基于Python的身份证验证识别和数据处理详解
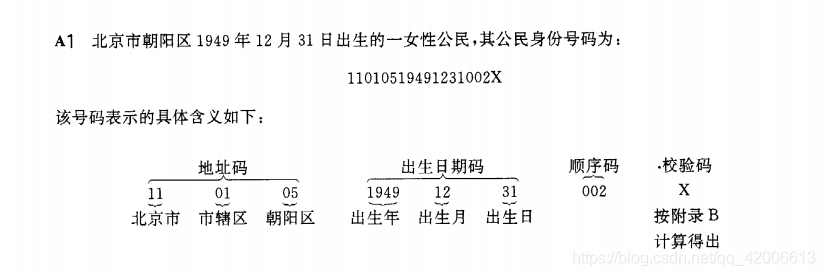
根据GB11643-1999公民身份证号码是特征组合码,由十七位数字本体码和一位数字校验码组成,排列顺序从左至右依次为:
六位数字地址码八位数字出生日期码三位数字顺序码一位数字校验码(数字10用罗马X表示)
校验系统:
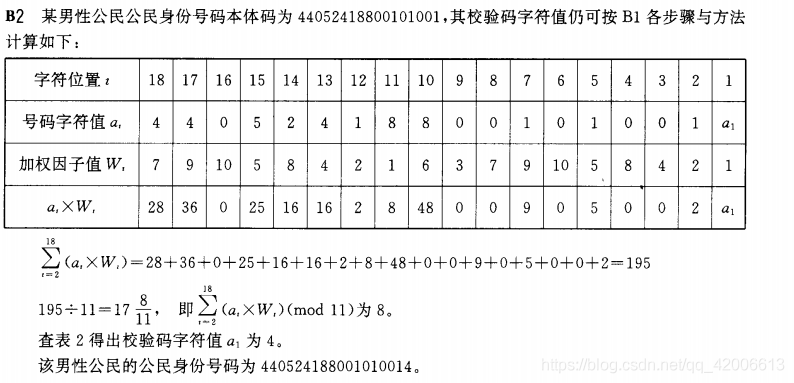
校验码采用ISO7064:1983,MOD11-2校验码系统(图为校验规则样例)
用身份证号的前17位的每一位号码字符值分别乘上对应的加权因子值,得到的结果求和后对11进行取余,最后的结果放到表2检验码字符值..换算关系表中得出最后的一位身份证号码

代码:
# coding=utf-8
# Copyright 2018 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert BERT checkpoint."""
import argparse
import torch
from transformers import BertConfig, BertForPreTraining, load_tf_weights_in_bert
from transformers.utils import logging
logging.set_verbosity_info()
def convert_tf_checkpoint_to_pytorch(tf_checkpoint_path, bert_config_file, pytorch_dump_path):
# Initialise PyTorch model
config = BertConfig.from_json_file(bert_config_file)
print("Building PyTorch model from configuration: {}".format(str(config)))
model = BertForPreTraining(config)
# Load weights from tf checkpoint
load_tf_weights_in_bert(model, config, tf_checkpoint_path)
# Save pytorch-model
print("Save PyTorch model to {}".format(pytorch_dump_path))
torch.save(model.state_dict(), pytorch_dump_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--tf_checkpoint_path", default=None, type=str, required=True, help="Path to the TensorFlow checkpoint path."
)
parser.add_argument(
"--bert_config_file",
default=None,
type=str,
required=True,
help="The config json file corresponding to the pre-trained BERT model. \n"
"This specifies the model architecture.",
)
parser.add_argument(
"--pytorch_dump_path", default=None, type=str, required=True, help="Path to the output PyTorch model."
)
args = parser.parse_args()
convert_tf_checkpoint_to_pytorch(args.tf_checkpoint_path, args.bert_config_file, args.pytorch_dump_path)
到此这篇关于基于Python的身份证验证识别和数据处理详解的文章就介绍到这了,更多相关python 身份验证识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-
对python .txt文件读取及数据处理方法总结
1.处理包含数据的文件 最近利用Python读取txt文件时遇到了一个小问题,就是在计算两个np.narray()类型的数组时,出现了以下错误: TypeError: ufunc 'subtract' did not contain a loop with signature matching types dtype('<U3') dtype('<U3') dtype('<U3') 作为一个Python新手,遇到这个问题后花费了挺多时间,在网上找了许多大神们写的例子,最后终于解决了. 总
-
python数据处理之如何选取csv文件中某几行的数据
前言 有些人看到这个问题觉得不是问题,是嘛,不就是df.col[]函数嘛,其实忽略了一个重点,那就是我们要省去把csv文件全部读取这个过程,因为如果在面临亿万级别的大规模数据,得到的结果就是boom,boom,boom. 我们要使用一下现成的函数里面的参数nrows,和skiprows,一个代表你要读几行,一个代表你从哪开始读,这就可以了,比如从第3行读取4个 示例代码 import pandas as pd df = pd.DataFrame({'a':[1,2,3,4,5,6,7,8,9],
-

Python 数据处理库 pandas 入门教程基本操作
pandas是一个Python语言的软件包,在我们使用Python语言进行机器学习编程的时候,这是一个非常常用的基础编程库.本文是对它的一个入门教程. pandas提供了快速,灵活和富有表现力的数据结构,目的是使"关系"或"标记"数据的工作既简单又直观.它旨在成为在Python中进行实际数据分析的高级构建块. 入门介绍 pandas适合于许多不同类型的数据,包括: 具有异构类型列的表格数据,例如SQL表格或Excel数据 有序和无序(不一定是固定频率)时间序列数据.
-
Python数据处理篇之Sympy系列(五)---解方程
前言 sympy不仅在符号运算方面强大,在解方程方面也是很强大. 本章节学习对应官网的:Solvers 官方教程 https://docs.sympy.org/latest/tutorial/solvers.html (一)求解多元一次方程-solve() 1.说明: 解多元一次方程可以使用solve(),在sympy里,等式是用Eq()来表示, 例如:2x=42x=4 表示为:Eq(x*2, 4) 2.源代码: """ 解下列二元一次方程 2x-y=3 3x+y=7 &qu
-
基于Python的身份证验证识别和数据处理详解
根据GB11643-1999公民身份证号码是特征组合码,由十七位数字本体码和一位数字校验码组成,排列顺序从左至右依次为: 六位数字地址码八位数字出生日期码三位数字顺序码一位数字校验码(数字10用罗马X表示) 校验系统: 校验码采用ISO7064:1983,MOD11-2校验码系统(图为校验规则样例) 用身份证号的前17位的每一位号码字符值分别乘上对应的加权因子值,得到的结果求和后对11进行取余,最后的结果放到表2检验码字符值..换算关系表中得出最后的一位身份证号码 代码: # coding=ut
-
Python基于keras训练实现微笑识别的示例详解
目录 一.数据预处理 二.训练模型 创建模型 训练模型 训练结果 三.预测 效果 四.源代码 pretreatment.py train.py predict.py 一.数据预处理 实验数据来自genki4k 提取含有完整人脸的图片 def init_file(): num = 0 bar = tqdm(os.listdir(read_path)) for file_name in bar: bar.desc = "预处理图片: "
-
基于python中staticmethod和classmethod的区别(详解)
例子 class A(object): def foo(self,x): print "executing foo(%s,%s)"%(self,x) @classmethod def class_foo(cls,x): print "executing class_foo(%s,%s)"%(cls,x) @staticmethod def static_foo(x): print "executing static_foo(%s)"%x a=A(
-
基于Python对象引用、可变性和垃圾回收详解
变量不是盒子 在示例所示的交互式控制台中,无法使用"变量是盒子"做解释.图说明了在 Python 中为什么不能使用盒子比喻,而便利贴则指出了变量的正确工作方式. 变量 a 和 b 引用同一个列表,而不是那个列表的副本 >>> a = [1, 2, 3] >>> b = a >>> a.append(4) >>> b [1, 2, 3, 4] 如果把变量想象为盒子,那么无法解释 Python 中的赋值:应该把变量视作
-
基于Python函数的作用域规则和闭包(详解)
作用域规则 命名空间是从名称到对象的映射,Python中主要是通过字典实现的,主要有以下几个命名空间: 内置命名空间,包含一些内置函数和内置异常的名称,在Python解释器启动时创建,一直保存到解释器退出.内置命名实际上存在于一个叫__builtins__的模块中,可以通过globals()['__builtins__'].__dict__查看其中的内置函数和内置异常. 全局命名空间,在读入函数所在的模块时创建,通常情况下,模块命名空间也会一直保存到解释器退出.可以通过内置函数globals()
-
基于Python中capitalize()与title()的区别详解
capitalize()与title()都可以实现字符串首字母大写. 主要区别在于: capitalize(): 字符串第一个字母大写 title(): 字符串内的所有单词的首字母大写 例如: >>> str='huang bi quan' >>> str.capitalize() 'Huang bi quan' #第一个字母大写 >>> str.title() 'Huang Bi Quan' #所有单词的首字母大写 非字母开头的情况: >>
-
Python用sndhdr模块识别音频格式详解
本文主要介绍了Python编程中,用sndhdr模块识别音频格式的相关内容,具体如下. sndhdr模块 功能描述:sndhdr模块提供检测音频类型的接口. 唯一一个API sndhdr模块提供了sndhdr.what(filename)和sndhdr.whathdr(filename)两个函数.但实际上它们的功能是一样的.(不知道多写一个的意义何在,what函数在内部调用了whathdr函数并把数据完完整整地返回) 在之前的版本,whathdr函数返回元组类型的数据,在Python3.5版本之
-
基于python内置函数与匿名函数详解
内置函数 Built-in Functions abs() dict() help() min() setattr() all() dir() hex() next() slice() any() divmod() id() object() sorted() ascii() enumerate() input() oct() staticmethod() bin() eval() int() open() str() bool() exec() isinstance() pow() super
-
基于python if 判断选择结构的实例详解
代码执行结构为顺序结构.选择结构.循环结构. python判断选择结构[if] if 判断条件 #进行判断条件满足之后执行下方语句 执行语句 elif 判断条件 #在不满足上面所有条件基础上进行条件筛选匹配之后执行下方语句 执行语句 else #再不满足上面所有的添加下执行下方语句 执行语句 下面举一个简单的例子,看兜里有多少钱来决定吃什么饭. douliqian=2 if douliqian>200: print("小龙虾走起!!0.0") elif douliqian>
-
基于Python中求和函数sum的用法详解
基于Python中求和函数sum的用法详解 今天在看<集体编程智慧>这本书的时候,看到一段Python代码,当时是百思不得其解,总觉得是书中排版出错了,后来去了解了一下sum的用法,看了一些Python大神写的代码后才发现是自己浅薄了!特在此记录一下.书中代码段摘录如下: from math import sqrt def sim_distance(prefs, person1, person2): # 得到shared_items的列表 si = {} for item in prefs[p