python神经网络AlexNet分类模型训练猫狗数据集
目录
- 什么是AlexNet模型
- 训练前准备
- 1、数据集处理
- 2、创建Keras的AlexNet模型
- 开始训练
- 1、训练的主函数
- 2、Keras数据生成器
- 3、主训练函数全部代码
- 训练结果
最近在做实验室的工作,要用到分类模型,老板一星期催20次,我也是无语了,上有对策下有政策,在下先找个猫猫狗狗的数据集练练手,快乐极了
什么是AlexNet模型
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网络被提出,比如优秀的vgg,GoogLeNet。 这对于传统的机器学习分类算法而言,已经相当的出色。如下是其网络的结构,现在看来还是比较简单的。


这是一个AlexNet的网络结构图,其实并不复杂,很好的反应了AlexNet的结构:
1、一张原始图片被resize到(224,224,3);
2、使用步长为4x4,大小为11的卷积核对图像进行卷积,输出的特征层为96层,输出的shape为(55,55,96);
3、使用步长为2的最大池化层进行池化,此时输出的shape为(27,27,96)
4、使用步长为1x1,大小为5的卷积核对图像进行卷积,输出的特征层为256层,输出的shape为(27,27,256);
5、使用步长为2的最大池化层进行池化,此时输出的shape为(13,13,256);
6、使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为384层,输出的shape为(13,13,384);
7、使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为384层,输出的shape为(13,13,384);
8、使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为256层,输出的shape为(13,13,256);
9、使用步长为2的最大池化层进行池化,此时输出的shape为(6,6,256);
10、两个全连接层,最后输出为1000类
最后输出的就是每个类的预测。
从上面的图也可以看出,其实最大的内存与计算消耗在于第一个全连接层的实现,它的参数有37M之多(这一点与VGG很类似,第一个全连接层参数巨多。),
训练前准备
1、数据集处理
在数据集处理之前,首先要下载猫狗数据集,地址如下。
链接:https://pan.baidu.com/s/1IfN8Cvt60n64bbC2gF4Ung
提取码:he9i
顺便直接下载我的源代码吧。
这里的源代码包括了所有的代码部分,训练集需要自己下载,大概训练2个小时就可以进行预测了。
本次教程准备使用model.fit_generator来训练模型,在训练模型之前,需要将数据集的内容保存到一个TXT文件中,便于读取。
txt文件的保存格式如下:
文件名;种类
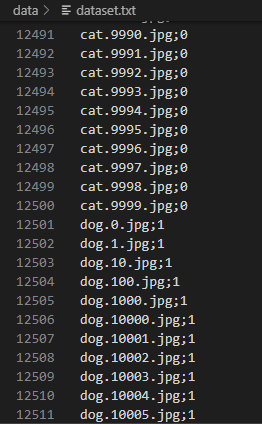
具体操作步骤如下:
1、将训练文件存到"./data/image/train/"目录下。
2、调用如下代码:
import os
photos = os.listdir("./data/image/train/")
# 该部分用于将
with open("data/dataset.txt","w") as f:
for photo in photos:
name = photo.split(".")[0]
if name=="cat":
f.write(photo + ";0\n")
elif name=="dog":
f.write(photo + ";1\n")
f.close()
就可以得到训练数据集的文本文件。
2、创建Keras的AlexNet模型
该步就是按照AlexNet的结构创建AlexNet的模型。我试了原大小的模型,发现根本呢不收敛,可能是模型太复杂而且猫狗的特征太少了(也许是我打开方式不对)……于是我就缩减了模型,每个卷积层的filter减半,全连接层减为1024.
from keras.models import Sequential
from keras.layers import Dense,Activation,Conv2D,MaxPooling2D,Flatten,Dropout,BatchNormalization
from keras.datasets import mnist
from keras.utils import np_utils
from keras.optimizers import Adam
def AlexNet(input_shape=(224,224,3),output_shape=2):
# AlexNet
model = Sequential()
# 使用步长为4x4,大小为11的卷积核对图像进行卷积,输出的特征层为96层,输出的shape为(55,55,96);
# 所建模型后输出为48特征层
model.add(
Conv2D(
filters=48,
kernel_size=(11,11),
strides=(4,4),
padding='valid',
input_shape=input_shape,
activation='relu'
)
)
model.add(BatchNormalization())
# 使用步长为2的最大池化层进行池化,此时输出的shape为(27,27,96)
model.add(
MaxPooling2D(
pool_size=(3,3),
strides=(2,2),
padding='valid'
)
)
# 使用步长为1x1,大小为5的卷积核对图像进行卷积,输出的特征层为256层,输出的shape为(27,27,256);
# 所建模型后输出为128特征层
model.add(
Conv2D(
filters=128,
kernel_size=(5,5),
strides=(1,1),
padding='same',
activation='relu'
)
)
model.add(BatchNormalization())
# 使用步长为2的最大池化层进行池化,此时输出的shape为(13,13,256);
model.add(
MaxPooling2D(
pool_size=(3,3),
strides=(2,2),
padding='valid'
)
)
# 使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为384层,输出的shape为(13,13,384);
# 所建模型后输出为192特征层
model.add(
Conv2D(
filters=192,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu'
)
)
# 使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为384层,输出的shape为(13,13,384);
# 所建模型后输出为192特征层
model.add(
Conv2D(
filters=192,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu'
)
)
# 使用步长为1x1,大小为3的卷积核对图像进行卷积,输出的特征层为256层,输出的shape为(13,13,256);
# 所建模型后输出为128特征层
model.add(
Conv2D(
filters=128,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu'
)
)
# 使用步长为2的最大池化层进行池化,此时输出的shape为(6,6,256);
model.add(
MaxPooling2D(
pool_size=(3,3),
strides=(2,2),
padding='valid'
)
)
# 两个全连接层,最后输出为1000类,这里改为2类
# 缩减为1024
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(output_shape, activation='softmax'))
return model
开始训练
1、训练的主函数
训练的主函数主要包括如下部分:
1、读取训练用txt,并打乱,利用该txt进行训练集和测试集的划分。
2、建立AlexNet模型
3、设定模型保存的方式、学习率下降的方式、是否需要早停。
4、利用model.fit_generator训练模型。
具体代码如下:
if __name__ == "__main__":
# 模型保存的位置
log_dir = "./logs/"
# 打开数据集的txt
with open(r".\data\dataset.txt","r") as f:
lines = f.readlines()
# 打乱行,这个txt主要用于帮助读取数据来训练
# 打乱的数据更有利于训练
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
# 90%用于训练,10%用于估计。
num_val = int(len(lines)*0.1)
num_train = len(lines) - num_val
# 建立AlexNet模型
model = AlexNet()
# 保存的方式,3世代保存一次
checkpoint_period1 = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='acc',
save_weights_only=False,
save_best_only=True,
period=3
)
# 学习率下降的方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='acc',
factor=0.5,
patience=3,
verbose=1
)
# 是否需要早停,当val_loss一直不下降的时候意味着模型基本训练完毕,可以停止
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
# 交叉熵
model.compile(loss = 'categorical_crossentropy',
optimizer = Adam(lr=1e-3),
metrics = ['accuracy'])
# 一次的训练集大小
batch_size = 64
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
# 开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size),
validation_steps=max(1, num_val//batch_size),
epochs=150,
initial_epoch=0,
callbacks=[checkpoint_period1, reduce_lr])
model.save_weights(log_dir+'last1.h5')
model.fit_generator需要用到python的生成器来滚动读取数据,具体方法看第二步。
2、Keras数据生成器
Keras的数据生成器就是在一个while 1的无限循环中不断生成batch大小的数据集。
def generate_arrays_from_file(lines,batch_size):
# 获取总长度
n = len(lines)
i = 0
while 1:
X_train = []
Y_train = []
# 获取一个batch_size大小的数据
for b in range(batch_size):
if i==0:
np.random.shuffle(lines)
name = lines[i].split(';')[0]
# 从文件中读取图像
img = cv2.imread(r".\data\image\train" + '/' + name)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img = img/255
X_train.append(img)
Y_train.append(lines[i].split(';')[1])
# 读完一个周期后重新开始
i = (i+1) % n
# 处理图像
X_train = utils.resize_image(X_train,(224,224))
X_train = X_train.reshape(-1,224,224,3)
Y_train = np_utils.to_categorical(np.array(Y_train),num_classes= 2)
yield (X_train, Y_train)
在其中用到了一些处理函数,我存在了utils.py工具人文件中。
import matplotlib.image as mpimg
import numpy as np
import cv2
import tensorflow as tf
from tensorflow.python.ops import array_ops
def load_image(path):
# 读取图片,rgb
img = mpimg.imread(path)
# 将图片修剪成中心的正方形
short_edge = min(img.shape[:2])
yy = int((img.shape[0] - short_edge) / 2)
xx = int((img.shape[1] - short_edge) / 2)
crop_img = img[yy: yy + short_edge, xx: xx + short_edge]
return crop_img
def resize_image(image, size):
with tf.name_scope('resize_image'):
images = []
for i in image:
i = cv2.resize(i, size)
images.append(i)
images = np.array(images)
return images
def print_answer(argmax):
with open("./data/model/index_word.txt","r",encoding='utf-8') as f:
synset = [l.split(";")[1][:-1] for l in f.readlines()]
print(synset[argmax])
return synset[argmax]
3、主训练函数全部代码
大家可以整体看看哈:
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from keras.utils import np_utils
from keras.optimizers import Adam
from model.AlexNet import AlexNet
import numpy as np
import utils
import cv2
from keras import backend as K
K.set_image_dim_ordering('tf')
def generate_arrays_from_file(lines,batch_size):
# 获取总长度
n = len(lines)
i = 0
while 1:
X_train = []
Y_train = []
# 获取一个batch_size大小的数据
for b in range(batch_size):
if i==0:
np.random.shuffle(lines)
name = lines[i].split(';')[0]
# 从文件中读取图像
img = cv2.imread(r".\data\image\train" + '/' + name)
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img = img/255
X_train.append(img)
Y_train.append(lines[i].split(';')[1])
# 读完一个周期后重新开始
i = (i+1) % n
# 处理图像
X_train = utils.resize_image(X_train,(224,224))
X_train = X_train.reshape(-1,224,224,3)
Y_train = np_utils.to_categorical(np.array(Y_train),num_classes= 2)
yield (X_train, Y_train)
if __name__ == "__main__":
# 模型保存的位置
log_dir = "./logs/"
# 打开数据集的txt
with open(r".\data\dataset.txt","r") as f:
lines = f.readlines()
# 打乱行,这个txt主要用于帮助读取数据来训练
# 打乱的数据更有利于训练
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
# 90%用于训练,10%用于估计。
num_val = int(len(lines)*0.1)
num_train = len(lines) - num_val
# 建立AlexNet模型
model = AlexNet()
# 保存的方式,3世代保存一次
checkpoint_period1 = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='acc',
save_weights_only=False,
save_best_only=True,
period=3
)
# 学习率下降的方式,acc三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='acc',
factor=0.5,
patience=3,
verbose=1
)
# 是否需要早停,当val_loss一直不下降的时候意味着模型基本训练完毕,可以停止
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
# 交叉熵
model.compile(loss = 'categorical_crossentropy',
optimizer = Adam(lr=1e-3),
metrics = ['accuracy'])
# 一次的训练集大小
batch_size = 64
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
# 开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size),
validation_steps=max(1, num_val//batch_size),
epochs=150,
initial_epoch=0,
callbacks=[checkpoint_period1, reduce_lr, early_stopping ])
model.save_weights(log_dir+'last1.h5')
训练结果
在完成上述的一大堆内容的配置后就可以开始训练了,所有文件的构架如下:

……训练是真的慢
…… Epoch 36/50 175/175 [==============================] - 219s 1s/step - loss: 0.0124 - acc: 0.9962 - val_loss: 0.5256 - val_acc: 0.9034 Epoch 37/50 175/175 [==============================] - 178s 1s/step - loss: 0.0028 - acc: 0.9991 - val_loss: 0.7911 - val_acc: 0.9034 Epoch 38/50 175/175 [==============================] - 174s 992ms/step - loss: 0.0047 - acc: 0.9987 - val_loss: 0.6690 - val_acc: 0.8910 Epoch 39/50 175/175 [==============================] - 241s 1s/step - loss: 0.0044 - acc: 0.9986 - val_loss: 0.6518 - val_acc: 0.9001 Epoch 40/50 142/175 [=======================>......] - ETA: 1:07 - loss: 0.0074 - acc: 0.9976
差不多是这样,在测试集上有90的准确度呢!我们拿一个模型预测一下看看。
import numpy as np
import utils
import cv2
from keras import backend as K
from model.AlexNet import AlexNet
K.set_image_dim_ordering('tf')
if __name__ == "__main__":
model = AlexNet()
# 载入模型
model.load_weights("./logs/ep039-loss0.004-val_loss0.652.h5")
# 载入图片,并处理
img = cv2.imread("./Test.jpg")
img_RGB = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
img_nor = img_RGB/255
img_nor = np.expand_dims(img_nor,axis = 0)
img_resize = utils.resize_image(img_nor,(224,224))
# 预测~!
#utils.print_answer(np.argmax(model.predict(img)))
print(utils.print_answer(np.argmax(model.predict(img_resize))))
cv2.imshow("ooo",img)
cv2.waitKey(0)
预测结果为:
猫猫

大功告成。
以上就是python神经网络AlexNet分类模型训练猫狗数据集的详细内容,更多关于AlexNet分类模型训练猫狗数据集的资料请关注我们其它相关文章!
相关推荐
-
Tensorflow实现AlexNet卷积神经网络及运算时间评测
本文实例为大家分享了Tensorflow实现AlexNet卷积神经网络的具体实现代码,供大家参考,具体内容如下 之前已经介绍过了AlexNet的网络构建了,这次主要不是为了训练数据,而是为了对每个batch的前馈(Forward)和反馈(backward)的平均耗时进行计算.在设计网络的过程中,分类的结果很重要,但是运算速率也相当重要.尤其是在跟踪(Tracking)的任务中,如果使用的网络太深,那么也会导致实时性不好. from datetime import datetime import
-

TensorFlow卷积神经网络之使用训练好的模型识别猫狗图片
本文是Python通过TensorFlow卷积神经网络实现猫狗识别的姊妹篇,是加载上一篇训练好的模型,进行猫狗识别 本文逻辑: 我从网上下载了十几张猫和狗的图片,用于检验我们训练好的模型. 处理我们下载的图片 加载模型 将图片输入模型进行检验 代码如下: #coding=utf-8 import tensorflow as tf from PIL import Image import matplotlib.pyplot as plt import input_data import numpy
-
使用pytorch搭建AlexNet操作(微调预训练模型及手动搭建)
本文介绍了如何在pytorch下搭建AlexNet,使用了两种方法,一种是直接加载预训练模型,并根据自己的需要微调(将最后一层全连接层输出由1000改为10),另一种是手动搭建. 构建模型类的时候需要继承自torch.nn.Module类,要自己重写__ \_\___init__ \_\___方法和正向传递时的forward方法,这里我自己的理解是,搭建网络写在__ \_\___init__ \_\___中,每次正向传递需要计算的部分写在forward中,例如把矩阵压平之类的. 加载预训练ale
-
Python通过TensorFlow卷积神经网络实现猫狗识别
这份数据集来源于Kaggle,数据集有12500只猫和12500只狗.在这里简单介绍下整体思路 处理数据 设计神经网络 进行训练测试 1. 数据处理 将图片数据处理为 tf 能够识别的数据格式,并将数据设计批次. 第一步get_files() 方法读取图片,然后根据图片名,添加猫狗 label,然后再将 image和label 放到 数组中,打乱顺序返回 将第一步处理好的图片 和label 数组 转化为 tensorflow 能够识别的格式,然后将图片裁剪和补充进行标准化处理,分批次返回. 新建
-
Python编程pytorch深度卷积神经网络AlexNet详解
目录 容量控制和预处理 读取数据集 2012年,AlexNet横空出世.它首次证明了学习到的特征可以超越手工设计的特征.它一举打破了计算机视觉研究的现状.AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年的ImageNet图像识别挑战赛. 下图展示了从LeNet(左)到AlexNet(right)的架构. AlexNet和LeNet的设计理念非常相似,但也有如下区别: AlexNet比相对较小的LeNet5要深得多. AlexNet使用ReLU而不是sigmoid作为其激活函数
-
python神经网络AlexNet分类模型训练猫狗数据集
目录 什么是AlexNet模型 训练前准备 1.数据集处理 2.创建Keras的AlexNet模型 开始训练 1.训练的主函数 2.Keras数据生成器 3.主训练函数全部代码 训练结果 最近在做实验室的工作,要用到分类模型,老板一星期催20次,我也是无语了,上有对策下有政策,在下先找个猫猫狗狗的数据集练练手,快乐极了 什么是AlexNet模型 AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的.也是在那年之后,更多的更深的神经网络
-
Python机器学习之基于Pytorch实现猫狗分类
一.环境配置 安装Anaconda 具体安装过程,请点击本文 配置Pytorch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision 二.数据集的准备 1.数据集的下载 kaggle网站的数据集下载地址: https://www.kaggle.com/lizhensheng/-2000 2.
-
python神经网络slim常用函数训练保存模型
目录 学习前言 slim是什么 slim常用函数 1.slim = tf.contrib.slim 2.slim.create_global_step 3.slim.dataset.Dataset 4.slim.dataset_data_provider.DatasetDataProvider 5.slim.conv2d 6.slim.max_pool2d 7.slim.fully_connected 8.slim.learning.train 本次博文实现的目标 整体框架构建思路 1.整体框架
-
Python深度学习之简单实现猫狗图像分类
一.前言 本文使用的是 kaggle 猫狗大战的数据集 训练集中有 25000 张图像,测试集中有 12500 张图像.作为简单示例,我们用不了那么多图像,随便抽取一小部分猫狗图像到一个文件夹里即可. 通过使用更大.更复杂的模型,可以获得更高的准确率,预训练模型是一个很好的选择,我们可以直接使用预训练模型来完成分类任务,因为预训练模型通常已经在大型的数据集上进行过训练,通常用于完成大型的图像分类任务. tf.keras.applications中有一些预定义好的经典卷积神经网络结构(Applic
-
python之tensorflow手把手实例讲解猫狗识别实现
目录 一,猫狗数据集数目构成 二,数据导入 三,数据集构建 四,模型搭建 五,模型训练 六,模型测试 作为tensorflow初学的大三学生,本次课程作业的使用猫狗数据集做一个二分类模型. 一,猫狗数据集数目构成 train cats:1000 ,dogs:1000 test cats: 500,dogs:500 validation cats:500,dogs:500 二,数据导入 train_dir = 'Data/train' test_dir = 'Data/test' validati
-
Python人工智能深度学习模型训练经验总结
目录 一.假如训练集表现不好 1.尝试新的激活函数 2.自适应学习率 ①Adagrad ②RMSProp ③ Momentum ④Adam 二.在测试集上效果不好 1.提前停止 2.正则化 3.Dropout 一.假如训练集表现不好 1.尝试新的激活函数 ReLU:Rectified Linear Unit 图像如下图所示:当z<0时,a = 0, 当z>0时,a = z,也就是说这个激活函数是对输入进行线性转换.使用这个激活函数,由于有0的存在,计算之后会删除掉一些神经元,使得神经网络变窄.
-
python神经网络MobileNetV3 large模型的复现详解
目录 神经网络学习小记录38——MobileNetV3(large)模型的复现详解 学习前言什么是MobileNetV3代码下载MobileNetV3(large)的网络结构1.MobileNetV3(large)的整体结构2.MobileNetV3特有的bneck结构 网络实现代码 学习前言 为了防止某位我的粉丝寒假没有办法正常工作,我赶紧看了看MobilenetV3. 什么是MobileNetV3 最新的MobileNetV3的被写在了论文<Searching for MobileNetV3
-
python神经网络MobileNetV3 small模型的复现详解
目录 什么是MobileNetV3 large与small的区别 MobileNetV3(small)的网络结构 1.MobileNetV3(small)的整体结构 2.MobileNetV3特有的bneck结构 网络实现代码 什么是MobileNetV3 不知道咋地,就是突然想把small也一起写了. 最新的MobileNetV3的被写在了论文<Searching for MobileNetV3>中. 它是mobilnet的最新版,据说效果还是很好的. 作为一种轻量级网络,它的参数量还是一如
-
python神经网络Keras GhostNet模型的实现
目录 什么是GhostNet模型 GhostNet模型的实现思路 1.Ghost Module 2.Ghost Bottlenecks 3.Ghostnet的构建 GhostNet的代码构建 1.模型代码的构建 2.Yolov4上的应用 什么是GhostNet模型 GhostNet是华为诺亚方舟实验室提出来的一个非常有趣的网络,我们一起来学习一下. 2020年,华为新出了一个轻量级网络,命名为GhostNet. 在优秀CNN模型中,特征图存在冗余是非常重要的.如图所示,这个是对ResNet-50
-
python神经网络Inception ResnetV2模型复现详解
目录 什么是Inception ResnetV2 Inception-ResNetV2的网络结构 1.Stem的结构: 2.Inception-resnet-A的结构: 3.Inception-resnet-B的结构: 4.Inception-resnet-C的结构: 全部代码 什么是Inception ResnetV2 Inception ResnetV2是Inception ResnetV1的一个加强版,两者的结构差距不大,如果大家想了解Inception ResnetV1可以看一下我的另一