Netty分布式ByteBuf使用的底层实现方式源码解析
目录
- 概述
- AbstractByteBuf属性和构造方法
- 首先看这个类的属性和构造方法
- 我们看几个最简单的方法
- 我们重点关注第二个校验方法ensureWritable(length)
- 我们跟到扩容的方法里面去
- 最后将写指针后移length个字节
概述
熟悉Nio的小伙伴应该对jdk底层byteBuffer不会陌生, 也就是字节缓冲区, 主要用于对网络底层io进行读写, 当channel中有数据时, 将channel中的数据读取到字节缓冲区, 当要往对方写数据的时候, 将字节缓冲区的数据写到channel中
但是jdk的byteBuffer是使用起来有诸多不便, 比如只有一个标记位置的指针position, 在进行读写操作时要频繁的通过flip()方法进行指针位置的移动, 极易出错, 并且byteBuffer的内存一旦分配则不能改变, 不支持动态扩容, 当读写的内容大于缓冲区内存时, 则会发生索引越界异常
而Netty的ByteBuf对jdk的byteBuffer做了重新的定义, 同样是字节缓冲区用于读取网络io中的数据, 但是使用起来大大简化, 并且支持了自动扩容, 不用担心读写数据大小超过初始分配的大小
byteBuf根据其分类的不同底层实现方式有所不同, 有直接基于jdk底层byteBuffer实现的, 也有基于字节数组的实现的, 对于byteBuf的分类, 在后面的小节将会讲到
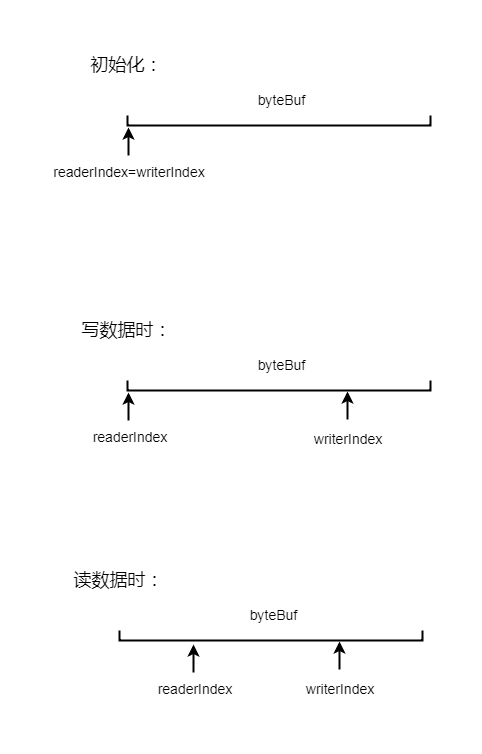
byteBuf中维护了两个指针, 一是读指针, 二是写指针, 两个指针相互独立, 在读操作的时候, 只会移动读指针, 通过指针位置记录读取的字节数
同样在写操作时, 也只会移动写指针, 通过写指针的位置记录写的字节数
在每次读写操作的过程中都会对指针的位置进行校验, 读指针的位置不能超过写指针, 否则会抛出异常
同样, 写指针不能超过缓冲区分配的内存, 则将对缓冲区做扩容操作
具体指针操作, 入下图所示:
AbstractByteBuf属性和构造方法
在讲AbstractByteBuf之前, 我们首先先了解一下ByteBuf这个类, 这是所有ByteBuf的最顶层抽象, 里面定义了大量对ByteBuf操作的抽象方法供子类实现
AbstractByteBuf同样也缓冲区的抽象类, 定义了byteBuf的骨架操作, 比如参数校验, 自动扩容, 以及一些读写操作的指针移动, 但具体的实现, 不同的bytebuf实现起来是不同的, 这种情况则交给其子类实现
AbstractByteBuf继承了这个类, 并实现了其大部分的方法
首先看这个类的属性和构造方法
//读指针
int readerIndex;
//写指针
int writerIndex;
//保存读指针
private int markedReaderIndex;
//保存写指针
private int markedWriterIndex;
//最大分配容量
private int maxCapacity;
protected AbstractByteBuf(int maxCapacity) {
if (maxCapacity < 0) {
throw new IllegalArgumentException("maxCapacity: " + maxCapacity + " (expected: >= 0)");
}
this.maxCapacity = maxCapacity;
}
我们可以看到在属性中定义了读写指针的成员标量, 和读写指针位置的保存
在构造方法中可以传入可分配的最大内存, 然后赋值到成员变量中
我们看几个最简单的方法
@Override
public int maxCapacity() {
return maxCapacity;
}
@Override
public int readerIndex() {
return readerIndex;
}
@Override
public int writerIndex() {
return writerIndex;
}
获取最大内存, 获取读写指针这些方法, 对所有的bytebuf都是通用的, 所以可以定义在AbstractByteBuf中
我们以一个writeBytes方法为例, 让同学们熟悉AbstractByteBuf中哪些部分自己实现, 哪些部分则交给了子类实现:
@Override
public ByteBuf writeBytes(ByteBuf src) {
writeBytes(src, src.readableBytes());
return this;
}
这个方法是将源的ByteBuf(参数)中的字节写入到自身ByteBuf中
首先这里调用了自身的writeBytes方法, 并传入参数ByteBuf本身, 以及Bytebuf的可读字节数, 我们跟到readbleBytes()方法中, 其实就是调用了自身的方法:
@Override
public int readableBytes() {
return writerIndex - readerIndex;
}
我们看到, 这里可读字节数就是返回了写指针到读指针之间的长度
我们再继续跟到writeBytes(src, src.readableBytes())中:
@Override
public ByteBuf writeBytes(ByteBuf src, int length) {
if (length > src.readableBytes()) {
throw new IndexOutOfBoundsException(String.format(
"length(%d) exceeds src.readableBytes(%d) where src is: %s", length, src.readableBytes(), src));
}
writeBytes(src, src.readerIndex(), length);
src.readerIndex(src.readerIndex() + length);
return this;
}
这里同样调用了自身的方法首先会对参数进行验证, 就是写入自身的长度不能超过源ByteBuf的可读字节数
这里又调用了一个wirte方法, 参数传入源Bytebuf, 其可读字节数, 写入的长度, 这里写入的长度我们知道就是源ByteBuf的可读字节数
我们再跟到writeBytes(src, src.readerIndex(), length);
public ByteBuf writeBytes(ByteBuf src, int srcIndex, int length) {
ensureAccessible();
ensureWritable(length);
setBytes(writerIndex, src, srcIndex, length);
writerIndex += length;
return this;
}
我们重点关注第二个校验方法ensureWritable(length)
public ByteBuf ensureWritable(int minWritableBytes) {
if (minWritableBytes < 0) {
throw new IllegalArgumentException(String.format(
"minWritableBytes: %d (expected: >= 0)", minWritableBytes));
}
ensureWritable0(minWritableBytes);
return this;
}
然后我们再跟到ensureWritable0(minWritableBytes)方法中:
private void ensureWritable0(int minWritableBytes) {
if (minWritableBytes <= writableBytes()) {
return;
}
if (minWritableBytes > maxCapacity - writerIndex) {
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
//自动扩容
int newCapacity = alloc().calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity);
capacity(newCapacity);
}
开始做了两个参数校验, 第一个表示当前ByteBuf写入的长度如果要小于可写字节数, 则返回
第二个可以换种方式去看minWritableBytes+ writerIndex> maxCapacity 也就是需要写入的长度+写指针必须要小于最大分配的内存, 否则报错, 注意这里最大分配内存不带表当前内存, 而是byteBuf所能分配的最大内存
如果需要写入的长度超过了可写字节数, 并且需要写入的长度+写指针不超过最大内存, 则就开始了ByteBuf非常经典也非常重要的操作, 也就是自动扩容
int newCapacity = alloc().calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity);
其中alloc()返回的是当前bytebuf返回的缓冲区分配器对象, 我们之后的小节会讲到, 这里调用了其calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity)方法为其扩容, 其中传入的参数writerIndex + minWritableBytes代表所需要的容量, maxCapacity为最大容量
我们跟到扩容的方法里面去
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {
//合法性校验
if (minNewCapacity < 0) {
throw new IllegalArgumentException("minNewCapacity: " + minNewCapacity + " (expectd: 0+)");
}
if (minNewCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"minNewCapacity: %d (expected: not greater than maxCapacity(%d)",
minNewCapacity, maxCapacity));
}
//阈值为4mb
final int threshold = 1048576 * 4;
//最小需要扩容内存(总内存) == 阈值
if (minNewCapacity == threshold) {
//返回阈值
return threshold;
}
//最小扩容内存>阈值
if (minNewCapacity > threshold) {
//newCapacity为需要扩容内存
int newCapacity = minNewCapacity / threshold * threshold;
//目标容量+阈值>最大容量
if (newCapacity > maxCapacity - threshold) {
//将最大容量作为新容量
newCapacity = maxCapacity;
} else {
//否则, 目标容量+阈值
newCapacity += threshold;
}
return newCapacity;
}
//如果小于阈值
int newCapacity = 64;
//目标容量<需要扩容的容量
while (newCapacity < minNewCapacity) {
//倍增
newCapacity <<= 1;
}
//目标容量和最大容量返回一个最小的
return Math.min(newCapacity, maxCapacity);
}
扩容相关的逻辑注释也写的非常清楚, 如果小于阈值(4mb), 采用倍增的方式, 如果大于阈值(4mb), 采用平移4mb的方式
我们回到writeBytes(ByteBuf src, int srcIndex, int length):
public ByteBuf writeBytes(ByteBuf src, int srcIndex, int length) {
ensureAccessible();
ensureWritable(length);
setBytes(writerIndex, src, srcIndex, length);
writerIndex += length;
return this;
}
再往下看setBytes(writerIndex, src, srcIndex, length), 这里的参数的意思是从当前byteBuf的writerIndex节点开始写入, 将源缓冲区src的读指针位置, 写lenght个字节, 这里的方法中AbstractByteBuf类并没有提供实现, 因为不同类型的BtyeBuf实现的方式是不一样的, 所以这里交给了子类去实现
最后将写指针后移length个字节
最后我们回到writeBytes(ByteBuf src, int length)方法中:
public ByteBuf writeBytes(ByteBuf src, int length) {
if (length > src.readableBytes()) {
throw new IndexOutOfBoundsException(String.format(
"length(%d) exceeds src.readableBytes(%d) where src is: %s", length, src.readableBytes(), src));
}
writeBytes(src, src.readerIndex(), length);
src.readerIndex(src.readerIndex() + length);
return this;
}
当writeBytes(src, src.readerIndex(), length)写完之后, 通过src.readerIndex(src.readerIndex() + length)将源缓冲区的读指针后移lenght个字节
以上对AbstractByteBuf的简单介绍和其中写操作的方法的简单剖析
以上就是Netty分布式ByteBuf使用的底层实现方式源码解析的详细内容,更多关于Netty分布式ByteBuf使用底层实现的资料请关注我们其它相关文章!
相关推荐
-

Netty分布式pipeline管道传播outBound事件源码解析
目录 outbound事件传输流程 这里我们同样给出两种写法 跟到其write方法中: 跟到findContextOutbound中 回到write方法: 继续跟invokeWrite0 我们跟到HeadContext的write方法中 了解了inbound事件的传播过程, 对于学习outbound事件传输的流程, 也不会太困难 outbound事件传输流程 在我们业务代码中, 有可能使用wirte方法往写数据: public void channelActive(ChannelHandlerC
-
Netty分布式pipeline管道Handler的删除逻辑操作
目录 删除handler操作 我们跟到getContextPrDie这个方法中 首先要断言删除的节点不能是tail和head 回到remove(ctx)方法 上一小节我们学习了添加handler的逻辑操作, 这一小节我们学习删除handler的相关逻辑 删除handler操作 如果用户在业务逻辑中进行ctx.pipeline().remove(this)这样的写法, 或者ch.pipeline().remove(new SimpleHandler())这样的写法, 则就是对handler进行删除
-
Netty分布式pipeline管道Handler的添加代码跟踪解析
目录 添加handler 我们跟到其addLast()方法中 再继续跟到addLast()方法中去 我们跟到checkMultiplicity(handler)中 跟到filterName方法中 跟到isInbound(handler)方法中 我们回到最初的addLast()方法中 我们跟进addLast0(newCtx)中 前文传送门:Netty分布式pipeline管道创建 添加handler 我们以用户代码为例进行剖析: .childHandler(new ChannelInitializ
-
Netty分布式pipeline传播inbound事件源码分析
前一小结回顾:pipeline管道Handler删除 传播inbound事件 有关于inbound事件, 在概述中做过简单的介绍, 就是以自己为基准, 流向自己的事件, 比如最常见的channelRead事件, 就是对方发来数据流的所触发的事件, 己方要对这些数据进行处理, 这一小节, 以激活channelRead为例讲解有关inbound事件的处理流程 在业务代码中, 我们自己的handler往往会通过重写channelRead方法来处理对方发来的数据, 那么对方发来的数据是如何走到chann
-
Netty分布式pipeline管道异常传播事件源码解析
目录 传播异常事件 简单的异常处理的场景 我们跟到invokeChannelRead这个方法 我还是通过两种写法来进行剖析 跟进invokeExceptionCaught方法 跟到invokeExceptionCaught方法中 讲完了inbound事件和outbound事件的传输流程, 这一小节剖析异常事件的传输流程 传播异常事件 简单的异常处理的场景 @Override public void channelRead(ChannelHandlerContext ctx, Object msg
-
Netty分布式pipeline管道传播事件的逻辑总结分析
目录 问题分析 首先完成了handler的添加, 但是并没有马上执行回调 回到callHandlerCallbackLater方法中 章节总结 我们在第一章和第三章中, 遗留了很多有关事件传输的相关逻辑, 这里带大家一一回顾 问题分析 首先看两个问题: 1.在客户端接入的时候, NioMessageUnsafe的read方法中pipeline.fireChannelRead(readBuf.get(i))为什么会调用到ServerBootstrap的内部类ServerBootstrapAccep
-
Netty分布式ByteBuf使用的底层实现方式源码解析
目录 概述 AbstractByteBuf属性和构造方法 首先看这个类的属性和构造方法 我们看几个最简单的方法 我们重点关注第二个校验方法ensureWritable(length) 我们跟到扩容的方法里面去 最后将写指针后移length个字节 概述 熟悉Nio的小伙伴应该对jdk底层byteBuffer不会陌生, 也就是字节缓冲区, 主要用于对网络底层io进行读写, 当channel中有数据时, 将channel中的数据读取到字节缓冲区, 当要往对方写数据的时候, 将字节缓冲区的数据写到cha
-
Netty分布式ByteBuf的分类方式源码解析
目录 ByteBuf根据不同的分类方式 会有不同的分类结果 1.Pooled和Unpooled 2.基于直接内存的ByteBuf和基于堆内存的ByteBuf 3.safe和unsafe 上一小节简单介绍了AbstractByteBuf这个抽象类, 这一小节对其子类的分类做一个简单的介绍 ByteBuf根据不同的分类方式 会有不同的分类结果 我们首先看第一种分类方式 1.Pooled和Unpooled pooled是从一块内存里去取一段连续内存封装成byteBuf 具体标志是类名以Pooled开头
-
await 错误捕获实现方式源码解析
目录 前言 Promise 的使用方法 await-to-js 源码 总结 前言 Promise 是一种在 JavaScript 中用于处理异步操作的机制.Promise 在开发中被广泛使用,这篇文章将学习如何优雅的捕获 await 的错误. 资源: 仓库地址:await-to-js 参考文章:How to write async await without try-catch blocks in Javascript (grossman.io) Promise 的使用方法 创建一个 Promi
-
Netty分布式Server启动流程服务端初始化源码分析
目录 第一节:服务端初始化 group方法 初始化成员变量 初始化客户端Handler 第一节:服务端初始化 首先看下在我们用户代码中netty的使用最简单的一个demo: //创建boss和worker线程(1) EventLoopGroup bossGroup = new NioEventLoopGroup(1); EventLoopGroup workerGroup = new NioEventLoopGroup(); //创建ServerBootstrap(2) ServerBootst
-
Netty分布式ByteBuf缓冲区分配器源码解析
目录 缓冲区分配器 以其中的分配ByteBuf的方法为例, 对其做简单的介绍 跟到directBuffer()方法中 我们回到缓冲区分配的方法 然后通过validate方法进行参数验证 缓冲区分配器 顾明思议就是分配缓冲区的工具, 在netty中, 缓冲区分配器的顶级抽象是接口ByteBufAllocator, 里面定义了有关缓冲区分配的相关api 抽象类AbstractByteBufAllocator实现了ByteBufAllocator接口, 并且实现了其大部分功能 和AbstractByt
-
Netty分布式ByteBuf使用page级别的内存分配解析
目录 netty内存分配数据结构 我们看PoolArena中有关chunkList的成员变量 我们看PoolSubpage的属性 我们回到PoolArena的allocate方法 我们跟进allocateNormal 首先会从head节点往下遍历 这里直接通过构造函数创建了一个chunk 首先将参数传入的值进行赋值 我们再回到PoolArena的allocateNormal方法中 跟到allocate(normCapacity)中 我们跟到allocateNode方法中 我们跟进updatePa
-
Netty分布式ByteBuf使用命中缓存的分配解析
目录 分析先关逻辑之前, 首先介绍缓存对象的数据结构 我们以tiny类型为例跟到createSubPageCaches方法中 回到PoolArena的allocate方法中 我们跟到normalizeCapacity方法中 回到allocate方法中 allocateTiny是缓存分配的入口 回到acheForTiny方法中 我们简单看下Entry这个类 跟进init方法 上一小节简单分析了directArena内存分配大概流程 ,知道其先命中缓存, 如果命中不到, 则区分配一款连续内存, 这一
-
Netty分布式ByteBuf使用subPage级别内存分配剖析
目录 subPage级别内存分配 我们其中是在构造方法中初始化的, 看构造方法中其初始化代码 在构造方法中创建完毕之后, 会通过循环为其赋值 这里通过normCapacity拿到tableIdx 跟到allocate(normCapacity)方法中 我们跟到PoolSubpage的构造方法中 我们跟到addToPool(head)中 我们跟到allocate()方法中 我们继续跟进findNextAvail方法 我们回到allocate()方法中 我们跟到initBuf方法中 回到initBu
-
Netty分布式ByteBuf使用directArena分配缓冲区过程解析
目录 directArena分配缓冲区 回到newDirectBuffer中 我们跟到newByteBuf方法中 跟到reuse方法中 跟到allocate方法中 1.首先在缓存上进行分配 2.如果在缓存上分配不成功, 则实际分配一块内存 上一小节简单分析了PooledByteBufAllocator中, 线程局部缓存和arean的相关逻辑, 这一小节简单分析下directArena分配缓冲区的相关过程 directArena分配缓冲区 回到newDirectBuffer中 protected
-
Netty分布式ByteBuf中PooledByteBufAllocator剖析
目录 前言 PooledByteBufAllocator分配逻辑 逻辑简述 我们回到newDirectBuffer中 有关缓存列表, 我们循序渐进的往下看 我们在static块中看其初始化过程 我们再次跟到initialValue方法中 我们跟到createSubPageCaches这个方法中 最后并保存其类型 前言 上一小节简单介绍了ByteBufAllocator以及其子类UnPooledByteBufAllocator的缓冲区分类的逻辑, 这一小节开始带大家剖析更为复杂的PooledByt