python保留格式汇总各部门excel内容的实现思路
使用pthon汇总各部门的excel内容,主要思路:
1.使用pandas读入汇总表(b3df)和其中一个部门的表格内容(dedf)
2.填充pandas空值,使'项目名称','主管部门'列没有空值
3.使用xlwings打开汇总表(b3ws)和部门表(dews)
4.用b3df、dedf对比两个表中项目的行数是否一样,不一样则在汇总表(b3ws)插入行,使汇总表和部门表格(dews)一致
5.复制部门表格(dews)内容到汇总表(b3ws)
6.保存退出
汇总表格如下:
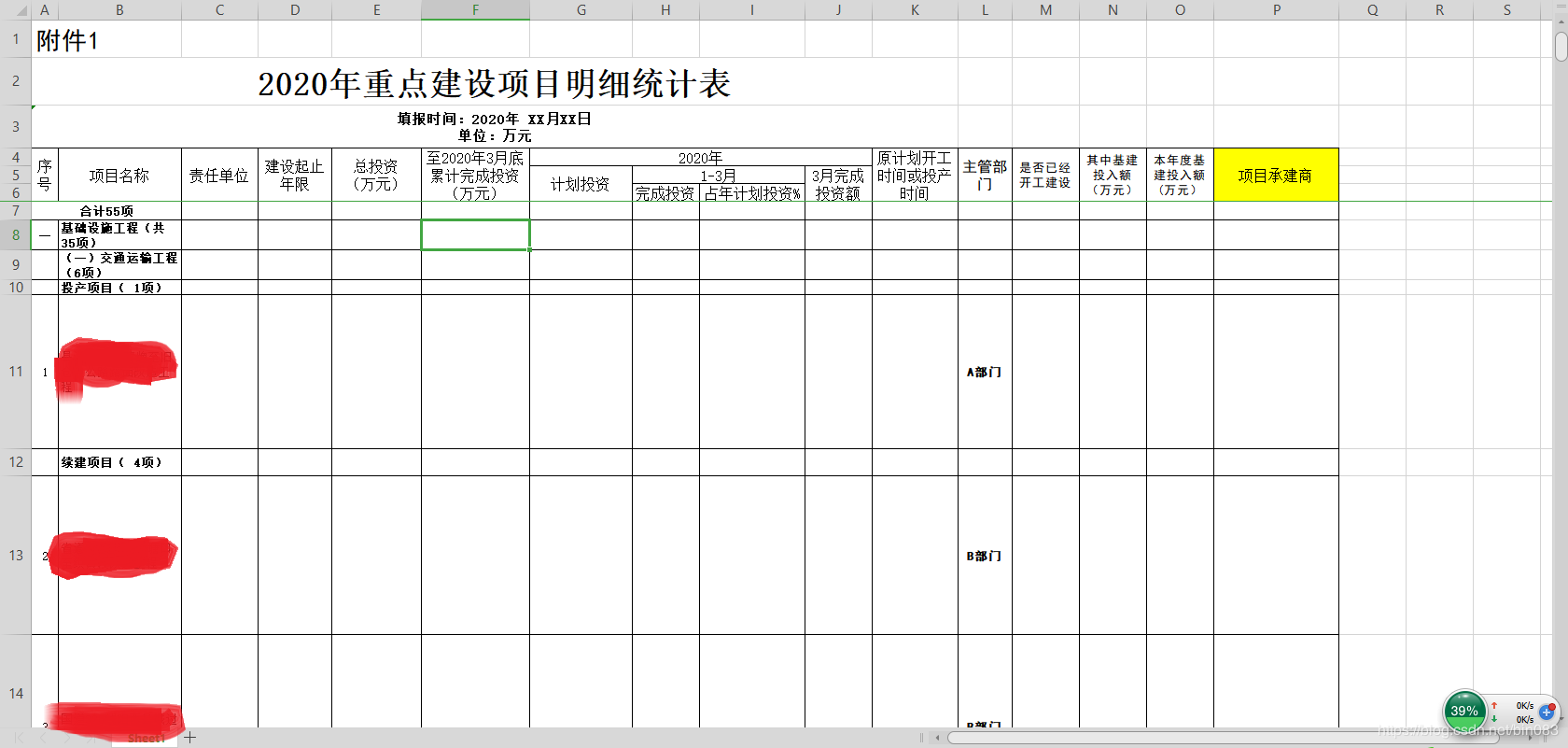
汇总A、B、C、D部门后的表格如下:
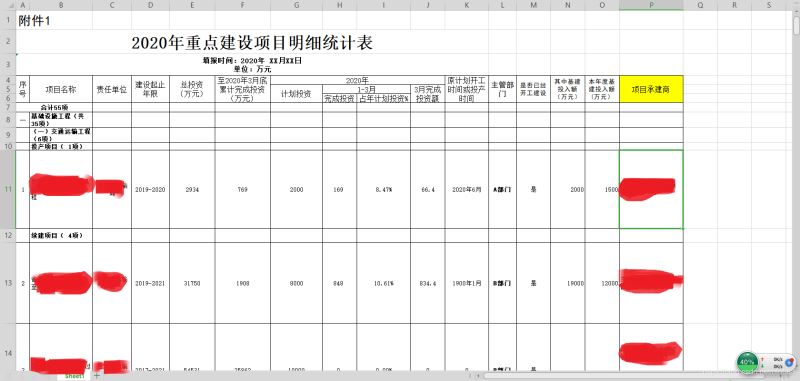
具体代码如下:
import pandas as pd
import xlwings as xw
def insertRow(zgfj,deFile,b3df,b3ws):
'''
'''
print('正在汇总:' + zgfj)
dedf = pd.read_excel(deFile,header=3)
dedf[['项目名称','主管部门']] = dedf[['项目名称','主管部门']].fillna(axis=0,method='ffill')
dewb = app.books.open(deFile)
dews = dewb.sheets[0]
#对比两个表的不同
df1 = pd.pivot_table(dedf[dedf['主管部门']==zgfj],values='责任单位',index='项目名称',aggfunc=[len])
df2 = pd.pivot_table(b3df[b3df['主管部门']==zgfj],values='责任单位',index='项目名称',aggfunc=[len])
df12 = df1 - df2
if df12.shape[0]:
diff = df12[df12[('len','责任单位')] != 0]
#两个表不同则修改excel表,使相同项目的行数相同
#if diff.shape[0]:
for xmmc in list(diff.index):
for r in range(1,b3ws.used_range.shape[0]+1):
if b3ws.range(r,2).value == xmmc:
if diff.loc[xmmc][0] > 0:
print(str(r+1) + ':' + str(int(r+diff.loc[xmmc][0])))
b3ws.api.rows(str(r+1) + ':' + str(int(r+diff.loc[xmmc][0]))).insert #插入部门多出的行
break
else:
b3ws.api.rows(str(r+1) + ':' + str(int(r-diff.loc[xmmc][0]))).delete #删除多余的行
break
#复制部门内容到汇总表
for xmmc in list(df2.index):
for r in range(1,b3ws.used_range.shape[0]+1):
if b3ws.range(r,2).value == xmmc:
#项目名称在部门excel表的行号
rfj = dedf[dedf['项目名称'] == xmmc].index[0] + 5
#需要插入的行数
rows = df1.loc[xmmc][0]
#复制部门excel表格项目名称所在行到汇总表
dews.api.rows(str(rfj) + ':' + str(rfj+rows-1)).Copy(b3ws.api.rows(str(r) + ':' + str(r+rows-1)))
break #因为项目名称唯一,复制后可跳出进行下一项目
if __name__ == '__main__':
#汇总表格文件
b3File = '汇总文件.xls'
#各部门表格文件所在位置
fjFile = {'B部门':'B部门.xls',\
'A部门':'A部门.xls',\
'C部门':'C部门.xls',\
'D部门':'D部门.xls'}
app = xw.App(visible=False,add_book=False)
app.display_alerts = False
app.screen_updating = False
b3wb = app.books.open(b3File)
b3ws = b3wb.sheets[0]
b3df = pd.read_excel(b3File,header=3)
for zgfj,file in fjFile.items():
b3df[['项目名称','主管部门']] = b3df[['项目名称','主管部门']].fillna(axis=0,method='ffill') #填充合并单元格内容
#print(b3df.shape[0])
insertRow(zgfj,file,b3df,b3ws)
b3wb.save('汇总后文件.xls')
app.quit()
app.kill()
总结
到此这篇关于python保留格式汇总各部门excel内容的实现思路的文章就介绍到这了,更多相关python保留格式excel内容内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python格式化输出保留2位小数的实现方法
我是小白就不用多说了,学习python做了个练习题,结果运行了一遍,发现输入金额后得到的有很多位小数, 虽然不知道为什么,但是看得很不舒服, 就想到应该把让小数点后只保留2位数 找到了方法:将{0}改为{:.2f} # 一家商场在降价促销.如果购买金额50-100元(包含50元和100元)之间, # 会给10%的折扣,如果购买金额大于100元会给20%折扣.编写一程序, # 询问购买价格,再显示出折扣(%10或20%)和最终价格 sum_money = float(input('请输入购买总金额
-
python读取tif图片时保留其16bit的编码格式实例
tif图片的编码格式一般是16bit的,在使用python-opencv读取tif文件时,为了保留其编码格式,我们需要用以下的方式: import numpy as np import cv2 img = cv2.imread('demo.tif', -1) print(img.dtype) 输出结果为:uint16 对于opencv中imread函数最后的参数解释如下: 当参数>0时,opencv读取的是3通道的彩色图(灰度图也会被默认转化成彩色图),编码格式会转化成8bit 当参数=0时,o
-

python爬取内容存入Excel实例
最近老师布置了个作业,爬取豆瓣top250的电影信息.按照套路,自然是先去看看源代码了,一看,基本的信息竟然都有,心想这可省事多了.简单分析了下源代码,标记出所需信息的所在标签,ok,开始干活! 鉴于正则表达式的资料已经看了不少,所以本次除了beautifulsoup外,还有些re的使用,当然,比较简单.而爬到信息后,以往一般是存到txt文件,或者数据库中,老是重样的操作,难免有些'厌倦'.心想,干嘛不存到Excel表呢?对啊,可以存到Excel表. 环境准备:pip install openp
-
Python读取txt内容写入xls格式excel中的方法
由于xlwt目前只支持xls格式,至于xlsx格式,后面会继续更新 import xlwt import codecs def Txt_to_Excel(inputTxt,sheetName,start_row,start_col,outputExcel): fr = codecs.open(inputTxt,'r') wb = xlwt.Workbook(encoding = 'utf-8') ws = wb.add_sheet(sheetName) line_number = 0#记录有多少
-
Python实现提取XML内容并保存到Excel中的方法
本文实例讲述了Python实现提取XML内容并保存到Excel中的方法.分享给大家供大家参考,具体如下: 最近做一个项目是解析XML文件,提取其中的chatid和lt.timestamp等信息,存到excel里. 1.解析xml,提取数据 使用python自带的xml.dom中的minidom(也可以用lxml) xml文件如下: minidom.parse()#解析文件,返回DOM对象 _get_documentElement()DOM是树形结构,获得了树形结构的根节点 getElements
-
python保留格式汇总各部门excel内容的实现思路
使用pthon汇总各部门的excel内容,主要思路: 1.使用pandas读入汇总表(b3df)和其中一个部门的表格内容(dedf) 2.填充pandas空值,使'项目名称','主管部门'列没有空值 3.使用xlwings打开汇总表(b3ws)和部门表(dews) 4.用b3df.dedf对比两个表中项目的行数是否一样,不一样则在汇总表(b3ws)插入行,使汇总表和部门表格(dews)一致 5.复制部门表格(dews)内容到汇总表(b3ws) 6.保存退出 汇总表格如下: 汇总A.B.C.D部门
-
python批量生成身份证号到Excel的两种方法实例
身份证号码的编排规则 前1.2位数字表示:所在省份的代码: 第3.4位数字表示:所在城市的代码: 第5.6位数字表示:所在区县的代码: 第7~14位数字表示:出生年.月.日: 第15.16位数字表示:所在地的派出所的代码: 第17位数字表示性别:奇数表示男性,偶数表示女性: 第18位数字是校检码,计算方法如下: (1)将前面的身份证号码17位数分别乘以不同的系数.从第一位到第十七位的系数分别为:7-9-10-5-8-4-2-1-6-3-7-9-10-5-8-4-2. (2)将这17位数字和系数相
-
python使用xlrd与xlwt对excel的读写和格式设定
前言 python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库.本文主要介绍了python使用xlrd与xlwt对excel的读写和格式设定,下面话不多说,来看看详细的实现过程. 脚本里先注明# -*- coding:utf-8 -*- 1. 确认源excel存在并用xlrd读取第一个表单中每行的第一列的数值. import xlrd, xlwt import os assert os.path.isfile('source_ex
-
利用Python实现读取Word表格计算汇总并写入Excel
目录 前言 一.首先导入包 二.读评价表所在的目录文件 三.读word文件,处理word中的表格数据 四.统计计算 五.将统计计算结果写入汇总Excel 完整代码 总结 前言 快过年了,又到了公司年底评级的时候了.今年的评级和往常一下,每个人都要填写公司的民主评议表,给各个同事进行评价打分,然后部门收集起来根据收集上来的评价表进行汇总统计.想想要收集几十号人的评价表,并根据每个人的评价表又要填到Excel中进行汇总计算统计给出每个人的评价,就头大.虽然不是个什么难事,但是是个无脑的细致活.几十个
-
python list格式数据excel导出方法
如下所示: # _*_ coding:utf-8 _*_ #----------------------------------------------- # import modules #----------------------------------------------- import os import xlwt import sys import types def set_style(name, height, bold = False): style = xlwt.XFSt
-
python批量将excel内容进行翻译写入功能
由于小编初来乍到,有很多地方不是很到位,还请见谅,但是很实用的哦! 1.首先是需要进行文件的读写操作,需要获取文件路径,方式使用os.listdir(路径)进行批量查找文件. file_path = '/home/xx/xx/xx' # ret 返回一个列表 ret = list_dir = os.listdir(file_path) # 遍历列表,获取需要的结尾文件(只考虑获取文件,不考虑执行效率) for i in ret : if i.endswith('xlsx'): # 执行的逻辑 2
-
python实现word文档批量转成自定义格式的excel文档的思路及实例代码
支持按照文件夹去批量处理,也可以单独一个文件进行处理,并且可以自定义标识符 最近在开发一个答题类的小程序,到了录入试题进行测试的时候了,发现一个问题,试题都是word文档格式的,每份有100题左右,拿到的第一份试题,光是段落数目就有800个.而且可能有几十份这样的试题. 而word文档是没有固定格式的,想批量录入关系型数据库mysql,必须先转成excel文档.这个如果是手动一个个粘贴到excel表格,那就头大了. 我最终需要的excel文档结构是这样的:每道题独立占1行,每1列是这道题的一项内
-
教你如何利用Python批量翻译英文Word文档并保留格式
一.需求描述 手上有大量外文文档(本案例以5份为例,分别命名为 test1.docx test2.docx 以此类推),其中一份如下: 基本需求:「批量将这些文档的内容全部翻译成中文,并转存到新的文件中」,效果如下: 高级需求:基本需求满足的同时,要求 「保留原文档的格式」,效果如下: 二.逻辑梳理 2.1 翻译 API 本需求的核心是翻译,策略是利用网络的翻译 API,这里推荐百度翻译开放平台,不考虑并发数的话可以用标准版,免费使用不限字符量! " 百度翻译开放平台:http://api.fa
-
Python实现将Excel内容批量导出为PDF文件
目录 序言 实现代码 序言 上一篇咱们实现了多个表格数据合并到一个表格,本次咱们来学习如何将表格数据分开导出为PDF文件. 部分数据 然后需要安装一下这个软件 wkhtmltopdf 不知道怎么下载的可以在电脑端左侧扫一下找到我要 效果展示 数据单独导出为一个PDF 实现代码 import pdfkit import openpyxl import os target_dir = '经销商预算' if not os.path.exists(target_dir): os.mkdir(target
-
python 按照sheet合并多个Excel的示例代码(多个sheet)
工作中会遇到这样的需求,有多个Excel的格式一样,都有多个sheet,且每个sheet的名字和格式一样,我们需要按照sheet 合并,就是说合并后的表的格式和合并钱的格式是一样的.A.B.C表格式如图 现在需要合并成下图: 我这次处理是保留第一个表的首行,其余的表的首行都不保留.因此结果会和上面有所不同,上面的是将所有的首行都保存 import xlrd,xlsxwriter #待合并excel allxls=["C:/xxx/xxx.xlsx", "C:/xxx/xxx.