python-yml文件读写与xml文件读写
目录
- 一、python-yml文件读写
- 更新yml的数值
- 二、python-xml文件读写
- 寻找 XML 节点
- 修改 XML 数据
- 建立 XML 结构
- XPath 搜索
- XML 排版
一、python-yml文件读写
使用库 :import yaml
安装:
pip install pyyaml
示例:
文件config2.yml
guard_url : 'https://www.xxxx.com' app : chrome_files : 'C:\Program Files\Google\Chrome\Application\chrome.exe' networkTime : 30 title : '公司'
读取yml数据
def read_yml(file):
"""读取yml,传入文件路径file"""
f = open(file,'r',encoding="utf-8") # 读取文件
yml_config = yaml.load(f,Loader=yaml.FullLoader) # Loader为了更加安全
"""Loader的几种加载方式
BaseLoader - -仅加载最基本的YAML
SafeLoader - -安全地加载YAML语言的子集。建议用于加载不受信任的输入。
FullLoader - -加载完整的YAML语言。避免任意代码执行。这是当前(PyYAML5.1)默认加载器调用yaml.load(input)(发出警告后)。
UnsafeLoader - -(也称为Loader向后兼容性)原始的Loader代码,可以通过不受信任的数据输入轻松利用。"""
return yml_config
打印yml内容
yml_info=read_yml('config.yml')
print(yml_info['guard_url'])
print(yml_info['app'])
print((yml_info['app'])['chrome_files'])
"""
https:xxxx.com
{'chrome_files': 'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe'}
C:\Program Files\Google\Chrome\Application\chrome.exe
"""
插入到yml数据
def write_yml(file,data):
# 写入数据:
with open(file, "a",encoding='utf-8') as f:
# data数据中有汉字时,加上:encoding='utf-8',allow_unicode=True
f.write('\n') # 插入到下一行
yaml.dump(data, f, encoding='utf-8', allow_unicode=True)
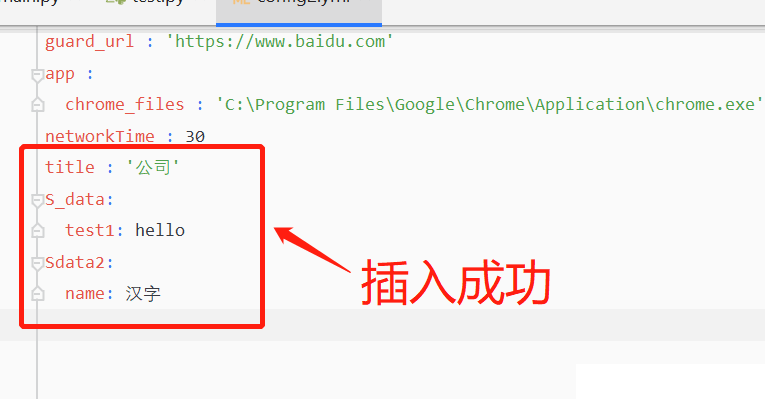
data = {"S_data": {"test1": "hello"}, "Sdata2": {"name": "汉字"}}
write_yml('config2.yml',data=data)
更新yml的数值
逻辑是完整读取然后更新数值后在完整写入。
def read_yml(file):
"""读取yml,传入文件路径file"""
f = open(file, 'r', encoding="utf-8") # 读取文件
yml_config = yaml.load(f, Loader=yaml.FullLoader) # Loader为了更加安全
return yml_config
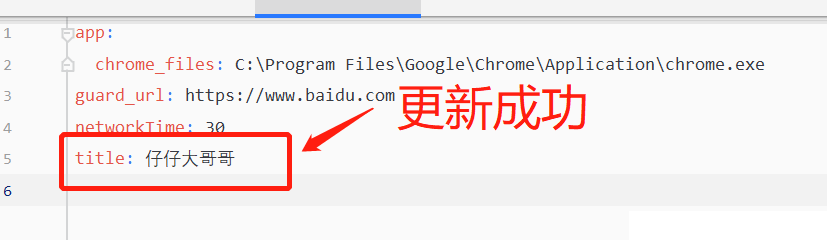
def updata_yaml(file):
"""更新yml的数值"""
old_data=read_yml(file) #读取文件数据
old_data['title']='仔仔大哥哥' #修改读取的数据(
with open(file, "w", encoding="utf-8") as f:
yaml.dump(old_data,f,encoding='utf-8', allow_unicode=True)
updata_yaml('config2.yml')
二、python-xml文件读写
使用库 :import xml
安装:系统自带
示例:
如果只是配置文件尽量使用yml来读写,
读取xml文件:
config.xml
<config>
<id>905594711349653</id>
<sec>0tn1jeerioj4x6lcugdd8xmzvm6w42tp</sec>
</config>
import xml.dom.minidom
dom = xml.dom.minidom.parse('config.xml')
root = dom.documentElement
def xml(suser):
suser = root.getElementsByTagName(suser)
return suser[0].firstChild.data
id = xml('id') # 进程名
print("打印ID:"+id)
"""
打印ID:905594711349653
"""
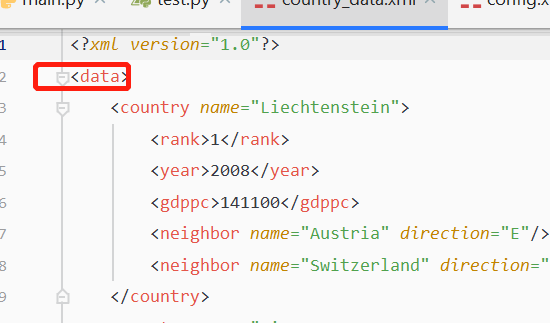
进阶country_data.xml
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
这里产生的 root 是一个 Element 物件,代表 XML 的根节点,每一个 Element 物件都有 tag 与 attrib 两个属性:
import xml.etree.ElementTree as ET
# 从文件加载并解析 XML 数据
tree = ET.parse('country_data.xml')
root = tree.getroot()
print(root.tag) # 打印根节点名称
print(root.attrib) # 打印根节点属性
# for 循环可以列出所有的子节点:
# 子节点与属性
for child in root:
print(child.tag, child.attrib)
"""
data
{} # data 没有属性所以返回空
country {'name': 'Liechtenstein'}
country {'name': 'Singapore'}
country {'name': 'Panama'}
"""
也可以使用索引的方式存取任意的节点,透过 text 属性即可取得节点的内容:
print(root[0][1].text) """ 2008 """
可透过 get 直接取得指定的属性值:
# 取得指定的属性值
print(root[0][3].get('name'))
"""
Austria
"""
寻找 XML 节点
iter 可以在指定节点之下,以递回方式搜索所有子节点:
# 搜索所有子节点
for neighbor in root.iter('neighbor'):
print(neighbor.attrib)
"""
{'name': 'Austria', 'direction': 'E'}
{'name': 'Switzerland', 'direction': 'W'}
{'name': 'Malaysia', 'direction': 'N'}
{'name': 'Costa Rica', 'direction': 'W'}
{'name': 'Colombia', 'direction': 'E'}
"""
findall 与 find 则是只从第一层子节点中搜索(不包含第二层以下),findall 会传回所有结果,而 find 则是只传回第一个找到的节点:
# 只从第一层子节点中搜索,传回所有找到的节点
for country in root.findall('country'):
# 只从第一层子节点中搜索,传回第一个找到的节点
rank = country.find('rank').text
# 取得节点指定属性质
name = country.get('name')
print(name, rank)
"""
Liechtenstein 1
Singapore 4
Panama 68
"""
修改 XML 数据
XML 节点的数据可以透过 Element.text 来修改,而属性值则可以使用 Element.set() 来指定,若要将修改的结果写入 XML 文件,则可使用 ElementTree.write():
# 寻找 rank 节点
for rank in root.iter('rank'):
# 将 rank 的数值加 1
new_rank = int(rank.text) + 1
# 设置新的 rank 值
rank.text = str(new_rank)
# 增加一个 updated 属性值
rank.set('updated', 'yes')
# 写入 XML 文件
tree.write('output.xml')
编辑之后的 XML 文件内容会像这样:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
若要移除 XML 的节点,可以使用 Element.remove():
# 在第一层子节点钟寻找 country 节点
for country in root.findall('country'):
# 取得 rank 数值
rank = int(country.find('rank').text)
# 若 rank 大于 50,则移除此节点
if rank > 50:
root.remove(country)
# 写入 XML 文件
tree.write('output.xml')
移除节点之后的 XML 文件内容会像这样:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
</data>
建立 XML 结构
若要建立一个全新的 XML 结构,可以使用 Element 建立根节点,再以 SubElement() 加入子节点:
# 建立新的 XML 结构
orders = ET.Element('orders')
# 新增节点
order1 = ET.SubElement(orders, 'order')
order1.text = "My Order 1"
order1.set("new", "yes")
# 新增节点
order2 = ET.SubElement(orders, 'order')
order2.text = "My Order 2"
order2.set("new", "no")
# 输出 XML 原始数据
ET.dump(orders)
<orders><order new="yes">My Order 1</order><order new="no">My Order 2</order></orders>
XPath 搜索
XPath 可以让用户在 XML 结构中以较复杂的条件进行搜索,以下是一些常见的范例。
# 顶层节点
root.findall(".")
# 寻找「顶层节点 => country => neighbor」这样结构的节点
root.findall("./country/neighbor")
# 寻找 name 属性为 Singapore,且含有 year 子节点的节点
root.findall(".//year/..[@name='Singapore']")
# 寻找父节点 name 属性为 Singapore 的 year 节点
root.findall(".//*[@name='Singapore']/year")
# 寻找在同一层 neighbor 节点中排在第二位的那一个
root.findall(".//neighbor[2]")
XML 排版
若要对一般的 XML 文件内容进行自动排版,可以使用 lxml 模组的 etree:
import lxml.etree as etree
# 读取 XML 文件
root = etree.parse("country_data.xml")
# 输出排版的 XML 数据
print(etree.tostring(root, pretty_print=True, encoding="unicode"))
# 将排版的 XML 数据写入文件
root.write("pretty_print.xml", encoding="utf-8")
到此这篇关于python-yml文件读写与xml文件读写的文章就介绍到这了,更多相关 python文件读写内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python练习之读取XML节点和属性值的方法
面试题 有一个test.xml文件,要求读取该文件中products节点的所有子节点的值以及子节点的属性值. test.xml文件: <!-- products.xml --> <root> <products> <product uuid='1234'> <id>10000</id> <name>苹果</name> <price>99999</price> </product&g
-
三分钟教会你用Python+OpenCV批量裁剪xml格式标注的图片
目录 前言 xml文件格式 代码思想 完整代码 效果展示 总结 前言 在目标检测中,数据集常常使用labelimg标注,会生成xml文件.本文旨在根据xml标注文件来裁剪目标,以达到去除背景信息的目的. xml文件格式 以下是一个标注好的图片生成的xml文件.具体含义见代码注释. <annotation> <!--xml所属文件夹--> <folder>JPEGImages</folder> <!--对应图片所属文件夹--> <filena
-
python处理xml文件操作详解
目录 1.python 操作xml的方式介绍 2.ElementTree模块 3.解析xml格式字符串并获取根节点 4.读取节点内容,getroot() 5.通标标签名直接获取标签(find,findall) 6.全文搜索标签名(类似xpath路径查找标签) 7.修改节点 8.删除节点 9.构建文件 方式1 (Element) 方式2 (makeelement) 方式3 1.python 操作xml的方式介绍 查看全部包含“三种⽅法: ⼀是xml.dom. * 模块,它是W3CDOMAPI的实现
-
python实现修改xml文件内容
XML 被设计用来传输和存储数据. HTML 被设计用来显示数据. XML 指可扩展标记语言(eXtensible Markup Language). 可扩展标记语言(英语:Extensible Markup Language,简称:XML)是一种标记语言,是从标准通用标记语言(SGML)中简化修改出来的.它主要用到的有可扩展标记语言.可扩展样式语言(XSL).XBRL和XPath等. 直接上代码,拿来就可用. 首先需要准备一个测试xml文件,我这个文件名字为text.xml:
-
python批量修改xml文件中的信息
目录 项目场景: 问题描述: 分析: 解决方案: 总结 项目场景: 在做目标检测时,重新进行标注会耗费大量的时间,如果能够批量对xml中的信息进行修改,那么将会节省大量的时间,接下来将详细介绍如何修改标注文件xml中的相关信息. 问题描述: 例如:当我有一批标注好的xml文件,文件格式如下图所示 : <?xml version='1.0' encoding='us-ascii'?> <annotation> <folder>VOC2012</folder>
-
python操作XML格式文件的一些常见方法
目录 前言 1. 读取文件和内容 2.读取节点数据 3.修改和删除节点 4.构建文档 方式一ET.Element() 补充:XML文件和JSON文件互转 1.XML文件转为JSON文件 2.JSON文件转换为XML文件 总结 前言 可扩展标记语言,是一种简单的数据存储语言,XML被设计用来传输和存储数据 存储,可用来存放配置文件,例:java配置文件 传输,网络传输以这种格式存在,例:早期ajax传输数据等 <data> <country name="Liechtenstein
-
python-yml文件读写与xml文件读写
目录 一.python-yml文件读写 更新yml的数值 二.python-xml文件读写 寻找 XML 节点 修改 XML 数据 建立 XML 结构 XPath 搜索 XML 排版 一.python-yml文件读写 使用库 :import yaml 安装: pip install pyyaml 示例: 文件config2.yml guard_url : 'https://www.xxxx.com' app : chrome_files : 'C:\Program Files\Google\Ch
-
Python使用sax模块解析XML文件示例
本文实例讲述了Python使用sax模块解析XML文件.分享给大家供大家参考,具体如下: XML样例: <?xml version="1.0"?> <collection shelf="New Arrivals"> <movie title="Enemy Behind"> <type>War, Thriller</type> <format>DVD</format>
-
Python批量将csv文件转化成xml文件的实例
一.前言 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本).纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据.CSV文件由任意数目的记录组成,记录间以某种换行符分隔:每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符.通常,所有记录都有完全相同的字段序列,通常都是纯文本文件. 可扩展标记语言,标准通用标记语言的子集,简称XML.是一种用
-
用asp实现把文件打包成Xml文件包,带解包的ASP工具附下载
把文件打包成Xml文件包,带解包的ASP工具! 把网站源码全部打包到Xml文件里面,生成 updata.xml 文件,把xml文件上传到空间里面 然后通过 install.asp文件将文件全部释放出来. 就和z-blog的 自动安装包一样的功能呵呵. 代码是落伍的一位兄弟写的,不过代码好像有错误,这个是我参考他的 修改过了,可以正常运行!~~ 此代码可以应用到 asp程序的 自动升级服务上面.具体怎么来实现,欢迎探讨!~~ 就在下面回帖探讨!~~~ 不用设定打包目录版,需要设定打包目录版 这两个
-
C#从文件流读取xml文件到DataSet并显示的方法
本文实例讲述了C#从文件流读取xml文件到DataSet并显示的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: DataSet ds= new DataSet (); FileStream fs = new FileStream (Server.MapPath=("somexml.xml"),FileMode.Open,FileAccess.Read); ds.ReadXml (fs); DataGrid1.DataSource = ds; DataGrid1.D
-
Android实现向本地写入一个XML文件和解析XML文件
在网络存储过程中有很多时候会遇到XML文件解析和使用XML保存一些信息,解析XML文件用的比较多的方法是pull解析和SAX解析,但是我一般只用pull解析,下面就向cd卡写入一个XML文件,然后再使用pull解析的方法对文件进行解析. 一.向SD卡中写入一个XML文件: /** * 向SD卡写入一个XML文件 * * @param v */ public void savexml(View v) { try { File file = new File(Environment.getExter
-
Java中使用DOM4J生成xml文件并解析xml文件的操作
目录 一.前言 二.准备依赖 三.生成xml文件生成标准展示 四.解析xml文件 五.总结 一.前言 现在有不少需求,是需要我们解析xml文件中的数据,然后导入到数据库中,当然解析xml文件也有好多种方法,小编觉得还是DOM4J用的最多最广泛也最好理解的吧.小编也是最近需求里遇到了,就来整理一下自己的理解,只适合刚刚学习的,一起理解!今天我们把解析xml文件和生成xml文件在一起来展示. 二.准备依赖 <dependency> <groupId>dom4j</groupId&
-
php获取本地图片文件并生成xml文件输出具体思路
复制代码 代码如下: <?php $dir="upload/"; $dir_res=opendir($dir); $fileFormat=array(0=>".jpg",1=>".gif",2=>".png",3=>".bmp"); $xmlData = ""; $xmlData .= "<photos>\n"; while(
-
C++、Qt分别读写xml文件的方法实例
目录 XML语法 C++使用tinyxml读写xml Qt读写xml 总结 XML语法 第一行是XML文档声明,<>内的代表是元素,基本语法如以下所示.C++常见的是使用tiny库读写,Qt使用自带的库读写: <?xml version="1.0" encoding="utf-8" standalone="yes" ?> <根元素> <元素 属性名="属性值" 属性名="属性
-
Python实现XML文件解析的示例代码
1. XML简介 XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据,已经日趋成为当前许多新生技术的核心,在不同的领域都有着不同的应用.它是web发展到一定阶段的必然产物,既具有SGML的核心特征,又有着HTML的简单特性,还具有明确和结构良好等许多新的特性. test.XML文件 <?xml version="1.0" encoding="utf-8"?> <catalog> <m