SQL Server 2016 查询存储性能优化小结
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题。
我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在一切已经改变,SQL Server开始糟糕, 疯狂的事情不能解释。在这个情况下我介入,分析下整个SQL Server的安装,最后用一些神奇的调查方法找出性能问题的根源。
但很多时候问题的根源是一样的:所谓的计划回归(Plan Regression),即特定查询的执行计划已经改变。昨天SQL Server已经缓存了在计划缓存里缓存了一个好的执行计划,今天就生成、缓存最后重用了一个糟糕的执行计划——不断重复。
进入SQL Server 2016后,我就变得有点多余了,以为微软引进了查询存储(Query Store)。这是这个版本最热门的功能!查询存储帮助你很容易找出你的性能问题是不是计划回归造成的。如果你找到了计划回归,这很容易强制一个特定计划不使用计划向导。听起来很有意思?让我们通过一个特定的场景,向你展示下在SQL Server 2016里,如何使用查询存储来找出并最终修正计划回归。
查询存储(Query Store)——我的对手
在SQL Server 2016里,在你使用查询存储功能前,你要对这个数据库启用它。这是通过ALTER DATABASE语句实现,如你所见的下列代码:
CREATE DATABASE QueryStoreDemo GO USE QueryStoreDemo GO -- Enable the Query Store for our database ALTER DATABASE QueryStoreDemo SET QUERY_STORE = ON GO -- Configure the Query Store ALTER DATABASE QueryStoreDemo SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 367), DATA_FLUSH_INTERVAL_SECONDS = 900, INTERVAL_LENGTH_MINUTES = 1, MAX_STORAGE_SIZE_MB = 100, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = OFF ) GO
在线帮助为你提供了各个选项的详细信息。接下来我创建一个简单的表,创建一个非聚集索引,最后插入80000条记录。
-- Create a new table CREATE TABLE Customers ( CustomerID INT NOT NULL PRIMARY KEY CLUSTERED, CustomerName CHAR(10) NOT NULL, CustomerAddress CHAR(10) NOT NULL, Comments CHAR(5) NOT NULL, Value INT NOT NULL ) GO -- Create a supporting new Non-Clustered Index. CREATE UNIQUE NONCLUSTERED INDEX idx_Test ON Customers(Value) GO -- Insert 80000 records DECLARE @i INT = 1 WHILE (@i <= 80000) BEGIN INSERT INTO Customers VALUES ( @i, CAST(@i AS CHAR(10)), CAST(@i AS CHAR(10)), CAST(@i AS CHAR(5)), @i ) SET @i += 1 END GO
为了访问我们的表,我额创建了一个简单的存储过程,传入value值作为过滤谓语。
-- Create a simple stored procedure to retrieve the data CREATE PROCEDURE RetrieveCustomers ( @Value INT ) AS BEGIN SELECT * FROM Customers WHERE Value < @Value END GO
现在我用80000的参数值来执行存储过程。
-- Execute the stored procedure. -- This generates an execution plan with a Key Lookup (Clustered). EXEC RetrieveCustomers 80000 GO
现在当你查看实际的执行计划时,你会看到查询优化器已经选择了有419个逻辑读的聚集索引扫描运算符。SQL Server并没有使用非聚集索引,因为这样没有意义,由于临界点。这个查询结果并没有选择性。
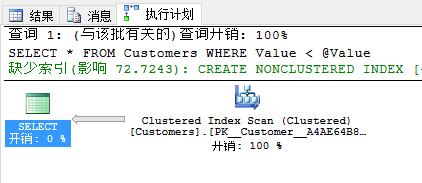
现在假设SQL Server发生了些事情(例如重启,故障转移),SQL Server忽略已经缓存的计划,这里我通过执行DBCC FREEPROCCACHE从计划缓存里抹掉每个缓存的计划来模拟SQL Server重启(不要在生产环境里使用!)。
-- Get rid of the cached execution plan... DBCC FREEPROCCACHE GO
现在有人再次调用你的存储过程,这次输入参数值是1。这次执行计划不一样,因为现在在执行计划里你会有书签查找。SQL Server估计行数是1,在非聚集索引里没有找到任何行。因此与非聚集索引查找结合的书签查找才有意义,因为这个查询是有选择性的。
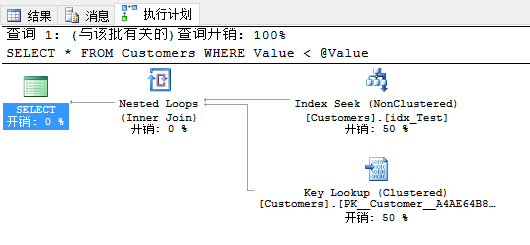
现在我再执行用80000参数值的查询。
-- Execute the stored procedure EXEC RetrieveCustomers 1 GO -- Execute the stored procedure again -- This introduces now a plan regression, because now we get a Clustered Index Scan -- instead of the Key Lookup (Clustered). EXEC RetrieveCustomers 80000 GO
当你再次看STATISTICS IO的输出,你会看到这个查询现在产生了160139个逻辑读——刚才的查询只有419个逻辑读。这个时候DBA的手机就会响起,性能问题。但今天我们要不同的方式解决——使用刚才启用的查询存储。
当你再次看实际的执行计划,在你面前你会看到有一个计划回归,因为SQL Server刚重用了书签查找的的计划缓存。刚才你有聚集索引扫描运算符的执行计划。这是SQL Server里参数嗅探的副作用。
让我们通过查询存储来详细了解这个问题。在SSMS里的对象资源管理器里,SQL Server 2016提供了一个新的结点叫查询存储,这里你会看到一些报表。
【前几个资源使用查询】向你展示了最昂贵的查询,基于你选择的维度。这里切换到【逻辑读取次数】。
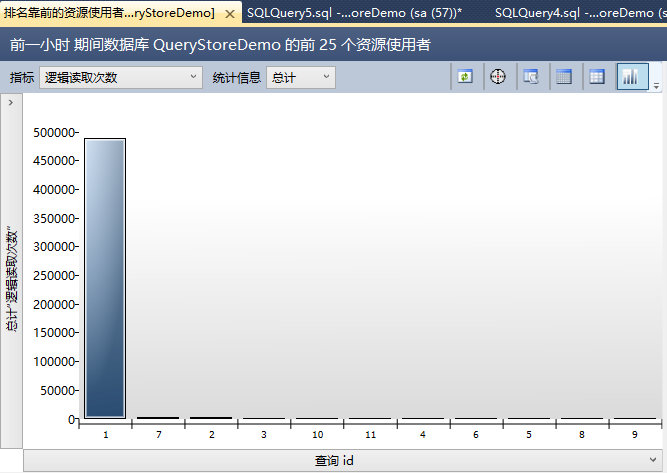
这里在你面前有一些查询。最昂贵的查询生成了近500000个逻辑读。这是我们的初始语句。这已经是第一个WOW效果的的查询存储:SQL Server重启后,查询存储的数据还是存在的!第2个是你存储过程里的SELECT语句。在查询存储里每个捕获的查询都有一个标示号——这里是7。最后当你看报告的右边,你会看这个查询的不同执行计划。
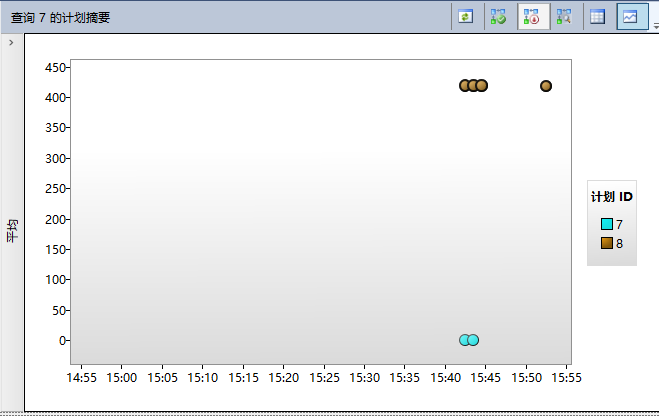
如你所见,查询存储捕获了2个不同的执行计划,一个ID是7,一个ID是8。当你点击计划ID时,SQL Server会在报表的最下面为你显示估计的执行计划。
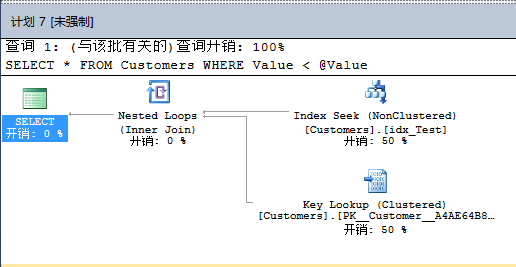
计划8是聚集索引扫描,计划7是书签查找。如你所见,使用查询存储分析计划回归非常简单。但你现在还没结束。你现在可以对指定的查询强制执行计划。 现在你知道包含聚集索引扫描的执行计划有更好的性能。因此现在你可以通过点击【强制执行计划】强制查询7使用执行计划。

搞定,我们已经解决问题了!
现在当你执行存储过程(用80000的输入参数值),在执行计划里你可以看到聚集索引扫描,执行计划只生成419个逻辑读——很简单,是不是?绝对不是!!!!
微软告诉我们只给修正SQL Server性能相关的“新方式”。你只是强制了特定的计划,一切都还好。这个方法有个大的问题,因为性能问题的根源并没有解决!这个问题的关键是因为书签查找计划没有稳定性。取决于首次执行计划默认的输入值,执行计划因此就被不断重用。
通常我会建议调整下你的索引设计,创建一个覆盖索引来保证计划的稳定性。但强制特定执行计划只是临时解决问题——你还是要修正你问题的根源。
小结
不要误解我:SQL Server 2016里的查询存储功能很棒,可以帮你更容易理解计划回归。它也会帮你“临时”强制特定的执行计划。但性能调优的目标还是一样:你要找到问题根源,尝试解决问题——不要在外面晃荡!
相关推荐
-

Sql Server2016 正式版安装程序图解教程
好不容易有个周末,不能闲着,趁着这个时间安装sql server2016正式版,下载那个安装包都用了一个星期 安装包可以从这里下载:http://www.itellyou.cn/ https://msdn.microsoft.com/zh-cn/subscriptions/downloads/hh442898.aspx 安装环境 hyper-v虚拟机 Windows2012R2数据中心版 打开安装包可以看到现在SQL 引擎功能和SSMS已经独立分开安装了 只支持64位 功能选择里多出来的R Se
-
SQL Server 2016 无域群集配置 AlwaysON 可用性组图文教程
windows server 2016 与 sql server 2016 都可用允许不许要加入AD ,管理方面省了挺多操作,也不用担心域控出现问题影响各服务器了. 本测试版本: window server 2016 datacenter + sql server 2016 ctp IP规划: 主机名 IP 说明 ad 192.168.2.2 域服务器(kk.com)windows xp Server131 192.168.2.131 节点 Server132 192.168.2.132 节点
-
SQL Server 2016的数据库范围内的配置详解
SQL Server 2016真的让人眼前一亮.几天前微软就提供了RCO(候选发布版)版本的下载.我已经围观了一圈RCO版本,其中一个最拽的功能是数据库范围内的配置(Database Scoped Configuration),在今天的文章里我想谈谈它.补充几句:装好之后,居然发现没有SSMS,崩溃中,原来是在向导中就有独立的安装程序,好吧! 这配色,真是低调有内涵. 另外,如过你的电脑已经安装了就[Microsoft Visual Studio 2010 Shell(独立)Redistribu
-
SQL Server 2016正式版安装配置过程图文详解
本文针对SQL 2016 正式版安装过程进行梳理总结,帮助大家顺利安装SQL 2016,具体内容如下 1.点击全新安装 2.接着就是下一步,下一步... 3.选择你要安装的功能 [可以利用PolyBase,使用标准TSQL查询hadoop数据,但这里我不需要装] 4.设置排序规则 5.设置登录用户 6.临时数据库配置[SQL Server 2016:可以根据逻辑CPU数量来调整tempdb的数据文件数量] 7.数据库安装完成后,点击安装管理工具 8.管理工具要从官网去下载[https://msd
-
SQL Server2016正式版安装配置方法图文教程
安装SQL Server2016正式版 今天终于有时间安装SQL Server2016正式版,下载那个安装包都用了一个星期 安装包可以从这里下载:http://www.itellyou.cn/ https://msdn.microsoft.com/zh-cn/subscriptions/downloads/hh442898.aspx 安装环境 hyper-v虚拟机 Windows2012R2数据中心版 打开安装包可以看到现在SQL 引擎功能和SSMS已经独立分开安装了 只支持64位 功能选择里多
-
SQL Server 2016 配置 SA 登录教程
tips:在win10中查找SQL Server 2016配置管理器,用来开启SQL Server网络配置,启用实例TCP/IP协议和Name PiPe. Windows 10: 要打开 SQL Server 配置管理器,请在"起始页"中键入 SQLServerManager13.msc(适用于 SQL Server 2016). 对于早期版本的 SQL Server ,请将 13 替换为较小的数字. 单击"SQLServerManager13.msc"可打开配置管
-
SQL Server 2016 查询存储性能优化小结
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题. 我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在一切已经改变,SQL Server开始糟糕, 疯狂的事情不能解释.在这个情况下我介入,分析下整个SQL Server的安装,最后用一些神奇的调查方法找出性能问题的根源. 但很多时候问题的根源是一样的:所谓的计划回归(Plan Regression),即特定查询的执行计划已经改变.昨天SQL Serv
-
SQL Server 2016 CTP2.3 的关键特性总结
SQL Server 2016带来全新突破性的 in-memory性能和分析功能来实现关键任务处理.全面的安全特性 -Always Encrypted 技术可以帮助保护您的数据 数据库方面的增强 Row Level Security已经支持In-memory OLTP 表.用户现在可以对内存优化表实施row-level security策略. 另外SCHEMABINDING.predicate 函数和内联表值函数都要包含NATIVE_COMPILATION编译选项. 使用NATIVE_COMP
-
详解SQL Server 2016快照代理过程
本文我们通过SQL Server 2016一个实例数据表,给大家详细分析了快照代理过程遇到的问题和解决办法,并对快照生成过程做了详细说明,以下是全部内容: 概述 快照代理准备已发布表的架构和初始数据文件以及其他对象.存储快照文件并记录分发数据库中的同步信息. 快照代理在分发服务器上运行:SQLServer2016版本对快照代理做了一些比较好的优化,接下来详细了解一下快照的执行过程. 一.快照代理文件 在执行快照作业是会在指定的快照目录生成4种类型的文件. BCP文件:发布对象的数据文件. IDX
-
Sql Server 2016新功能之Row-Level Security(值得关注)
Sql Server 2016 有一个新功能叫 Row-Level Security ,大概意思是行版本的安全策略(原来我是个英语渣_(:з」∠)_) 直接上例子.这个功能相当通过对表添加一个函数作为过滤规则,使得拥有不同条件的用户(或者登录名) 之类的,只能获取到符合条件的数据.相对来说是提供了那么一点的便捷性,当然也增加了数据的安全性,相当于每个用户连接进来只能看到 符合规则的数据(当然,这里的用户只是一个举例.其实是可以通过编写过滤函数来实现的) 举个例子 有三个用户 Sales1 ,Sa
-
SQL Server 2016 TempDb里的显著提升
几个星期前,SQL Server 2016的最新CTP版本已经发布了:CTP 2.4(目前已经是CTP 3.0).关于SQL Server 2016 CTP2.3 的关键特性总结,在此不多说了,具体内容请查相关资料.这个预览版相比以前的CTP包含了很多不同的提升.在这篇文章里我会谈下对于SQL Server 2016,TempDb里的显著提升. TempDb定制 在SQL Server 2016安装期间,第一个你会碰到的改变是在安装过程中,现在你能配置TempDb的物理配置.我们可以详细看下面的
-
浅谈SQL Server 2016里TempDb的进步
几个星期前,SQL Server 2016的最新CTP版本已经发布了:CTP 2.4(目前已经是CTP 3.0).这个预览版相比以前的CTP包含了很多不同的提升.在这篇文章里我会谈下对于SQL Server 2016,TempDb里的显著提升. TempDb定制 在SQL Server 2016安装期间,第一个你会碰到的改变是在安装过程中,现在你能配置TempDb的物理配置.我们可以详细看下面的截屏. 微软现在检测几个可用的CPU内核,基于这个数字安装程序自动配置TempDb文件个数.这个对克服
-
SQL Server 2016 Alwayson新增功能图文详解
概述 SQLServer2016发布版本到现在已有一年多的时间了,目前最新的稳定版本是SP1版本.接下来就开看看2016在Alwyson上做了哪些改进,记得之前我在写2014Alwayson的时候提到过几个需要改进的问题在2016上已经做了改进. 一.自动故障转移副本数量 在2016之前的版本自动故障转移副本最多只能配置2个副本,在2016上变成了3个. 说明:自动故障转移增加到三个副本影响并不是很大不是非常的重要,多增加一个故障转移副本也意味着你的作业也需要多维护一个副本.重要程度(一般).
-
SQL Server 2016 CTP2.2安装配置方法图文教程
SQL Server 2016 CTP2.2 安装配置教程 下载一个iso文件,解压出来(大约2.8G左右),在该路径下双击Setup.exe即可开始安装. 安装之前请先安装.NET 3.5 SP1,在服务器管理器->添加角色和功能里就能安装 打开安装界面 安装界面一如既往的熟悉,这个安装界面从SQL Server2008开始就没有太大变化 因为是评估版,那么就不需要产品密钥,直接安装 勾选接受许可条款 验证是否符合规则 不要勾选检查更新 选择SQL Server功能安装 高大上的功能来了,可以