Project Reactor源码解析publishOn使用示例
目录
- 功能分析
- 代码示例
- prefetch
- delayError
- 源码分析
- Flux#publishOn()
- Flux#subscribe()
- FluxPublishOn#subscribeOrReturn()
- FluxPublishOn#onSubscribe()
- 非融合
- FluxPublishOn#onNext()
- FluxPublishOn#trySchedule()
- FluxPublishOn#run()
- FluxPublishOn#runAsync()
- FluxPublishOn#checkTerminated()
- FluxPublishOn#onComplete()
- 小结
- 同步队列融合
- SynchronousSubscription#requestFusion()
- FluxPublishOn#request()
- FluxPublishOn#runSync()
- 小结
- 异步队列融合
- WindowPredicateMain#requestFusion()
- FluxPublishOn#onNext()
- 总结
功能分析
相关示例源码:github.com/chentianmin…
public final Flux<T> publishOn(Scheduler scheduler, boolean delayError, int prefetch)

在onNext()、onComplete()、onError()方法进行线程切换,publishOn()使得它下游的消费阶段异步执行。
- scheduler:线程切换的调度器,
Scheduler用来生成实际执行异步任务的Worker。 - delayError:是否延时转发
Error。如果为true,当收到上游的Error时,会等队列中的元素消费完毕后再向下游转发Error。否则会立即转发Error,可能导致队列中的元素丢失。默认为true。 - prefetch:预取元素的数量,同时也是队列的容量。默认值为
Queues.SMALL_BUFFER_SIZE,该值通过配置进行修改。

代码示例
prefetch
/**
* 每隔delayMillis生产一个元素
*/
protected Flux<Integer> delayPublishFlux(int delayMillis, int startInclusive, int endExclusive) {
return Flux.create(fluxSink -> {
IntStream.range(startInclusive, endExclusive)
.forEach(i -> {
// 同步next
sleep(delayMillis);
logInt(i, "生产");
fluxSink.next(i);
});
fluxSink.complete();
});
}
@Test
public void testPreFetch() {
delayPublishFlux(1000, 1, 5)
.doOnRequest(i -> logLong(i, "request"))
.publishOn(Schedulers.boundedElastic(), 2)
.subscribe(i -> logInt(i, "消费"));
sleep(10000);
}

每次会都向上游请求2个元素。另外还能发现,从第二个request开始,线程发生了切换。
delayError
/**
* 每隔delayMillis生产一个元素,最后发送Error
*/
protected Flux<Integer> delayPublishFluxError(int delayMillis, int startInclusive, int endExclusive) {
return Flux.create(fluxSink -> {
IntStream.range(startInclusive, endExclusive)
.forEach(i -> {
// 同步next
sleep(delayMillis);
logInt(i, "生产");
fluxSink.next(i);
});
fluxSink.error(new RuntimeException("发布错误!"));
});
}
@Test
public void testDelayError() {
delayPublishFluxError(500, 1, 5)
.publishOn(Schedulers.boundedElastic())
// 只是为了消费慢一点
.doOnNext(i -> sleep(1000))
.subscribe(i -> logInt(i, "消费"));
sleep(10000);
}

元素消费完才触发Error!
@Test
public void testNotDelayError() {
delayPublishFluxError(500, 1, 5)
.publishOn(Schedulers.boundedElastic(), false, 256)
// 只是为了消费慢一点
.doOnNext(i -> sleep(1000))
.subscribe(i -> logInt(i, "消费"));
sleep(10000);
}

元素还没消费完就触发Error!
源码分析
首先看一下publishOn()操作符在装配阶段做了什么,直接查看Flux#publishOn()源码。
Flux#publishOn()

publishOn()装配阶段重点是创建了FluxPublishOn对象。
接下来,我们分析订阅阶段发生了什么。一个Publisher在订阅的时候调用的是其subscribe()方法,因此我们继续看Flux#subscribe()源码。
Flux#subscribe()

在Flux#subscribe()方法的实现中,如果上游Publisher是OptimizableOperator类型,实际的Subscriber是通过调用该InternalFluxOperator#subscribeOrReturn()方法返回的。如果返回值为null,直接return。
对于publishOn()操作符来说,装配阶段创建的FluxPublishOn就是OptimizableOperator类型。所以继续查看FluxPublishOn#subscribeOrReturn()源码。
FluxPublishOn#subscribeOrReturn()

可以看到,方法返回的是PublishOnSubscriber,它包装了原始的Subscriber。
在后续的订阅阶段一定会调用其onSubscribe()方法,在运行阶段一定会调用其onNext()方法。我们先看FluxPublishOn#onSubscribe()源码。
FluxPublishOn#onSubscribe()

在onSubscribe()实现中,分为同步队列融合、异步队列融合以及非融合方式处理。
如果上游的Subscription是QueueSubscription类型,则会进行队列融合。具体采用同步还是异步,取决于该QueueSubscription#requestFusion()实现。
- 同步队列融合:复用当前队列,继续调用下游
onSubscribe()方法,但不会继续调用上游request()方法。 - 异步队列融合:复用当前队列,然后继续调用下游
onSubscribe()以及上游request()方法,请求数量是prefetch。 - 非融合:创建一个新的队列,然后继续调用下游
onSubscribe()以及上游request()方法,请求数量是prefetch。
接下来,我们从源码角度分别介绍上述三种方式的处理逻辑,首先介绍非融合方式。
非融合
先看如下代码示例,该代码会以非融合方式执行。
@Test
public void testNoFuse() {
delayPublishFlux(1000, 1, 5)
.publishOn(Schedulers.boundedElastic())
.subscribe(i -> logInt(i, "消费"));
sleep(10000);
}

间隔1s生产消费元素!
在消费阶段,一定会调用FluxPublishOn#onNext()方法。
FluxPublishOn#onNext()

我们重点关注非融合方式执行逻辑,其实只做了2件事:
- 将下发的元素添加到队列中,该队列就是
onSubscribe()阶段创建的新队列。 - 调用
trySchedule()方法进行调度。
继续看FluxPublishOn#trySchedule()源码。
FluxPublishOn#trySchedule()

这里其实就是交由woker异步执行,后续会执行FluxPublishOn.run()方法。
FluxPublishOn#run()

在run()方法执行的时候,分为3段逻辑:
- 如果是输出融合,执行
runBackfused()方法。 - 如果是同步队列融合,执行
runSync()方法。 - 否则,执行
runAsync()方法。
对于当前例子,实际执行的是runAsync()方法,继续查看其源码。
FluxPublishOn#runAsync()
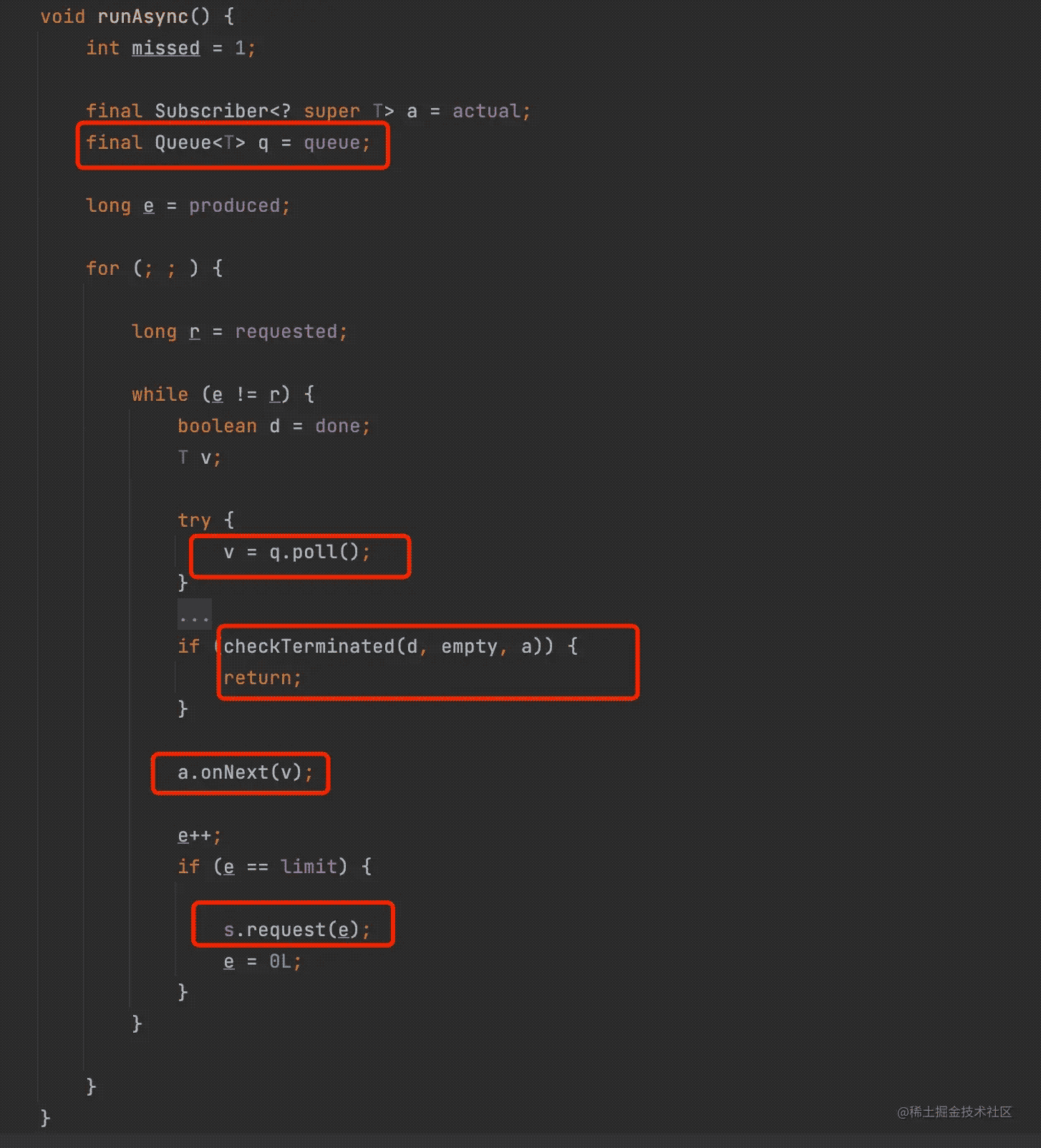
runAsync()做的事情比较简单,就是排空队列中的元素下发给下游。同时在这里会继续调用request()向上游请求数据,这也是前面说的从第二个request()开始会进行线程切换的原因。
另外这里还会调用checkTerminated(),检查终止情况。
FluxPublishOn#checkTerminated()

如果delayError=true,必须当前队列为空是才会转发Error。如果delayError=false,则直接转发Error。继续查看onComplete()方法。
FluxPublishOn#onComplete()

如果未结束,将done标记设置为true,然后再次调用trySchedule()进行调度。后续再被调度到的时候,如果队列已经排空,才会调用下游onComplete(),触发完成。
小结
简单总结一下非融合执行过程:
在onSubscribe()时创建一个队列,在onNext()时将上游下发的元素添加到队列中,然后异步排空队列中的元素,继续下发给下游。
同步队列融合
以下代码会以同步队列融合方式执行。
@Test
public void testSyncFuse() {
Flux.just(1, 2 ,3, 4, 5)
.publishOn(Schedulers.boundedElastic())
.subscribe(this::logInt);
sleep(10000);
}
因为Flux.just()对应的Subscription是SynchronousSubscription,其requestFusion()方法实现如下:
SynchronousSubscription#requestFusion()

此时返回的是SYNC,执行同步队列融合。
前面提到过,同步队列融合会复用当前队列,继续调用下游onSubscribe()方法,但不会继续调用上游request()方法。
这意味着,此时FluxPublishOn#onNext()和FluxPublishOn#onComplete()方法并不会调用。但是FluxPublishOn#request()依然会被下游调用到。
FluxPublishOn#request()

在request()方法中还是会调用trySchedule(),后续会异步调用runSync()方法(前面已经分析了)。
对于非融合方式,trySchedule()也会执行,只是这次调度的时候,队列中还没有数据被添加进去。
FluxPublishOn#runSync()

runSync()实现上runAsync()差不多,也是排空队列的元素,继续下发给下游。不同的点是少了request()调用,以及取消完成控制有差异。
小结
简单总结一下同步队列融合执行过程:
在onSubsrribe()时直接复用上游QueueSubscription作为队列,不会调用上游request()请求数据,在自身request()时异步排空队列中的元素,继续下发给下游。
异步队列融合
以下代码会以异步队列融合方式执行。
@Test
public void testAsyncFuse() {
Flux.just(1, 2, 3, 4, 5)
.windowUntil(i -> i % 3 == 0)
.publishOn(Schedulers.boundedElastic())
.flatMap(Function.identity())
.subscribe(this::logInt);
sleep(10000);
}
因为windowUntil()对应的Subscription是WindowPredicateMain,其requestFusion()方法实现如下:
WindowPredicateMain#requestFusion()

此时返回ASYNC,执行异步队列融合。接下来再看一下FluxPublishOn#onNext()源码。
FluxPublishOn#onNext()

注意,此时onNext()方法参数是null,表明上游并没有真正下发元素,可以将其看做是一个触发Worker调度的信号。后续还是会异步执行runAsync()方法,这里就不再分析了。
这其实也很容易理解:异步队列融合直接复用了上游的QueueSubscription作为队列,真正的数据应该由这个队列下发。
总结
简单总结一下同步队列融合执行过程:
在onSubsrribe()时直接复用上游QueueSubscription作为队列,在onNext()时接收上游信号,异步排空队列中的元素,继续下发给下游。
非融合、同步队列融合、异步队列融合比较如下:

以上就是Project Reactor源码解析publishOn使用示例的详细内容,更多关于Project Reactor publishOn的资料请关注我们其它相关文章!
相关推荐
-
Java Reactor反应器模式使用方法详解
Reactor反应器模式 到目前为止,高性能网络编程都绕不开反应器模式.很多著名的服务器软件或者中间件都是基于反应器模式实现的,如Nginx.Redis.Netty. 反应器模式是高性能网络编程的必知.必会的模式. Reactor简介 反应器模式由Reactor反应器线程.Handlers处理器两大角色组成: (1)Reactor反应器线程的职责:负责响应IO事件,并且分发到Handlers处理器. (2)Handlers处理器的职责:非阻塞的执行业务处理逻辑. 从上面的反应器模式定义,看不出这
-

Java IO篇之Reactor 网络模型的概念
目录 一.什么是 Reactor 模型: 二.Reactor 模型的分类: 1.单 Reactor 单线程模型: 1.1.处理流程: 1.2.优缺点: 2.单 Reactor 多线程模型: 2.1.处理流程: 2.2.优缺点: 3.主从 Reactor 多线程模型: 3.1.处理流程: 3.2.优缺点: 4.Reactor 优缺点: 一.什么是 Reactor 模型: The reactor design pattern is an event handling pattern for hand
-
Java反应式框架Reactor中的Mono和Flux
1. 前言 最近写关于响应式编程的东西有点多,很多同学反映对Flux和Mono这两个Reactor中的概念有点懵逼.但是目前Java响应式编程中我们对这两个对象的接触又最多,诸如Spring WebFlux.RSocket.R2DBC.我开始也对这两个对象头疼,所以今天我们就简单来探讨一下它们. 2. 响应流的特点 要搞清楚这两个概念,必须说一下响应流规范.它是响应式编程的基石.他具有以下特点: 响应流必须是无阻塞的.响应流必须是一个数据流.它必须可以异步执行.并且它也应该能够处理背压. 背压是
-
Java中多线程Reactor模式的实现
目录 1. 主服务器 2.IO请求handler+线程池 3.客户端 多线程Reactor模式旨在分配多个reactor每一个reactor独立拥有一个selector,在网络通信中大体设计为负责连接的主Reactor,其中在主Reactor的run函数中若selector检测到了连接事件的发生则dispatch该事件. 让负责管理连接的Handler处理连接,其中在这个负责连接的Handler处理器中创建子Handler用以处理IO请求.这样一来连接请求与IO请求分开执行提高通道的并发量.同时
-
Project Reactor源码解析publishOn使用示例
目录 功能分析 代码示例 prefetch delayError 源码分析 Flux#publishOn() Flux#subscribe() FluxPublishOn#subscribeOrReturn() FluxPublishOn#onSubscribe() 非融合 FluxPublishOn#onNext() FluxPublishOn#trySchedule() FluxPublishOn#run() FluxPublishOn#runAsync() FluxPublishOn#ch
-
Go Excelize API源码解析GetSheetFormatPr使用示例
目录 一.Go-Excelize简介 二.GetSheetFormatPr 一.Go-Excelize简介 Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准. 可以使用它来读取.写入由 Microsoft Excel™ 2007 及以上版本创建的电子表格文档. 支持 XLAM / XLSM / XLSX / XLTM / XLTX 等多种文档格式,高度兼容带有样式.图片(表).透视表.切片器等复杂组
-
JAVA Vector源码解析和示例代码
第1部分 Vector介绍Vector 是矢量队列,它是JDK1.0版本添加的类.继承于AbstractList,实现了List, RandomAccess, Cloneable这些接口.Vector 继承了AbstractList,实现了List:所以,它是一个队列,支持相关的添加.删除.修改.遍历等功能.Vector 实现了RandmoAccess接口,即提供了随机访问功能.RandmoAccess是java中用来被List实现,为List提供快速访问功能的.在Vector中,我们即可以通过
-
Laravel源码解析之路由的使用和示例详解
前言 我的解析文章并非深层次多领域的解析攻略.但是参考着开发文档看此类文章会让你在日常开发中更上一层楼. 废话不多说,我们开始本章的讲解. 入口 Laravel启动后,会先加载服务提供者.中间件等组件,在查找路由之前因为我们使用的是门面,所以先要查到Route的实体类. 注册 第一步当然还是通过服务提供者,因为这是laravel启动的关键,在 RouteServiceProvider 内加载路由文件. protected function mapApiRoutes() { Route::pref
-
JetCache 缓存框架的使用及源码解析(推荐)
目录 一.简介 为什么使用缓存? 使用场景 使用规范 二.如何使用 引入maven依赖 添加配置 配置说明 注解说明 @EnableCreateCacheAnnotation @EnableMethodCache @CacheInvalidate @CacheUpdate @CacheRefresh @CachePenetrationProtect @CreateCache 三.源码解析 项目的各个子模块 常用注解与变量 缓存API Cache接口 AbstractCache抽象类 Abstra
-
Android 中 SwipeLayout一个展示条目底层菜单的侧滑控件源码解析
由于项目上的需要侧滑条目展示收藏按钮,记得之前代码家有写过一个厉害的开源控件 AndroidSwipeLayout 本来准备直接拿来使用,但是看过 issue 发现现在有不少使用者反应有不少的 bug ,而且代码家现在貌似也不进行维护了.故自己实现了一个所要效果的一个控件.因为只是实现我需要的效果,所以大家也能看到,代码里有不少地方我是写死的.希望对大家有些帮助.而且暂时也不需要 AndroidSwipeLayout 大而全的功能,算是变相给自己做的项目精简代码了. 完整示例代码请看:GitHu
-
Python中getpass模块无回显输入源码解析
本文主要讨论了python中getpass模块的相关内容,具体如下. getpass模块 昨天跟学弟吹牛b安利Python标准库官方文档的时候偶然发现了这个模块.仔细一看内容挺少的,只有两个主要api,就花了点时间阅读了一下源码,感觉挺实用的,在这安利给大家. getpass.getpass(prompt='Password: ', stream=None) 调用该函数可以在命令行窗口里面无回显输入密码.参数prompt代表提示字符串,默认是'Password: '.在Unix系统中,strea
-
Android源码解析之截屏事件流程
今天这篇文章我们主要讲一下Android系统中的截屏事件处理流程.用过android系统手机的同学应该都知道,一般的android手机按下音量减少键和电源按键就会触发截屏事件(国内定制机做个修改的这里就不做考虑了).那么这里的截屏事件是如何触发的呢?触发之后android系统是如何实现截屏操作的呢?带着这两个问题,开始我们的源码阅读流程. 我们知道这里的截屏事件是通过我们的按键操作触发的,所以这里就需要我们从android系统的按键触发模块开始看起,由于我们在不同的App页面,操作音量减少键和电
-
.NET Core源码解析配置文件及依赖注入
写在前面 上篇文章我给大家讲解了ASP.NET Core的概念及为什么使用它,接着带着你一步一步的配置了.NET Core的开发环境并创建了一个ASP.NET Core的mvc项目,同时又通过一个实战教你如何在页面显示一个Content的列表.不知道你有没有跟着敲下代码,千万不要做眼高手低的人哦. 这篇文章我们就会设计一些复杂的概念了,因为要对ASP.NET Core的启动及运行原理.配置文件的加载过程进行分析,依赖注入,控制反转等概念的讲解等. 俗话说,授人以鱼不如授人以渔,所以文章旨在带着大
-
源码解析JDK 1.8 中的 Map.merge()
Map 中ConcurrentHashMap是线程安全的,但不是所有操作都是,例如get()之后再put()就不是了,这时使用merge()确保没有更新会丢失. 因为Map.merge()意味着我们可以原子地执行插入或更新操作,它是线程安全的. 一.源码解析 default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction) { Objects.requireNonNu