C#使用AngleSharp库解析html文档
一、简介
AngleSharp:https://github.com/AngleSharp/AngleSharp
AngleSharp是一个.NET库,使您能够解析基于尖括号的超文本,例如HTML,SVG和MathML,该库还支持未经验证的XML,AngleSharp的一个重要方面是CSS也可以解析。
AngleSharp与类似的库(例如HtmlAgilityPack)相比的优势在于:
- 公开的DOM使用的是W3C官方指定的API,即,甚至在AngleSharp中也可以使用querySelectorAll之类的东西。
- 解析器还使用HTML 5.1规范,该规范定义了错误处理和元素校正。
AngleSharp库专注于标准合规性,交互性和可扩展性。因此,它为使用C#的Web开发人员提供了从在任何现代浏览器中使用DOM所获得的所有可能性。

官方实例:https://github.com/AngleSharp/AngleSharp.Samples
这个简单的示例将使用Wikipedia的网站进行数据检索。
var config = Configuration.Default.WithDefaultLoader(); var address = "https://en.wikipedia.org/wiki/List_of_The_Big_Bang_Theory_episodes"; var context = BrowsingContext.New(config); var document = await context.OpenAsync(address); var cellSelector = "tr.vevent td:nth-child(3)"; var cells = document.QuerySelectorAll(cellSelector); var titles = cells.Select(m => m.TextContent);
二、使用AngleSharp生成自动缩进格式化的html方法
1、操作DOM示例
//创建一个(可重用)解析器前端
var parser = new HtmlParser();
//html DOM节点
var source = "
<h1>Some example source</h1>
<p>This is a paragraph element</p>
";
//解析源文件
var document = parser.Parse(source);
//创建P标签
var p = document.CreateElement("p");
p.TextContent = "This is another paragraph.";
//添加到DOM
document.Body.AppendChild(p);
//返回完整html
var html = document.DocumentElement.OuterHtml;
ViewData["html"] = html;
效果展示

2、更改标签属性
给标签添加自定义属性
var parser = new HtmlParser();
//为以下源代码生成HTML DOM
var document = parser.Parse("
<ul>
<li>First element</li>
<li>Second element</li>
<li>third</li>
<li class='bla'>Last</li>
</ul>
");
//获取所有li元素并将test属性设置为值测试
var elements = document.QuerySelectorAll("li").Attr("test", "test");
//元素仍然包含所有li元素
ViewData["html"] = document.DocumentElement.OuterHtml;
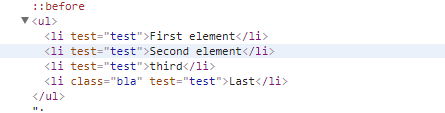
效果展示

3、使用AngleSharp生成html代码自动缩进格式化
var parser = new HtmlParser();
var document = parser.ParseDocument(text);
using (var writer = new StringWriter())
{
document.ToHtml(writer, new PrettyMarkupFormatter
{
Indentation = "\t",
NewLine = "\n"
});
var indentedText = writer.ToString();
}
4、使用AngleSharp下载获取html代码
var requester = new DefaultHttpRequester("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36");
requester.Headers.Add("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8");
requester.Headers.Add("Referer", "");
requester.Headers.Add("Accept-Language", "zh-Hans-CN,zh-Hans;q=0.8,en-US;q=0.5,en;q=0.3");
var context = BrowsingContext.New(Configuration.Default.WithLocaleBasedEncoding().WithDefaultLoader().WithDefaultCookies().With(requester));
//根据虚拟请求/响应模式创建文档
var document = context.OpenAsync(url).Result;
using (var writer = new StringWriter())
{
document.ToHtml(writer, new PrettyMarkupFormatter
{
Indentation = "\t",
NewLine = "\n"
});
var indentedText = writer.ToString();
}
5、爬取豆瓣美女图片
新建一个Belle类用于保存获取的图片信息
///
/// 解析html
///
public class Belle
{
///
/// 标题
///
public string Title { get; set; }
///
/// 图片地址
///
public string ImageUrl { get; set; }
}
获取html并解析
// 设置配置以支持文档加载
var config = Configuration.Default.WithDefaultLoader();
// 豆瓣地址
var address = "https://www.dbmeinv.com/dbgroup/show.htm?cid=4";
// 请求豆辨网
var document = BrowsingContext.New(config).OpenAsync(address);
// 根据class获取html元素
var cells = document.Result.QuerySelectorAll(".panel-body li");
// We are only interested in the text - select it with LINQ
List list = new List();
foreach (var item in cells)
{
var belle = new Belle
{
Title= item.QuerySelector("img").GetAttribute("title"),
ImageUrl= item.QuerySelector("img").GetAttribute("src")
};
list.Add(belle);
}
ViewData["html"] = list;
到此这篇关于C#使用AngleSharp库解析html文档的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

C#使用HtmlAgilityPack组件解析html文档
一.HtmlAgilityPack介绍 参考: GitHub:https://github.com/zzzprojects/html-agility-pack/releases 官网:https://html-agility-pack.net/ https://www.nuget.org/packages/HtmlAgilityPack/ HtmlAgilityPack(以下简称HAP)是一个基于.Net的.第三方免费开源的微型类库,主要用于在服务器端解析html文档. HtmlAgilityP
-
基于C#实现网络爬虫 C#抓取网页Html源码
最近刚完成一个简单的网络爬虫,开始的时候很迷茫,不知道如何入手,后来发现了很多的资料,不过真正能达到我需要,有用的资料--代码很难找.所以我想发这篇文章让一些要做这个功能的朋友少走一些弯路. 首先是抓取Html源码,并选择<ul class="post_list"> </ul>节点的href:要添加using System.IO;using System.Net; private void Search(string url) { string rl; Web
-
C#使用HtmlAgilityPack抓取糗事百科内容实例
本文实例讲述了C#使用HtmlAgilityPack抓取糗事百科内容的方法.分享给大家供大家参考.具体实现方法如下: Console.WriteLine("*****************糗事百科24小时热门*******************"); Console.WriteLine("请输入页码,输入0退出"); string page = Console.ReadLine(); while (page!="0") { HtmlWeb h
-
C#获取网页HTML源码实例
本文实例讲述了C#获取网页HTML源码的方法,分享给大家供大家参考.具体方法如下: 关键代码如下: 复制代码 代码如下: /// <summary> /// 获取网页HTML源码 /// </summary> /// <param name="url">链接 eg:http://www.baidu.com/ </param> /// <param name="charset">编码 eg:Encoding.
-
使用C#获取网页HTML源码的例子
最近在做一个项目,其中一个功能是根据一个URL地址,获取到网页的源代码.在ASP.NET(C#)中,获取网页源代码貌似有很多种方法,我随便搞了一个简单的WebClient,非常简单容易.但后面一个非常恼火的问题出来了,那就是中文的乱码. 通过仔细研究,中文的网页不外乎GB2312和UTF-8这两种编码.于是有了下面这段代码: 复制代码 代码如下: /// <summary> /// 根据网址的URL,获取源代码HTML /// </summary>
-
c# 使用HtmlAgilityPack解析Html
HtmlAgilityPack 是一个开源的快速解析Html的C#类库.简单理解,它可以像解析Xml一样,将Html根据XPATH转化为一个个Node节点,并支持调整节点以及节点的各种属性. 传送门:官网 | Github源码 多种方式加载Html 主要加载方式有3类:从网络链接加载.从字符串文本中加载.从文件加载 var doc = new HtmlDocument(); //直接通过url加载 doc = new HtmlWeb().Load("https://www.baidu.com/&
-
解析xHTML源码的DLL组件AngleSharp介绍
AngleSharp是基于.NET(C#)开发的专门为解析xHTML源码的DLL组件. 项目地址:https://github.com/FlorianRappl/AngleSharp 我主要介绍是一些使用AngleSharp常用的方法,跟大家介绍,我会以我们站点作为原型. 其它的类似组件有: 国内:Jumony github地址: https://github.com/Ivony/Jumony 国外:Html Agility Pack 项目地址:http://htmlagilitypack.co
-
C# 封装HtmlHelper组件:BootstrapHelper
前言:之前学习过很多的Bootstrap组件,博主就在脑海里构思:是否可以封装一套自己Bootstrap组件库呢.再加上看到MVC的Razor语法里面直接通过后台方法输出前端控件的方式,于是打算仿照HtmlHelper封装一套BootstrapHelper,今天只是一个开头,讲述下如何封装自己的Html组件,以后慢慢完善. 一.揭开HtmlHelper的"面纱" 经常使用Razor写法的园友都知道,在cshtml里面,我们可以通过后台的方法输出成前端的html组件,比如我们随便看两个例
-
C#开发WinForm项目实现HTML编辑器
做Web开发时,我们经常会用到HTML富文本框编辑器来编写文章或产品描述的详细内容,常用的编辑器有FCKEditor.CKEditor .TinyMCE.KindEditor和ueditor(百度的), 我们知道WinForm上有一个webBrowser控件,本文正是采用webBrowser结合Web上的HTML编辑器KindEditor来实现的,KindEditor是一个国人写的编辑器,轻量级用起来挺不错,至少我知道目前拍拍和开源中国就是用此编辑器. KindEditor的官方地址为:http
-
C#使用AngleSharp库解析html文档
一.简介 AngleSharp:https://github.com/AngleSharp/AngleSharp AngleSharp是一个.NET库,使您能够解析基于尖括号的超文本,例如HTML,SVG和MathML,该库还支持未经验证的XML,AngleSharp的一个重要方面是CSS也可以解析. AngleSharp与类似的库(例如HtmlAgilityPack)相比的优势在于: 公开的DOM使用的是W3C官方指定的API,即,甚至在AngleSharp中也可以使用querySelecto
-
使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解
下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最基础的内容 html_doc = """ <html><head><title>The Dormouse's story</title></head> <p class="title"><b>The Dormouse's story</b></p>
-
Python利用命名空间解析XML文档
问题 你想解析某个XML文档,文档中使用了XML命名空间. 解决方案 考虑下面这个使用了命名空间的文档: <?xml version="1.0" encoding="utf-8"?> <top> <author>David Beazley</author> <content> <html xmlns="http://www.w3.org/1999/xhtml"> <he
-
dom4j创建和解析xml文档的实现方法
DOM4J解析 特征: 1.JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功能. 2.它使用接口和抽象基本类方法. 3.具有性能优异.灵活性好.功能强大和极端易用的特点. 4.是一个开放源码的文件 jar包:dom4j-1.6.1.jar 创建 book.xml: package com.example.xml.dom4j; import java.io.FileWriter; import org.dom4j.Document; import org.dom4j.Document
-
PHP4和PHP5版本下解析XML文档的操作方法实例分析
本文实例讲述了PHP4和PHP5版本下解析XML文档的操作方法.分享给大家供大家参考,具体如下: 在PHP网站开发与建设过程中,时常会碰到需要对XML文档进行解析,PHP4版本自带了XML解析器(sax),PHP5版本增加了SimpleXML(基于dom)的XML扩展,对XML的解析更是非常方便,今天和大家分享下在不同环境下对XML文档进行解析的方法. XML文档 <?xml version="1.0" encoding="gbk"?> <Leap
-
Android XmlPullParser 方式解析 Xml 文档
Android XmlPullParser 方式解析 Xml 文档 xml 文件格式 <?xml version="1.0" encoding="UTF-8"?> <persons> <person id="1"> <name>张三</name> <age>22</age> </person> <person id="2"&g
-
JS实现兼容各浏览器解析XML文档数据的方法
本文实例讲述了JS实现兼容各浏览器解析XML文档数据的方法.分享给大家供大家参考.具体分析如下: 网站上很多用JS解析XML文档的资料或多或少都有点问题, 以下是自己总结的代码,用来解析XML文档,兼容各个浏览器. parseXMLDOM.js代码: /* * 纯JS解析XML文档(兼容各个浏览器) */ function parseXMLDOM(){ var _browserType = ""; var _xmlFile = ""; var _XmlDom = n
-
java使用dom4j生成与解析xml文档的方法示例
本文实例讲述了java使用dom4j生成与解析xml文档的方法.分享给大家供大家参考,具体如下: xml是一种新的数据格式,主要用于数据交换.我们所用的框架都有涉及到xml.因此解析或生成xml对程序员也是一个技术难点.这里就用dom4j来生成一个文档,需要注意的是每个xml文档只有一个根节点. package org.lxh; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutput
-
原生javascript实现解析XML文档与字符串
之前写过一篇 <使用jquery解析XML的方法>链接是http://www.jb51.net/article/54842.htm,上篇文章详细解释了jQuery 与字符串互相转换的方法 ,这里着重论述javascript操作xml. 总代码如下: var XMLHttp = null; if (window.XMLHttpRequest) { //现代浏览器 XMLHttp = new XMLHttpRequest(); } else if (window.ActiveXObject) {