Java数据结构之图的两种搜索算法详解
目录
- 前言
- 深度优先搜索算法
- API设计
- 代码实现
- 广度优先搜素算法
- API设计
- 代码实现
- 案例应用
前言
在很多情况下,我们需要遍历图,得到图的一些性质,例如,找出图中与指定的顶点相连的所有顶点,或者判定某个顶点与指定顶点是否相通,是非常常见的需求。
有关图的搜索,最经典的算法有深度优先搜索和广度优先搜索,接下来我们分别讲解这两种搜索算法。
学习本文前请先阅读这篇文章 【数据结构与算法】图的基础概念和数据模型。
深度优先搜索算法
所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么先找子结点,然后找兄弟结点。
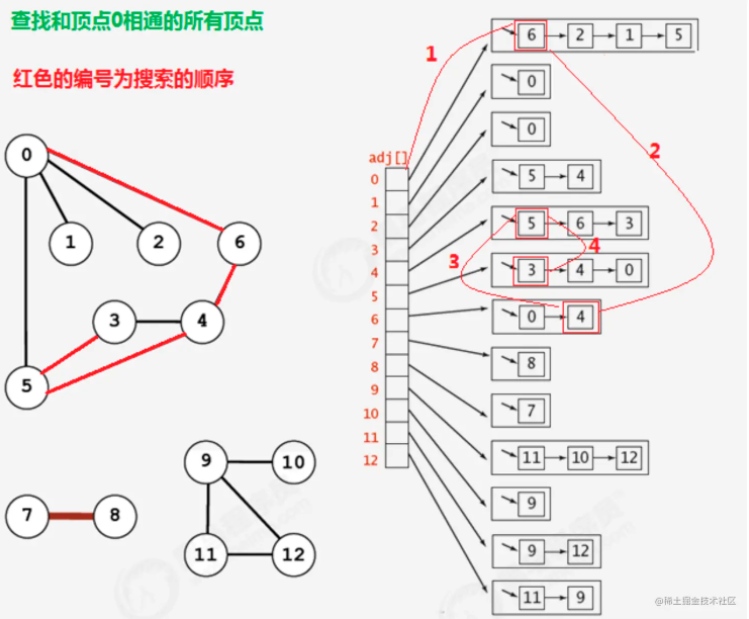
如上图所示:
由于边是没有方向的,所以,如果4和5顶点相连,那么4会出现在5的相邻链表中,5也会出现在4的相邻链表中。
为了不对顶点进行重复搜索,应该要有相应的标记来表示当前顶点有没有搜索过,可以使用一个布尔类型的数组boolean[V] marked,索引代表顶点,值代表当前顶点是否已经搜索,如果已经搜索,标记为true,
如果没有搜索,标记为false;
API设计
| 类名 | DepthFirstSearch |
|---|---|
| 成员变量 | 1.private boolean[] marked: 索引代表顶点,值表示当前顶点是否已经被搜索2.private int count:记录有多少个顶点与s顶点相通 |
| 构造方法 | DepthFirstSearch(Graph G,int s):构造深度优先搜索对象,使用深度优先搜索找出G图中s顶点的所有相通顶点 |
| 成员方法 | 1.private void dfs(Graph G, int v):使用深度优先搜索找出G图中v顶点的所有相通顶点2.public boolean marked(int w):判断w顶点与s顶点是否相通3.public int count():获取与顶点s相通的所有顶点的总数 |
代码实现
/**
* 图的深度优先搜索算法
*
* @author alvin
* @date 2022/10/31
* @since 1.0
**/
public class DepthFirstSearch {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//记录有多少个顶点与s顶点相通
private int count;
//构造深度优先搜索对象,使用深度优先搜索找出G图中s顶点的所有相邻顶点
public DepthFirstSearch(Graph G, int s) {
//创建一个和图的顶点数一样大小的布尔数组
marked = new boolean[G.V()];
dfs(G, s);
}
//使用深度优先搜索找出G图中v顶点的所有相邻顶点
private void dfs(Graph G, int v) {
//把当前顶点标记为已搜索
marked[v] = true;
//遍历v顶点的邻接表,得到每一个顶点w
for (Integer w : G.adj(v)) {
//遍历v顶点的邻接表,得到每一个顶点w
if (!marked[w]) {
//如果当前顶点w没有被搜索过,则递归搜索与w顶点相通的其他顶点
dfs(G, w);
}
}
//相通的顶点数量+1
count++;
}
//判断w顶点与s顶点是否相通
public boolean marked(int w) {
return marked[w];
}
//获取与顶点s相通的所有顶点的总数
public int count() {
return count;
}
}
测试:
public class DepthFirstSearchTest {
@Test
public void test() {
//准备Graph对象
Graph G = new Graph(13);
G.addEdge(0,5);
G.addEdge(0,1);
G.addEdge(0,2);
G.addEdge(0,6);
G.addEdge(5,3);
G.addEdge(5,4);
G.addEdge(3,4);
G.addEdge(4,6);
G.addEdge(7,8);
G.addEdge(9,11);
G.addEdge(9,10);
G.addEdge(9,12);
G.addEdge(11,12);
//准备深度优先搜索对象
DepthFirstSearch search = new DepthFirstSearch(G, 0);
//测试与某个顶点相通的顶点数量
int count = search.count();
System.out.println("与起点0相通的顶点的数量为:"+count);
//测试某个顶点与起点是否相同
boolean marked1 = search.marked(5);
System.out.println("顶点5和顶点0是否相通:"+marked1);
boolean marked2 = search.marked(7);
System.out.println("顶点7和顶点0是否相通:"+marked2);
}
}
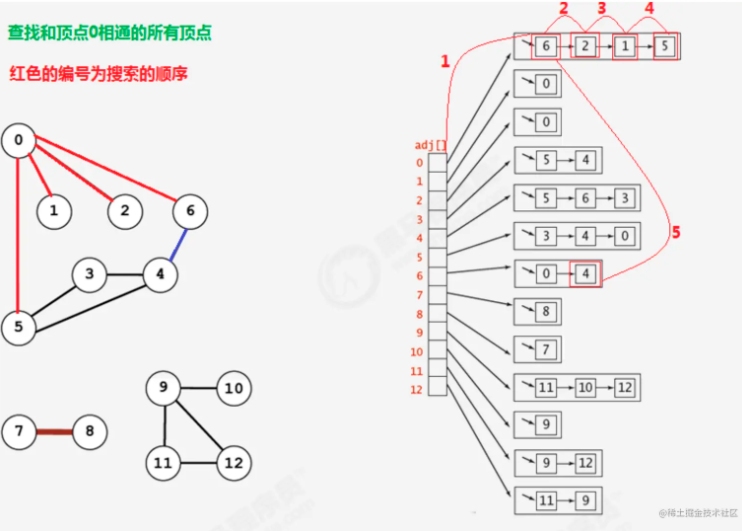
广度优先搜素算法
所谓的广度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,又有兄弟结点,那么先找兄弟结点,然后找子结点。
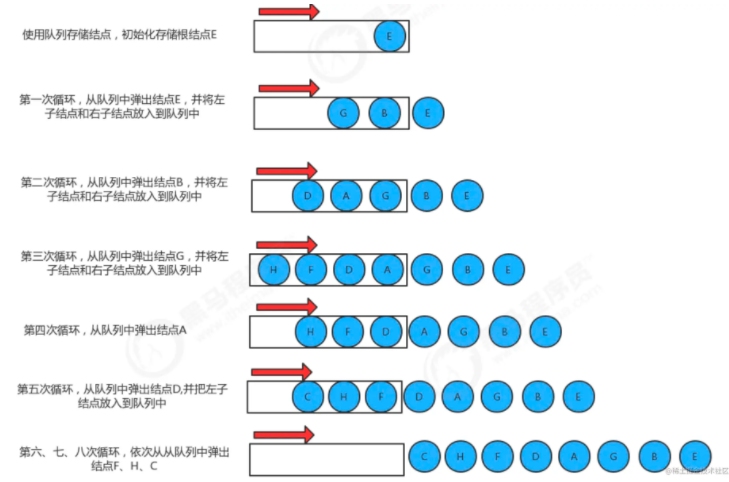
- 可以通过借助一个辅助队列实现,先将1加入到队列中
- 然后取出1,将1的相邻顶点加入到队列中
- 依次递归,如下图所示:
API设计
| 类名 | BreadthFirstSearch |
|---|---|
| 成员变量 | 1.private boolean[] marked: 索引代表顶点,值表示当前顶点是否已经被搜索2.private int count:记录有多少个顶点与s顶点相通3.private Queue waitSearch: 用来存储待搜索邻接表的点 |
| 构造方法 | BreadthFirstSearch(Graph G,int s):构造广度优先搜索对象,使用广度优先搜索找出G图中s顶点的所有相邻顶点 |
| 成员方法 | 1.private void bfs(Graph G, int v):使用广度优先搜索找出G图中v顶点的所有相邻顶点2.public boolean marked(int w):判断w顶点与s顶点是否相通3.public int count():获取与顶点s相通的所有顶点的总数 |
代码实现
/**
* 图的广度优先搜索算法
*
* @author alvin
* @date 2022/10/31
* @since 1.0
**/
public class BreadthFirstSearch {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//记录有多少个顶点与s顶点相通
private int count;
//用来存储待搜索邻接表的点
private Queue<Integer> waitSearch;
//构造广度优先搜索对象,使用广度优先搜索找出G图中s顶点的所有相邻顶点
public BreadthFirstSearch(Graph G, int s) {
this.marked = new boolean[G.V()];
this.count = 0;
this.waitSearch = new ArrayDeque<>();
bfs(G, s);
}
//使用广度优先搜索找出G图中v顶点的所有相邻顶点
private void bfs(Graph G, int v) {
//把当前顶点v标识为已搜索
marked[v] = true;
//让顶点v进入队列,待搜索
waitSearch.add(v);
//通过循环,如果队列不为空,则从队列中弹出一个待搜索的顶点进行搜索
while (!waitSearch.isEmpty()) {
//弹出一个待搜索的顶点
Integer wait = waitSearch.poll();
//遍历wait顶点的邻接表
for (Integer w : G.adj(wait)) {
if (!marked[w]) {
bfs(G, w);
}
}
}
//让相通的顶点+1;
count++;
}
//判断w顶点与s顶点是否相通
public boolean marked(int w) {
return marked[w];
}
//获取与顶点s相通的所有顶点的总数
public int count() {
return count;
}
}
测试代码:
public class BreadthFirstSearchTest {
@Test
public void test() {
//准备Graph对象
Graph G = new Graph(13);
G.addEdge(0, 5);
G.addEdge(0, 1);
G.addEdge(0, 2);
G.addEdge(0, 6);
G.addEdge(5, 3);
G.addEdge(5, 4);
G.addEdge(3, 4);
G.addEdge(4, 6);
G.addEdge(7, 8);
G.addEdge(9, 11);
G.addEdge(9, 10);
G.addEdge(9, 12);
G.addEdge(11, 12);
//准备广度优先搜索对象
BreadthFirstSearch search = new BreadthFirstSearch(G, 0);
//测试与某个顶点相通的顶点数量
int count = search.count();
System.out.println("与起点0相通的顶点的数量为:" + count);
//测试某个顶点与起点是否相同
boolean marked1 = search.marked(5);
System.out.println("顶点5和顶点0是否相通:" + marked1);
boolean marked2 = search.marked(7);
System.out.println("顶点7和顶点0是否相通:" + marked2);
}
}
案例应用
某省调查城镇交通状况,得到现有城镇道路统计表,表中列出了每条道路直接连通的城镇。“畅通工程”的目标是使全省任何两个城镇间都可以实现交通(但不一定有直接的道路相连,只要互相间接通过道路可达即可)。目前的道路状况,9号城市和10号城市是否相通?9号城市和8号城市是否相通?
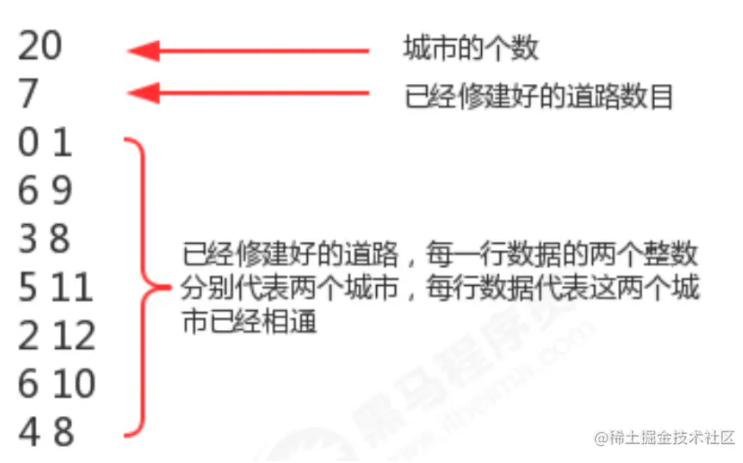
测试数据格式如上图所示,总共有20个城市,目前已经修改好了7条道路,问9号城市和10号城市是否相通?9号城市和8号城市是否相通?
解题思路:
- 创建一个图Graph对象,表示城市;
- 分别调用
addEdge(0,1),addEdge(6,9),addEdge(3,8),addEdge(5,11),addEdge(2,12),addEdge(6,10),addEdge(4,8),表示已经修建好的道路把对应的城市连接起来; - 通过Graph对象和顶点9,构建
DepthFirstSearch对象或BreadthFirstSearch对象; - 调用搜索对象的
marked(10)方法和marked(8)方法,即可得到9和城市与10号城市以及9号城市与8号城市是否相通。
代码实现:
public class TrafficProjectGraph {
public static void main(String[] args) throws Exception{
//城市数量
int totalNumber = 20;
Graph G = new Graph(totalNumber);
//添加城市的交通路线
G.addEdge(0,1);
G.addEdge(6,9);
G.addEdge(3,8);
G.addEdge(5,11);
G.addEdge(2,12);
G.addEdge(6,10);
G.addEdge(4,8);
//构建一个深度优先搜索对象,起点设置为顶点9
DepthFirstSearch search = new DepthFirstSearch(G, 9);
//调用marked方法,判断8顶点和10顶点是否与起点9相通
System.out.println("顶点8和顶点9是否相通:"+search.marked(8));
System.out.println("顶点10和顶点9是否相通:"+search.marked(10));
}
}
结果:

以上就是Java数据结构之图的两种搜索算法详解的详细内容,更多关于Java图搜索算法的资料请关注我们其它相关文章!
相关推荐
-

Java数据结构之图的领接矩阵详解
目录 1.图的领接矩阵(Adjacency Matrix)存储结构 2.图的接口类 3.图的类型,用枚举类表示 4.图的领接矩阵描述 测试类 结果 1.图的领接矩阵(Adjacency Matrix)存储结构 图的领接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图.一个一位数组存储图中顶点信息,一个二维数组(称为领接矩阵)存储图中的边或弧的信息. 举例 无向图 无向图的领接矩阵的第i行或第i列的非零元素个数正好是第i个顶点的度. 有向图 有向图的领接矩阵的第i行的非零元素个
-
Java数据结构之图的基础概念和数据模型详解
目录 图的实际应用 图的定义及分类 图的相关术语 图的存储结构 邻接矩阵 邻接表 图的实现 图的API设计 代码实现 图的实际应用 在现实生活中,有许多应用场景会包含很多点以及点点之间的连接,而这些应用场景我们都可以用即将要学习的图这种数据结构去解决. 地图: 我们生活中经常使用的地图,基本上是由城市以及连接城市的道路组成,如果我们把城市看做是一个一个的点,把道路看做是一条一条的连接,那么地图就是我们将要学习的图这种数据结构. 图的定义及分类 定义: 图是由一组顶点和一组能够将两个顶点相连的边组
-
Java数据结构之图(动力节点Java学院整理)
1,摘要: 本文章主要讲解学习如何使用JAVA语言以邻接表的方式实现了数据结构---图(Graph).从数据的表示方法来说,有二种表示图的方式:一种是邻接矩阵,其实是一个二维数组:一种是邻接表,其实是一个顶点表,每个顶点又拥有一个边列表.下图是图的邻接表表示. 从图中可以看出,图的实现需要能够表示顶点表,能够表示边表.邻接表指是的哪部分呢?每个顶点都有一个邻接表,一个指定顶点的邻接表中,起始顶点表示边的起点,其他顶点表示边的终点.这样,就可以用邻接表来实现边的表示了.如顶点V0的邻接表如下: 与
-
Java数据结构中图的进阶详解
目录 有向图 有向图API设计 有向图的实现 拓扑排序 拓扑排序图解 检测有向图中的环 检测有向环的API设计 检测有向环实现 代码 基于深度优先的顶点排序 顶点排序API设计 顶点排序实现 代码: 有向图 有向图的定义及相关术语 定义∶ 有向图是一副具有方向性的图,是由一组顶点和一组有方向的边组成的,每条方向的边都连着 一对有序的顶点. 出度∶ 由某个顶点指出的边的个数称为该顶点的出度. 入度: 指向某个顶点的边的个数称为该顶点的入度. 有向路径︰ 由一系列顶点组成,对于其中的每个顶点都存在一
-
Java数据结构之图的原理与实现
目录 1 图的定义和相关概念 2 图的存储结构 2.1 邻接矩阵 2.2 邻接表 3 图的遍历 3.1 深度优先遍历 3.2 广度优先遍历 4 图的实现 4.1 无向图的邻接表实现 4.2 有向图的邻接表实现 4.3 无向图的邻接矩阵实现 4.4 有向图的邻接矩阵实现 5 总结 首先介绍了图的入门概念,然后介绍了图的邻接矩阵和邻接表两种存储结构.以及深度优先遍历和广度优先遍历的两种遍历方式,最后提供了Java代码的实现. 图,算作一种比较复杂的数据结构,因此建议有一定数据结构基础的人再来学习!
-
java图搜索算法之DFS与BFS详解
目录 一.前言 二.深度优先搜索 三.广度优先搜索 四.结语 你好,我是小黄,一名独角兽企业的Java开发工程师. 感谢茫茫人海中我们能够相遇, 俗话说:当你的才华和能力,不足以支撑你的梦想的时候,请静下心来学习, 希望优秀的你可以和我一起学习,一起努力,实现属于自己的梦想. 一.前言 上一篇文章我们提到了关于图的形象化描述方法,不知道大家还有没有印象.没有印象的话,可以去看一下上期的内容 对于图来说,搜索的方法无外乎两种,深度优先搜索(DFS)和广度优先搜索(BFS) 两种搜索算法也不太相同,
-
java图搜索算法之图的对象化描述示例详解
目录 一.前言 二.什么是图 三.怎么存储一个图的结构 1.邻接矩阵 2.邻接表 3.图对象化表示 四.图的作用 你好,我是小黄,一名独角兽企业的Java开发工程师. 校招收获数十个offer,年薪均20W~40W. 感谢茫茫人海中我们能够相遇, 俗话说:当你的才华和能力,不足以支撑你的梦想的时候,请静下心来学习, 希望优秀的你可以和我一起学习,一起努力,实现属于自己的梦想. 一.前言 对于图来说,我一直以来都似懂非懂 懂的是图的含义,不懂的是图具体的实现 对于当前各大厂面试的图题,不外乎以下几
-
Java编程实现基于图的深度优先搜索和广度优先搜索完整代码
为了解15puzzle问题,了解了一下深度优先搜索和广度优先搜索.先来讨论一下深度优先搜索(DFS),深度优先的目的就是优先搜索距离起始顶点最远的那些路径,而广度优先搜索则是先搜索距离起始顶点最近的那些路径.我想着深度优先搜索和回溯有什么区别呢?百度一下,说回溯是深搜的一种,区别在于回溯不保留搜索树.那么广度优先搜索(BFS)呢?它有哪些应用呢?答:最短路径,分酒问题,八数码问题等.言归正传,这里笔者用java简单实现了一下广搜和深搜.其中深搜是用图+栈实现的,广搜使用图+队列实现的,代码如下:
-
Java数据结构之图的两种搜索算法详解
目录 前言 深度优先搜索算法 API设计 代码实现 广度优先搜素算法 API设计 代码实现 案例应用 前言 在很多情况下,我们需要遍历图,得到图的一些性质,例如,找出图中与指定的顶点相连的所有顶点,或者判定某个顶点与指定顶点是否相通,是非常常见的需求. 有关图的搜索,最经典的算法有深度优先搜索和广度优先搜索,接下来我们分别讲解这两种搜索算法. 学习本文前请先阅读这篇文章 [数据结构与算法]图的基础概念和数据模型. 深度优先搜索算法 所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,
-
Java数据结构之图的路径查找算法详解
目录 前言 算法详解 实现 API设计 代码实现 前言 在实际生活中,地图是我们经常使用的一种工具,通常我们会用它进行导航,输入一个出发城市,输入一个目的地 城市,就可以把路线规划好,而在规划好的这个路线上,会路过很多中间的城市.这类问题翻译成专业问题就是: 从s顶点到v顶点是否存在一条路径?如果存在,请找出这条路径. 例如在上图上查找顶点0到顶点4的路径用红色标识出来,那么我们可以把该路径表示为 0-2-3-4. 如果对图的前置知识不了解,请查看系列文章: [数据结构与算法]图的基础概念和数据
-
Java唤醒本地应用的两种方法详解
目录 引言 1. Runtime使用方式 2. ProcessBuilder使用方式 3. 小结 引言 作为一个后端同学,经常被安全的小伙伴盯上,找一找安全漏洞:除了常说的注入之外,还有比较吓人的执行远程命令,唤醒本地应用程序等:然后有意思的问题就来了,写了这么多年的代码,好像还真没有尝试过用java来唤醒本地应用程序的 比如说一个最简单的,打开本地的计算器,应该怎么搞? 接下来本文将介绍一下如何使用java打开本地应用,以及打开mac系统中特殊一点的处理方式(直白来说就是不同操作系统,使用姿势
-
Java 中分形图的几种方法详解
Java分形 Java的分形主要有一下几种: 1.类似Clifford的分形.这种分形的特点是:分形的初始坐标为(0,0),通过初始坐标经过大量的迭代,得到一系列的点,根据得到的点来绘制分形曲线.这类分形的参数有限,可以很简单的实现. 2.类似IFS fern这样的分形.这种分形比上一种分形具有更多的参数,值得注意的是IFS fern分形的参数列表中有一项P值,该值表示的是各组不同的参数应该出现的概率,如果这个值没用上是无法得到想要的图形的. 3.类似Mandelbrot这样的分形.这种分形涉及
-
Java求最小生成树的两种算法详解
目录 1 最小生成树的概述 2 普里姆算法(Prim) 2.1 原理 2.2 案例分析 3 克鲁斯卡尔算法(Kruskal) 3.1 原理 3.2 案例分析 4 邻接矩阵加权图实现 5 邻接表加权图实现 6 总结 介绍了图的最小生成树的概念,然后介绍了求最小生成树的两种算法:Prim算法和Kruskal算法的原理,最后提供了基于邻接矩阵和邻接链表的图对两种算法的Java实现. 阅读本文需要一定的图的基础,如果对于图不是太明白的可以看看这篇文章:Java数据结构之图的原理与实现. 1 最小生成树的
-
使用Java构造和解析Json数据的两种方法(详解二)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面接着介绍用org.json构造和解析Json数据的方法
-
使用Java构造和解析Json数据的两种方法(详解一)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面首先介绍用json-lib构造和解析Json数据的方法
-
Java实现Excel转PDF的两种方法详解
目录 一.使用spire转化PDF 1.使用spire将整个Excel文件转为PDF 2.指定单个的sheet页转为PDF 二.使用jacob实现Excel转PDF(推荐使用) 1.环境准备 2.执行导出PDF 使用具将Excel转为PDF的方法有很多,在这里我给大家介绍两种常用的方法,分别应对两种不一样的使用场景,接下来我在springboot环境下给大家做一下演示! 一.使用spire转化PDF 首先介绍一种比较简单的方法,这种方法可以使用短短的几行代码就可以将我们的Excel文件中的某一个
-
Java数据结构之链表的增删查改详解
一.链表的概念和结构 1.1 链表的概念 简单来说链表是物理上不一定连续,但是逻辑上一定连续的一种数据结构 1.2 链表的分类 实际中链表的结构非常多样,以下情况组合起来就有8种链表结构. 单向和双向,带头和不带头,循环和非循环.排列组合和会有8种. 但我这只是实现两种比较难的链表,理解之后其它6种就比较简单了 1.单向不带头非循环链表 2.双向不带头非循环链表 二.单向不带头非循环链表 2.1 创建节点类型 我们创建了一个 ListNode 类为节点类型,里面有两个成员变量,val用来存储数值