Java HashMap中除了死循环之外的那些问题
目录
- 1.死循环问题
- 1.1 死循环执行流程一
- 1.2 死循环执行流程二
- 1.3 死循环执行流程三
- 1.4 解决方案
- 2.数据覆盖问题
- 2.1 数据覆盖执行流程一
- 2.2 数据覆盖执行流程二
- 2.3 数据覆盖执行流程三
- 2.4 解决方案
- 3.无序性问题
- 3.1 解决方案
- 总结
前言:
本篇的这个问题是一个开放性问题,HashMap 除了死循环之外,还有其他什么问题?总体来说 HashMap 的所有“问题”,都是因为使用(HashMap)不当才导致的,这些问题大致可以分为两类:
- 程序问题:比如 HashMap 在 JDK 1.7 中,并发插入时可能会发生死循环或数据覆盖的问题。
- 业务问题:比如 HashMap 无序性造成查询结果和预期结果不相符的问题。
接下来我们一个一个来看。
1.死循环问题
死循环问题发生在 JDK 1.7 版本中,形成的原因是 JDK 1.7 HashMap 使用的是头插法,那么在并发扩容时可能就会导致死循环的问题,具体产生的过程如下流程所示。
HashMap 正常情况下的扩容实现如下图所示:
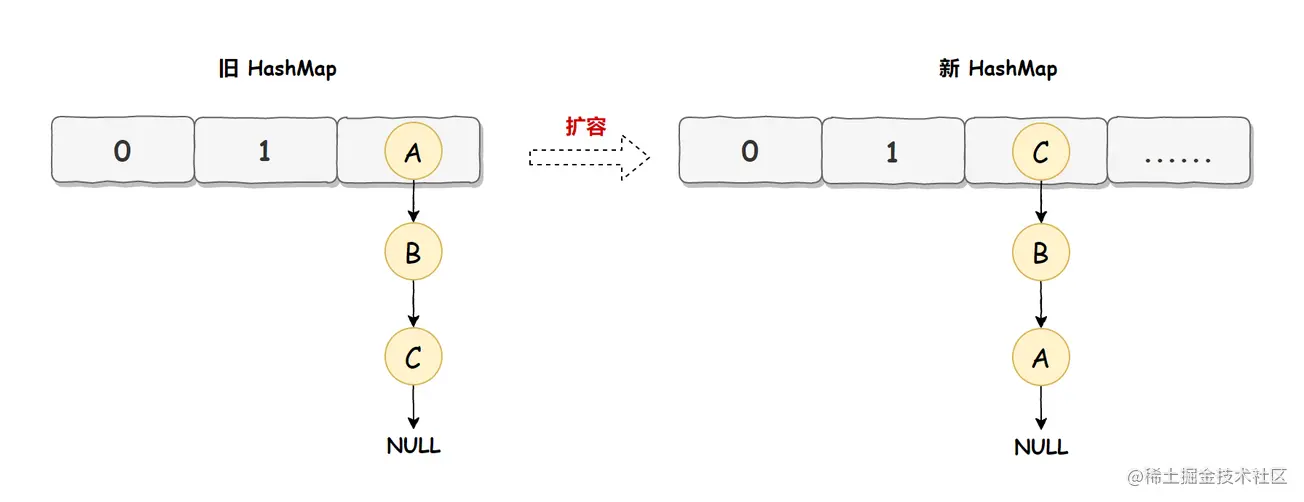
旧 HashMap 的节点会依次转移到新 HashMap 中,旧 HashMap 转移的顺序是 A、B、C,而新 HashMap 使用的是头插法,所以最终在新 HashMap 中的顺序是 C、B、A,也就是上图展示的那样。有了这些前置知识之后,咱们来看死循环是如何诞生的?
1.1 死循环执行流程一
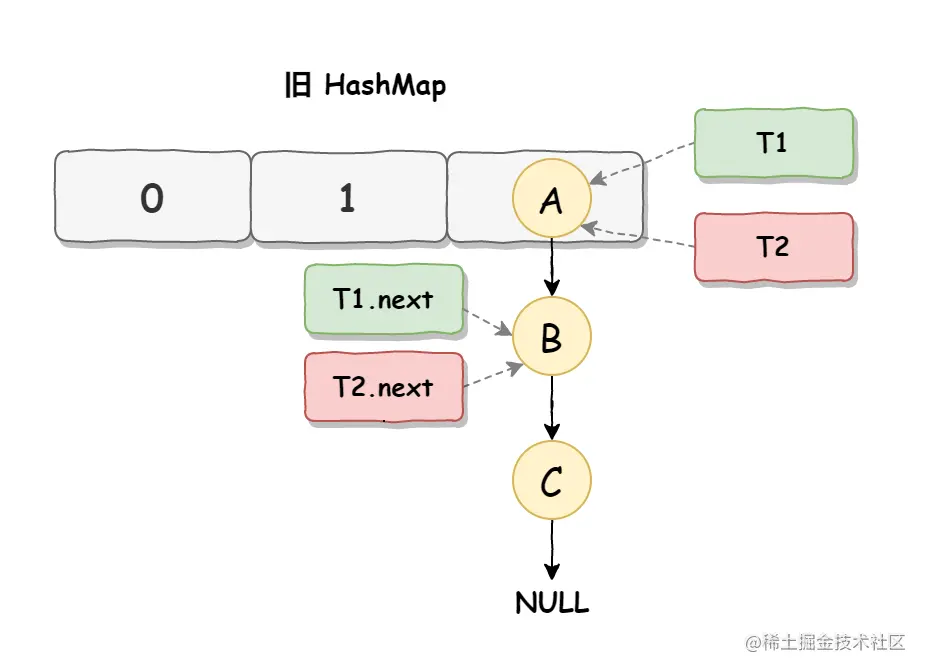
死循环是因为并发 HashMap 扩容导致的,并发扩容的第一步,线程 T1 和线程 T2 要对 HashMap 进行扩容操作,此时 T1 和 T2 指向的是链表的头结点元素 A,而 T1 和 T2 的下一个节点,也就是 T1.next 和 T2.next 指向的是 B 节点,
如下图所示:
1.2 死循环执行流程二
死循环的第二步操作是,线程 T2 时间片用完进入休眠状态,而线程 T1 开始执行扩容操作,一直到线程 T1 扩容完成后,线程 T2 才被唤醒,扩容之后的场景如下图所示:
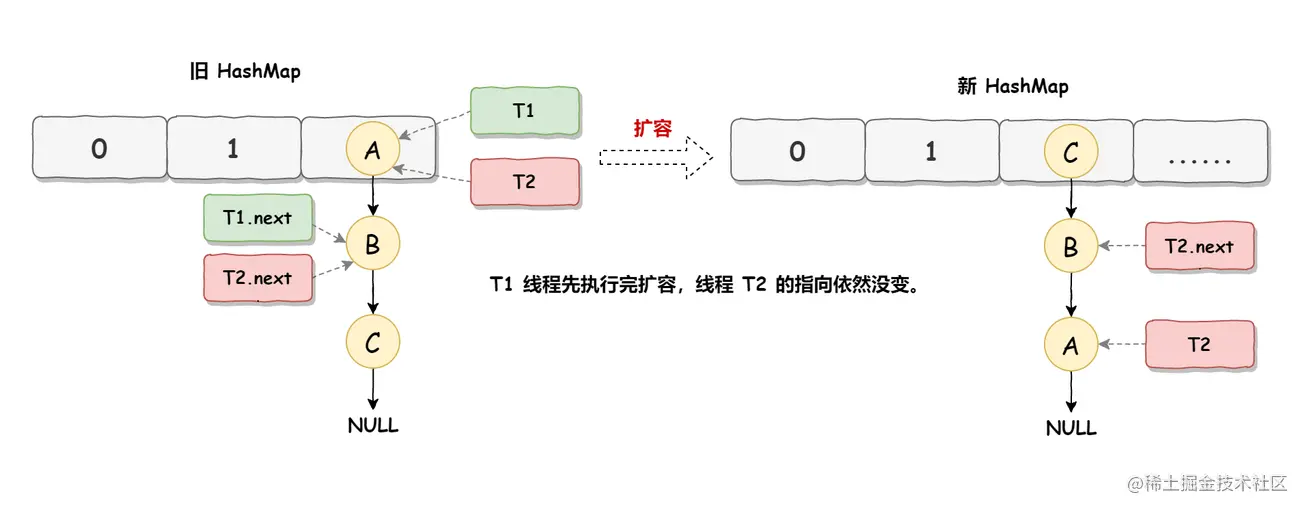
从上图可知线程 T1 执行之后,因为是头插法,所以 HashMap 的顺序已经发生了改变,但线程 T2 对于发生的一切是不可知的,所以它的指向元素依然没变,如上图展示的那样,T2 指向的是 A 元素,T2.next 指向的节点是 B 元素。
1.3 死循环执行流程三
当线程 T1 执行完,而线程 T2 恢复执行时,死循环就建立了,如下图所示:
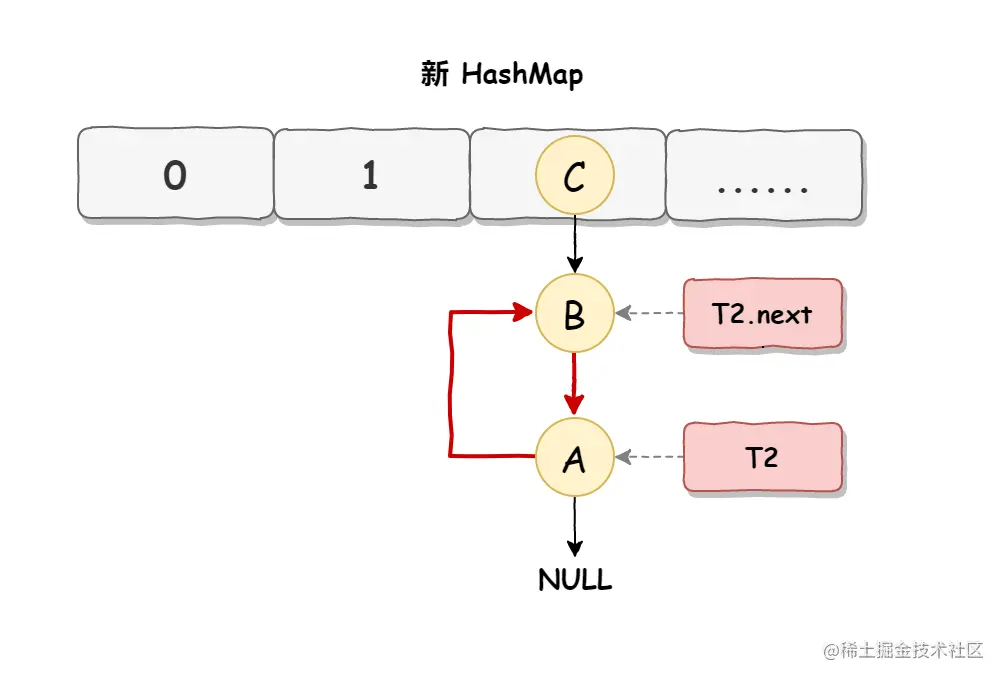
因为 T1 执行完扩容之后 B 节点的下一个节点是 A,而 T2 线程指向的首节点是 A,第二个节点是 B,这个顺序刚好和 T1 扩完容完之后的节点顺序是相反的。T1 执行完之后的顺序是 B 到 A,而 T2 的顺序是 A 到 B,这样 A 节点和 B 节点就形成死循环了,这就是 HashMap 死循环导致的原因。
1.4 解决方案
使用线程安全的容器来替代 HashMap,比如 ConcurrentHashMap 或 Hashtable,因为 ConcurrentHashMap 的性能远高于 Hashtable,因此推荐使用 ConcurrentHashMap 来替代 HashMap。
2.数据覆盖问题
数据覆盖问题发生在并发添加元素的场景下,它不止出现在 JDK 1.7 版本中,其他版本中也存在此问题
数据覆盖产生的流程如下:
- 线程 T1 进行添加时,判断某个位置可以插入元素,但还没有真正的进行插入操作,自己时间片就用完了。
- 线程 T2 也执行添加操作,并且 T2 产生的哈希值和 T1 相同,也就是 T2 即将要存储的位置和 T1 相同,因为此位置尚未插入值(T1 线程执行了一半),于是 T2 就把自己的值存入到当前位置了。
- T1 恢复执行之后,因为非空判断已经执行完了,它感知不到此位置已经有值了,于是就把自己的值也插入到了此位置,那么 T2 的值就被覆盖了。
具体执行流程如下图所示。
2.1 数据覆盖执行流程一
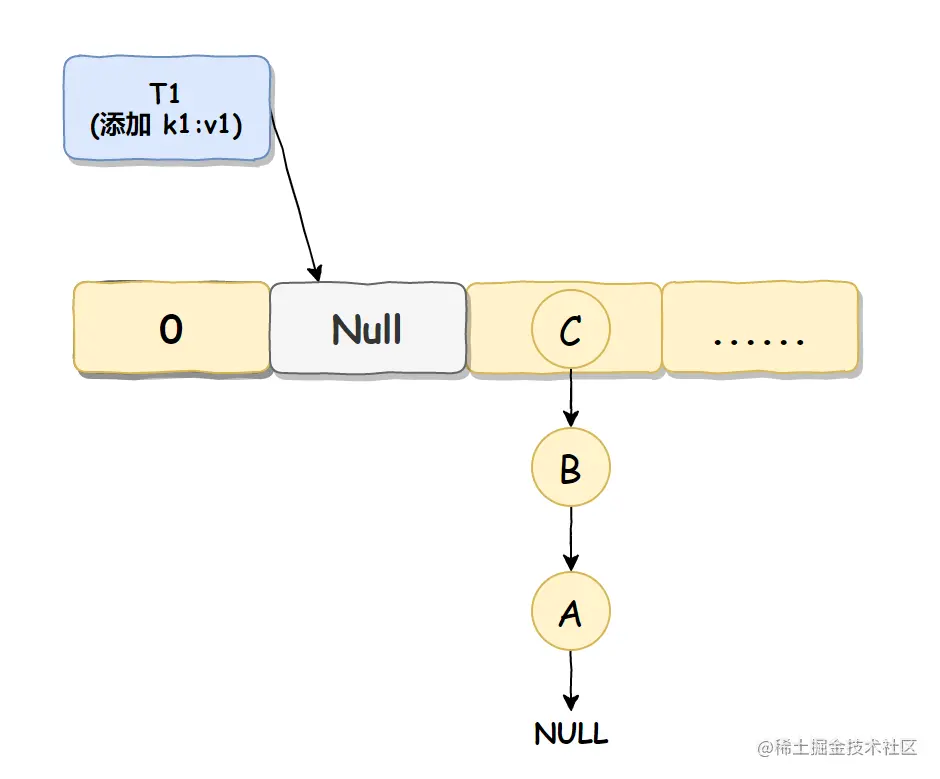
线程 T1 准备将数据 k1:v1 插入到 Null 处,但还没有真正的执行,自己的时间片就用完了,进入休眠状态了,
如下图所示:
2.2 数据覆盖执行流程二
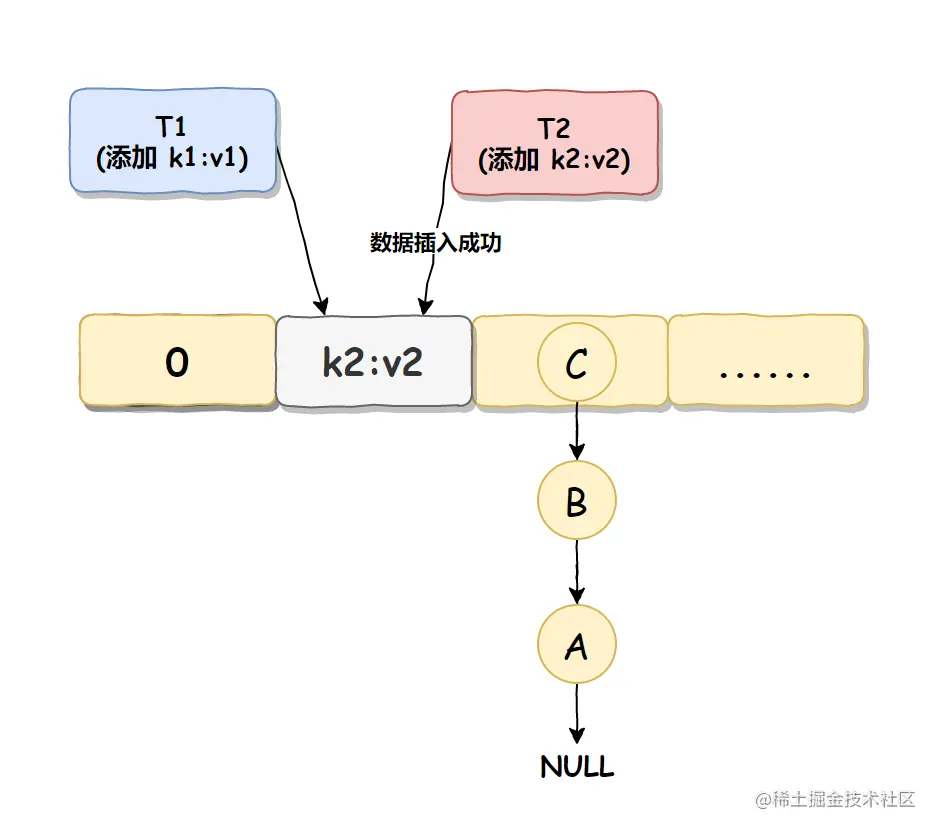
线程 T2 准备将数据 k2:v2 插入到 Null 处,因为此处现在并未有值,如果此处有值的话,它会使用链式法将数据插入到下一个没值的位置上,但判断之后发现此处并未有值,那么就直接进行数据插入了,
如下图所示:
2.3 数据覆盖执行流程三
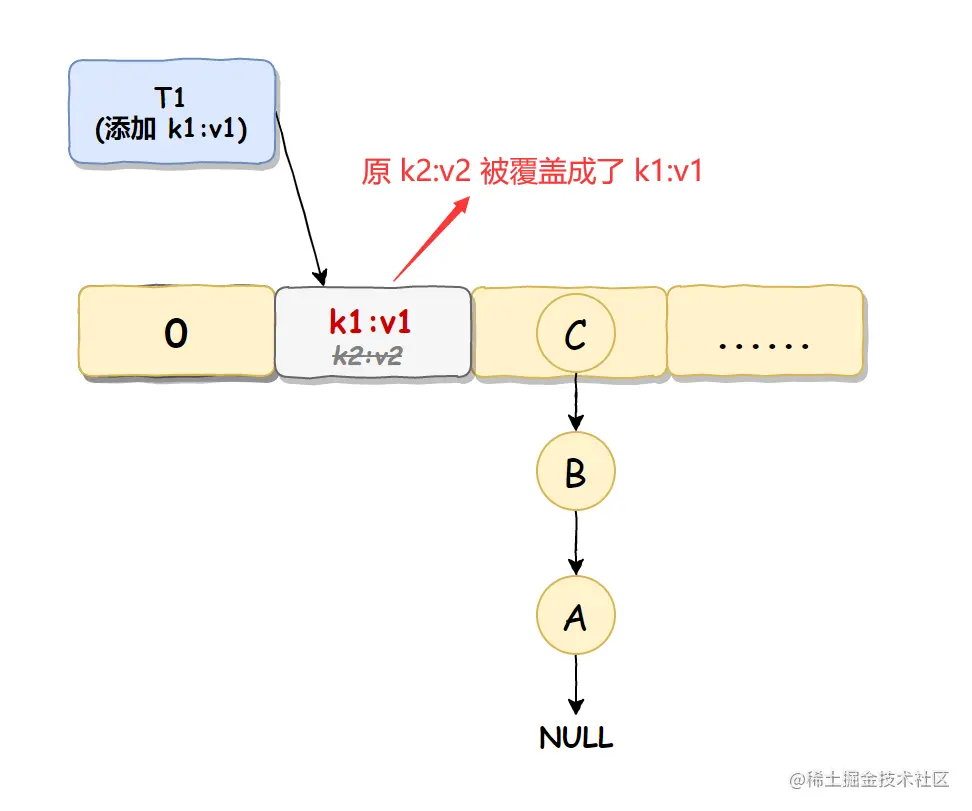
线程 T2 执行完成之后,线程 T1 恢复执行,因为线程 T1 之前已经判断过此位置没值了,所以会直接插入,此时线程 T2 插入的值就被覆盖了,
如下图所示:
2.4 解决方案
解决方案和第一个解决方案相同,使用 ConcurrentHashMap 来替代 HashMap 就可以解决此问题了。
3.无序性问题
这里的无序性问题指的是 HashMap 添加和查询的顺序不一致,导致程序执行的结果和程序员预期的结果不相符,
如以下代码所示:
HashMap<String, String> map = new HashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-10-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
});
我们添加的顺序:
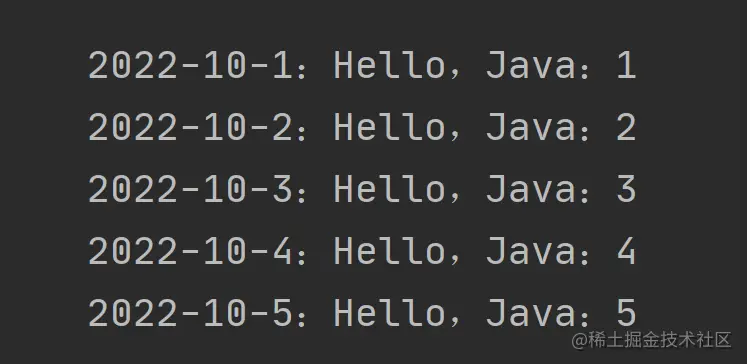
我们期望查询的顺序和添加的顺序是一致的,然而以上代码输出的结果却是:
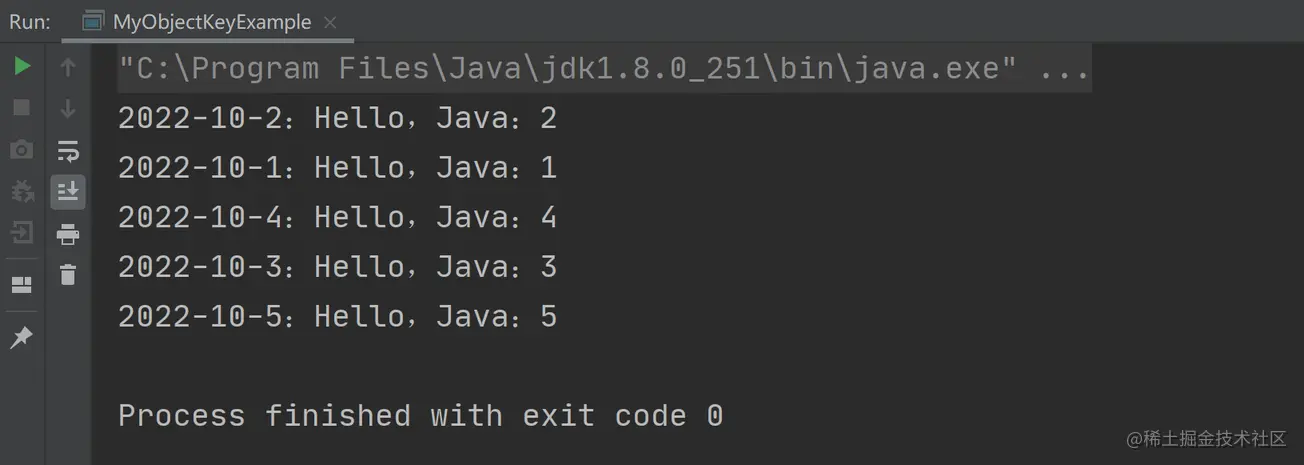
执行结果和我们预期结果不相符,这就是 HashMap 的无序性问题。我们期望输出的结果是 Hello,Java 1、2、3、4、5,而得到的顺序却是 2、1、4、3、5。
3.1 解决方案
想要解决 HashMap 无序问题,我们只需要将 HashMap 替换成 LinkedHashMap 就可以了,
如下代码所示:
LinkedHashMap<String, String> map = new LinkedHashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-10-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
});
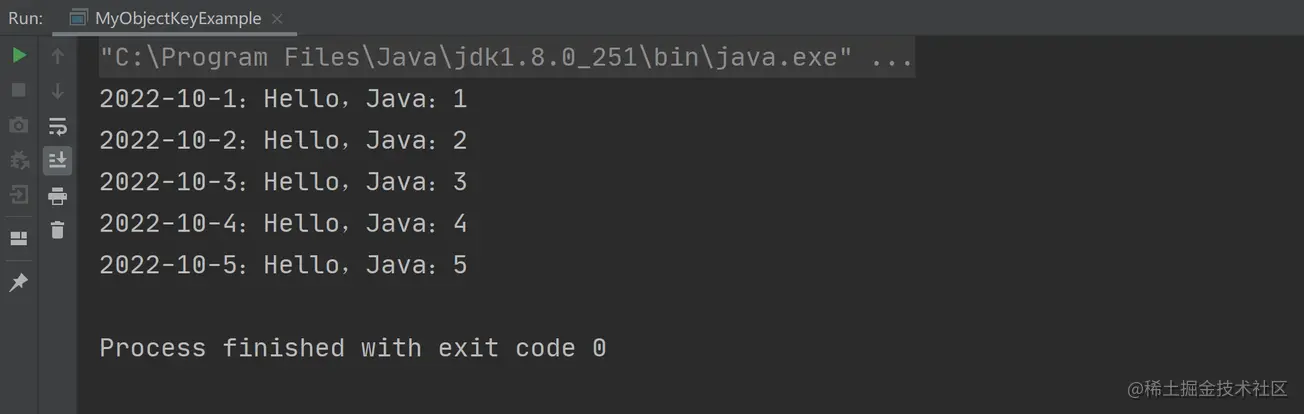
以上程序的执行结果如下图所示:
总结
本文演示了 3 个 HashMap 的经典问题,其中死循环和数据覆盖是发生在并发添加元素时,而无序问题是添加元素的顺序和查询的顺序不一致的问题,这些问题本质来说都是对 HashMap 使用不当才会造成的问题,比如在多线程情况下就应该使用 ConcurrentHashMap,想要保证插入顺序和查询顺序一致就应该使用 LinkedHashMap,但刚开始时我们对 HashMap 不熟悉,所以才会造成这些问题,不过了解了它们之后,就能更好的使用它和更好的应对面试了。
到此这篇关于Java HashMap中除了死循环之外的那些问题的文章就介绍到这了,更多相关Java HashMap内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java中HashMap如何解决哈希冲突
目录 1. Hash算法和Hash表 2. Hash冲突 3. 解决Hash冲突的方法有四种 4.HashMap在JDK1.8版本的优化 1. Hash算法和Hash表 了解Hash冲突首先了解Hash算法和Hash表 Hash算法就是把任意长度的输入通过散列算法变成固定长度的输出,这个输出结果就是一个散列值 Hash表又叫做“散列表”,它是通过key直接访问到内存存储位置的数据结构,在具体的实现上,我们通过Hash函数,把key映射到表中的某个位置,来获取这个位置的数据,从而加快数据的查找 2
-
Java实现HashMap排序方法的示例详解
目录 简介 排序已有数据 按key排序 按value排序 按插入顺序存放 HashMap不按插入顺序存放 LinkedHashMap会按照插入顺序存放 简介 本文用示例介绍HashMap排序的方法. 排序已有数据 按key排序 使用stream进行排序(按key升序/降序) package org.example.a; import java.util.*; public class Demo { public static void main(String[] args) { Map<Stri
-
Java中HashMap 中的一个坑
目录 前言 问题展示 原因分析 解决方案 LinkedHashMap 的魔力 总结 前言 最近公司的系统要增加一个新的列表展示功能,功能本身难度并不大,但遇到了一个很“奇怪”的问题.小伙伴在执行查询列表时,明明已经使用了 order by 进行排序了,但最终查询出来的数据却还是乱的. 预期中的(正确)结果: 现实中的(非预期)结果: 那到底是哪里出现了问题呢? 问题展示 为了方便展示,我把复杂的业务程序简化成了以下代码: import java.util.HashMap; public c
-
Java中的HashMap为什么会产生死循环
目录 前置知识 死循环执行步骤1 死循环执行步骤2 死循环执行步骤3 解决方案 总结 前言: HashMap 死循环是一个比较常见.比较经典的问题,在日常的面试中出现的频率比较高,所以接下来咱们通过图解的方式,带大家彻底理解死循环的原因. 前置知识 死循环问题发生在 JDK 1.7 版本中,造成这个问题主要是由于 HashMap 自身的运行机制,加上并发操作,从而导致了死循环. 在 JDK 1.7 中 HashMap 的底层数据实现是数组 + 链表的方式, 如下图所示: 而 HashMap
-
Java HashMap遍历方法汇总
目录 1.JDK 8 之前的遍历 1.1 EntrySet 遍历 1.2 KeySet 遍历 2.KeySet 性能问题 2.1 EntrySet 迭代器遍历 2.2 KeySet 迭代器遍历 2.3 迭代器的作用 2.4 不使用迭代器删除 2.5 使用迭代器删除 3.JDK 8 之后的遍历 3.1 Lambda 遍历 3.2 Stream 单线程遍历 3.3 Stream 多线程遍历 4.推荐使用哪种遍历方式? 总结 前言: HashMap 的遍历方法有很多种,不同的 JDK 版本有不同的写法
-
java 中的HashMap的底层实现和元素添加流程
目录 HashMap 底层实现 HashMap 插入流程 为什么要将链表转红黑树? 哈希算法实现 总结 前言: HashMap 是使用频率最高的数据类型之一,同时也是面试必问的问题之一,尤其是它的底层实现原理,既是常见的面试题又是理解 HashMap 的基石,所以重要程度不言而喻. HashMap 底层实现 HashMap 在 JDK 1.7 和 JDK 1.8 的底层实现是不一样的,在 JDK 1.7 中,HashMap 使用的是数组 + 链表实现的,而 JDK 1.8 中使用的是数组 + 链
-
Java单例模式利用HashMap实现缓存数据
本文实例为大家分享了Java单例模式利用HashMap实现缓存数据的具体代码,供大家参考,具体内容如下 一.单例模式是什么? 单例模式是一种对象创建模式,它用于产生一个对象的具体实例,它可以确保系统中一个类只产生一个实例.Java 里面实现的单例是一个虚拟机的范围,因为装载类的功能是虚拟机的,所以一个虚拟机在通过自己的 ClassLoad 装载实现单例类的时候就会创建一个类的实例.在 Java 语言中,这样的行为能带来两大好处: 1.对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重
-
Java详细分析讲解HashMap
目录 1.HashMap数据结构 2.HashMap特点 3.HashMap中put方法流程 java集合容器类分为Collection和Map两大类,Collection类的子接口有Set.List.Queue,Map类子接口有SortedMap.如ArrayList.HashMap的继承实现关系分别如下 1.HashMap数据结构 在jdk1.8中,底层数据结构是“数组+链表+红黑树”.HashMap其实底层实现还是数组,只是数组的每一项都是一条链,如下 当链表过长时,会严重影响HashMa
-
Java HashMap中除了死循环之外的那些问题
目录 1.死循环问题 1.1 死循环执行流程一 1.2 死循环执行流程二 1.3 死循环执行流程三 1.4 解决方案 2.数据覆盖问题 2.1 数据覆盖执行流程一 2.2 数据覆盖执行流程二 2.3 数据覆盖执行流程三 2.4 解决方案 3.无序性问题 3.1 解决方案 总结 前言: 本篇的这个问题是一个开放性问题,HashMap 除了死循环之外,还有其他什么问题?总体来说 HashMap 的所有“问题”,都是因为使用(HashMap)不当才导致的,这些问题大致可以分为两类: 程序问题:比如 H
-
深入了解JAVA HASHMAP的死循环
前言 在淘宝内网里看到同事发了贴说了一个CPU被100%的线上故障,并且这个事发生了很多次,原因是在Java语言在并发情况下使用HashMap造成Race Condition,从而导致死循环.这个事情我4.5年前也经历过,本来觉得没什么好写的,因为Java的HashMap是非线程安全的,所以在并发下必然出现问题.但是,我发现近几年,很多人都经历过这个事(在网上查"HashMap Infinite Loop"可以看到很多人都在说这个事)所以,觉得这个是个普遍问题,需要写篇疫苗文章说一下这
-
举例详解Java编程中HashMap的初始化以及遍历的方法
一.HashMap的初始化 1.HashMap 初始化的文艺写法 HashMap 是一种常用的数据结构,一般用来做数据字典或者 Hash 查找的容器.普通青年一般会这么初始化: HashMap<String, String> map = new HashMap<String, String>(); map.put("Name", "June"); map.put("QQ", "2572073701"
-
为什么JDK8中HashMap依然会死循环
JDK8中HashMap依然会死循环! 是否你听说过JDK8之后HashMap已经解决的扩容死循环的问题,虽然HashMap依然说线程不安全,但是不会造成服务器load飙升的问题. 然而事实并非如此.少年可曾了解一种红黑树成环的场景,=v= 今日在查看监控时候发现,某一台机器load飙升 感觉问题不对劲,ssh大法登陆机器,top,top -Hp,jstack,jmap四连击保存下来堆栈,cpu使用最高的线程,内存信息准备分析. 首先查看使用最耗费cpu的线程堆栈信息 cat stack | g
-
解决Java Redis删除HashMap中的key踩到的坑
现象 Java使用Redis删除HashMap中的key时,取出对应的HashMap后通过Java中HashMap的remove方法移除key然后重新调用redis的Hmset方法将覆盖无效 示例代码 //通过key取出对应的HashMap Map<String, String> ruleMap = jedisCluster.hgetAll("HashKey"); //通过java中移除HashMap中的Key ruleMap.remove("ruleA"
-
Java高级之HashMap中的entrySet()方法使用
目录 基本使用 原理剖析 总结 基本使用 entrySet()方法得到HashMap中各个键值对映射关系的集合. 然后Map.Entry中包含了getKey()和getValue()方法获取键和值. 示例: public class Demo { public static void main(String[] args) { Map<String, String> map = new HashMap<>(); map.put("abc", "123&
-
Java基础之代码死循环详解
一.前言 代码死循环这个话题,个人觉得还是挺有趣的.因为只要是开发人员,必定会踩过这个坑.如果真的没踩过,只能说明你代码写少了,或者是真正的大神. 尽管很多时候,我们在极力避免这类问题的发生,但很多时候,死循环却悄咪咪的来了,坑你于无形之中.我敢保证,如果你读完这篇文章,一定会对代码死循环有一些新的认识,学到一些非常实用的经验,少走一些弯路. 二.死循环的危害 我们先来一起了解一下,代码死循环到底有哪些危害? 程序进入假死状态, 当某个请求导致的死循环,该请求将会在很大的一段时间内,都无法获取接
-
java HashMap 的工作原理详解
HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道Hashtable和HashMap之间的区别,那么为何这道面试题如此特殊呢?是因为这道题考察的深度很深.这题经常出现在高级或中高级面试中.投资银行更喜欢问这个问题,甚至会要求你实现HashMap来考察你的编程能力.ConcurrentHashMap和其它同步集合的引入让这道题变得更加复杂.让我们开始探索的旅程吧! 先来些简单的问题 "你用过HashMap吗?&quo
-
Java 集合中的类关于线程安全
Java集合中那些类是线程安全的 线程安全类 在集合框架中,有些类是线程安全的,这些都是jdk1.1中的出现的.在jdk1.2之后,就出现许许多多非线程安全的类. 下面是这些线程安全的同步的类: vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用.在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的. statck:堆栈类,先进后出 hashtable:就比hashmap多了个线程安全 enumeration:枚举,相当于迭代器