LRU LFU TinyLFU缓存算法实例详解
目录
- 简介
- 一、LRU和LFU算法
- LRU算法
- LFU算法
- 小结:
- 二、TinyLFU
- 三、Window-TinyLFU
简介
前置知识
知道什么是缓存
听完本节公开课,你可以收获
- 掌握朴素LRU、LFU算法的思想以及源码
- 掌握一种流式计数的算法 Count-Min Sketch
- 手撕TinyLFU算法、分析Window-TinyLFU源码
一、LRU和LFU算法
LRU算法
LRU Least Recently Used 最近最少使用算法
LRU 算法的思想是如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。所以,当指定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
也就是淘汰数据的时候,只看数据在缓存里面待的时间长短这个维度。
这样子做有什么缺点呢?我们来看个例子
无法复制加载中的内容
按照LRU算法进行访问和数据淘汰,10次访问的结果如下图所示
无法复制加载中的内容
10次访问结束后,缓存中剩下的数据是b、c、d三个元素,这个显然不太合理。
直观上讲,为什么说他不合理,是因为明明a是被频繁访问的数据,最终却被淘汰掉了。所以如果要改进这个算法,我们希望的是能够记录每个元素的访问频率信息,访问频率最低的那个才是最应该被淘汰的那个。
恭喜你,这就是LFU的规则。
在开始LFU之前,我们先来看一下LRU的代码怎么写。
有句古话讲得好:缓存就是Map + 淘汰策略。Map的作用是提供快速访问,淘汰策略是缓存算法的灵魂,决定了命中率的高低。根据对于LRU的描述,我们需要一个东西(术语叫做数据结构)来记录数据被访问的先后顺序,这里我们可以选择链表。
打开IDE,迅速写下第一行代码:
type LRU struct {
data map[string]*list.Element
cap int
list *list.List
}
解释一下为什么需要这几个变量, cap 是缓存中可以存放的数据个数,也就是缓存的容量上限。data就是Map。List我们用来记录数据的先后访问顺序,每次访问,都把本次访问的节点移动到链表中的头部。这样子整个链表就会按照近期的访问记录来排序了。
func (lru *LRU) add(k, v string) {
if Map中存有这条Key {
替换Map中的Value值
将链表中的对应节点移到最前面
} else {
if 已经达到缓存容量上限 {
获取链表尾部节点的Key,并从Map中删除
移除链表尾部的Node
}
创建要插入的新节点
将新节点插入到链表头部
放入Map中
}
}
func (lru *LRU) get(k string) string {
if Map中存有这条Key {
返回查询到的Value
将对应节点移动到链表头部
} else {
返回 空
}
}
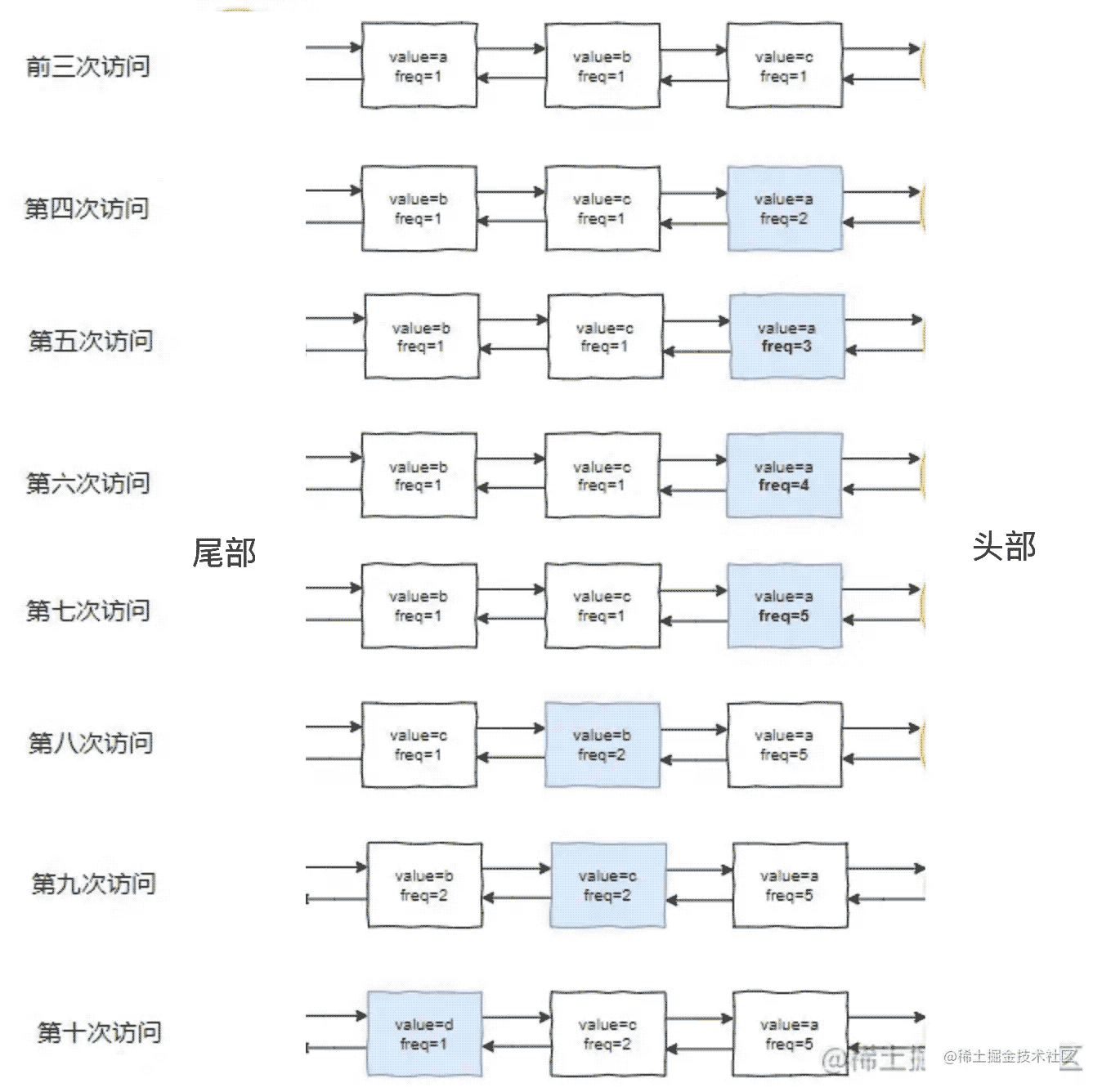
LFU算法
我们已经成功的写出了LRU算法(伪代码),接下来尝试自己写一下LFU算法。首先我们知道LFU算法比LRU多了什么,LFU需要记录每条数据的访问次数信息,并且按照访问次数从高到低排序,访问次数用什么来记录呢?
只需要在链表节点中增加一个访问频率Frequency,就可以了,这个Frequency可以使用int来存储。同时排序的规则稍加变动,不是把最近访问的放到最前面,而是按照访问频率插入到对应位置即可。如果频率相同,再按照LRU的规则,比较谁是最新访问的。
暂时无法在文档外展示此内容
小结:
讲完了LRU和LFU,我们来看一下他们有啥优缺点。
LRU
优点:实现简单、可以很快的适应访问模式的改变
缺点:对于热点数据的命中率可能不如LFU
LFU
优点:对于热点数据命中率更高
缺点:难以应对突发的稀疏流量、可能存在旧数据长期不被淘汰,会影响某些场景下的命中率(如外卖),需要额外消耗来记录和更新访问频率
二、TinyLFU
Count-Min Sketch 算法
刚才提到了LFU需要统计每个条数据的访问频率,这就需要一个int或者long类型来存储次数,但是仔细一想,一条缓存数据的访问次数真的需要int类型这么大的表示范围来统计吗?我们认为一个缓存被访问15次已经算是很高的频率了,那么我们只用4个Bit就可以保存这个数据。(2^4=16)
再来介绍一个cmSketch算法,看过硬核课堂BloomFilter视频的都知道,BloomFilter利用位图的思想来标记一条数据是否存在,存在与否可以用某个Bit位的0 | 1来代替,那么我们能不能扩展一下,利用这种思想来计数呢?
我们给要计数的值计算一个Hash,然后在位图中给这个Hash值对应的位置累加1就可以了,但是BloomFilter中的一个典型问题是假阳性,可以说只要是用Hash计算就有存在冲突的可能,那么cmSketch计数法如果出现冲突会怎么样呢?会给同一个位置多计算访问次数。这里cmSketch选择了以最小的统计数据值作为结果。这是一个不那么精确地统计方法,但是可以大致的反应访问分布的规律。
因为这个算法也就有了一个名字,叫做Count-Min Sketch。
下面我们来手撕这个算法。
//根据BloomFilter来思考一下我们需要什么
//一个bit图,n个Hash函数
//一个BitMap的实现
type cmRow []byte //byte = uint8 = 0000,0000 = COUNTER 4BIT = 2 counter
//64 counter
//1 uint8 = 2counter
//32 uint8 = 64 counter
func newCmRow(numCounters int64) cmRow {
return make(cmRow, numCounters/2)
}
func (r cmRow) get(n uint64) byte {
return byte(r[n/2]>>((n&1)*4)) & 0x0f
}
0000,0000|0000,0000| 0000,0000 make([]byte, 3) = 6 counter
func (r cmRow) increment(n uint64) {
//定位到第i个Counter
i := n / 2 //r[i]
//右移距离,偶数为0,奇数为4
s := (n & 1) * 4
//取前4Bit还是后4Bit
v := (r[i] >> s) & 0x0f //0000, 1111
//没有超出最大计数时,计数+1
if v < 15 {
r[i] += 1 << s
}
}
//cmRow 100,
//保鲜
func (r cmRow) reset() {
// 计数减半
for i := range r {
r[i] = (r[i] >> 1) & 0x77 //0111,0111
}
}
func (r cmRow) clear() {
// 清空计数
for i := range r {
r[i] = 0
}
}
//快速计算最接近x的二次幂的算法
//比如x=5,返回8
//x = 110,返回128
//2^n
//1000000 (n个0)
//01111111(n个1) + 1
// x = 1001010 = 1111111 + 1 =10000000
func next2Power(x int64) int64 {
x--
x |= x >> 1
x |= x >> 2
x |= x >> 4
x |= x >> 8
x |= x >> 16
x |= x >> 32
x++
return x
}
如果我们要给n个数据计数,那么每4Bit当做一个计数器Counter,我们一共需要几个uint8来计数呢?答案是n/2
| 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
|---|---|---|---|---|---|---|---|
| 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
| 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
| 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
//cmSketch封装
const cmDepth = 4
type cmSketch struct {
rows [cmDepth]cmRow
seed [cmDepth]uint64
mask uint64
}
//numCounter - 1 = next2Power() = 0111111(n个1)
//0000,0000|0000,0000|0000,0000
//0000,0000|0000,0000|0000,0000
//0000,0000|0000,0000|0000,0000
//0000,0000|0000,0000|0000,0000
func newCmSketch(numCounters int64) *cmSketch {
if numCounters == 0 {
panic("cmSketch: bad numCounters")
}
numCounters = next2Power(numCounters)
sketch := &cmSketch{mask: uint64(numCounters - 1)}
// Initialize rows of counters and seeds.
source := rand.New(rand.NewSource(time.Now().UnixNano()))
for i := 0; i < cmDepth; i++ {
sketch.seed[i] = source.Uint64()
sketch.rows[i] = newCmRow(numCounters)
}
return sketch
}
func (s *cmSketch) Increment(hashed uint64) {
for i := range s.rows {
s.rows[i].increment((hashed ^ s.seed[i]) & s.mask)
}
}
// 找到最小的计数值
func (s *cmSketch) Estimate(hashed uint64) int64 {
min := byte(255)
for i := range s.rows {
val := s.rows[i].get((hashed ^ s.seed[i]) & s.mask)
if val < min {
min = val
}
}
return int64(min)
}
// 让所有计数器都减半,保鲜机制
func (s *cmSketch) Reset() {
for _, r := range s.rows {
r.reset()
}
}
// 清空所有计数器
func (s *cmSketch) Clear() {
for _, r := range s.rows {
r.clear()
}
}
TinyLFU解决了LFU统计的内存消耗问题,和缓存保鲜的问题,但是TinyLFU是否还有缺点呢?
有,论文中是这么描述的,根据实测TinyLFU应对突发的稀疏流量时表现不佳。大概思考一下也可以得知,这些稀疏流量的访问频次不足以让他们在LFU缓存中占据位置,很快就又被淘汰了。
我们回顾之前讲过的,LRU对于稀疏流量效果很好,那可以不可以把LRU和LFU结合一下呢?就出现了下面这种缓存策略。
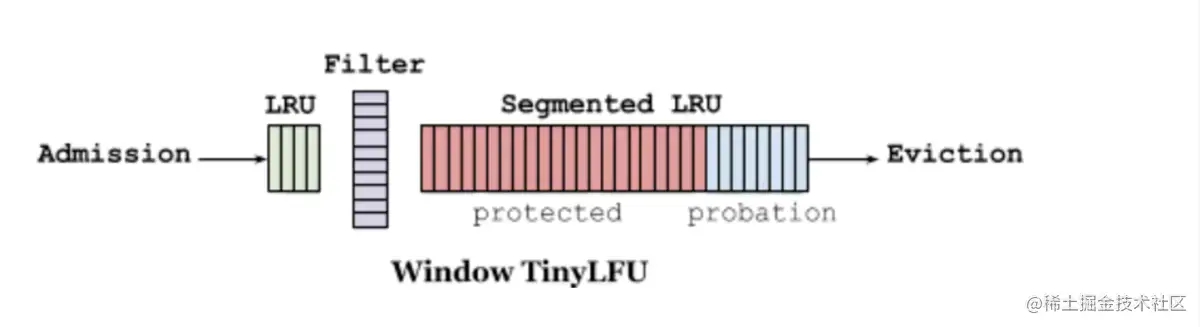
三、Window-TinyLFU
Window-TinyLFU策略里包含LRU和LFU两部分,前端的小LRU叫做Window LRU,它的容量只占据1%的总空间,它的目的就是用来存放短期的突发访问数据。存放主要元素的Segmented LRU(SLRU)是一种LRU的改进,主要把在一个时间窗口内命中至少2次的记录和命中1次的单独存放,这样就可以把短期内较频繁的缓存元素区分开来。具体做法上,SLRU包含2个固定尺寸的LRU,一个叫Probation段A1,一个叫Protection段A2。新记录总是插入到A1中,当A1的记录被再次访问,就把它移到A2,当A2满了需要驱逐记录时,会把驱逐记录插入到A1中。W-TinyLFU中,SLRU有80%空间被分配给A2段。
以上就是LRU LFU TinyLFU缓存算法实例详解的详细内容,更多关于LRU LFU TinyLFU缓存算法的资料请关注我们其它相关文章!
相关推荐
-
java实现LRU缓存淘汰算法的方法
LRU算法:最近最少使用淘汰算法(Least Recently Used).LRU是淘汰最长时间没有被使用的缓存(即使该缓存被访问的次数最多). 如何实现LRU缓存淘汰算法 场景: 我们现在有这么个真实场景,我在爬取某个网站时,控制该网站的代理IP并发数,太多会搞垮对方网站的对吧,要蹲号子的呢.这里我需要维护一个代理IP代理池,而且这些IP肯定不是一直都很稳定的,但是又不能取一个就丢一个,这样太浪费资源.所以我会将这些IP缓存起来,进行按需提取,采用LRU最近最少使用的策略去管理代理IP. 代码
-
Mango Cache缓存管理库TinyLFU源码解析
目录 介绍 整体架构 初始化流程 读流程 写流程 事件处理机制 主流程 write 清理工作 缓存管理 什么是LRU? 什么是SLRU? 什么是TinyLFU? mango Cache中的TinyLFU counter counter的初始化 counter的使用 lruCache slruCache filter TinyLFU的初始化 TinyLFU写入 TinyLFU访问 增加entry的访问次数 估计entry访问次数 总结 介绍 据官方所述,mango Cache是对Guava Cac
-

C++ 实现LRU 与 LFU 的缓存算法
目录 一.LRU (Least Recently Used) 缓存 二.LFU (Least Frequently Used) 缓存 一.LRU (Least Recently Used) 缓存 详见 LeetCode Q146 https:// leetcode.com/problems/l ru-cache/ https:// leetcode-cn.com/problem s/lru-cache/ 问题描述: LRUCache(int capacity) 以正整数作为容量 capacity
-
Redis中LFU算法的深入分析
前言 在Redis中的LRU算法文中说到,LRU有一个缺陷,在如下情况下: ~~~~~A~~~~~A~~~~~A~~~~A~~~~~A~~~~~A~~| ~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~| ~~~~~~~~~~C~~~~~~~~~C~~~~~~~~~C~~~~~~| ~~~~~D~~~~~~~~~~D~~~~~~~~~D~~~~~~~~~D| 会将数据D误认为将来最有可能被访问到的数据. Redis作者曾想改进LRU算法,但发现Redis的LRU算法受制
-
LRU LFU TinyLFU缓存算法实例详解
目录 简介 一.LRU和LFU算法 LRU算法 LFU算法 小结: 二.TinyLFU 三.Window-TinyLFU 简介 前置知识 知道什么是缓存 听完本节公开课,你可以收获 掌握朴素LRU.LFU算法的思想以及源码 掌握一种流式计数的算法 Count-Min Sketch 手撕TinyLFU算法.分析Window-TinyLFU源码 一.LRU和LFU算法 LRU算法 LRU Least Recently Used 最近最少使用算法 LRU 算法的思想是如果一个数据在最近一段时间没有被访
-
Java实现LRU缓存的实例详解
Java实现LRU缓存的实例详解 1.Cache Cache对于代码系统的加速与优化具有极大的作用,对于码农来说是一个很熟悉的概念.可以说,你在内存中new 了一个一段空间(比方说数组,list)存放一些冗余的结果数据,并利用这些数据完成了以空间换时间的优化目的,你就已经使用了cache. 有服务级的缓存框架,如memcache,Redis等.其实,很多时候,我们在自己同一个服务内,或者单个进程内也需要缓存,例如,lucene就对搜索做了缓存,而无须依赖外界.那么,我们如何实现我们自己的缓存?还
-
MyBatis 动态SQL和缓存机制实例详解
有的时候需要根据要查询的参数动态的拼接SQL语句 常用标签: - if:字符判断 - choose[when...otherwise]:分支选择 - trim[where,set]:字符串截取,其中where标签封装查询条件,set标签封装修改条件 - foreach: if案例 1)在EmployeeMapper接口文件添加一个方法 public Student getStudent(Student student); 2)如果要写下列的SQL语句,只要是不为空,就作为查询条件,如下所示,这样
-
vue服务端渲染页面缓存和组件缓存的实例详解
vue缓存分为页面缓存.组建缓存.接口缓存,这里我主要说到了页面缓存和组建缓存 页面缓存: 在server.js中设置 const LRU = require('lru-cache') const microCache = LRU({ max: 100, // 最大缓存的数目 maxAge: 1000 // 重要提示:条目在 1 秒后过期. }) const isCacheable = req => { //判断是否需要页面缓存 if (req.url && req.url ===
-
java 中模式匹配算法-KMP算法实例详解
java 中模式匹配算法-KMP算法实例详解 朴素模式匹配算法的最大问题就是太低效了.于是三位前辈发表了一种KMP算法,其中三个字母分别是这三个人名的首字母大写. 简单的说,KMP算法的对于主串的当前位置不回溯.也就是说,如果主串某次比较时,当前下标为i,i之前的字符和子串对应的字符匹配,那么不要再像朴素算法那样将主串的下标回溯,比如主串为"abcababcabcabcabcabc",子串为"abcabx".第一次匹配的时候,主串1,2,3,4,5字符都和子串相应的
-
JavaScript算法系列之快速排序(Quicksort)算法实例详解
"快速排序"的思想很简单,整个排序过程只需要三步: (1)在数据集之中,选择一个元素作为"基准"(pivot). (2)所有小于"基准"的元素,都移到"基准"的左边:所有大于"基准"的元素,都移到"基准"的右边. (3)对"基准"左边和右边的两个子集,不断重复第一步和第二步,直到所有子集只剩下一个元素为止. 举例来说,现在有一个数据集{85, 24, 63, 45,
-
微信小程序之数据缓存的实例详解
微信小程序之数据缓存的实例详解 前言: 在H5之前,缓存一般都是用cookie,但是cookie的存储空间太小.于是,H5增加了新的缓存机制,即localstorage 和 sessionstorage,具体的介绍就不在多说.在微信小程序中,数据缓存其实就和localstorage 的原理差不多,所以理解起来并不难.下面我们来一起实现一下. 效果图展示: 我们在index页面存入数字11,然后在跳转到新页面,在将缓存中的11取出渲染到当前页面.具体代码如下: index页面: <span sty
-
Java 选择排序、插入排序、希尔算法实例详解
1.基本思想: 在要排序的一组数中,选出最小的一个数与第一个位置的数交换:然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止. 2.实例 3.算法实现 /** * 选择排序算法 * 在未排序序列中找到最小元素,存放到排序序列的起始位置 * 再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾. * 以此类推,直到所有元素均排序完毕. * @param numbers */ public static void selectSort(int[] nu
-
Java 归并排序算法、堆排序算法实例详解
基本思想: 归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的.然后再把有序子序列合并为整体有序序列. 归并排序示例: 合并方法: 设r[i-n]由两个有序子表r[i-m]和r[m+1-n]组成,两个子表长度分别为n-i +1.n-m. j=m+1:k=i:i=i; //置两个子表的起始下标及辅助数组的起始下标 若i>m 或j>n,转⑷ //其中一个子表已合并完,比较选取结束 //选取r[i]和r[j]较小的存入辅助数组
-
KMP 算法实例详解
KMP 算法实例详解 KMP算法,是由Knuth,Morris,Pratt共同提出的模式匹配算法,其对于任何模式和目标序列,都可以在线性时间内完成匹配查找,而不会发生退化,是一个非常优秀的模式匹配算法. 分析:KMP模板题.KMP的关键是求出next的值.先预处理出next的值.然后一遍扫过.复杂度O(m+n) 实例代码: #include<stdio.h> #include<string.h> #define N 1000005 int s[N]; int p[N]; int n