springboot中使用ElasticSearch的详细教程
新建项目
新建一个springboot项目springboot_es用于本次与ElasticSearch的整合,如下图

引入依赖
修改我们的pom.xml,加入spring-boot-starter-data-elasticsearch
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
编写配置文件
由于ElasticSearch从7.x版本开始淡化TransportClient甚至于在8.x版本中遗弃,所以spring data elasticsearch推荐我们使用rest客户端RestHingLevelClient(端口号使用9200)以及接口ElasticSearchRespositoy。
- RestHighLevelClient 更强大,更灵活,但是不能友好的操作对象
- ElasticSearchRepository 对象操作友好
首先我们编写配置文件如下
/**
* ElasticSearch Rest Client config
* @author Christy
* @date 2021/4/29 19:40
**/
@Configuration
public class ElasticSearchRestClientConfig extends AbstractElasticsearchConfiguration{
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("192.168.8.101:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
springboot操作ES
RestHighLevelClient方式
有了上面的rest client,我们就可以在其他的地方注入该客户端对ElasticSearch进行操作。我们新建一个测试文件,使用客户端对ElasticSearch进行基本的操作
1.注入RestClient
/**
* ElasticSearch Rest client操作
*
* RestHighLevelClient 更强大,更灵活,但是不能友好的操作对象
* ElasticSearchRepository 对象操作友好
*
* 我们使用rest client 主要测试文档的操作
* @Author Christy
* @Date 2021/4/29 19:51
**/
@SpringBootTest
public class TestRestClient {
// 复杂查询使用:比如高亮查询
@Autowired
private RestHighLevelClient restHighLevelClient;
}
2.插入一条文档
/**
* 新增一条文档
* @author Christy
* @date 2021/4/29 20:17
*/
@Test
public void testAdd() throws IOException {
/**
* 向ES中的索引christy下的type类型中添加一天文档
*/
IndexRequest indexRequest = new IndexRequest("christy","user","11");
indexRequest.source("{\"name\":\"齐天大圣孙悟空\",\"age\":685,\"bir\":\"1685-01-01\",\"introduce\":\"花果山水帘洞美猴王齐天大圣孙悟空是也!\"," +
"\"address\":\"花果山\"}", XContentType.JSON);
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(indexResponse.status());
}

我们可以看到文档插入成功,我们去kibana中查询该条文档

完全没有问题的。
3.删除一条文档
/**
* 删除一条文档
* @author Christy
* @date 2021/4/29 20:18
*/
@Test
public void deleteDoc() throws IOException {
// 我们把特朗普删除了
DeleteRequest deleteRequest = new DeleteRequest("christy","user","rYBNG3kBRz-Sn-2f3ViU");
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
}

4.更新一条文档
/**
* 更新一条文档
* @author Christy
* @date 2021/4/29 20:19
*/
@Test
public void updateDoc() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("christy","user","p4AtG3kBRz-Sn-2fMFjj");
updateRequest.doc("{\"name\":\"调皮捣蛋的hardy\"}",XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}

5.批量更新文档
/**
* 批量更新
* @author Christy
* @date 2021/4/29 20:42
*/
@Test
public void bulkUpdate() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
// 添加
IndexRequest indexRequest = new IndexRequest("christy","user","13");
indexRequest.source("{\"name\":\"天蓬元帅猪八戒\",\"age\":985,\"bir\":\"1685-01-01\",\"introduce\":\"天蓬元帅猪八戒因调戏嫦娥被贬下凡\",\"address\":\"高老庄\"}", XContentType.JSON);
bulkRequest.add(indexRequest);
// 删除
DeleteRequest deleteRequest01 = new DeleteRequest("christy","user","pYAtG3kBRz-Sn-2fMFjj");
DeleteRequest deleteRequest02 = new DeleteRequest("christy","user","uhTyGHkBExaVQsl4F9Lj");
DeleteRequest deleteRequest03 = new DeleteRequest("christy","user","C8zCGHkB5KgTrUTeLyE_");
bulkRequest.add(deleteRequest01);
bulkRequest.add(deleteRequest02);
bulkRequest.add(deleteRequest03);
// 修改
UpdateRequest updateRequest = new UpdateRequest("christy","user","10");
updateRequest.doc("{\"name\":\"炼石补天的女娲\"}",XContentType.JSON);
bulkRequest.add(updateRequest);
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
BulkItemResponse[] items = bulkResponse.getItems();
for (BulkItemResponse item : items) {
System.out.println(item.status());
}
}
在kibana中查询结果

6.查询文档
@Test
public void testSearch() throws IOException {
//创建搜索对象
SearchRequest searchRequest = new SearchRequest("christy");
//搜索构建对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery())//执行查询条件
.from(0)//起始条数
.size(10)//每页展示记录
.postFilter(QueryBuilders.matchAllQuery()) //过滤条件
.sort("age", SortOrder.DESC);//排序
//创建搜索请求
searchRequest.types("user").source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("符合条件的文档总数: "+searchResponse.getHits().getTotalHits());
System.out.println("符合条件的文档最大得分: "+searchResponse.getHits().getMaxScore());
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsMap());
}
}

ElasticSearchRepository方式
1.准备工作
ElasticSearchRepository方式主要通过注解和对接口实现的方式来实现ES的操作,我们在实体类上通过注解配置ES索引的映射关系后,当实现了ElasticSearchRepository接口的类第一次操作ES进行插入文档的时候,ES会自动生成所需要的一切。但是该种方式无法实现高亮查询,想要实现高亮查询只能使用RestHighLevelClient
开始之前我们需要熟悉一下接口方式为我们提供的注解,以及编写一些基础的类
1.清空ES数据

2.了解注解
@Document: 代表一个文档记录
indexName: 用来指定索引名称
type: 用来指定索引类型
@Id: 用来将对象中id和ES中_id映射
@Field: 用来指定ES中的字段对应Mapping
type: 用来指定ES中存储类型
analyzer: 用来指定使用哪种分词器
3.新建实体类
/**
* 用在类上作用:将Emp的对象映射成ES中一条json格式文档
* indexName: 用来指定这个对象的转为json文档存入那个索引中 要求:ES服务器中之前不能存在此索引名
* type : 用来指定在当前这个索引下创建的类型名称
*
* @Author Christy
* @Date 2021/4/29 21:22
*/
@Data
@Document(indexName = "christy",type = "user")
public class User {
@Id //用来将对象中id属性与文档中_id 一一对应
private String id;
// 用在属性上 代表mapping中一个属性 一个字段 type:属性 用来指定字段类型 analyzer:指定分词器
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String name;
@Field(type = FieldType.Integer)
private Integer age;
@Field(type = FieldType.Date)
@JsonFormat(pattern = "yyyy-MM-dd")
private Date bir;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String content;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String address;
}
4.UserRepository
/**
* @Author Christy
* @Date 2021/4/29 21:23
**/
public interface
extends ElasticsearchRepository<User,String> {
}
5.TestUserRepository
/**
* @Author Christy
* @Date 2021/4/29 21:51
**/
@SpringBootTest
public class TestUserRepository {
@Autowired
private UserRepository userRepository;
}
2.保存文档
@Test
public void testSaveAndUpdate(){
User user = new User();
// id初识为空,此操作为新增
user.setId(UUID.randomUUID().toString());
user.setName("唐三藏");
user.setBir(new Date());
user.setIntroduce("西方世界如来佛祖大弟子金蝉子转世,十世修行的好人,得道高僧!");
user.setAddress("大唐白马寺");
userRepository.save(user);
}

3.修改文档
@Test
public void testSaveAndUpdate(){
User user = new User();
// 根据id修改信息
user.setId("1666eb47-0bbf-468b-ab45-07758c741461");
user.setName("唐三藏");
user.setBir(new Date());
user.setIntroduce("俗家姓陈,状元之后。西方世界如来佛祖大弟子金蝉子转世,十世修行的好人,得道高僧!");
user.setAddress("大唐白马寺");
userRepository.save(user);
}

4.删除文档
repository接口默认提供了4种删除方式,我们演示根据id进行删除

@Test
public void deleteDoc(){
userRepository.deleteById("1666eb47-0bbf-468b-ab45-07758c741461");
}

5.检索一条记录
@Test
public void testFindOne(){
Optional<User> optional = userRepository.findById("1666eb47-0bbf-468b-ab45-07758c741461");
System.out.println(optional.get());
}

6.查询所有
@Test
public void testFindAll(){
Iterable<User> all = userRepository.findAll();
all.forEach(user-> System.out.println(user));
}

7.排序
@Test
public void testFindAllSort(){
Iterable<User> all = userRepository.findAll(Sort.by(Sort.Order.asc("age")));
all.forEach(user-> System.out.println(user));
}

8.分页
@Test
public void testFindPage(){
//PageRequest.of 参数1: 当前页-1
Page<User> search = userRepository.search(QueryBuilders.matchAllQuery(), PageRequest.of(1, 1));
search.forEach(user-> System.out.println(user));
}

9.自定义查询
先给大家看一个表,是不是很晕_(¦3」∠)_
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And |
findByNameAndPrice |
{"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or |
findByNameOrPrice |
{"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is |
findByName |
{"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not |
findByNameNot |
{"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between |
findByPriceBetween |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
LessThanEqual |
findByPriceLessThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
GreaterThanEqual |
findByPriceGreaterThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Before |
findByPriceBefore |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After |
findByPriceAfter |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like |
findByNameLike |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith |
findByNameStartingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith |
findByNameEndingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
Contains/Containing |
findByNameContaining |
{"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
In |
findByNameIn(Collection<String>names) |
{"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn |
findByNameNotIn(Collection<String>names) |
{"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
Near |
findByStoreNear |
Not Supported Yet ! |
True |
findByAvailableTrue |
{"bool" : {"must" : {"field" : {"available" : true}}}} |
False |
findByAvailableFalse |
{"bool" : {"must" : {"field" : {"available" : false}}}} |
OrderBy |
findByAvailableTrueOrderByNameDesc |
{"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
这个表格看起来复杂,实际上也不简单,但是确实很牛逼。我们只要按照上面的定义在接口中定义相应的方法,无须写实现就可实现我们想要的功能
举个例子,上面有个findByName是下面这样定义的

假如我们现在有个需求需要按照名字查询用户,我们可以在UserRepository中定义一个方法,如下
// 根据姓名查询 List<User> findByName(String name);
系统提供的查询方法中findBy是一个固定写法,像上面我们定义的方法findByName,其中Name是我们实体类中的属性名,这个必须对应上。也就是说这个findByName不仅仅局限于name,还可以findByAddress、findByAge等等;
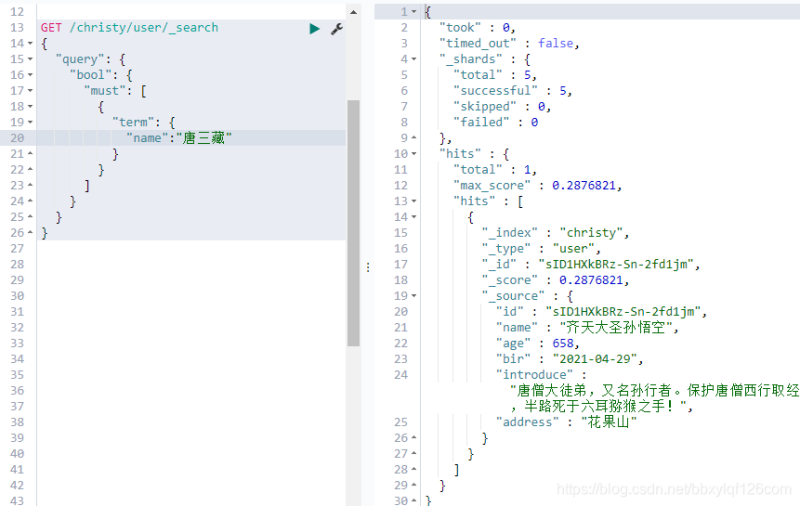
现在就拿findByName来讲,我们要查询名字叫唐三藏的用户
@Test
public void testFindByName(){
List<User> userList = userRepository.findByName("唐三藏");
userList.forEach(user-> System.out.println(user));
}

其实就是框架底层直接使用下面的命令帮我们实现的查询
GET /christy/user/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name":"?"
}
}
]
}
}
}
10.高亮查询
我们上面说了,ElasticSearchRepository实现不了高亮查询,想要实现高亮查询还是需要使用RestHighLevelClient方式。最后我们使用rest clientl实现一次高亮查询
@Test
public void testHighLightQuery() throws IOException, ParseException {
// 创建搜索请求
SearchRequest searchRequest = new SearchRequest("christy");
// 创建搜索对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("introduce", "唐僧")) // 设置查询条件
.from(0) // 起始条数(当前页-1)*size的值
.size(10) // 每页展示条数
.sort("age", SortOrder.DESC) // 排序
.highlighter(new HighlightBuilder().field("*").requireFieldMatch(false).preTags("<span style='color:red;'>").postTags("</span>")); // 设置高亮
searchRequest.types("user").source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = searchResponse.getHits().getHits();
List<User> userList = new ArrayList<>();
for (SearchHit hit : hits) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
User user = new User();
user.setId(hit.getId());
user.setAge(Integer.parseInt(sourceAsMap.get("age").toString()));
user.setBir(new SimpleDateFormat("yyyy-MM-dd").parse(sourceAsMap.get("bir").toString()));
user.setIntroduce(sourceAsMap.get("introduce").toString());
user.setName(sourceAsMap.get("name").toString());
user.setAddress(sourceAsMap.get("address").toString());
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if(highlightFields.containsKey("name")){
user.setName(highlightFields.get("name").fragments()[0].toString());
}
if(highlightFields.containsKey("introduce")){
user.setIntroduce(highlightFields.get("introduce").fragments()[0].toString());
}
if(highlightFields.containsKey("address")){
user.setAddress(highlightFields.get("address").fragments()[0].toString());
}
userList.add(user);
}
userList.forEach(user -> System.out.println(user));
}

到此这篇关于ElasticSearch在springboot中使用的详细教程的文章就介绍到这了,更多相关springboot使用ElasticSearch内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SpringBoot整合ElasticSearch的示例代码
ElasticSearch作为基于Lucene的搜索服务器,既可以作为一个独立的服务部署,也可以签入Web应用中.SpringBoot作为Spring家族的全新框架,使得使用SpringBoot开发Spring应用变得非常简单.本文要介绍如何整合ElasticSearch与SpringBoot. 实体设计: 每一本书(Book)都属于一个分类(Classify),都有一个作者(Author). 生成这个三个实体类,并实现其get和set方法. SpringBoot配置修改: 1.修改pom.xm
-
springboot2.0+elasticsearch5.5+rabbitmq搭建搜索服务的坑
前一阵子准备为项目搭建一个简单的搜索服务,虽然业务数据库mongodb提供了文本搜索的支持,但是在大量文档需要通过关键词进行定位时,es明显更加适合去作为一个搜索引擎(虽然我们之前大部分使用到了ELK那套分析和可视化的特性).Elasticsearch建立在Lucene之上并且支持极其快速的查询和丰富的查询语法,偶尔也可以作为一个轻量级的NoSQL.但是对复杂查询和聚合操作的能力并不是很强. 本篇不会提及如何搭建一个简单搜索服务,而是记录一下大约一周工作时间内遇见的几个坑.. 为什么选择elas
-
es(elasticsearch)整合SpringCloud(SpringBoot)搭建教程详解
注意:适用于springboot或者springcloud框架 1.首先下载相关文件 2.然后需要去启动相关的启动文件 3.导入相关jar包(如果有相关的依赖包不需要导入)以及配置配置文件,并且写一个dao接口继承一个类,在启动类上标注地址 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> &l
-

SpringBoot整合Elasticsearch7.2.0的实现方法
Spring boot 2.1.X整合Elasticsearch最新版的一处问题 新版本的Spring boot 2的spring-boot-starter-data-elasticsearch中支持的Elasticsearch版本是2.X,但Elasticsearch实际上已经发展到7.2.X版本了,为了更好的使用Elasticsearch的新特性,所以弃用了spring-boot-starter-data-elasticsearch依赖,而改为直接使用Spring-data-elastics
-
SpringBoot整合Elasticsearch游标查询的示例代码(scroll)
游标查询(scroll)简介 scroll 查询 可以用来对 Elasticsearch 有效地执行大批量的文档查询,而又不用付出深度分页那种代价. 游标查询会取某个时间点的快照数据. 查询初始化之后索引上的任何变化会被它忽略. 它通过保存旧的数据文件来实现这个特性,结果就像保留初始化时的索引 视图 一样. 启用游标查询可以通过在查询的时候设置参数 scroll 的值为我们期望的游标查询的过期时间. 游标查询的过期时间会在每次做查询的时候刷新,所以这个时间只需要足够处理当前批的结果就可以了,而不
-
Springboot集成spring data elasticsearch过程详解
版本对照 各版本的文档说明:https://docs.spring.io/spring-data/elasticsearch/docs/ 1.在application.yml中添加配置 spring: data: elasticsearch: repositories: enabled: true #多实例集群扩展时需要配置以下两个参数 #cluster-name: datab-search #cluster-nodes: 127.0.0.1:9300,127.0.0.1:9301 2.添加 M
-
SpringBoot整合Spring Data Elasticsearch的过程详解
Spring Data Elasticsearch提供了ElasticsearchTemplate工具类,实现了POJO与elasticsearch文档之间的映射 elasticsearch本质也是存储数据,它不支持事物,但是它的速度远比数据库快得多, 可以这样来对比elasticsearch和数据库 索引(indices)--------数据库(databases) 类型(type)------------数据表(table) 文档(Document)---------------- 行(ro
-
SpringBoot整合Elasticsearch并实现CRUD操作
配置准备 在build.gradle文件中添加如下依赖: compile "org.elasticsearch.client:transport:5.5.2" compile "org.elasticsearch:elasticsearch:5.5.2" //es 5.x的内部使用的 apache log4日志 compile "org.apache.logging.log4j:log4j-core:2.7" compile "org
-
SpringBoot整合ElasticSearch实践
本节我们基于一个发表文章的案例来说明SpringBoot如何elasticsearch集成.elasticsearch本身可以是一个独立的服务,也可以嵌入我们的web应用中,在本案例中,我们讲解如何将elasticsearch嵌入我们的应用中. 案例背景:每个文章(Article)都要属于一个教程(Tutorial),而且每个文章都要有一个作者(Author). 一.实体设计: Tutorial.java public class Tutorial implements Serializable
-
springboot中使用ElasticSearch的详细教程
新建项目 新建一个springboot项目springboot_es用于本次与ElasticSearch的整合,如下图 引入依赖 修改我们的pom.xml,加入spring-boot-starter-data-elasticsearch <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</
-
SpringBoot中使用Ehcache的详细教程
EhCache 是一个纯 Java 的进程内缓存框架,具有快速.精干等特点,是 Hibernate 中默认的 CacheProvider.用惯了 Redis,很多人可能已经忘记了还有 EhCache 这么一个缓存框架 一.简介 EhCache 是一个纯 Java 的进程内缓存框架,具有快速.精干等特点,是 Hibernate 中默认CacheProvider.Ehcache 是一种广泛使用的开源 Java 分布式缓存.主要面向通用缓存,Java EE 和轻量级容器.它具有内存和磁盘存储,缓存加载
-
Springboot启动扩展点超详细教程小结
1.背景 Spring的核心思想就是容器,当容器refresh的时候,外部看上去风平浪静,其实内部则是一片惊涛骇浪,汪洋一片.Springboot更是封装了Spring,遵循约定大于配置,加上自动装配的机制.很多时候我们只要引用了一个依赖,几乎是零配置就能完成一个功能的装配. 我非常喜欢这种自动装配的机制,所以在自己开发中间件和公共依赖工具的时候也会用到这个特性.让使用者以最小的代价接入.想要把自动装配玩的转,就必须要了解spring对于bean的构造生命周期以及各个扩展接口.当然了解了bean
-
IDEA SpringBoot 项目配置Swagger2的详细教程
原先前后端分离的api文档开启了前后端相互撕逼的对接之路 api更新不及时导致对接失败,以及存在测试不够方便,而swagger则很好的解决了这个问题 在项目中也经常用到swagger2,于是动手记录一下swagger2配置过程,希望能带来一点帮助. 在SpringBoot项目当中使用Swagger主要分为以下几步: 1.SpringBoot-web项目并添加pom.xml依赖 2.编写HelloController,测试成功运行 3.创建一个SwaggerConfig类,配置swagger-ui
-
springboot快速集成mybatis-plus的详细教程
简介 Mybatis-Plus(简称MP)是一个 Mybatis 的增强工具,在 Mybatis 的基础上只做增强不做改变,为简化开发.提高效率而生.这是官方给的定义,关于mybatis-plus的更多介绍及特性,可以参考mybatis-plus官网.那么它是怎么增强的呢?其实就是它已经封装好了一些crud方法,我们不需要再写xml了,直接调用这些方法就行,就类似于JPA. springBoot快速集成mybatis-plus 一.pom文件引入mybatis-plus依赖 <dependenc
-
java、spring、springboot中整合Redis的详细讲解
java整合Redis 1.引入依赖或者导入jar包 <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> 2.代码实现 public class JedisTest { public static void main(String[]
-
k3d入门指南之在Docker中运行K3s的详细教程
什么是k3d? k3d是一个小型程序,用于在Docker中运行K3s集群. K3s是经过CNCF认证的轻量级Kubernetes发行和沙箱项目.它是为资源有限环境设计的,被打包为单个二进制文件,所需RAM小于512MB. 要了解有关K3s的更多信息,请查看我们之前的公众号文章及B站上的视频. k3d借助从K3s仓库构建的Docker镜像在安装了Docker的任何机器上的Docker容器中启动多个K3s节点. 这样,一台物理(或虚拟)机(称为Docker Host)可以运行多个K3s集群,每个集群
-
Python中使用ipython的详细教程
ipython简介 ipython他是一个非常流行的python解释器,相比于原生的python解释器,有太多优点和长处,因此几乎是python开发人员的必知必会. 1.ipython相比于原生的python有什么优势 (1) python shell不能在退出保存历史:ipython历史记录自动保存:保存在history.sqlite文件下:可用"_"."__"."___"调用最近三次记录: (2) python shell不支持tab自动补全
-
IntelliJ IDEA中配置Tomcat超详细教程
目录 在IntelliJ IDEA中配置Tomcat 一.下载及安装Tomcat 二.配置Tomcat环境变量 三.在IntelliJ IDEA中配置Tomcat 在IntelliJ IDEA中配置Tomcat 一.下载及安装Tomcat 1.首先进入Tomcat官网:http://tomcat.apache.org/,在Download中选择需要下载的版本,然后根据电脑系统选择64位/32位的zip,开始下载(要记住安装路径!). ps:有zip和exe两种格式的,zip(64-bit Win
-
可能是vue中使用axios最详细教程
目录 安装: 较科学的封装好的axios:(new-axios.js) main.js 引入,添加到vue原型 使用 以下步骤一般不需要 总结 前提条件:vue-cli 项目 安装: npm axios from 'axios' 较科学的封装好的axios:(new-axios.js) import axios from 'axios' import { Notify } from 'vant'; // import Vue from 'vue' // import store from '@/