Python中threading库实现线程锁与释放锁
控制资源访问
前文提到threading库在多线程时,对同一资源的访问容易导致破坏与丢失数据。为了保证安全的访问一个资源对象,我们需要创建锁。
示例如下:
import threading
import time
class AddThread():
def __init__(self, start=0):
self.lock = threading.Lock()
self.value = start
def increment(self):
print("Wait Lock")
self.lock.acquire()
try:
print("Acquire Lock")
self.value += 1
print(self.value)
finally:
self.lock.release()
def worker(a):
time.sleep(1)
a.increment()
addThread = AddThread()
for i in range(3):
t = threading.Thread(target=worker, args=(addThread,))
t.start()
运行之后,效果如下:
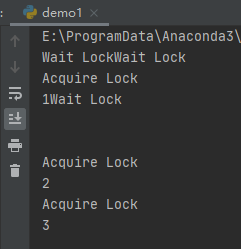
acquire()会通过锁进行阻塞其他线程执行中间段,release()释放锁,可以看到,基本都是获得锁之后才执行。避免了多个线程同时改变其资源对象,不会造成混乱。
判断是否有另一个线程请求锁
要确定是否有另一个线程请求锁而不影响当前的线程,可以设置acquire()的参数blocking=False。
示例如下:
import threading
import time
def worker2(lock):
print("worker2 Wait Lock")
while True:
lock.acquire()
try:
print("Holding")
time.sleep(0.5)
finally:
print("not Holding")
lock.release()
time.sleep(0.5)
def worker1(lock):
print("worker1 Wait Lock")
num_acquire = 0
value = 0
while num_acquire < 3:
time.sleep(0.5)
have_it = lock.acquire(blocking=False)
try:
value += 1
print(value)
print("Acquire Lock")
if have_it:
num_acquire += 1
finally:
print("release Lock")
if have_it:
lock.release()
lock = threading.Lock()
word2Thread = threading.Thread(
target=worker2,
name='work2',
args=(lock,)
)
word2Thread.start()
word1Thread = threading.Thread(
target=worker1,
name='work1',
args=(lock,)
)
word1Thread.start()
运行之后,效果如下:

这里,我们需要迭代很多次,work1才能获取3次锁。但是尝试了很8次。
with lock
前文,我们通过lock.acquire()与lock.release()实现了锁的获取与释放,但其实我们Python还给我们提供了一个更简单的语法,通过with lock来获取与释放锁。
示例如下:
import threading
import time
class AddThread():
def __init__(self, start=0):
self.lock = threading.Lock()
self.value = start
def increment(self):
print("Wait Lock")
with self.lock:
print("lock acquire")
self.value += 1
print(self.value)
print("lock release")
def worker(a):
time.sleep(1)
a.increment()
addThread = AddThread()
for i in range(3):
t = threading.Thread(target=worker, args=(addThread,))
t.start()
这里,我们只是将最上面的例子改变了一下。效果如下:
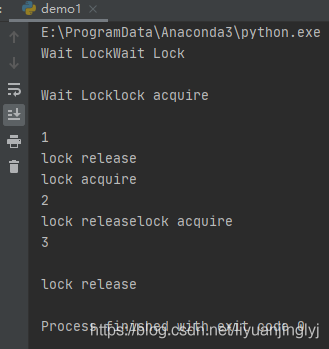
需要注意的是,正常的Lock对象不能请求多次,即使是由同一个线程请求也不例外。如果同一个调用链中的多个函数访问一个锁,则会发生意外。如果期望在同一个线程的不同代码需要重新获得锁,那么这种情况下使用RLock。
同步线程
Condition
在实际的操作中,我们还可以使用Condition对象来同步线程。由于Condition使用了一个Lock,所以它可以绑定到一个共享资源,允许多个线程等待资源的更新。
示例如下:
import threading
import time
def consumer(cond):
print("waitCon")
with cond:
cond.wait()
print('获取更新的资源')
def producer(cond):
print("worker")
with cond:
print('更新资源')
cond.notifyAll()
cond = threading.Condition()
t1 = threading.Thread(name='t1', target=consumer, args=(cond,))
t2 = threading.Thread(name='t2', target=consumer, args=(cond,))
t3 = threading.Thread(name='t3', target=producer, args=(cond,))
t1.start()
time.sleep(0.2)
t2.start()
time.sleep(0.2)
t3.start()
运行之后,效果如下:

这里,我们通过producer线程处理完成之后调用notifyAll(),consumer等线程等到了它的更新,可以类比为观察者模式。这里是,当一个线程用完资源之后时,则会自动通知依赖它的所有线程。
屏障(barrier)
屏障是另一种线程的同步机制。barrier会建立一个控制点,所有参与的线程会在这里阻塞,直到所有这些参与方都到达这一点。采用这种方法,线程可以单独启动然后暂停,直到所有线程都准备好了才可以继续。
示例如下:
import threading
import time
def worker(barrier):
print(threading.current_thread().getName(), "worker")
worker_id = barrier.wait()
print(threading.current_thread().getName(), worker_id)
threads = []
barrier = threading.Barrier(3)
for i in range(3):
threads.append(
threading.Thread(
name="t" + str(i),
target=worker,
args=(barrier,)
)
)
for t in threads:
print(t.name, 'starting')
t.start()
time.sleep(0.1)
for t in threads:
t.join()
运行之后,效果如下:

从控制台的输出会发发现,barrier.wait()会阻塞线程,直到所有线程被创建后,才同时释放越过这个控制点继续执行。wait()的返回值指示了释放的参与线程数,可以用来限制一些线程做清理资源等动作。
当然屏障Barrier还有一个abort()方法,该方法可以使所有等待线程接收一个BroKenBarrierError。如果线程在wait()上被阻塞而停止处理,会产生这个异常,通过except可以完成清理工作。
有限资源的并发访问
除了多线程可能访问同一个资源之外,有时候为了性能,我们也会限制多线程访问同一个资源的数量。例如,线程池支持同时连接,但数据可能是固定的,或者一个网络APP提供的并发下载数支持固定数目。这些连接就可以使用Semaphore来管理。
示例如下:
import threading
import time
class WorkerThread(threading.Thread):
def __init__(self):
super(WorkerThread, self).__init__()
self.lock = threading.Lock()
self.value = 0
def increment(self):
with self.lock:
self.value += 1
print(self.value)
def worker(s, pool):
with s:
print(threading.current_thread().getName())
pool.increment()
time.sleep(1)
pool.increment()
pool = WorkerThread()
s = threading.Semaphore(2)
for i in range(5):
t = threading.Thread(
name="t" + str(i),
target=worker,
args=(s, pool,)
)
t.start()
运行之后,效果如下:

从图片虽然能看所有输出,但无法看到其停顿的事件。读者自己运行会发现,每次顶多只有两个线程在工作,是因为我们设置了threading.Semaphore(2)。
隐藏资源
在实际的项目中,有些资源需要锁定以便于多个线程使用,而另外一些资源则需要保护,以使它们对并非使这些资源的所有者的线程隐藏。
local()函数会创建一个对象,它能够隐藏值,使其在不同的线程中无法被看到。示例如下:
import threading
import random
def show_data(data):
try:
result = data.value
except AttributeError:
print(threading.current_thread().getName(), "No value")
else:
print(threading.current_thread().getName(), "value=", result)
def worker(data):
show_data(data)
data.value = random.randint(1, 100)
show_data(data)
local_data = threading.local()
show_data(local_data)
local_data.value = 1000
show_data(local_data)
for i in range(2):
t = threading.Thread(
name="t" + str(i),
target=worker,
args=(local_data,)
)
t.start()
运行之后,效果如下:
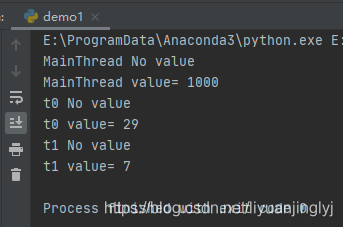
这里local_data.value对所有线程都不可见,除非在某个线程中设置了这个属性,这个线程才能看到它。
到此这篇关于Python中threading库实现线程锁与释放锁的文章就介绍到这了,更多相关Python 线程锁与释放锁内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
举例讲解Python编程中对线程锁的使用
锁 python的内置数据结构比如列表和字典等是线程安全的,但是简单数据类型比如整数和浮点数则不是线程安全的,要这些简单数据类型的通过操作,就需要使用锁. #!/usr/bin/env python3 # coding=utf-8 import threading shared_resource_with_lock = 0 shared_resource_with_no_lock = 0 COUNT = 100000 shared_resource_lock = threading.Lock()
-
python线程锁(thread)学习示例
复制代码 代码如下: # encoding: UTF-8import threadimport time # 一个用于在线程中执行的函数def func(): for i in range(5): print 'func' time.sleep(1) # 结束当前线程 # 这个方法与thread.exit_thread()等价 thread.exit() # 当func返回时,线程同样会结束 # 启动一个线程,线程立即开始运行# 这个方法与threa
-

Python中threading库实现线程锁与释放锁
控制资源访问 前文提到threading库在多线程时,对同一资源的访问容易导致破坏与丢失数据.为了保证安全的访问一个资源对象,我们需要创建锁. 示例如下: import threading import time class AddThread(): def __init__(self, start=0): self.lock = threading.Lock() self.value = start def increment(self): print("Wait Lock") se
-
python中threading开启关闭线程操作
在python中启动和关闭线程: 首先导入threading import threading 然后定义一个方法 def serial_read(): ... ... 然后定义线程,target指向要执行的方法 myThread = threading.Thread(target=serial_read) 启动它 myThread.start() 二.停止线程 不多说了直接上代码 import inspect import ctypes def _async_raise(tid, exctype
-
python中threading和queue库实现多线程编程
摘要 本文主要介绍了利用python的 threading和queue库实现多线程编程,并封装为一个类,方便读者嵌入自己的业务逻辑.最后以机器学习的一个超参数选择为例进行演示. 多线程实现逻辑封装 实例化该类后,在.object_func函数中加入自己的业务逻辑,再调用.run方法即可. # -*- coding: utf-8 -*- # @Time : 2021/2/4 14:36 # @Author : CyrusMay WJ # @FileName: run.py # @Software:
-
python中threading超线程用法实例分析
本文实例讲述了python中threading超线程用法.分享给大家供大家参考.具体分析如下: threading基于Java的线程模型设计.锁(Lock)和条件变量(Condition)在Java中是对象的基本行为(每一个对象都自带了锁和条件变量),而在Python中则是独立的对象.Python Thread提供了Java Thread的行为的子集:没有优先级.线程组,线程也不能被停止.暂停.恢复.中断.Java Thread中的部分被Python实现了的静态方法在threading中以模块方
-
简述Python中的进程、线程、协程
进程.线程和协程之间的关系和区别也困扰我一阵子了,最近有一些心得,写一下. 进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度. 线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程是的). 协程和线程一样共享堆,不共享栈,协程由程序员在协程的代码里显示调度. 进程和其他两个的区别还是很明显的. 协程和线程的区别是:协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任,同时,协程也失去了标准线程使用多CPU的能力. Pyt
-
Python中Threading用法详解
Python的threading模块松散地基于Java的threading模块.但现在线程没有优先级,没有线程组,不能被销毁.停止.暂停.开始和打断. Java Thread类的静态方法,被移植成了模块方法. main thread: 运行python程序的线程 daemon thread 守护线程,如果守护线程之外的线程都结束了.守护线程也会结束,并强行终止整个程序.不要在守护进程中进行资源相关操作.会导致资源不能正确的释放.在非守护进程中使用Event. Thread 类 (group=No
-
详解Python中的进程和线程
进程是什么? 进程就是一个程序在一个数据集上的一次动态执行过程.进程一般由程序.数据集.进程控制块三部分组成.我们编写的程序用来描述进程要完成哪些功能以及如何完成:数据集则是程序在执行过程中所需要使用的资源:进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志. 线程是什么? 线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID.程序计数器.寄存器集合和堆栈共同组成.线程的引入减小了程序并发
-
Python中threading模块join函数用法实例分析
本文实例讲述了Python中threading模块join函数用法.分享给大家供大家参考.具体分析如下: join的作用是众所周知的,阻塞进程直到线程执行完毕.通用的做法是我们启动一批线程,最后join这些线程结束,例如: for i in range(10): t = ThreadTest(i) thread_arr.append(t) for i in range(10): thread_arr[i].start() for i in range(10): thread_arr[i].joi
-
在python中实现强制关闭线程的示例
如下所示: import threading import time import inspect import ctypes def _async_raise(tid, exctype): """raises the exception, performs cleanup if needed""" tid = ctypes.c_long(tid) if not inspect.isclass(exctype): exctype = type(e
-
Python 使用threading+Queue实现线程池示例
一.线程池 1.为什么需要使用线程池 1.1 创建/销毁线程伴随着系统开销,过于频繁的创建/销毁线程,会很大程度上影响处理效率. 记创建线程消耗时间T1,执行任务消耗时间T2,销毁线程消耗时间T3,如果T1+T3>T2,那说明开启一个线程来执行这个任务太不划算了!在线程池缓存线程可用已有的闲置线程来执行新任务,避免了创建/销毁带来的系统开销. 1.2 线程并发数量过多,抢占系统资源从而导致阻塞. 线程能共享系统资源,如果同时执行的线程过多,就有可能导致系统资源不足而产生阻塞的情况. 1.3 对线