pd.read_csv读取文件路径出现的问题解决
目录
- 写在前面
- 出现的问题
- 解决问题
- 用相对路径读取数据集
- 完整的代码
- 参考
写在前面
在用pd.read_csv读取数据集时,我有2个疑问?1是:写相对路径还是绝对路径。2是:相对路径,绝对路径怎么写。这篇文章就是解决以上两个问题。如果这个脚本只是在自己电脑上,都可以无所谓,但是如果别人也想用你的脚本,我认为相对路径还是比较好的,数据集和脚本一起拷贝给别人,如果环境没问题的话路径不用修改就可以直接运行,如果你用绝对路径的话,别人拿到之后还得自己修改路径。
出现的问题
报错,这个路径没找到文件,路径写错了。

解决问题
一般是数据集与你的脚本在一个文件夹下。 我用的是绝对路径
第1步打印脚本所在的路径
import os os.getcwd() print(os.getcwd())

第2步
加上你的数据集路径
train = pd.read_csv('F:\\pythonProject3\\data\\data\\train.csv')
下面是我的脚本和数据集的文件。
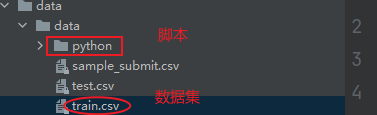
第3步测试一下
print(train)

用相对路径读取数据集
前提数据集与脚本不在同一个文件下,但同在上一级文件夹。就是下面这种情况。
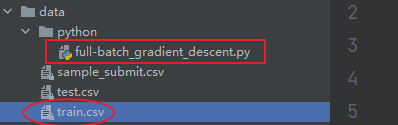
读取文件方式
train = pd.read_csv('..\\train.csv')
图中的“..”表示是当前所处的文件夹上一级文件夹的绝对路径。也就是我下图中data路径
F:\pythonProject3\data\data
实在不理解可以自己试试
import os
path1=os.path.abspath('.') #表示当前所处的文件夹的绝对路径
print("path1@@@@@",path1)
path2=os.path.abspath('..') ## 表示当前所处的文件夹上一级文件夹的绝对路径
print("path2@@@@@",path2)
完整的代码
import pandas as pd
import numpy as np
import os
os.getcwd()
# F:\\pythonProject3\\data\\data\\train.csv
# dataset_path = '..'
train = pd.read_csv('..\\train.csv')
path1=os.path.abspath('.')
print("path1@@@@@",path1)
path2=os.path.abspath('..')
print("path2@@@@@",path2)
print(train)
参考
https://www.jb51.net/article/168860.htm
到此这篇关于pd.read_csv读取文件路径出现的问题解决的文章就介绍到这了,更多相关pd.read_csv读取文件路径内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

pandas pd.read_csv()函数中parse_dates()参数的用法说明
parse_dates : boolean or list of ints or names or list of lists or dict, default False boolean. If True -> try parsing the index. list of ints or names. e.g. If [1, 2, 3] -> try parsing columns 1, 2, 3 each as a separate date column. list of lists.
-
pd.read_csv读取文件路径出现的问题解决
目录 写在前面 出现的问题 解决问题 用相对路径读取数据集 完整的代码 参考 写在前面 在用pd.read_csv读取数据集时,我有2个疑问?1是:写相对路径还是绝对路径.2是:相对路径,绝对路径怎么写.这篇文章就是解决以上两个问题.如果这个脚本只是在自己电脑上,都可以无所谓,但是如果别人也想用你的脚本,我认为相对路径还是比较好的,数据集和脚本一起拷贝给别人,如果环境没问题的话路径不用修改就可以直接运行,如果你用绝对路径的话,别人拿到之后还得自己修改路径. 出现的问题 报错,这个路径没找到文件,
-
利用Pandas读取文件路径或文件名称包含中文的csv文件方法
利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错,无法导入: import pandas as pd df=pd.read_csv('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') 解决方法如下: import pandas as pd f=open('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') df=pd.read_csv(f) 以上这篇利用Pandas读取文件路径或文件名称包含中文的csv文件方法就是小编
-
解决pandas使用read_csv()读取文件遇到的问题
如下: 数据文件: 上海机场 (sh600009) 24.11 3.58 东风汽车 (sh600006) 74.25 1.74 中国国贸 (sh600007) 26.38 2.66 包钢股份 (sh600010) 61.01 2.35 武钢股份 (sh600005) 75.85 1.3 浦发银行 (sh600000) 6.65 0.96 在使用read_csv() API读取CSV文件时求取某一列数据比较大小时, df=pd.read_csv(output_file,encoding='gb23
-
Pandas之read_csv()读取文件跳过报错行的解决
读取文件时遇到和列数不对应的行,此时会报错.若报错行可以忽略,则添加以下参数: 样式: pandas.read_csv(***,error_bad_lines=False) pandas.read_csv(filePath) 方法来读取csv文件时,可能会出现这种错误: ParserError:Error tokenizing data.C error:Expected 2 fields in line 407,saw 3. 是指在csv文件的第407行数据,期待2个字段,但在第407行实际发现
-
java 读取文件路径空格、"+"和中文的处理方法
有时候在java代码中读取文件,如果文件所在路径包含空格."+"号或者是中文的时候,由于这些特殊的字符会被进行编码转译,所以就会报没有发现文件的错误,那么遇到这种错误,我们就要把编码过后的路径进行解码,这样才能正确的找到文件.主要的解决方法有一下三种方法: 解决方法 1.替换法 比如文件路径如果存在空格,那么会被转译成"%20",那么就可以利用字符串替换,把"%20"传化成空格,这样就能正确的找到文件了.这是这种如此暴力,低级的处理方法,一般有经
-
SpringBoot中jar启动下如何读取文件路径
目录 SpringBoot jar启动下读取文件路径 代码如下 截图如下 SpringBoot获取路径的方式 前置条件 SpringBoot jar启动下读取文件路径 由于我们经常使用jar 包作为我们的项目启动方式 以及我们经常会设涉及到生成文件这时候就需要一个文件路劲存放临时文件 因为我们正在存放可以在第三方服务器或者自己文件服务器. 下面就介绍一种jar 下生成文件存放示例. 代码如下 @GetMapping("/index") public String getFile() t
-
Java代码读取文件缓存问题解决
一.业务场景 最近遇到了一个Java文件读取的缓存问题,打远程断点出现的也是原来的老代码参数,好在晚上十点突然找到了解决方案,豁然开朗,现整理分享思路,希望对遇到同样文件读取缓存问题的你有帮助 我更新几次插件包后,服务器也缓存也清理了 我本地用postman调用测试,下载的文件是新文件,但是上线后发现下载下来的文件是老文件 下载下来的文件还是原来的文件,文件大小28.5K,我动态写入部分数据,按道理下载下来的文件大小应该比这个大 业务场景: 我现在需要获取一个Java项目resource目录下的
-
Java中关于文件路径读取问题的分析
Java读取文件路径 记录一种通用获取文件绝对路径的方法,即使代码换了位置了,这样编写也是通用的: 注意: 使用以下方法的前提是文件必须在类路径下,类路径:凡是在src下的都是类路径. 1.拿到User.properties文件的绝对路径: package com.lxc.domain; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.
-
node.js通过url读取文件
本文实例为大家分享了node.js通过url读取文件的具体代码,供大家参考,具体内容如下 在浏览器地址栏中输入127.0.0.1:3000和127.0.0.1:3000/node时,读取node.html文件,输入127.0.0.1:3000/banner时读取banner.json文件 准备工作 首先我们在www的文件目录下新建两个文件,一个是node.htnl,一个是banner.json,并在文件中添加一点内容 1.新建01.js文件并导入模块 let fs = require("fs&q
-
.Net Core读取文件时中文乱码问题的解决方法分享
目录 背景 问题 .NETFramework中的默认属性 .NETCore上的默认属性 解决办法 附.NetCore下读取配置文件中文乱码 总结 背景 今天在使用core web api上传txt文档的时候本来很顺利的,但是一测试发现读取的中文内容是乱码的,很是纳闷. 出于经验,立马把代码的Encoding.Default改成 Encoding.uft8, 发现还是不行.后面索性把上传的文件另存为下,特地选择带有bom的utf8选项. 但是发现还是乱码.郁闷. 问题 于是在本能的百度下,发现方法