python反爬虫方法的优缺点分析
我们选择一种问题的解决办法,通常需要考虑到想要达到的效果,还有最重要的是这个办法本身的优缺点有哪些,与其他的方法对比哪一个更好。之前小编之前也教过大家在python应对反爬虫的方法,那么小伙伴们知道具体情况下选择哪一种办法更适合吗?今天就其中的user-agent和ip代码两个办法进行优缺点分析比较,让大家可以明确不同办法的区别从而进行选择。
方法一:
可以自己设置一下user-agent,或者更好的是,可以从一系列的user-agent里随机挑出一个符合标准的使用。
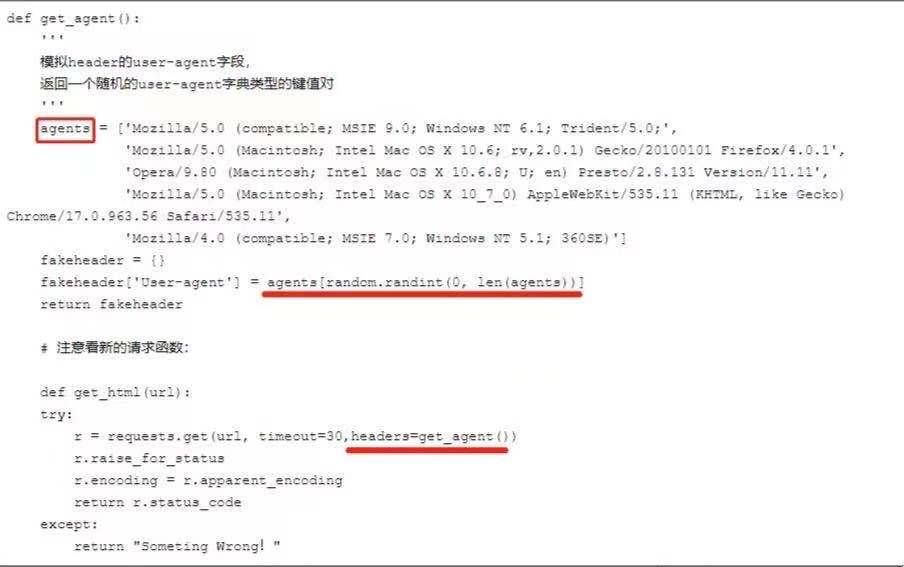 缺点:
缺点:
容易伪造头部,github上有人分享开源库fake-useragent
IP限制
如果一个固定的ip在短暂的时间内,快速大量的访问一个网站,后台管理员可以编写IP限制,不让该IP继续访问。
方法二:
比较成熟的方式是:IP代理池

简单的说,就是通过ip代理,从不同的ip进行访问,这样就不会被封掉ip了。
可是ip代理的获取本身就是一个很麻烦的事情,网上有免费和付费的,但是质量都层次不齐。如果是企业里需要的话,可以通过自己购买集群云服务来自建代理池。
缺点:
可以使用免费/付费代理,绕过检测。
读完本篇我们会发现,每种方法都有它的缺陷,我们要做的就是发挥使用它的优势出。根据不同的环境情况,可以选择适合自己操作顺手的方法。对于两种方法知识点遗忘的,可以直接点击进去进行回顾。
到此这篇关于python反爬虫方法的优缺点分析的文章就介绍到这了,更多相关python解决反爬虫方法的优缺点对比内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序 反爬虫:使用技术手段防止爬虫程序爬取数据 误伤:反爬虫技术将普通用户识别为爬虫,这种情况多出现在封ip中,例如学校网络.小区网络再或者网络网络都是共享一个公共ip,这个时候如果是封ip就会导致很多正常访问的用户也无法获取到数据.所以相对来说封ip的策略不是特别好,通常都是禁止某ip一段时间访问. 成本:反爬虫也是需要人力和机器成本 拦截:成功拦截爬虫,一般拦截
-
python中绕过反爬虫的方法总结
我们在登山的途中,有不同的路线可以到达终点.因为选择的路线不同,上山的难度也有区别.就像最近几天教大家获取数据的时候,断断续续的讲过header.地址ip等一些的方法.具体的爬取方法相信大家已经掌握住,本篇小编主要是给大家进行应对反爬虫方法的一个梳理,在进行方法回顾的同时查漏补缺,建立系统的爬虫知识框架. 首先分析要爬的网站,本质是一个信息查询系统,提供了搜索页面.例如我想获取某个case,需要利用这个case的id或者name字段,才能搜索到这个case的页面. 出于对安全的考虑,有些网站会做
-
cookies应对python反爬虫知识点详解
在保持合理的数据采集上,使用python爬虫也并不是一件坏事情,因为在信息的交流上加快了流通的频率.今天小编为大家带来了一个稍微复杂一点的应对反爬虫的方法,那就是我们自己构造cookies.在开始正式的构造之前,我们先进行简单的分析如果不构造cookies爬虫时会出现的一些情况,相信这样更能体会出cookies的作用. 网站需要cookies才能正常返回,但是该网站的cookies过期很快,我总不能用浏览器开发者工具获取cookies,然后让程序跑一会儿,每隔几分钟再手动获取cookies,再让
-
python 常见的反爬虫策略
1.判断请求头来进行反爬 这是很早期的网站进行的反爬方式 User-Agent 用户代理 referer 请求来自哪里 cookie 也可以用来做访问凭证 解决办法:请求头里面添加对应的参数(复制浏览器里面的数据) 2.根据用户行为来进行反爬 请求频率过高,服务器设置规定时间之内的请求阈值 解决办法:降低请求频率或者使用代理(IP代理) 网页中设置一些陷阱(正常用户访问不到但是爬虫可以访问到) 解决办法:分析网页,避开这些特殊陷阱 请求间隔太短,返回相同的数据 解决办法:增加请求间隔 3.js加
-
Python反爬虫伪装浏览器进行爬虫
对于爬虫中部分网站设置了请求次数过多后会封杀ip,现在模拟浏览器进行爬虫,也就是说让服务器认识到访问他的是真正的浏览器而不是机器操作 简单的直接添加请求头,将浏览器的信息在请求数据时传入: 打开浏览器--打开开发者模式--请求任意网站 如下图:找到请求的的名字,打开后查看headers栏,找到User-Agent,复制.然后添加到请求头中 代码如下: import requests url = 'https://www.baidu.com' headers ={ 'User-Agent':'Mo
-
Python常见反爬虫机制解决方案
1.使用代理 适用情况:限制IP地址情况,也可解决由于"频繁点击"而需要输入验证码登陆的情况. 这种情况最好的办法就是维护一个代理IP池,网上有很多免费的代理IP,良莠不齐,可以通过筛选找到能用的.对于"频繁点击"的情况,我们还可以通过限制爬虫访问网站的频率来避免被网站禁掉. proxies = {'http':'http://XX.XX.XX.XX:XXXX'} Requests: import requests response = requests.get(u
-
python反爬虫方法的优缺点分析
我们选择一种问题的解决办法,通常需要考虑到想要达到的效果,还有最重要的是这个办法本身的优缺点有哪些,与其他的方法对比哪一个更好.之前小编之前也教过大家在python应对反爬虫的方法,那么小伙伴们知道具体情况下选择哪一种办法更适合吗?今天就其中的user-agent和ip代码两个办法进行优缺点分析比较,让大家可以明确不同办法的区别从而进行选择. 方法一: 可以自己设置一下user-agent,或者更好的是,可以从一系列的user-agent里随机挑出一个符合标准的使用. 缺点: 容易伪造头部,gi
-

用sleep间隔进行python反爬虫的实例讲解
在找寻材料的时候,会看到一些暂时用不到但是内容不错的网页,就这样关闭未免浪费掉了,下次也不一定能再次搜索到.有些小伙伴会提出可以保存网页链接,但这种基本的做法并不能在网页打不开后还能看到内容.我们完全可以用爬虫获取这方面的数据,不过操作过程中会遇到一些阻拦,今天小编就教大家用sleep间隔进行python反爬虫,这样就可以得到我们想到的数据啦. 步骤 要利用headers拉动请求,模拟成浏览器去访问网站,跳过最简单的反爬虫机制. 获取网页内容,保存在一个字符串content中. 构造正则表达式,
-
Python反爬虫技术之防止IP地址被封杀的讲解
在使用爬虫爬取别的网站的数据的时候,如果爬取频次过快,或者因为一些别的原因,被对方网站识别出爬虫后,自己的IP地址就面临着被封杀的风险.一旦IP被封杀,那么爬虫就再也爬取不到数据了. 那么常见的更改爬虫IP的方法有哪些呢? 1,使用动态IP拨号器服务器. 动态IP拨号服务器的IP地址是可以动态修改的.其实动态IP拨号服务器并不是什么高大上的服务器,相反,属于配置很低的一种服务器.我们之所以使用动态IP拨号服务器,不是看中了它的计算能力,而是能够实现秒换IP. 动态IP拨号服务器有一个特点,就是每
-
python中zip()方法应用实例分析
本文实例分析了python中zip()方法的应用.分享给大家供大家参考,具体如下: 假设有一个集合set, 需要对set中的每个元素指定一个唯一的id,从而组建成一个dict结构. 这个场景可以演化成,两个list/set或者一个set与一个list如何创建成为一个字典,如: A = ["a", "b", "c", "d"] B = [1, 2, 3, 4] ? ==> C = {"a":1, &qu
-
IIS启用Gzip的方法与优缺点分析
现代的浏览器IE6和Firefox都支持客户端Gzip,也就是说,在服务器上的网页,传输之前,先使用Gzip压缩再传输给客户端,客户端接收之后由浏览器解压显示,这样虽然稍微占用了一些服务器和客户端的CPU,但是换来的是更高的带宽利用率.对于纯文本来讲,压缩率是相当可观的.如果每个用户节约50%的带宽,那么你租用来的那点带宽就可以服务多一倍的客户了. IIS6已经内建了Gzip压缩的支持,可惜,没有设置更好的管理界面.所以要打开这个选项,还要费些功夫. 首先,如果你需要压缩静态文件(HTML),需
-
实现图片预加载的三大方法及优缺点分析
预加载图片是提高用户体验的一个很好方法.图片预先加载到浏览器中,访问者便可顺利地在你的网站上冲浪,并享受到极快的加载速度.这对图片画廊及图片占据很大比例的网站来说十分有利,它保证了图片快速.无缝地发布,也可帮助用户在浏览你网站内容时获得更好的用户体验.本文将分享三个不同的预加载技术,来增强网站的性能与可用性. 方法一:用CSS和JavaScript实现预加载 实现预加载图片有很多方法,包括使用CSS.JavaScript及两者的各种组合.这些技术可根据不同设计场景设计出相应的解决方案,十分高效.
-
详解python 破解网站反爬虫的两种简单方法
最近在学爬虫时发现许多网站都有自己的反爬虫机制,这让我们没法直接对想要的数据进行爬取,于是了解这种反爬虫机制就会帮助我们找到解决方法. 常见的反爬虫机制有判别身份和IP限制两种,下面我们将一一来进行介绍. (一) 判别身份 首先我们看一个例子,看看到底什么时反爬虫. 我们还是以 豆瓣电影榜top250(https://movie.douban.com/top250) 为例.` import requests # 豆瓣电影榜top250的网址 url = 'https://movie.douban