使用Python webdriver图书馆抢座自动预约的正确方法
文章目录 微信登录问题Python chrome driver操作导入库并声明浏览器:完整流程:用js来预约生成js代码 主函数——程序出错时尝试:检测是否成功:logging: 生成每天的日志文件 Windows定时任务后记:
学校的图书馆需要网上预约。复习考研的人多、疫情座位少,约上一个好点的座位对于我这种经常忘记事情的懒人来说很难。
考虑到老师实验室有一台供我们使用的Windows服务器是不会关机的,正好可以帮我在早上7:00预约系统开启的时候执行程序去预约一个座位。所以产生了这个想法。
微信登录问题
想用chromedriver去操作,方便快捷,但我们图书馆的预约在微信上进行的,在微信公众号上认证过帐号以后,会发送一个链接,点进去就是自己的登录信息。经过和同学的验证,他将他的链接发送给我,我就可以打开他的登录信息。这让我感到很神奇,本以为登录信息仅仅携带在网址上,但如果在微信中用浏览器打开,再将网址复制到其它浏览器,会登陆失败。查找一系列百度谷歌想弄清楚这个问题,应该与cookies之类的有关,这里希望以后可以填坑。
当我没有找到头绪的时候,我偶然间发现学校图书馆开放了另一个入口可以在网页上预约,而这个流程就清晰很多了:
- 进入网站
- 输入账号和密码,点击登录按钮
- 找到座位并选择
Python chrome driver操作
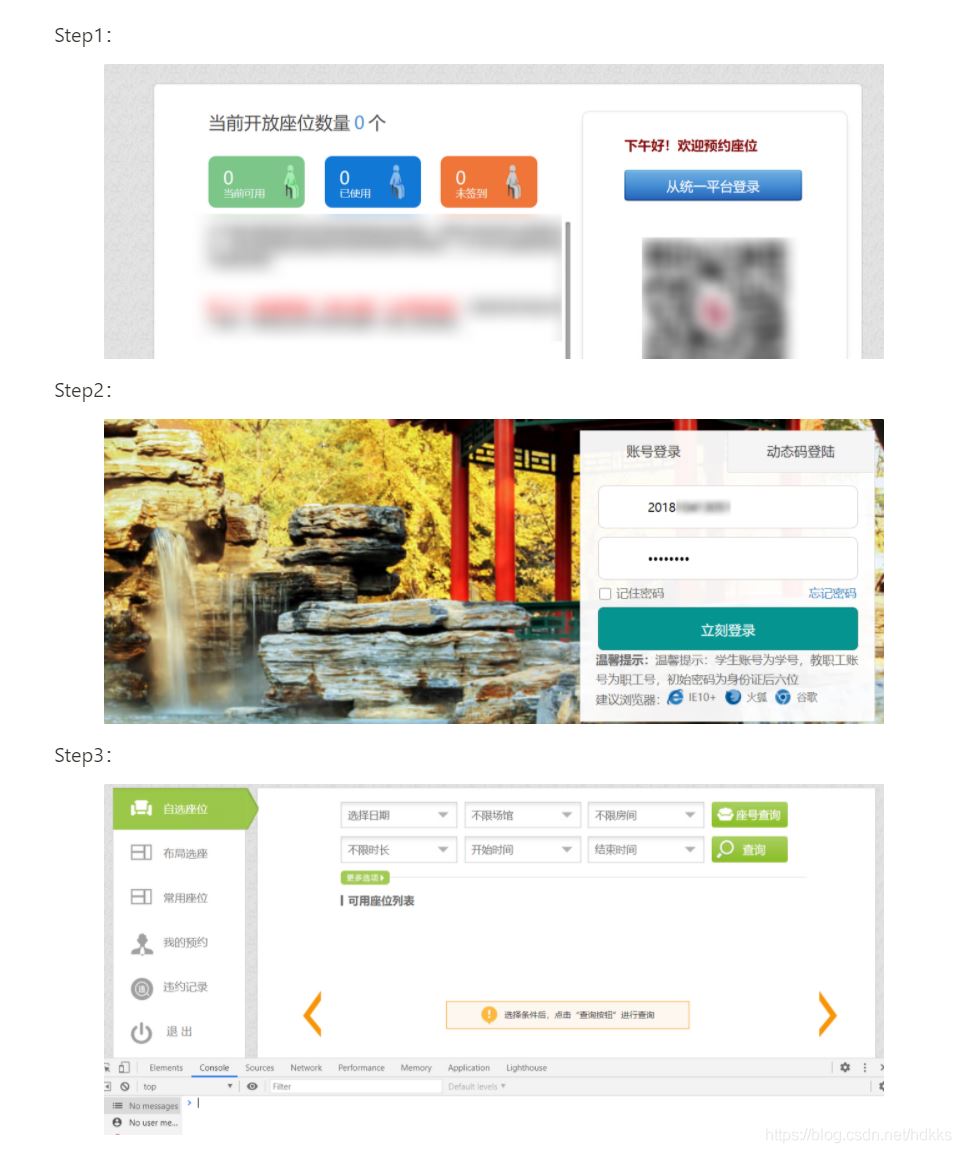
有几个注意的点:
- 每天早上系统开放的时间有几分钟的差别,需要留时间尝试。
- 刚开放的时候,系统会很卡,所以很可能会出现获取元素失败之类的情况。
这就要求我们的程序得有足够的鲁棒性(哈哈蛤) 容错能力,不会一下崩了就没用了。
所以我选择用try...except...的方法去进行,写了好多个try, 希望能找到不写这么多Try的更好的方法。
导入库并声明浏览器:
from selenium import webdriver option = webdriver.ChromeOptions() url='网址' local_dir = 'C:\\Users\\Administrator\\Desktop\\librarytest\\' #webdiriver 位置 browser = webdriver.Chrome(local_dir+"chromedriver.exe",options=option)
完整流程:
使用selenium操作非常简单,就是find_element_by_id()和find_element_by_xpath(),主要是看F12去找他们的xpath或者id。
def wholeProcess(browser):
browser.get(url)
try:
btn=browser.find_element_by_xpath("/html/body/div[4]/div[2]/div[2]/dl/input") #找到登录的按钮,如果没找到证明还没到开放时间/系统在崩溃
except:
return 1 #1说明预约还没到时候
'''执行到这里说明打开啦'''
try:
btn.click()
username=browser.find_element_by_id("un")
password=browser.find_element_by_id("pd")#找到账号密码
username.send_keys(studentNumber)
password.send_keys(loginPassword)
btn=browser.find_element_by_xpath('//*[@id="index_login_btn"]/input')#找到登录按键
btn.click()
js=generateJsCode(startTime,endTime)#使用js代码来预约
res=browser.execute_script(js)
return 0
except:
return 2 #2说明打开了网页,但是遇到了其它问题
用js来预约
找到座位并选择,如果用鼠标操作的话是很繁琐的,包括先找到座位图标,点击,下拉选择开始时间和结束时间,再点击预约,这个过程麻烦不说,主要是容易出错。
而其实一个座位预定的本质其实是提交一个表单。浏览器的前端做了那么多人性化的操作,如可视化座位表、下拉框、温馨提示等,就是为了人使用时好看而又方便,而我们作为计算机就可以饶过他,直接提交表单。这里用的是selenium的execute_script()函数,可以用来执行网页上的js代码。
生成js代码
用F12去观察发现,图书管的表单提交需要下面几步:
$("#date").val("2020-12-10");
$("#reserveForm#seat").val("13022"); //座位号
$("#start").val("540"); //用分钟表示的时间 : 540=9*60 即九点
$("#end").val("1260");
$("#reserveForm").submit();
因此这个函数用来生成js代码:
def generateJsCode(startTime_ori,endTime_ori):
seatnumber_str = seatId
startTime_str = str(startTime_ori * 60)
endTime_str = str(endTime_ori * 60)
tomorrowTime = (datetime.datetime.now() + datetime.timedelta(days=1)).strftime('%Y-%m-%d') # 明天
js = '$("#date").val("' + tomorrowTime + '");$("#reserveForm #seat").val("' + seatnumber_str + '");$("#start").val("' + startTime_str + '");$("#end").val("' + endTime_str + '");$("#reserveForm").submit();'
return js
主函数——程序出错时尝试:
返回的状态中,如果网页没打开,让他休息10s再尝试,如果是其它原因,那么休息0.5秒就继续尝试:
if __name__=='__main__':
browser = webdriver.Chrome(local_dir+"chromedriver.exe",options=option)#声明浏览器
while True:
state=wholeProcess(browser)
if state==0: #没出错
break:
elif state==1:
logger.info("打开网页失败")
time.sleep(10)
elif state==2:
logger.info("其它错误")
time.sleep(0.5)
检测是否成功:
除了上面提到的网页崩溃导致WebDriver报错,还有几种可能导致失败:
- 座位被人抢了😟
- 已经有过预约了
- 有人约了但不是全部时间段。
这几种错误都不会报错,会在执行代码后以标签的形式告诉我们,可以用关键字定位这些标签,如果失败可以选择预约PlanB:
比如:
try:
a=browser.find_element_by_xpath("//*[contains(text(),'尽快')]") #有人约了(非全部时间)
error_reason=a.text
isNoSeat=True
logging: 生成每天的日志文件
写好小程序以后,几个兄弟听说了也想尝试,每天预约。
不想每天早上七点起来看,为了防止为止错误发生后还不知道是哪步出错,采取的办法是写日志文件(事后追责),这里使用的是logging这个包。
logger的初始化代码来源 : python的logging模块
import logging
# 创建一个logger
logger = logging.getLogger('mylogger')
logger.setLevel(logging.DEBUG)
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler(local_dir+'logfile\\'+logname+'.log')
fh.setLevel(logging.DEBUG)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 定义handler的输出格式
formatter = logging.Formatter('[%(asctime)s][%(thread)d][%(filename)s][line: %(lineno)d][%(levelname)s] ## %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
logger.addHandler(fh)
logger.addHandler(ch)
# 记录一条日志
记录时只要使用 logger.info("xxxxx")就可以,非常方便,写在了上面。
Windows定时任务
- 此电脑上右键管理
- 右侧有创建任务(下图)
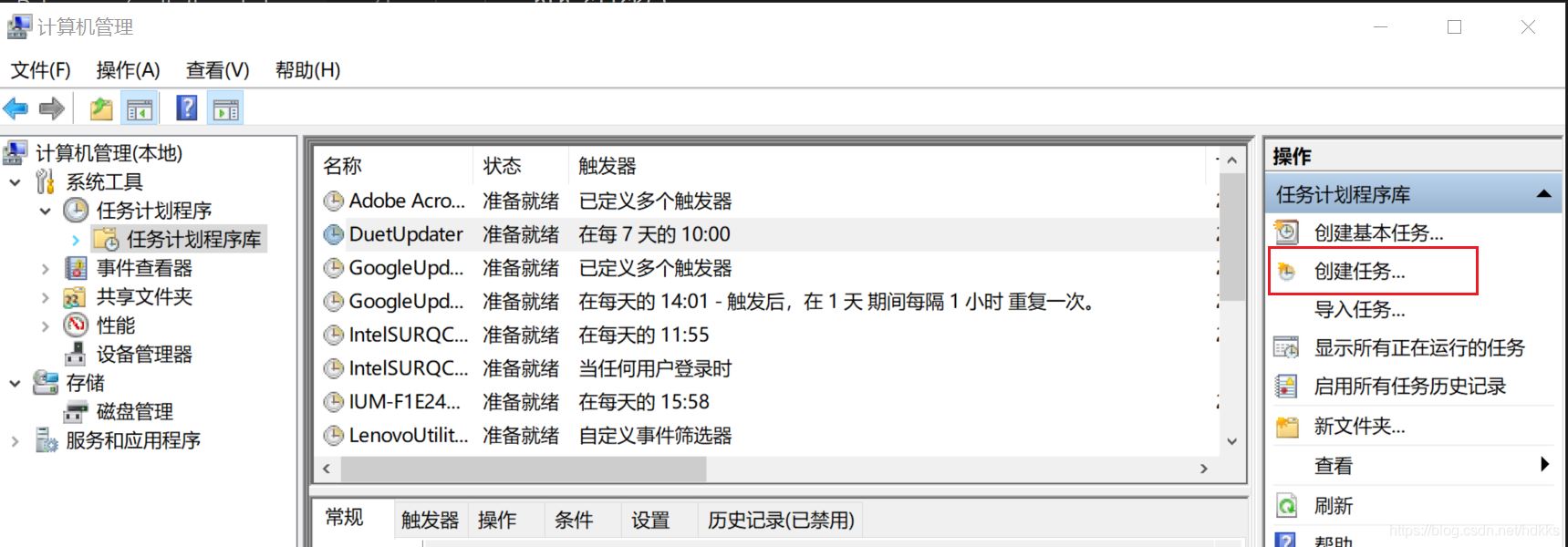
- 在触发器选项卡中新建,并设定时间
- 在操作选项卡中新建,并选择程序路径(下图)
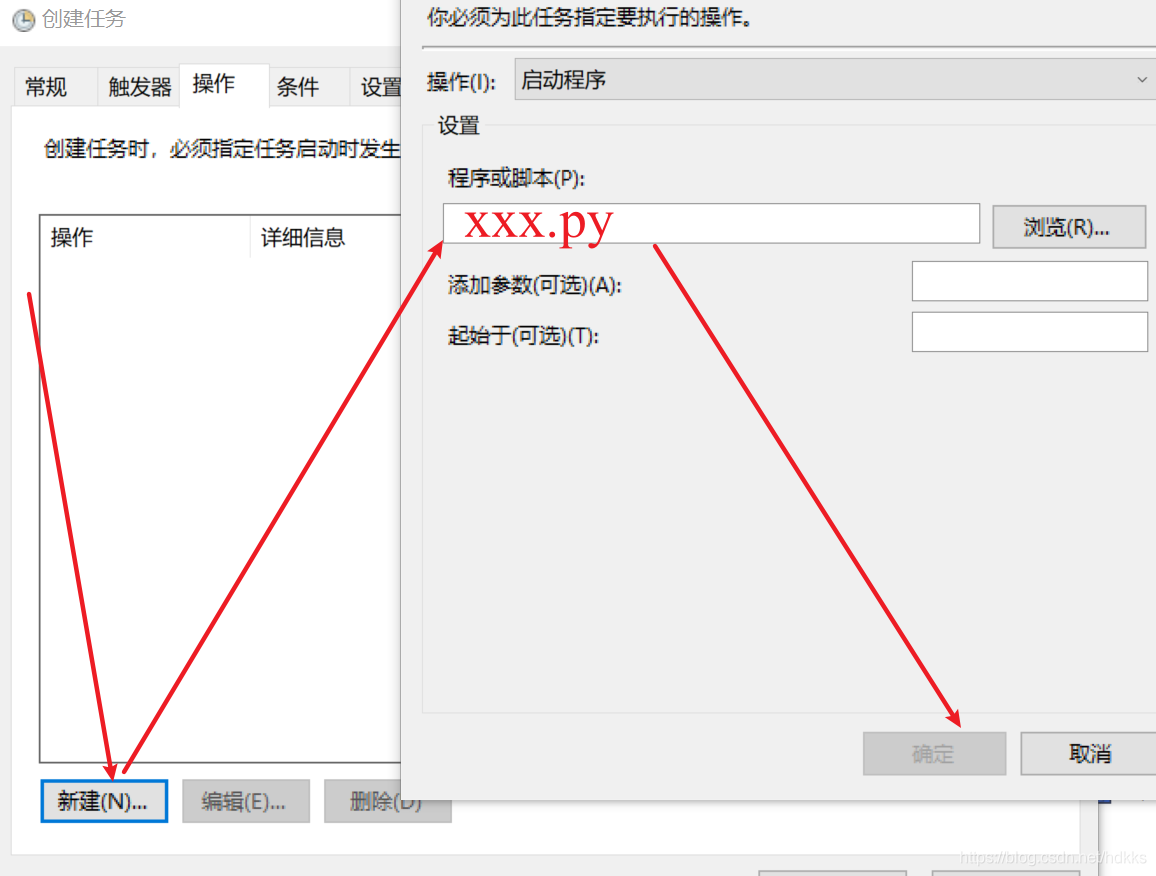
这样就程序就会每天早上执行,只要有一台不关机的电脑。
后记:
大家开始使用我的代码,但都是我放在学校的服务器上,为了方便他们修改自己想要的预约时间、位置等信息,我写了个微信小程序方便同学修改时间。
思路就是使用微信小程序修改自己的预约信息,同步到微信的数据库。
早上预约时,我的程序通过微信云开发数据库的API获取到这些预约信息(时间、座位、学号、密码),再去预约,免去了总要去服务器上修改程序/参数的麻烦事。
具体的小程序部分的内容这里不展开,以后再写日记。
这就是上学期快期末的时候搞的一个小事情,虽然原理非常简单,但能帮自己和同学去预约图书馆还是很快乐的,尤其是每天早上醒来大家都收到企业微信的“预约成功”的提示的时候,然而过程中还有一些没懂的知识和没填的坑,所以在CSDN写个小记,怕以后忘了。
到此这篇关于使用Python webdriver图书馆抢座自动预约的正确方法的文章就介绍到这了,更多相关Python webdriver图书馆抢座自动预约内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
selenium+python自动化测试之使用webdriver操作浏览器的方法
WebDriver简介 selenium从2.0开始集成了webdriver的API,提供了更简单,更简洁的编程接口.selenium webdriver的目标是提供一个设计良好的面向对象的API,提供了更好的支持进行web-app测试.从这篇博客开始,将学习使用如何使用python调用webdriver框架对浏览器进行一系列的操作 打开浏览器 在selenium+python自动化测试(一)–环境搭建中,运行了一个测试脚本,脚本内容如下: from selenium import webdri
-

python实现图书馆抢座(自动预约)功能的示例代码
脚本功能 系统开放座位时快速预约指定位置 可以设置预约的时间段 运行以后会一直帮你抢,需要手动停止 即使遇到更强的脚本自动帮抢下一个座位 实现 首先解决登录问题,通过F12找出登录请求包,分析对比一下包可以发现一般只有用户名和密码这个参数是变化的,然后用requests.session()的实例化去请求登录接口,登录成功. 然后预约座位抓一下包,分析包找到变化的关键的参数,一般情况下关键参数只有座位id.开始时间.结束时间,其他的参数一股脑照搬就行了,接下来用刚刚登录成功的那个requests.
-
用python-webdriver实现自动填表的示例代码
在日常工作中常常需要重复填写某些表单,如果人工完成,费时费力,而且网络延迟令人十分崩溃.如果能够用程序实现自动填表,效率可以提高一倍以上,并且能够移植到多台计算机,进一步提高工作效率.webdriver是python的selenium库中的一个自动化测试工具,它能完全模拟浏览器的操作,无需处理复杂的request.post,对爬虫初学者十分友好. 一.环境配置 python3.6+selenium库+xlrd库+xlwt库 其中xlrd和xlwt库用于读写excel表中的数据. 还要下载一个浏览
-
python+webdriver自动化环境搭建步骤详解
python是一个很好脚本语言工具,现在也比较流行的一个脚本语言工具,对目前web自动化可以用的比较是webdriver框架进行自动化测试,脚本写起来较简单,运行的占用的内容较小.那么对windown下python+webdriver自动化环境如何进行搭建. 下载一个python.exe文件,直接默认安装即可 配置python的环境,指定到python的路径 安装pip环境,从网上下载一个pip,解压完成后,进入解压目录下执行python setup install 安装selenium文件,在
-
Python Requests模拟登录实现图书馆座位自动预约
本文实例为大家分享了Python实现图书馆座位自动预约的具体代码,供大家参考,具体内容如下 配置 通过公网主机定时运行脚本,并发送邮件到自己的qq邮箱,这样在微信就会有消息提示是否预约成功 vim /etc/crontab 设置每到早上7:01自动运行脚本即可 程序流程 (以yuyue.juneberry.cn网站为例) get访问登录页面,获取cookie和表单里面的隐藏post字段 构造登录post数据,加入从表单里面拿到的隐藏post字段 post构造后的数据,模拟登录,激活cookie(
-
python实现图书馆研习室自动预约功能
本文为大家分享了python实现图书馆研习室自动预约的具体代码,供大家参考,具体内容如下 简介 现在好多学校为学生提供了非常良好的学习环境,通常体现在自习教室的设施设备上.对此不得不提一句的就是我们学校的图书馆,随着新图书馆的修建,馆内也设置了多个功能区,每层分为A.B.C.D四个区域,由南北连廊相连,中间由旋转楼梯贯通一至五层.A区为自修区:B区和C区为藏阅一体的社会科学和自然科学书库:D区为专项功能区,包含影视厅.数字媒体创客体验中心.智慧培训教室.云桌面电子阅览室等:B.C区东西连廊设有大
-
python使用webdriver爬取微信公众号
本文实例为大家分享了python使用webdriver爬取微信公众号的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- from selenium import webdriver import time import json import requests import re import random #微信公众号账号 user="" #公众号密码 password="" #设置要爬取的公众号列表 gzlist=['香河微服务
-
使用Python webdriver图书馆抢座自动预约的正确方法
文章目录 微信登录问题Python chrome driver操作导入库并声明浏览器:完整流程:用js来预约生成js代码 主函数--程序出错时尝试:检测是否成功:logging: 生成每天的日志文件 Windows定时任务后记: 学校的图书馆需要网上预约.复习考研的人多.疫情座位少,约上一个好点的座位对于我这种经常忘记事情的懒人来说很难. 考虑到老师实验室有一台供我们使用的Windows服务器是不会关机的,正好可以帮我在早上7:00预约系统开启的时候执行程序去预约一个座位.所以产生了这个想法.
-
Python中list循环遍历删除数据的正确方法
前言 初学Python,遇到过这样的问题,在遍历list的时候,删除符合条件的数据,可是总是报异常,代码如下: num_list = [1, 2, 3, 4, 5] print(num_list) for i in range(len(num_list)): if num_list[i] == 2: num_list.pop(i) else: print(num_list[i]) print(num_list) 会报异常:IndexError: list index out of range 原
-
python实现12306抢票及自动邮件发送提醒付款功能
#写在前面,这个程序我已经弄出来了,但是因为黄牛泛滥以及懒人太多,整个程序的代码就不贴出来了,这里纯粹就是技术交流. 只做技术交流..... 嗯,程序结束后,自己还是得手动付款. 废话不多说,下面就直接开始技术主要部分阐述. 先讲理论部分:首先我们需要代码实现一个浏览器功能,那么模块基本上可以确定urllib.parse.urllib.request,这两个包都是和网址有关的模块,那么咱们去登录一个网址,特别是有验证码这些的网址,我们登录进去是不是就行了?答案是对的,但是我们用代码实现的话,这个
-
基于Python实现火车票抢票软件
目录 导语 环境准备 项目思路 代码展示 导语 每年的节假日一到,大家头疼的总时同一个问题:你买到回家的票了吗? 尤其是大型的节日:”比如国庆.春节......“ 数以亿计的人口迁移,让车票成了一年里最难买到的那张票. 跨站买票.买短途票上车补票.准点捡漏等已是老生常谈的技巧.随着互联网的发展,抢票软件成为购票热门渠道.抢票软件的到底靠谱嘛?能抢到票嘛? 近日,小编给大家就正式编写一款Python实现查票以及自动购票抢票的小程序给大家,希望大家如愿! 环境准备 1)运行环境:Python 3 .
-
Python实现京东抢秒杀功能
京东购物车抢购商品 1.Python的下载和安装 这里由于我们代码是基于Python来执行的 所以我们这里需要2个东西: 一个是Python本身,另一个是pycharm,只需要这两个哦!!! 网上有很多教程,所以我在这里就不一一赘述了 2.系统环境,模块的配置 安装好Python,请移步我的另一篇博客,根据前面的3个步骤完成环境的配置 Python实现淘宝秒杀 3.京东抢秒杀代码 注意!!: ①将代码复制到pycharm中执行 ②注意代码修改最后的时间 ③需要安装火狐浏览器 ④京东扫码登录 ⑤!
-
python根据文章标题内容自动生成摘要的实例
text.py title = '智能金融起锚:文因.数库.通联瞄准的kensho革命' text = '''2015年9月13日,39岁的鲍捷乘上从硅谷至北京的飞机,开启了他心中的金融梦想. 鲍捷,人工智能博士后,如今他是文因互联公司创始人兼CEO.和鲍捷一样,越来越多的硅谷以及华尔街的金融和科技人才已经踏上了归国创业征程. 在硅谷和华尔街,已涌现出Alphasense.Kensho等智能金融公司. 如今,这些公司已经成长为独角兽. 大数据.算法驱动的人工智能已经进入到金融领域.人工智能有望在
-
python selenium 查找隐藏元素 自动播放视频功能
在使用python做爬虫的过程中,有些页面的的部分数据是通过js异步加载的,js调用接口的请求中有时还带有些加密的参数很难破解无法使用requests这样的包直接爬取数据,因此需要借助seleniu来完成js的自动加载. 通过selenium 模拟浏览器的真是操作来获取页面中的所有请求,并且可以查找到一下页面上一些隐藏的元素,这些元素在html源码中无法看到,并且和能通过xpath和正则来捕获,因此需要使用selenium来查找隐藏元素,例如视频网站的播放按钮 代码如下 import time