有时间就实现一个,并且随时优化代码. 下面是我简单实现爬取指定网页,并且保存的简单实现,其实有几种方式可以实现,这里慢慢添加该功能的几种实现方式. UrlConnection爬取实现 package html; import java.io.BufferedReader; i
-
利用Python2下载单张图片与爬取网页图片实例代码
前言 一直想好好学习一下Python爬虫,之前断断续续的把Python基础学了一下,悲剧的是学的没有忘的快.只能再次拿出来滤了一遍,趁热打铁,通过实例来实践下,下面这篇文章主要介绍了关于Python2下载单张图片与爬取网页的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 一.需求分析 1.知道图片的url地址,将图片下载到本地. 2.知道网页地址,将图片列表中的图片全部下载到本地. 二.准备工作 1.开发系统:win7 64位. 2.开发环境:python2.7. 3
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')