基于R语言 数据检验详解
目录
- 1.W检验(Shapiro–Wilk(夏皮罗–威克尔)W统计量检验)
- 2.K检验(经验分布的Kolmogorov-Smirnov检验)
- 3.相关性检验:
- 4.T检验
- 5.正态总体方差检验
- 6.二项分布总体假设检验
- 7.Pearson拟合优度χ2检验
- 8.Fisher精确的独立检验:
- 9.McNemar检验:
- 10.秩相关检验
- 11.Wilcoxon秩检验
1. W检验(Shapiro–Wilk (夏皮罗–威克尔 ) W统计量检验)
目标:检验数据是否符合某正态分布,如:标准正态分布N(0,1)
R函数:shapiro.test().
结果含义:当p值小于某个显著性水平α(比如0.05)时,则认为样本不是来自正态分布的总体,否则认为样本来自正态分布的总体。
2. K检验(经验分布的Kolmogorov-Smirnov检验)
目标:检验数据的分布是否符合函数F(x)
R函数:ks.test(),如果P值很小,说明拒绝原假设,表明数据不符合F(n,m)分布。
3. 相关性检验:
R函数:cor.test()
cor.test(x, y,
alternative = c("two.sided", "less", "greater"),
method = c("pearson", "kendall", "spearman"),
exact = NULL, conf.level = 0.95, ...)
结果含义:如果p值很小,则拒绝原假设,认为x,y是相关的。否则认为是不相关的。
4. T检验
目标:用于正态总体均值假设检验,单样本,双样本都可以。
R函数:t.test()
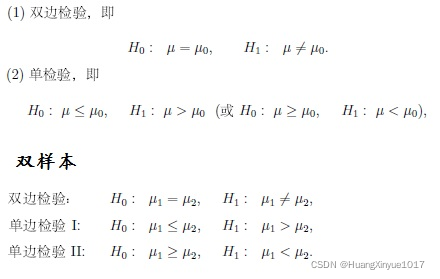
t.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE,
conf.level = 0.95, ...)
结果意义:P值小于显著性水平时拒绝原假设,否则,接受原假设。具体的假设要看所选择的是双边假设还是单边假设(又分小于和大于)
5. 正态总体方差检验
R函数:t.test()
t.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE,
conf.level = 0.95, ...)
结果意义:P值小于显著性水平时拒绝原假设,否则,接受原假设。具体的假设要看所选择的是双边假设还是单边假设(又分小于和大于)
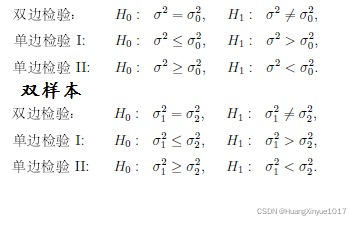
6. 二项分布总体假设检验
binom.test(x, n, p = 0.5,
alternative = c("two.sided", "less", "greater"),
conf.level = 0.95)
原假设:p=p0,p<p0,p<p0 计算结果p-值很小,表示拒绝假设,否则为接受假设.
7. Pearson 拟合优度χ2检验
chisq.test(x, y = NULL, correct = TRUE, p = rep(1/length(x), length(x)), rescale.p = FALSE, simulate.p.value = FALSE, B = 2000)
原假设H0:X符合F分布。
8. Fisher精确的独立检验:
fisher.test(x, y = NULL, workspace = 200000, hybrid = FALSE, control = list(), or = 1, alternative = "two.sided", conf.int = TRUE, conf.level = 0.95)
原假设:X,Y相关。
9. McNemar检验:
mcnemar.test(x, y = NULL, correct = TRUE)
原假设:两组数据的频数没有区别。
10. 秩相关检验
cor.test(x, y,
alternative = c("two.sided", "less", "greater"),
method = "spearman", conf.level = 0.95, ...)
原假设:x,y相关.
11. Wilcoxon秩检验
wilcox.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, exact = NULL, correct = TRUE,
conf.int = FALSE, conf.level = 0.95, ...)
原假设:中位数大于,小于,不等于mu
到此这篇关于R语言 数据检验的文章就介绍到这了,更多相关R语言 数据检验内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
R语言关于卡方检验实例详解
卡方检验是一种确定两个分类变量之间是否存在显着相关性的统计方法. 这两个变量应该来自相同的人口,他们应该是类似 是/否,男/女,红/绿等. 例如,我们可以建立一个观察人们的冰淇淋购买模式的数据集,并尝试将一个人的性别与他们喜欢的冰淇淋的味道相关联. 如果发现相关性,我们可以通过了解访问的人的性别的数量来计划适当的味道库存. 语法 用于执行卡方检验的函数是chisq.test(). 在R语言中创建卡方检验的基本语法是 chisq.test(data) 以下是所使用的参数的描述 data是以包含观察
-

R语言-如何实现卡方检验
卡方检验 在数据统计中,卡方检验是一种很重要的方法. 通常卡方检验的应用主要为: 1. 卡方拟合优度检验 2.卡方独立性检验 本文主要通过使用自己编程的方法实现相关检验. 卡方拟合优度检验 理论: 1.我们先做出0假设:H0:总体服从假定的理论分布 2.我们再构造一个统计量: 3.当n充分大时 4.我们得到该拒绝域 代码 #Chi_square Goodness Of Fit Test #函数说明: #n为所得样本数据:p为理论概率 #alpha为置信水平,df为自由度 cgoft <- fun
-
R语言刷题检验数据缺失类型过程详解
目录 题目 解答 下面考虑三种情况: 1. a = 0, b = 0 2. a = 2, b = 0 3. a = 0, b = 2 题目 解答 由于题目要求需要重复三次类似的操作,故首先载入所需要的包,构造生成数据的函数以及绘图的函数: library(tidyr) # 绘图所需 library(ggplot2) # 绘图所需 # 生成数据 GenerateData <- function(a = 0, b = 0, seed = 2018) { set.seed(seed) z1 <- r
-
R语言差异检验:非参数检验操作
非参数检验是在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态进行推断的方法.它利用数据的大小间的次序关系(秩Rank),而不是具体数值信息,得出推断结论. 它是参数检验所需要的某些条件不满足时所使用的方法. 和参数检验相比,非参数检验的优势如下: 稳健性.对总体分布的条件要求放宽 对数据类型要求不严格,适用有序分类变量 适用范围广 劣势: 没有利用实际数值,损失了部分信息,检验的有效性较差. 非参数性检验的方法非常多,基于方法的检验功效性角度,本文只涉及 双独立样本:Mann-Whi
-
R语言 检验多重共线性的操作
函数kappa() df<-data.frame() df_cor=cor(df) kappa(df_cor, exact=T) 当 κ<100κ<100 , 说明共线性程度小: 当 100<κ<1000100<κ<1000 , 有较强的多重共线性: 当 κ>1000κ>1000,存在严重的多重共线性. 函数qr() x<-matrix() qr(x)$rank qr(X)$rank 计算X矩阵的秩,如果不是满秩的,说明其中有xixi可以用其他x
-
基于R语言 数据检验详解
目录 1.W检验(Shapiro–Wilk(夏皮罗–威克尔)W统计量检验) 2.K检验(经验分布的Kolmogorov-Smirnov检验) 3.相关性检验: 4.T检验 5.正态总体方差检验 6.二项分布总体假设检验 7.Pearson拟合优度χ2检验 8.Fisher精确的独立检验: 9.McNemar检验: 10.秩相关检验 11.Wilcoxon秩检验 1. W检验(Shapiro–Wilk (夏皮罗–威克尔 ) W统计量检验) 目标:检验数据是否符合某正态分布,如:标准正态分布N(0,
-
R语言数据类型深入详解
R语言用来存储数据的对象包括: 向量, 因子, 数组, 矩阵, 数据框, 时间序列(ts)以及列表 意义介绍 1. 向量(一维数据): 只能存放同一类型的数据 语法: c(data1, data2, ...),访问的时候下标从1开始(和Matlab相同);向量里面只能存放相同类型的数据. > x <- c(1,5,8,9,1,2,5) > x [1] 1 5 8 9 1 2 5 > y <- c(1,"zhao") # 这里面有integer和字符串, 整
-
R语言关联规则深入详解
在用R语言做关联规则分析之前,我们先了解下关联规则的相关定义和解释. 关联规则的用途是从数据背后发现事物之间可能存在的关联或者联系,是无监督的机器学习方法,用于知识发现,而非预测. 关联规则挖掘过程主要包含两个阶段:第一阶段从资料集合中找出所有的高频项目组,第二阶段再由这些高频项目组中产生关联规则. 接下来,我们了解下关联规则的两个主要参数:支持度和置信度. 用简化的方式来理解这两个指标,支持度是两个关联物品同时出现的概率,而置信度是当一物品出现,则另一个物品也出现的概率. 假如有一条规则:牛肉
-
R语言“循环”知识点详解
可能有一种情况,当你需要执行一段代码几次. 通常,顺序执行语句. 首先执行函数中的第一个语句,然后执行第二个语句,依此类推. 编程语言提供允许更复杂的执行路径的各种控制结构. 循环语句允许我们多次执行一个语句或一组语句,以下是大多数编程语言中循环语句的一般形式 - R编程语言提供以下种类的循环来处理循环需求. 单击以下链接以检查其详细信息. Sr.No. 循环类型和描述 1 repeat循环 多次执行一系列语句,并简化管理循环变量的代码. 2 while循环 在给定条件为真时,重复语句或语句组.
-
C语言数据存储详解
目录 一.数据类型 二.整型在内存中的存储 1.原码.反码.补码 大小端介绍 三.浮点型在内存中的存储 1.举一个浮点数存储的例子: 2.浮点数存储规则: 总结 一.数据类型 char:字符数字类型.有无符号取决于编译器,大部分编译器有符号(signed char) 而short.int.long都是有符号的. unsigned char c1=255;内存中存放二进制的补码:11111111 都是有效位,没有符号位 char c2=255;结果为-1 同理可推出short.int等 二.整型在
-
详解R语言数据合并一行代码搞定
数据的合并 需要的函数 cbind(),rbind(),bind_rows(),merge() 准备数据 我们先构造一组数据,以便下面的演示 > data1<-data.frame( + namea=c("海波","立波","秀波"), + value=c("一波","接","一波") + ) > data1 namea value 1 海波 一波 2 立波 接 3 秀
-
R语言使用cgdsr包获取TCGA数据示例详解
目录 TCGA数据源 TCGA数据库探索工具 查看任意数据集的样本列表方式 选定数据形式及样本列表后获取感兴趣基因的信息,下载mRNA数据 选定样本列表获取临床信息 综合性获取 下载mRNA数据 获取病例列表的临床数据 从cBioPortal下载点突变信息 从cBioPortal下载拷贝数变异数据 把拷贝数及点突变信息结合画热图 TCGA数据源 众所周知,TCGA数据库是目前最综合全面的癌症病人相关组学数据库,包括的测序数据有: DNA Sequencing miRNA Sequencing P
-
R语言数据可视化学习之图形参数修改详解
1.图形参数的修改par()函数 我们可以通过使用par()函数来修改图形的参数,其调用格式为par(optionname=name, optionname=name,-).当par()不加参数时,返回当前图形参数设置的列表:par(no.readonly=T)将生成一个可以修改当前参数设置的列表.注意以这种方式修改参数设置,除非参数再次被修改,否则一直执行此参数设置. 例如现在想画出mtcars数据集中mpg的折线图,并用虚线代替实线,并将两幅图排列在同一幅图里,代码及图形如下: > opar
-
MySQL教程数据定义语言DDL示例详解
目录 1.SQL语言的基本功能介绍 2.数据定义语言的用途 3.数据库的创建和销毁 4.数据库表的操作(所有演示都以student表为例) 1)创建表 2)修改表 3)销毁表 如果你是刚刚学习MySQL的小白,在你看这篇文章之前,请先看看下面这些文章.有些知识你可能掌握起来有点困难,但请相信我,按照我提供的这个学习流程,反复去看,肯定可以看明白的,这样就不至于到了最后某些知识不懂却不知道从哪里下手去查. <MySQL详细安装教程> <MySQL完整卸载教程> <这点基础都不懂
-
使用 Python 读取电子表格中的数据实例详解
Python 是最流行.功能最强大的编程语言之一.由于它是自由开源的,因此每个人都可以使用.大多数 Fedora 系统都已安装了该语言.Python 可用于多种任务,其中包括处理逗号分隔值(CSV)数据.CSV文件一开始往往是以表格或电子表格的形式出现.本文介绍了如何在 Python 3 中处理 CSV 数据. CSV 数据正如其名.CSV 文件按行放置数据,数值之间用逗号分隔.每行由相同的字段定义.简短的 CSV 文件通常易于阅读和理解.但是较长的数据文件或具有更多字段的数据文件可能很难用肉眼