Java数据结构之有向图的拓扑排序详解
目录
- 前言
- 拓扑排序介绍
- 检测有向图中的环
- 实现思路
- API设计
- 代码实现
- 基于深度优先的顶点排序
- 实现思路
- API设计
- 代码实现
- 拓扑排序
- API设计
- 代码实现
- 测试验证
前言
在现实生活中,我们经常会同一时间接到很多任务去完成,但是这些任务的完成是有先后次序的。以我们学习java
学科为例,我们需要学习很多知识,但是这些知识在学习的过程中是需要按照先后次序来完成的。从java基础,到
jsp/servlet,到ssm,到springboot等是个循序渐进且有依赖的过程。在学习jsp前要首先掌握java基础和html基
础,学习ssm框架前要掌握jsp/servlet之类才行。
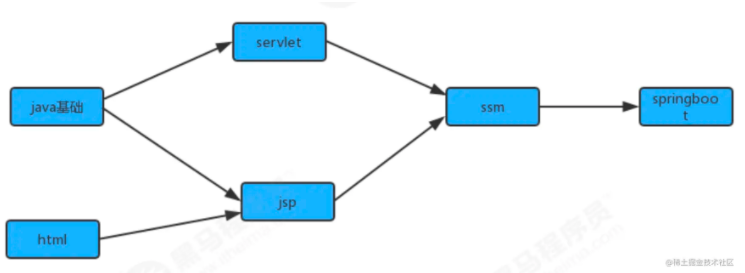
为了简化问题,我们使用整数为顶点编号的标准模型来表示这个案例:
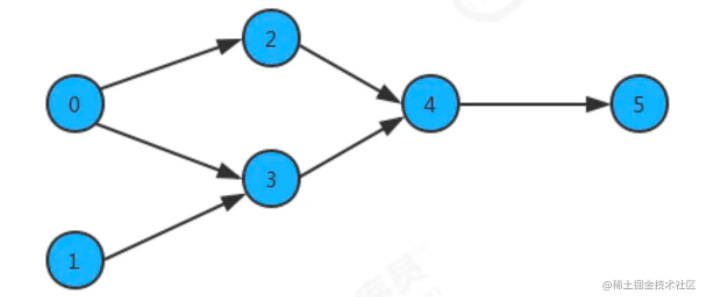
此时如果某个同学要学习这些课程,就需要指定出一个学习的方案,我们只需要对图中的顶点进行排序,让它转换为一个线性序列,就可以解决问题,这时就需要用到一种叫拓扑排序的算法。
拓扑排序介绍
给定一副有向图,将所有的顶点排序,使得所有的有向边均从排在前面的元素指向排在后面的元素,此时就可以明确的表示出每个顶点的优先级。下列是一副拓扑排序后的示意图:

检测有向图中的环
如果学习x课程前必须先学习y课程,学习y课程前必须先学习z课程,学习z课程前必须先学习x课程,那么一定是有问题了,我们就没有办法学习了,因为这三个条件没有办法同时满足。其实这三门课程x、y、z的条件组成了一个环:
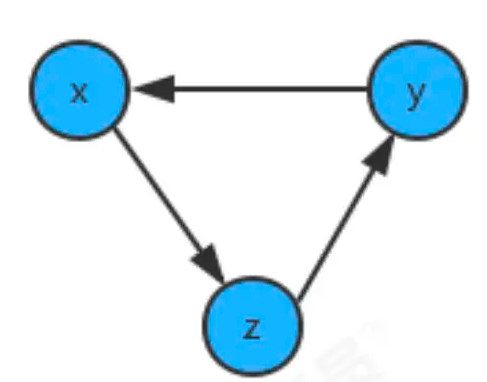
因此,如果我们要使用拓扑排序解决优先级问题,首先得保证图中没有环的存在。
实现思路
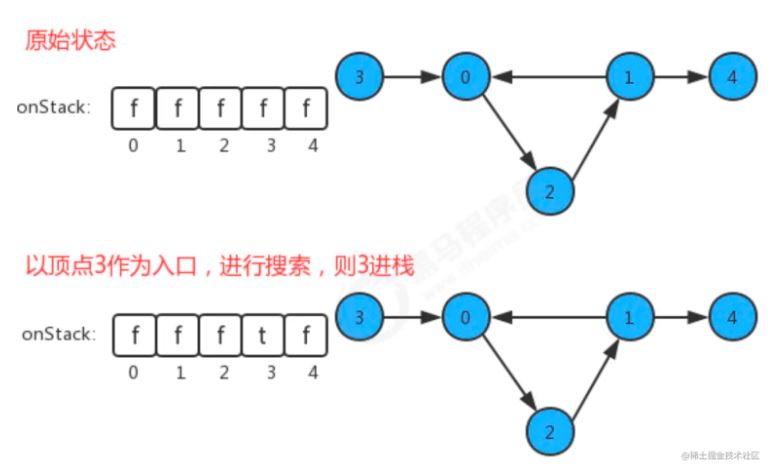
在API中添加了onStack[] 布尔数组,索引为图的顶点,当我们深度搜索时:
- 在如果当前顶点正在搜索,则把对应的onStack数组中的值改为true,标识进栈;
- 如果当前顶点搜索完毕,则把对应的onStack数组中的值改为false,标识出栈;
- 如果即将要搜索某个顶点,但该顶点已经在栈中,则图中有环;




API设计
| 类名 | DirectedCycle |
|---|---|
| 成员变量 | 1.private boolean[] marked: 索引代表顶点,值表示当前顶点是否已经被搜索2.private boolean hasCycle: 记录图中是否有环3.private boolean[] onStack:索引代表顶点,使用栈的思想,记录当前顶点有没有已经处于正在搜索的有向路径上 |
| 构造方法 | DirectedCycle(Digraph G):创建一个检测环对象,检测图G中是否有环 |
| 成员方法 | 1.private void dfs(Digraph G,int v):基于深度优先搜索,检测图G中是否有环2.public boolean hasCycle():判断图中是否有环 |
代码实现
/**
* 有向图是否存在环
*
* @author alvin
* @date 2022/11/2
* @since 1.0
**/
public class DirectedCycle {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//记录图中是否有环
private boolean hasCycle;
//索引代表顶点,使用栈的思想,记录当前顶点有没有已经处于正在搜索的有向路径上
private boolean[] onStack;
//创建一个检测环对象,检测图G中是否有环
public DirectedCycle(Digraph G){
//初始化marked数组
this.marked = new boolean[G.V()];
//初始化hasCycle
this.hasCycle = false;
//初始化onStack数组
this.onStack = new boolean[G.V()];
//找到图中每一个顶点,让每一个顶点作为入口,调用一次dfs进行搜索
for (int v =0; v<G.V();v++){
//判断如果当前顶点还没有搜索过,则调用dfs进行搜索
if (!marked[v]){
dfs(G,v);
}
}
}
//基于深度优先搜索,检测图G中是否有环
private void dfs(Digraph G, int v){
//把顶点v表示为已搜索
marked[v] = true;
//把当前顶点进栈
onStack[v] = true;
for(Integer w: G.adj(v)) {
//判断如果当前顶点w没有被搜索过,则继续递归调用dfs方法完成深度优先搜索
if(!marked[w]) {
dfs(G, w);
}
//判断当前顶点w是否已经在栈中,如果已经在栈中,证明当前顶点之前处于正在搜索的状态,那么现在又要搜索一次,证明检测到环了
if (onStack[w]){
hasCycle = true;
return;
}
}
//把当前顶点出栈
onStack[v] = false;
}
//判断当前有向图G中是否有环
public boolean hasCycle(){
return hasCycle;
}
}
基于深度优先的顶点排序
实现思路
如果要把图中的顶点生成线性序列其实是一件非常简单的事,之前我们学习并使用了多次深度优先搜索,我们会发现其实深度优先搜索有一个特点,那就是在一个连通子图上,每个顶点只会被搜索一次,如果我们能在深度优先搜索的基础上,添加一行代码,只需要将搜索的顶点放入到线性序列的数据结构中,我们就能完成这件事。
我们添加了一个栈reversePost用来存储顶点,当我们深度搜索图时,每搜索完毕一个顶点,把该顶点放入到reversePost中,这样就可以实现顶点排序。

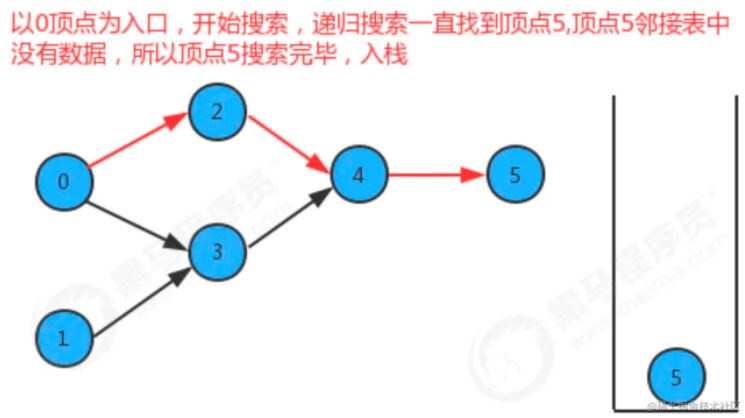



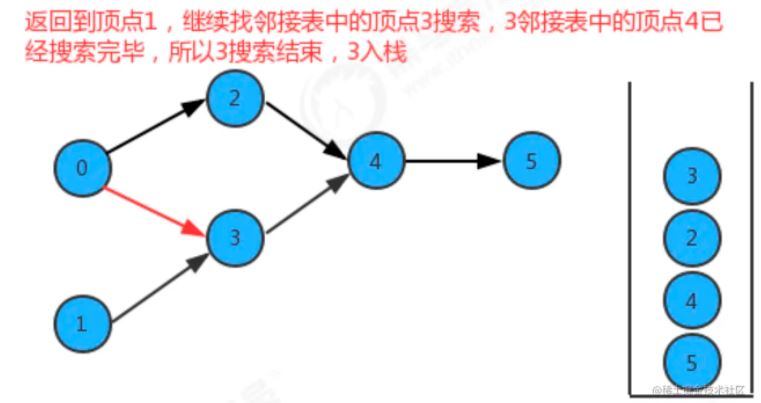


API设计
| 类名 | DepthFirstOrder |
|---|---|
| 成员变量 | 1.private boolean[] marked: 索引代表顶点,值表示当前顶点是否已经被搜索2.private Stack reversePost: 使用栈,存储顶点序列 |
| 构造方法 | DepthFirstOrder(Digraph G):创建一个顶点排序对象,生成顶点线性序列; |
| 成员方法 | 1.private void dfs(Digraph G,int v):基于深度优先搜索,生成顶点线性序列2.public Stack reversePost():获取顶点线性序列 |
代码实现
/**
* 顶点排序
*
* @author alvin
* @date 2022/11/2
* @since 1.0
**/
public class DepthFirstOrder {
//索引代表顶点,值表示当前顶点是否已经被搜索
private boolean[] marked;
//使用栈,存储顶点序列
private Stack<Integer> reversePost;
//创建一个检测环对象,检测图G中是否有环
public DepthFirstOrder(Digraph G){
//初始化marked数组
this.marked = new boolean[G.V()];
//初始化reversePost栈
this.reversePost = new Stack<>();
//遍历图中的每一个顶点,让每个顶点作为入口,完成一次深度优先搜索
for (int v = 0;v<G.V();v++){
if (!marked[v]){
dfs(G,v);
}
}
}
//基于深度优先搜索,把顶点排序
private void dfs(Digraph G, int v){
//标记当前v已经被搜索
marked[v] = true;
//通过循环深度搜索顶点v
for (Integer w : G.adj(v)) {
//如果当前顶点w没有搜索,则递归调用dfs进行搜索
if (!marked[w]){
dfs(G,w);
}
}
//让顶点v进栈
reversePost.push(v);
}
//获取顶点线性序列
public Stack<Integer> reversePost(){
return reversePost;
}
}
拓扑排序
前面已经实现了环的检测以及顶点排序,那么拓扑排序就很简单了,基于一幅图,先检测有没有环,如果没有环,则调用顶点排序即可。
API设计
| 类名 | TopoLogical |
|---|---|
| 成员变量 | 1.private Stack order: 顶点的拓扑排序 |
| 构造方法 | TopoLogical(Digraph G):构造拓扑排序对象 |
| 成员方法 | 1.public boolean isCycle():判断图G是否有环2.public Stack order():获取拓扑排序的所有顶点 |
代码实现
/**
* 拓扑排序
*
* @author alvin
* @date 2022/11/2
* @since 1.0
**/
public class TopoLogical {
//顶点的拓扑排序
private Stack<Integer> order;
//构造拓扑排序对象
public TopoLogical(Digraph G) {
//创建一个检测有向环的对象
DirectedCycle cycle = new DirectedCycle(G);
//判断G图中有没有环,如果没有环,则进行顶点排序:创建一个顶点排序对象
if (!cycle.hasCycle()){
DepthFirstOrder depthFirstOrder = new DepthFirstOrder(G);
order = depthFirstOrder.reversePost();
}
}
//判断图G是否有环
private boolean isCycle(){
return order==null;
}
//获取拓扑排序的所有顶点
public Stack<Integer> order(){
return order;
}
}
测试验证
public class TopoLogicalTest {
@Test
public void test() {
//准备有向图
Digraph digraph = new Digraph(6);
digraph.addEdge(0,2);
digraph.addEdge(0,3);
digraph.addEdge(2,4);
digraph.addEdge(3,4);
digraph.addEdge(4,5);
digraph.addEdge(1,3);
//通过TopoLogical对象堆有向图中的顶点进行排序
TopoLogical topoLogical = new TopoLogical(digraph);
//获取顶点的线性序列进行打印
Stack<Integer> order = topoLogical.order();
StringBuilder sb = new StringBuilder();
while (order.size() != 0) {
sb.append(order.pop()+"->");
};
String str = sb.toString();
int index = str.lastIndexOf("->");
str = str.substring(0,index);
System.out.println(str);
}
}

到此这篇关于Java数据结构之有向图的拓扑排序详解的文章就介绍到这了,更多相关Java有向图 拓扑排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java数据结构之图的两种搜索算法详解
目录 前言 深度优先搜索算法 API设计 代码实现 广度优先搜素算法 API设计 代码实现 案例应用 前言 在很多情况下,我们需要遍历图,得到图的一些性质,例如,找出图中与指定的顶点相连的所有顶点,或者判定某个顶点与指定顶点是否相通,是非常常见的需求. 有关图的搜索,最经典的算法有深度优先搜索和广度优先搜索,接下来我们分别讲解这两种搜索算法. 学习本文前请先阅读这篇文章 [数据结构与算法]图的基础概念和数据模型. 深度优先搜索算法 所谓的深度优先搜索,指的是在搜索时,如果遇到一个结点既有子结点,
-
Java实现拓扑排序的示例代码
目录 铺垫 简介 工作过程 数据结构 拓扑排序 测试样例1 测试样例2 总结 铺垫 有向图:我们这节要讲的算法涉及到有向图,所以我先把有向图的一些概念说一下,文章后面就不做解释啦.首先有向图节点与节点之间是用带箭头的线连接起来的.节点有出度和入度的概念,连线尾部指向的节点出度加1,连线头部,也就是箭头指向的节点入度加1.看下面这个例子,A的入度为0,出度为2,B的入度为1,出度为1,C的入度为1,出度为1,D的入度为2,出度为0. 邻接表:邻接表是存储图结构的一种有效方式,如下图所示,左边节点数
-
Java实现拓扑排序算法的示例代码
目录 拓扑排序原理 1.点睛 2.拓扑排序 3.算法步骤 4.图解 拓扑排序算法实现 1.拓扑图 2.实现代码 3.测试 拓扑排序原理 1.点睛 一个无环的有向图被称为有向无环图.有向无环图是描述一个工程.计划.生产.系统等流程的有效工具.一个大工程可分为若干子工程(活动),活动之间通常有一定的约束,例如先做什么活动,有什么活动完成后才可以开始下一个活动. 用节点表示活动,用弧表示活动之间的优先关系的有向图,被称为 AOV 网. 在 AOV 网中,若从节点 i 到节点 j 存在一条有向路径,则称
-
Java数据结构之图的基础概念和数据模型详解
目录 图的实际应用 图的定义及分类 图的相关术语 图的存储结构 邻接矩阵 邻接表 图的实现 图的API设计 代码实现 图的实际应用 在现实生活中,有许多应用场景会包含很多点以及点点之间的连接,而这些应用场景我们都可以用即将要学习的图这种数据结构去解决. 地图: 我们生活中经常使用的地图,基本上是由城市以及连接城市的道路组成,如果我们把城市看做是一个一个的点,把道路看做是一条一条的连接,那么地图就是我们将要学习的图这种数据结构. 图的定义及分类 定义: 图是由一组顶点和一组能够将两个顶点相连的边组
-
详解Java实现拓扑排序算法
目录 一.介绍 二.拓扑排序算法分析 三.拓扑排序代码实现 一.介绍 百科上这么定义的: 对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边<u,v>∈E(G),则u在线性序列中出现在v之前.通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列.简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序. 为什么会有拓扑排序?拓
-
Java数据结构之有向图设计与实现详解
目录 前言 定义及相关术语 API设计 代码实现 前言 在实际生活中,很多应用相关的图都是有方向性的,最直观的就是网络,可以从A页面通过链接跳转到B页面,那么a和b连接的方向是a->b,但不能说是b->a,此时我们就需要使用有向图来解决这一类问题,它和我们之前学习的无向图,最大的区别就在于连接是具有方向的,在代码的处理上也会有很大的不同. 定义及相关术语 定义: 有向图是一副具有方向性的图,是由一组顶点和一组有方向的边组成的,每条方向的边都连着一对有序的顶点. 出度: 由某个顶点指出的边的个数
-
Java数据结构之图的路径查找算法详解
目录 前言 算法详解 实现 API设计 代码实现 前言 在实际生活中,地图是我们经常使用的一种工具,通常我们会用它进行导航,输入一个出发城市,输入一个目的地 城市,就可以把路线规划好,而在规划好的这个路线上,会路过很多中间的城市.这类问题翻译成专业问题就是: 从s顶点到v顶点是否存在一条路径?如果存在,请找出这条路径. 例如在上图上查找顶点0到顶点4的路径用红色标识出来,那么我们可以把该路径表示为 0-2-3-4. 如果对图的前置知识不了解,请查看系列文章: [数据结构与算法]图的基础概念和数据
-
Java数据结构之有向图的拓扑排序详解
目录 前言 拓扑排序介绍 检测有向图中的环 实现思路 API设计 代码实现 基于深度优先的顶点排序 实现思路 API设计 代码实现 拓扑排序 API设计 代码实现 测试验证 前言 在现实生活中,我们经常会同一时间接到很多任务去完成,但是这些任务的完成是有先后次序的.以我们学习java 学科为例,我们需要学习很多知识,但是这些知识在学习的过程中是需要按照先后次序来完成的.从java基础,到 jsp/servlet,到ssm,到springboot等是个循序渐进且有依赖的过程.在学习jsp前要首先掌
-
java数据结构与算法之希尔排序详解
本文实例讲述了java数据结构与算法之希尔排序.分享给大家供大家参考,具体如下: 这里要介绍的是希尔排序(缩小增量排序法). 希尔排序:通过比较相距一定间隔的元素来工作:各趟比较所用的距离(增量)随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止.是插入排序的一种,是针对直接插入排序算法的改进. 算法思想:先将要排序的序列按某个增量d分成若干个子序列,对每个子序列中全部元素分别进行直接插入排序,然后再用一个较小的增量对它进行分组,在每组中再进行排序.当增量减到1时,整个要排序的数被分成一
-
Java数据结构之优先级队列(PriorityQueue)用法详解
目录 概念 PriorityQueue的使用 小试牛刀(最小k个数) 堆的介绍 优先级队列的模拟实现 Top-k问题 概念 优先级队列是一种先进先出(FIFO)的数据结构,与队列不同的是,操作的数据带有优先级,通俗的讲就是可以比较大小,在出队列的时候往往需要优先级最高或者最低的元素先出队列,这种数据结构就是优先级队列(PriorityQueue) PriorityQueue的使用 构造方法 这里只介绍三种常用的构造方法 构造方法 说明 PriorityQueue() 不带参数,默认容量为11 P
-
Java 数据结构算法Collection接口迭代器示例详解
目录 Java合集框架 Collection接口 迭代器 Java合集框架 数据结构是以某种形式将数据组织在一起的合集(collection).数据结构不仅存储数据,还支持访问和处理数据的操作 在面向对象的思想里,一种数据结构也被认为是一个容器(container)或者容器对象(container object),它是一个能存储其他对象的对象,这里的其他对象常被称为数据或者元素 定义一种数据结构从实质上讲就是定义一个类.数据结构类应该使用数据域存储数据,并提供方法支持查找.插入和删除等操作 Ja
-
Java数据结构之优先级队列(堆)图文详解
目录 一.堆的概念 二.向下调整 1.建初堆 2.建堆 三.优先级队列 1.什么是优先队列? 2.入队列 3.出队列 4.返回队首元素 5.堆的其他TopK问题 总结: 总结 一.堆的概念 堆的定义:n个元素的序列{k1 , k2 , … , kn}称之为堆,当且仅当满足以下条件时: (1)ki >= k2i 且 ki >= k(2i+1) ——大根堆 (2) ki <= k2i 且 ki <= k(2i+1) ——小根堆 简单来说: 堆是具有以下性质的完全二叉树:(1)每个结点的
-
Java数据结构之栈的线性结构详解
目录 一:栈 二:栈的实现 三:栈的测试 四:栈的应用(回文序列的判断) 总结 一:栈 栈是限制插入和删除只能在一个位置上进行的表,此位置就是表的末端,叫作栈顶. 栈的基本操作分为push(入栈) 和 pop(出栈),前者相当于插入元素到表的末端(栈顶),后者相当于删除栈顶的元素. 二:栈的实现 public class LinearStack { /** * 栈的初始默认大小为10 */ private int size = 5; /** * 指向栈顶的数组下标 */ int top = -1
-
Java数据结构之栈与队列实例详解
目录 一,栈 1,概念 2,栈的操作 3,栈的实现 4,实现mystack 二,队列 1,概念 2,队列的实现 3,实现myqueue 栈.队列与数组的区别? 总结 一,栈 1,概念 在我们软件应用 ,栈这种后进先出数据结构的应用是非常普遍的.比如你用浏 览器上网时不管什么浏览器都有 个"后退"键,你点击后可以接访问顺序的逆序加载浏览过的网页. 很多类似的软件,比如 Word Photoshop 等文档或图像编 软件中 都有撤销 )的操作,也是用栈这种方式来实现的,当然不同的
-
java 数据结构之堆排序(HeapSort)详解及实例
1 堆排序 堆是一种重要的数据结构,分为大根堆和小根堆,是完全二叉树, 底层如果用数组存储数据的话,假设某个元素为序号为i(Java数组从0开始,i为0到n-1),如果它有左子树,那么左子树的位置是2i+1,如果有右子树,右子树的位置是2i+2,如果有父节点,父节点的位置是(n-1)/2取整.最大堆的任意子树根节点不小于任意子结点,最小堆的根节点不大于任意子结点. 所谓堆排序就是利用堆这种数据结构的性质来对数组进行排序,在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的性质可知,最大的
-
java图搜索算法之DFS与BFS详解
目录 一.前言 二.深度优先搜索 三.广度优先搜索 四.结语 你好,我是小黄,一名独角兽企业的Java开发工程师. 感谢茫茫人海中我们能够相遇, 俗话说:当你的才华和能力,不足以支撑你的梦想的时候,请静下心来学习, 希望优秀的你可以和我一起学习,一起努力,实现属于自己的梦想. 一.前言 上一篇文章我们提到了关于图的形象化描述方法,不知道大家还有没有印象.没有印象的话,可以去看一下上期的内容 对于图来说,搜索的方法无外乎两种,深度优先搜索(DFS)和广度优先搜索(BFS) 两种搜索算法也不太相同,