Spark-Sql入门程序示例详解
SparkSQL运行架构
Spark SQL对SQL语句的处理,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。
spark-sql是用来处理结构化数据的模块,是入门spark的首要模块。
技术的学习无非就是去了解它的API,但是Spark有点难,因为它的例子和网上能搜到的基本都是Scala写的。我们这里使用Java。
入门例子
数据处理的第一个例子通常都是word count,就是统计一个文件里每个单词出现了几次。我们也来试一下。
> 这个例子网上有很多,即使是通过spark实现的也不少;这里面大部分都是使用Scala写的,我没有试过;少部分是通过Java写的;
Java里面的例子有一些是使用RDD实现的,只有极个别是通过DataSet来做的。但即使这一小撮例子,我也跑不通。
所以我自己来尝试完成这个例子,看到别人用Scala写三五行就完成了,而我尝试了一整天几无进展。在网上东拼西凑熟悉Spark的Java
还是以我们前面的例子来改:
String logFile = "words";
SparkSession spark = SparkSession.builder().appName("Simple Application").master("local").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache();
System.out.println("行数:" + logData.count());这里我不再使用之前的README文件,自己创建了一个words文件,内容随意写了一堆单词。
执行程序,可以正常打印出来:

接下来我们需要把句子分割成一个个单词合在一起,然后统计每个单词出现的次数。
> 可能有人会说,这个简单,我用Java8的流一下就处理好了:
把行集合通过flatMap处理,每一行通过split(" ")分割成一个独立的单词集合,再把结果通过自身groupBy一下就拿到终止数据结构Map了。
最后把map的key和value的大小拿到就好了。
的确,使用Java就是这样实现。但是Spark提供了一套和Java的流API名字和效果类似的工具,区别是Spark的是分布式API
我们通过Spark的flatMap先来处理一下:
Dataset<String> words = logData.flatMap((FlatMapFunction<String, String>) k -> Arrays.asList(k.split("\\s")).iterator(), Encoders.STRING());
System.out.println("单词数:" + words.count());
words.foreach(k -> {
System.out.println("W:" + k);
});
不同于Java的流,spark这个flatMap的返回值是可以直接访问结果的:
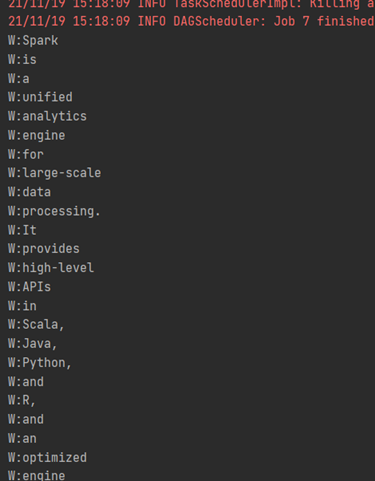
> 可能有人留意到spark中函数式方法的参数定义和Java差距较大。他们的参数不太一样,还多了个编码器。目前来讲我还不清楚为啥这样定义,不过印象中编码器也是spark3的重要优化内容。
再Java中使用Scala的方法总是有些怪异,Lambda表达式前面总是需要强制类型转换,只是为了指明参数类型,否则需要new一个匿名类。
这个也花了我不少时间,后来找到一个网页org.apache.spark.sql.Dataset.flatMap java code examples | Tabnine

再往后我迷茫了:
KeyValueGroupedDataset<String, String> group = words.groupByKey((Function1<String, String>) k -> k, Encoders.STRING());
这样我已经group好了,但是返回的不是DataSet,我也不知道这个返回有啥用,怎么拿到里面的内容呢?我费了好大劲没搞定。
比如我发现count方法会返回一个DataSet:

看起来正是我想要的,但是当我想把它输出竟然执行报错:
ount.foreach(t -> {
System.out.println(t);
});

别说foreach了,就算想看看里面的数量(就像一开始我们查看了文件有几行那样)都会报错,错误内容一样
count.count();
查了很多资料,大意是说spark的计算方法都是分布式的,各个任务之间需要通信,通信时需要序列化来传递信息。所以上面我们能看文件行数因为类型是String,有序列化标志;现在生成的是元组,不能序列化。我尝试了各种方法,甚至自己创建新类模拟了计算过程还是不行


查了好久资料,比如Job aborted due to stage failure: Task not serializable: | Databricks Spark Knowledge Base (gitbooks.io)依然没有解决。偶然的机会找到一个令人激动的网站Spark Groupby Example with DataFrame — SparkByExamples终于解决了我的问题。
使用DataFrame
DataFrame虽然是spark提供的重要工具,但是再Java上并没有对应的类,只是把DataSet的泛型对象改成Row而已。注意这个Row没有泛型定义,所以里面有哪些列不知道
可以从一开始就把DataSet转成DataFrame:

但是可以看到要从Row里面拿数据比较麻烦。所以目前我只在需要序列化的地方转:

到此这篇关于Spark-Sql入门程序的文章就介绍到这了,更多相关Spark-Sql入门内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SparkSQL使用IDEA快速入门DataFrame与DataSet的完美教程
目录 1.使用IDEA开发Spark SQL 1.1创建DataFrame/DataSet 1.1.1指定列名添加Schema 1.1.2StructType指定Schema 1.1.3反射推断Schema 1.使用IDEA开发Spark SQL 1.1创建DataFrame/DataSet 1.指定列名添加Schema 2.通过StrucType指定Schema 3.编写样例类,利用反射机制推断Schema 1.1.1指定列名添加Schema //导包 import org.apache.sp
-

SparkSQL使用快速入门
目录 一.SparkSQL的进化之路 二.认识SparkSQL 2.1 什么是SparkSQL? 2.2 SparkSQL的作用 2.3 运行原理 2.4 特点 2.5 SparkSession 2.6 DataFrames 三.RDD转换成为DataFrame 3.1通过case class创建DataFrames(反射) 3.2通过structType创建DataFrames(编程接口) 3.3通过 json 文件创建DataFrames 四.DataFrame的read和save和save
-
Spark-Sql入门程序示例详解
SparkSQL运行架构 Spark SQL对SQL语句的处理,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定.优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作. spark-sql是用来处理结构化数据的模块,是入门spark的首要模块. 技术的学习无非就是去了解它的API,但是Spark有点难,因为它的例子和网上能搜到的基本都是Scala写的.我们这里使用Java. 入门例子 数据处理的第一个例子通常都
-
Spring Security认证提供程序示例详解
1.简介 本教程将介绍如何在Spring Security中设置身份验证提供程序,与使用简单UserDetailsService的标准方案相比,提供了额外的灵活性. 2. The Authentication Provider Spring Security提供了多种执行身份验证的选项 - 所有这些都遵循简单的规范 - 身份验证请求由Authentication Provider处理,并且返回具有完整凭据的完全身份验证的对象. 标准和最常见的实现是DaoAuthenticationProvide
-
MyBatis自定义SQL拦截器示例详解
目录 前言 定义是否开启注解 注册SQL 拦截器 处理逻辑 如何使用 总结 前言 本文主要是讲通过 MyBaits 的 Interceptor 的拓展点进行对 MyBatis 执行 SQL 之前做一个逻辑拦截实现自定义逻辑的插入执行. 适合场景:1. 比如限制数据库查询最大访问条数:2. 限制登录用户只能访问当前机构数据. 定义是否开启注解 定义是否开启注解, 主要做的一件事情就是是否添加 SQL 拦截器. // 全局开启 @Retention(RetentionPolicy.RUNTIME)
-
Python简单的GUI程序示例详解
目录 一.记事本 二.简单画图 总结 一.记事本 源码 #python简易记事本 from tkinter import * from tkinter import messagebox from tkinter import filedialog import os filename='' #文件名,全局变量 def about(): messagebox.showinfo('提示','这是一个消息框') def openFile(): global filename #使用全局变量 file
-
从迷你todo 命令行入门Rust示例详解
目录 一个迷你 todo 应用 需要安装的依赖 文件目录组织 主文件 读取文件 状态处理工厂函数 Trait(特征) Create trait Get trait Delete trait Edit trait 导出 trait 为 struct 实现 trait Pending Done 导出 struct Process 输入处理 最后 一个迷你 todo 应用 该文章将使用 Rust 从零去做一个入门级别的 TODO 命令行应用 你将学会什么? 基本的命令行操作 文件读写和文件结构组织 我
-
Python数学建模PuLP库线性规划入门示例详解
目录 1.什么是线性规划 2.PuLP 库求解线性规划 -(0)导入 PuLP库函数 -(1)定义一个规划问题 -(2)定义决策变量 -(3)添加目标函数 -(4)添加约束条件 -(5)求解 3.Python程序和运行结果 1.什么是线性规划 线性规划(Linear programming),在线性等式或不等式约束条件下求解线性目标函数的极值问题,常用于解决资源分配.生产调度和混合问题.例如: max fx = 2*x1 + 3*x2 - 5*x3 s.t. x1 + 3*x2 + x3 <=
-
Python-OpenCV深度学习入门示例详解
目录 0. 前言 1. 计算机视觉中的深度学习简介 1.1 深度学习的特点 1.2 深度学习大爆发 2. 用于图像分类的深度学习简介 3. 用于目标检测的深度学习简介 4. 深度学习框架 keras 介绍与使用 4.1 keras 库简介与安装 4.2 使用 keras 实现线性回归模型 4.3 使用 keras 进行手写数字识别 小结 0. 前言 深度学习已经成为机器学习中最受欢迎和发展最快的领域.自 2012 年深度学习性能超越机器学习等传统方法以来,深度学习架构开始快速应用于包括计算机视觉
-
golang gorm更新日志执行SQL示例详解
目录 1. 更新日志 1.1. v1.0 1.1.1. 破坏性变更 gorm执行sql 1. 更新日志 1.1. v1.0 1.1.1. 破坏性变更 gorm.Open返回类型为*gorm.DB而不是gorm.DB 更新只会更新更改的字段 大多数应用程序不会受到影响,只有当您更改回调中的更新值(如BeforeSave,BeforeUpdate)时,应该使用scope.SetColumn,例如: func (user *User) BeforeUpdate(scope *gorm.Scope) {
-
Python程序包的构建和发布过程示例详解
关于我 编程界的一名小程序猿,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. 联系:hylinux1024@gmail.com 当我们开发了一个开源项目时,就希望把这个项目打包然后发布到 pypi.org 上,别人就可以通过 pip install 的命令进行安装.本文的教程来自于 Python 官方文档 , 如有不正确的地方欢迎评论拍砖. 0x00 创建项目 本文使用到的项目目录为 ➜ packaging-tuto
-
微信小程序之高德地图多点路线规划过程示例详解
调用 如何调用高德api? 高德官方给出的https://lbs.amap.com/api/wx/summary/开放文档比较详细: 第一步,注册高德开发者 第二部,去控制台创建应用 即点击右上角的控制平台创建应用 创建应用绑定服务记得选择微信小程序:同时在https://lbs.amap.com/api/wx/gettingstarted中下载开发包 第三步,登陆微信公众平台在开发设置中将高德域名配置上 https://restapi.amap.com 第四步,打开微信开发者工具,打开微信小程