浅谈HashMap中7种遍历方式的性能分析
目录
- 一、前言
- 二、HashMap遍历
- 2.1、迭代器EntrySet
- 2.2、迭代器 KeySet
- 2.3、ForEachEntrySet
- 2.4、ForEach KeySet
- 2.5、Lambda
- 2.6、Streams API 单线程
- 2.7、Streams API 多线程
- 三、性能分析
- 四、字节码分析
- 五、EntrySet性能分析
- 六、安全性测试
- 6.1、迭代器方式
- 6.2、For 循环方式
- 6.3、Lambda 方式
- 6.4、Stream 方式
- 6.5、小结
- 七、总结
一、前言
随着 JDK 1.8 Streams API 的发布,使得 HashMap 拥有了更多的遍历的方式,但应该选择那种遍历方式?反而成了一个问题。
本文主要内容如下图所示:
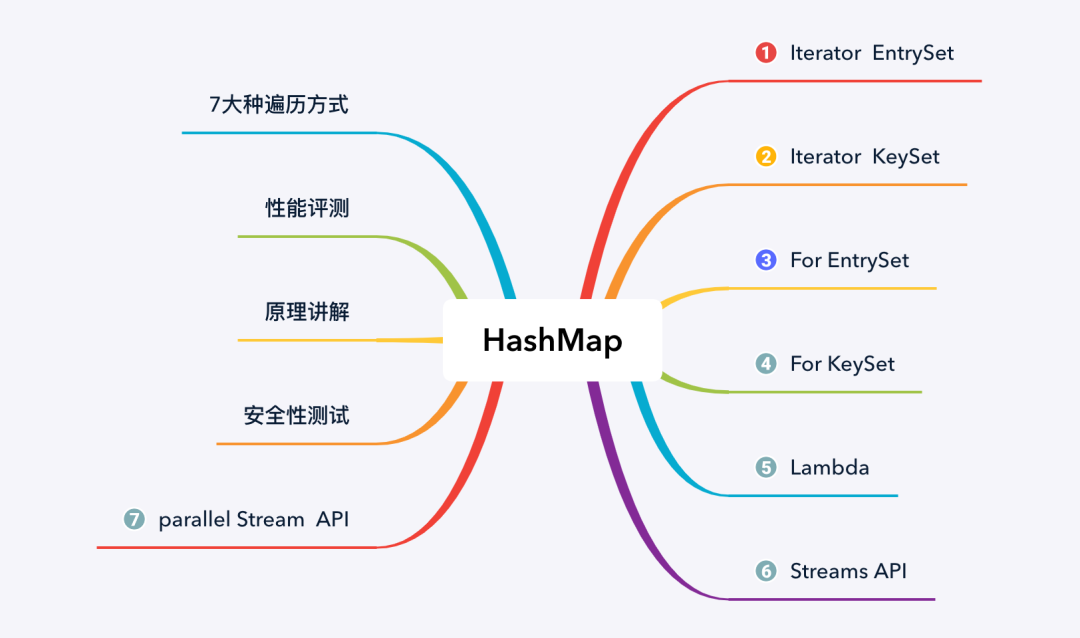
二、HashMap遍历
HashMap遍历从大的方向来说,可分为以下 4 类:
- 迭代器(Iterator)方式遍历;
- For Each 方式遍历;
- Lambda 表达式遍历(JDK 1.8+);
- Streams API 遍历(JDK 1.8+)。
但每种类型下又有不同的实现方式,因此具体的遍历方式又可以分为以下 7 种:
- 使用迭代器(Iterator)EntrySet 的方式进行遍历;
- 使用迭代器(Iterator)KeySet 的方式进行遍历;
- 使用 For Each EntrySet 的方式进行遍历;
- 使用 For Each KeySet 的方式进行遍历;
- 使用 Lambda 表达式的方式进行遍历;
- 使用 Streams API 单线程的方式进行遍历;
- 使用 Streams API 多线程的方式进行遍历。
接下来我们来看每种遍历方式的具体实现代码。
2.1、迭代器EntrySet
@Test
public void testIterator() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Oracle Database");
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
运行结果:

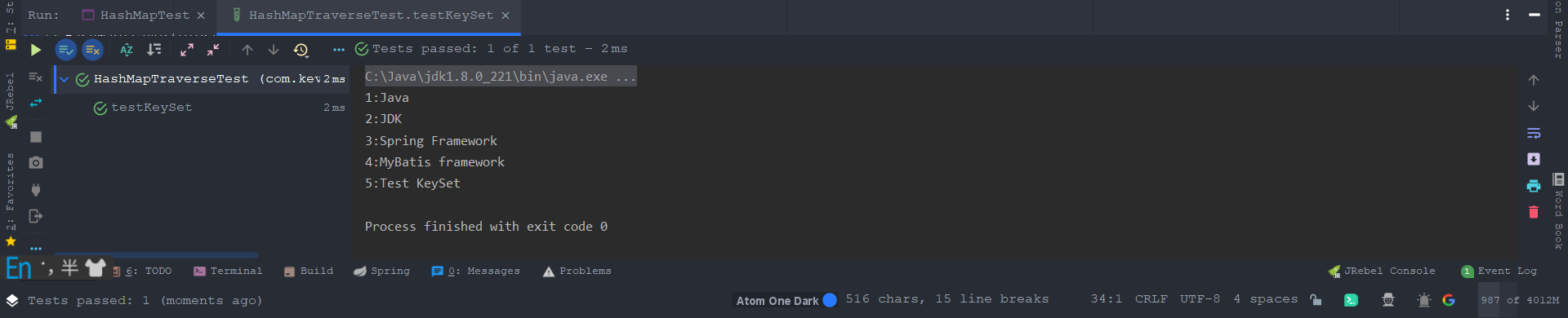
2.2、迭代器 KeySet
@Test
public void testKeySet() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test KeySet");
// 遍历
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer key = iterator.next();
System.out.println(key + ":" + map.get(key));
}
}
运行结果:
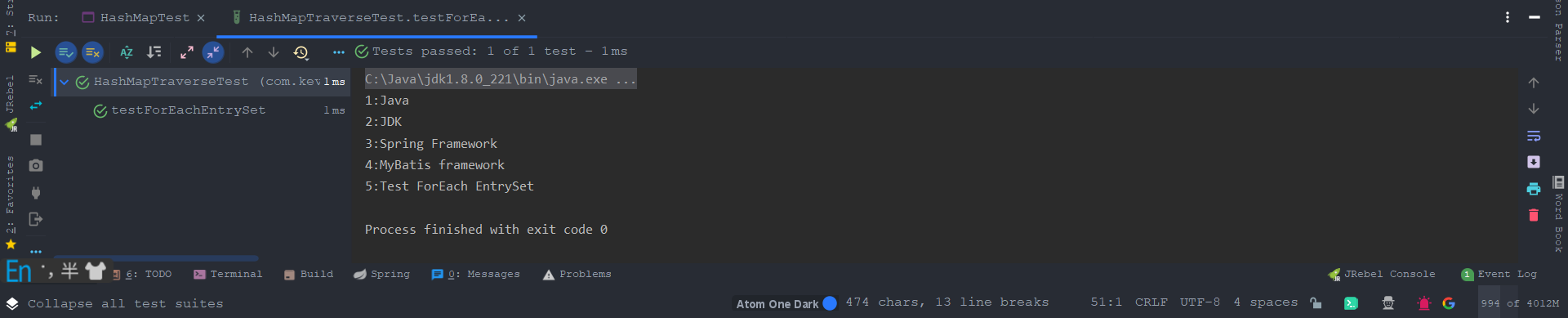
2.3、ForEachEntrySet
@Test
public void testForEachEntrySet() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test ForEach EntrySet");
// 遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
运行结果:
2.4、ForEach KeySet
@Test
public void testForEachKeySet() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test ForEach KeySet");
// 遍历
for (Integer key : map.keySet()) {
System.out.println(key + ":" + map.get(key));
}
}
运行结果:

2.5、Lambda
@Test
public void testLambda() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test Lambda");
// 遍历
map.forEach((key, value) -> {
System.out.println(key + ":" + value);
});
}
运行结果:

2.6、Streams API 单线程
@Test
public void testStreamApi() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test Stream API");
// 遍历
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
运行结果:

2.7、Streams API 多线程
@Test
public void testParallelStreamApi() {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Test Parallel Stream API");
// 遍历
map.entrySet().parallelStream().forEach((entry) -> {
System.out.println(entry.getKey() + ":" + entry.getValue());
});
}
运行结果:

三、性能分析
接下来我们使用 Oracle 官方提供的性能测试工具 JMH(Java Microbenchmark Harness,JAVA 微基准测试套件)来测试一下这 7 种循环的性能。
首先我们需要引入JMH框架,本次构建依赖使用工具为Gradle,引入配置如下:
implementation "org.openjdk.jmh:jmh-core:1.23"
implementation "org.openjdk.jmh:jmh-generator-annprocess:1.23"
如果使用Maven,可引入如下配置:
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-core -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.23</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-generator-annprocess -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.23</version>
<scope>provided</scope>
</dependency>
编写性能测试代码如下:
//@BenchmarkMode(Mode.Throughput) // 测试类型:吞吐量
@BenchmarkMode(Mode.AverageTime) // 测试类型:平均消耗时间
//@OutputTimeUnit(TimeUnit.MILLISECONDS)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 4, time = 1, timeUnit = TimeUnit.SECONDS) // 预热 4 轮,每次 1s
@Measurement(iterations = 10, time = 3, timeUnit = TimeUnit.SECONDS) // 测试 10 轮,每次 3s
@Fork(1) // fork 1 个线程
@State(Scope.Thread) // 每个测试线程一个实例
public class HashMapTest {
static Map<Integer, String> map = new HashMap() {
{
for(int var1 = 0; var1 < 2; ++var1) {
this.put(var1, "Kevin:" + var1);
}
}
};
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(HashMapTest.class.getSimpleName()) // 要导入的测试类
.output("E:/IDEAWorkSpaces/Test/src/main/java/com/kevin/performance/jmh-map2.log") // 输出测试结果的文件
.build();
new Runner(opt).run(); // 执行测试
}
/**
* Iterator遍历 entrySet
*/
@Benchmark
public void entrySet() {
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
Integer k = entry.getKey();
String v = entry.getValue();
}
}
/**
* Foreach遍历 entrySet
*/
@Benchmark
public void forEachEntrySet() {
// 遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
Integer k = entry.getKey();
String v = entry.getValue();
}
}
/**
* Iterator遍历 keySet
*/
@Benchmark
public void keySet() {
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer k = iterator.next();
String v = map.get(k);
}
}
/**
* Foreach遍历 keySet
*/
@Benchmark
public void forEachKeySet() {
for (Integer key : map.keySet()) {
Integer k = key;
String v = map.get(k);
}
}
/**
* Lambda遍历
*/
@Benchmark
public void lambda() {
map.forEach((key, value) -> {
Integer k = key;
String v = value;
});
}
/**
* 单线程遍历
*/
@Benchmark
public void streamApi() {
map.entrySet().stream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
}
/**
* 多线程遍历
*/
public void parallelStreamApi() {
map.entrySet().parallelStream().forEach((entry) -> {
Integer k = entry.getKey();
String v = entry.getValue();
});
}
}
所有被添加了@Benchmark注解的方法都会被测试(由于 parallelStream 为多线程版本性能一定由于其他单线程,故不参与本次测试),测试结果如下:
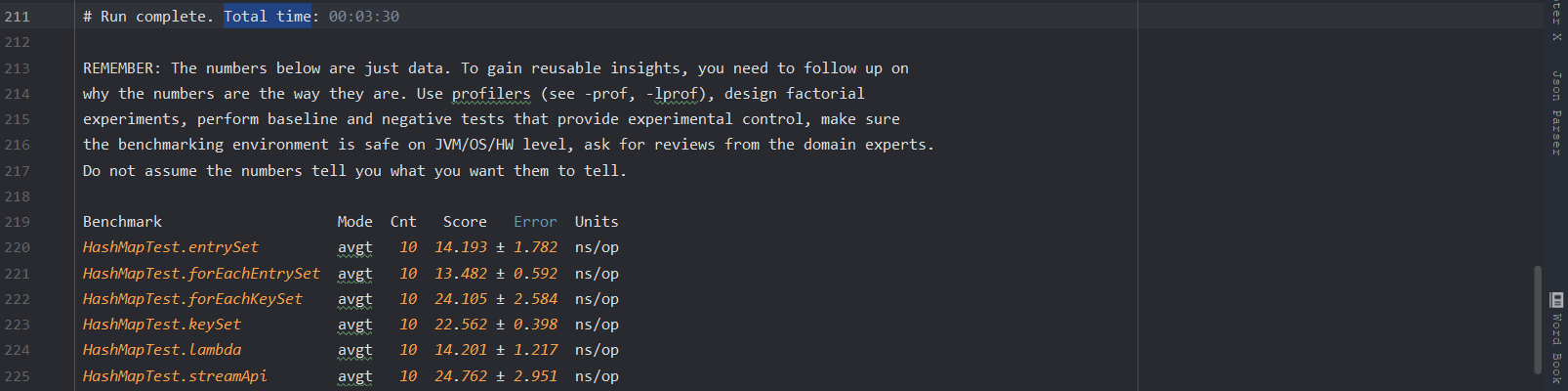
其中 Units 为 ns/op 意思是执行完成时间(单位为纳秒),而 Score 列为平均执行时间,±符号表示误差。从以上结果可以看出,两个entrySet的性能相近,并且执行速度最快,接下来是stream,然后是两个keySet,性能最差的是KeySet。
结论:
从以上结果可以看出entrySet的性能比keySet的性能高出了一倍之多,因此我们应该尽量使用entrySet来实现 Map集合的遍历。
四、字节码分析
要理解以上的测试结果,我们需要把所有遍历代码通过javac编译成字节码来看具体的原因。
编译后,我们使用 Idea 打开字节码,内容如下:
public class HashMapTest {
static Map<Integer, String> map = new HashMap() {
{
for(int var1 = 0; var1 < 2; ++var1) {
this.put(var1, "Kevin:" + var1);
}
}
};
public HashMapTest() {
}
public static void main(String[] var0) {
entrySet();
keySet();
forEachEntrySet();
forEachKeySet();
lambda();
streamApi();
parallelStreamApi();
}
public static void entrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
public static void keySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
public static void forEachEntrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
public static void forEachKeySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
public static void lambda() {
map.forEach((var0, var1) -> {
System.out.println(var0 + ":" + var1);
});
}
public static void streamApi() {
map.entrySet().stream().forEach((var0) -> {
System.out.println(var0.getKey() + ":" + (String)var0.getValue());
});
}
public static void parallelStreamApi() {
map.entrySet().parallelStream().forEach((var0) -> {
System.out.println(var0.getKey() + ":" + (String)var0.getValue());
});
}
}
//从结果可以看出,除了 Lambda 和 Streams API 之外,通过迭代器循环和 for 循环的遍历的 EntrySet 最终生成的代码是一样的,他们都是在循环中创建了一个遍历对象 Entry ,代码如下:
public static void entrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
public static void forEachEntrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
//而 KeySet 的代码也是类似的,如下所示:
public static void keySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
public static void forEachKeySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
从结果可以看出,除了 Lambda 和 Streams API 之外,通过迭代器循环和for循环的遍历的EntrySet最终生成的代码是一样的,他们都是在循环中创建了一个遍历对象Entry,代码如下:
public static void entrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
public static void forEachEntrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey() + ":" + (String)var1.getValue());
}
}
而KeySet的代码也是类似的,如下所示:
public static void keySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
public static void forEachKeySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1 + ":" + (String)map.get(var1));
}
}
所以我们在使用迭代器或是for循环EntrySet时,他们的性能都是相同的,因为他们最终生成的字节码基本都是一样的;同理KeySet的两种遍历方式也是类似的。
五、EntrySet性能分析
EntrySet之所以比KeySet的性能高是因为,KeySet在循环时使用了map.get(key),而map.get(key)相当于又遍历了一遍 Map 集合去查询key所对应的值。为什么要用“又”这个词?那是因为在使用迭代器或者 for 循环时,其实已经遍历了一遍 Map 集合了,因此再使用map.get(key)查询时,相当于遍历了两遍。
而EntrySet只遍历了一遍 Map 集合,之后通过代码“Entry<Integer, String> entry = iterator.next()”把对象的key和value值都放入到了Entry对象中,因此再获取key和value值时就无需再遍历 Map 集合,只需要从Entry对象中取值就可以了。
所以,EntrySet的性能比KeySet的性能高出了一倍,因为KeySet相当于循环了两遍 Map 集合,而EntrySet只循环了一遍。
六、安全性测试
从上面的性能测试结果和原理分析,我想大家应该选用那种遍历方式,已经心中有数的,而接下来我们就从「安全」的角度入手,来分析那种遍历方式更安全。
我们把以上遍历划分为四类进行测试:迭代器方式、For 循环方式、Lambda 方式和 Stream 方式,测试代码如下。
6.1、迭代器方式
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
iterator.remove();
} else {
System.out.println("show:" + entry.getKey());
}
}
运行结果:
show:0
del:1
show:2
测试结果:迭代器中循环删除数据安全。
6.2、For 循环方式
for (Map.Entry<Integer, String> entry : map.entrySet()) {
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
map.remove(entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
}
运行结果:
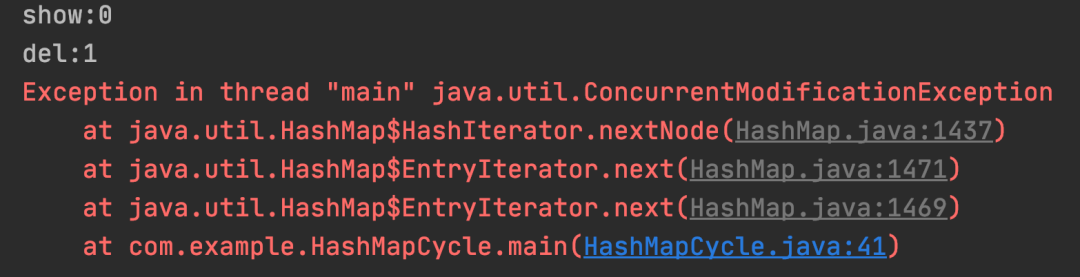
测试结果:For 循环中删除数据非安全。
6.3、Lambda 方式
map.forEach((key, value) -> {
if (key == 1) {
System.out.println("del:" + key);
map.remove(key);
} else {
System.out.println("show:" + key);
}
});
运行结果:
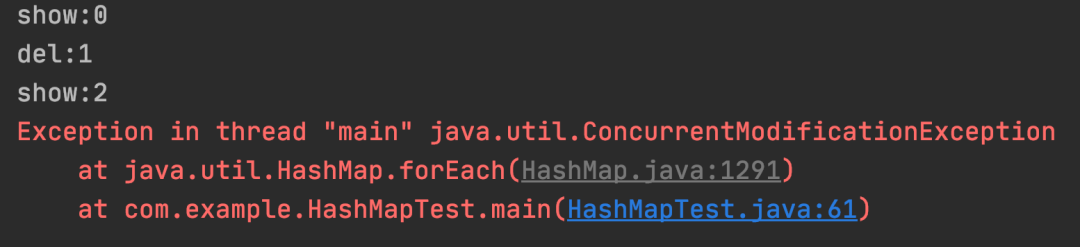
测试结果:Lambda 循环中删除数据非安全。
Lambda 删除的正确方式:
// 根据 map 中的 key 去判断删除
map.keySet().removeIf(key -> key == 1);
map.forEach((key, value) -> {
System.out.println("show:" + key);
});
运行结果:
show:0
show:2
从上面的代码可以看出,可以先使用Lambda的removeIf删除多余的数据,再进行循环是一种正确操作集合的方式。
6.4、Stream 方式
map.entrySet().stream().forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
map.remove(entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});
运行结果:
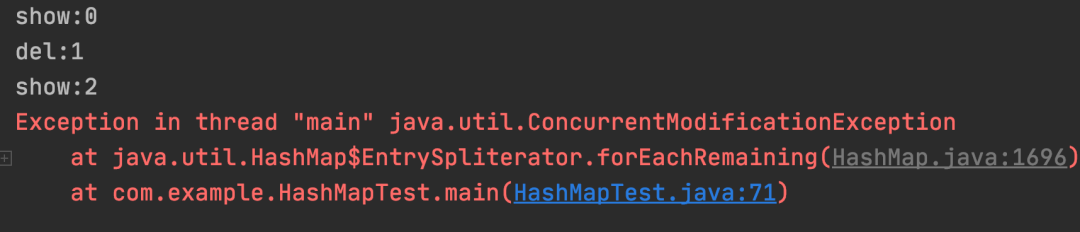
测试结果:Stream 循环中删除数据非安全。
Stream 循环的正确方式:
map.entrySet().stream().filter(m -> 1 != m.getKey()).forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});
运行结果:
show:0
show:2
从上面的代码可以看出,可以使用Stream中的filter过滤掉无用的数据,再进行遍历也是一种安全的操作集合的方式。
6.5、小结
我们不能在遍历中使用集合map.remove()来删除数据,这是非安全的操作方式,但我们可以使用迭代器的iterator.remove()的方法来删除数据,这是安全的删除集合的方式。同样的我们也可以使用 Lambda 中的removeIf来提前删除数据,或者是使用 Stream 中的filter过滤掉要删除的数据进行循环,这样都是安全的,当然我们也可以在for循环前删除数据在遍历也是线程安全的。
七、总结
本文我们讲了 HashMap 4 种遍历方式:迭代器、for、lambda、stream,以及具体的 7 种遍历方法,综合性能和安全性来看,我们应该尽量使用迭代器(Iterator)来遍历EntrySet的遍历方式来操作 Map 集合,这样就会既安全又高效了。
以上就是浅谈HashMap中7种遍历方式的性能分析的详细内容,更多关于HashMap 遍历性能分析的资料请关注我们其它相关文章!
相关推荐
-
Java中使用HashMap改进查找性能的步骤
Java中,HashMap,其实就是键值对.一个Key,对应一个值:写数据时,指定Key写对应值:读取时凭Key找到相应值.感觉就跟Redis差不多. // 创建 HashMap 对象 Sites HashMap<Integer, String> Sites = new HashMap<Integer, String>(); // 添加键值对 Sites.put(1, "Google"); Sites.put(2, "Runoob"); Si
-

剖析Java中HashMap数据结构的源码及其性能优化
存储结构 首先,HashMap是基于哈希表存储的.它内部有一个数组,当元素要存储的时候,先计算其key的哈希值,根据哈希值找到元素在数组中对应的下标.如果这个位置没有元素,就直接把当前元素放进去,如果有元素了(这里记为A),就把当前元素链接到元素A的前面,然后把当前元素放入数组中.所以在Hashmap中,数组其实保存的是链表的首节点.下面是百度百科的一张图: 如上图,每个元素是一个Entry对象,在其中保存了元素的key和value,还有一个指针可用于指向下一个对象.所有哈希值相同的key(也就
-
Java HashMap三种循环遍历方式及其性能对比实例分析
本文实例讲述了Java HashMap三种循环遍历方式及其性能对比.分享给大家供大家参考,具体如下: HashMap的三种遍历方式 (1)for each map.entrySet() Map<String, String> map = new HashMap<String, String>(); for (Entry<String, String> entry : map.entrySet()) { entry.getKey(); entry.getValue();
-
浅谈HashMap中7种遍历方式的性能分析
目录 一.前言 二.HashMap遍历 2.1.迭代器EntrySet 2.2.迭代器 KeySet 2.3.ForEachEntrySet 2.4.ForEach KeySet 2.5.Lambda 2.6.Streams API 单线程 2.7.Streams API 多线程 三.性能分析 四.字节码分析 五.EntrySet性能分析 六.安全性测试 6.1.迭代器方式 6.2.For 循环方式 6.3.Lambda 方式 6.4.Stream 方式 6.5.小结 七.总结 一.前言 随着
-
java中HashMap的7种遍历方式与性能分析
目录 1.遍历方式 1.1 迭代器 EntrySet 1.2 迭代器 KeySet 1.3 ForEach EntrySet 1.4 ForEach KeySet 1.5 Lambda 表达式 1.6 Stream API 单线程 1.7 Stream API 多线程 1.8 代码汇总 2.性能分析 2.1 引入依赖 2.2 编写测试类 2.3 测试结果 2.4 分析 2.5 总结 1.遍历方式 1.1 迭代器 EntrySet /** * 1. 迭代器 EntrySet */ @Test pu
-
浅谈js函数三种定义方式 & 四种调用方式 & 调用顺序
在Javascript定义一个函数一般有如下三种方式: 函数关键字(function)语句: function fnMethodName(x){alert(x);} 函数字面量(Function Literals): var fnMethodName = function(x){alert(x);} Function()构造函数: var fnMethodName = new Function('x','alert(x);') // 由Function构造函数的参数个数可变.最后一个参数写函数体
-
浅谈Java中几种常见的比较器的实现方法
在Java中经常会涉及到对象数组的排序问题,那么就涉及到对象之间的比较问题. 通常对象之间的比较可以从两个方面去看: 第一个方面:对象的地址是否一样,也就是是否引用自同一个对象.这种方式可以直接使用"=="来完成. 第二个方面:以对象的某一个属性的角度去比较. 从最新的JDK8而言,有三种实现对象比较的方法: 一.覆写Object类的equals()方法: 二.继承Comparable接口,并实现compareTo()方法: 三.定义一个单独的对象比较器,继承自Comparator接口
-
浅谈Android中Service的注册方式及使用
Service通常总是称之为"后台服务",其中"后台"一词是相对于前台而言的,具体是指其本身的运行并不依赖于用户可视的UI界面,因此,从实际业务需求上来理解,Service的适用场景应该具备以下条件: 1.并不依赖于用户可视的UI界面(当然,这一条其实也不是绝对的,如前台Service就是与Notification界面结合使用的): 2.具有较长时间的运行特性. 1.Service AndroidManifest.xml 声明 一般而言,从Service的启动方式上
-
浅谈vue中所有的封装方式总结
目录 1.封装API 2.注册全局工具组件 3.封装全局函数 4. 为了减少页面代码量的封装 如何确定我需要封装呢? 1.复用,如果觉得以后还会用到 2.你觉得方便,别的地方可能也需要用 3.如果不封装,页面代码臃肿的时候 1.封装API 使用场景:业务中最常见最普通的封装 步骤一: 步骤二: 步骤三: 2.注册全局工具组件 使用场景:想让组件全局可用,尤其是第三方插件使用时 步骤一: 步骤二: 3.封装全局函数 使用场景:有些逻辑处理函数代码量很大,且具有独特功能(如日期处理函数,数组
-
浅谈Python3中打开文件的方式(With open)
目录 0.背景知识 1.常规方式:读取文件-----open() 2.推荐方式:读取文件-----With Open 1).读取方式 2).常见的坑 3).跳过第一行内容(字段名) 3.写入内容----open()函数 4.写入内容----- With Open函数 5.打开非utf-8编码的文件 6.打开二进制文件 0.背景知识 python文件读写文件是最常见的IO操作.Python内置了读写文件的函数,用法和C是兼容的. 读写文件前,我们先必须了解一下,在磁盘上读写文件的功能都是由操作系统
-
JS常用的几种数组遍历方式以及性能分析对比实例详解
本文实例讲述了JS常用的几种数组遍历方式以及性能分析对比.分享给大家供大家参考,具体如下: 前言 这一篇与上一篇 JS几种变量交换方式以及性能分析对比 属于同一个系列,本文继续分析JS中几种常用的数组遍历方式以及各自的性能对比 起由 在上一次分析了JS几种常用变量交换方式以及各自性能后,觉得这种方式挺好的,于是抽取了核心逻辑,封装成了模板,打算拓展成一个系列,本文则是系列中的第二篇,JS数组遍历方式的分析对比 JS数组遍历的几种方式 JS数组遍历,基本就是for,forin,foreach,fo
-
java 单例的五种实现方式及其性能分析
java 单例的五种实现方式及其性能分析 序言 在23种设计模式中,单例是最简单的设计模式,但是也是很常用的设计模式.从单例的五种实现方式中我们可以看到程序员对性能的不懈追求.下面我将分析单例的五种实现方式的优缺点,并对其在多线程环境下的性能进行测试. 实现 单例模式适用于资源占用较多的类,保证一个类只有一个实例即单例.通用的做法就是构造器私有化,提供一个全局的访问点,返回类的实例. uml图: 1.饿汉式 代码实现: package com.zgh.gof23.singleton; /** *
-
浅谈springboot的三种启动方式
有段时间没有写博客了,也在努力的从传统单机开发向分布式系统过度,所以再次做一些笔记,以方便日后查看. 直接进入正题吧,今天记录spring-boot项目的三种启动方式. spring-boot的启动方式主要有三种: 1. 运行带有main方法类 2. 通过命令行 java -jar 的方式 3. 通过spring-boot-plugin的方式 一.执行带有main方法类 这种方式很简单,我主要是通过idea的方式,进行执行.这种方式在启动的时候,会去自动加载classpath下的配置文件 (这里