Python爬虫实战项目掌握酷狗音乐的加密过程
1.前言
小编在这里讲一下,下面的内容仅供学习参考,切莫用于商业活动,一经被相关人员发现,本小编概不负责!读者切记切记。

2.获取音乐播放列表
其实,这就是小编要讲的重点,因为就是这部分用到了加密。
我们在搜索栏上输入我们想听的音乐,小编输入:刺客
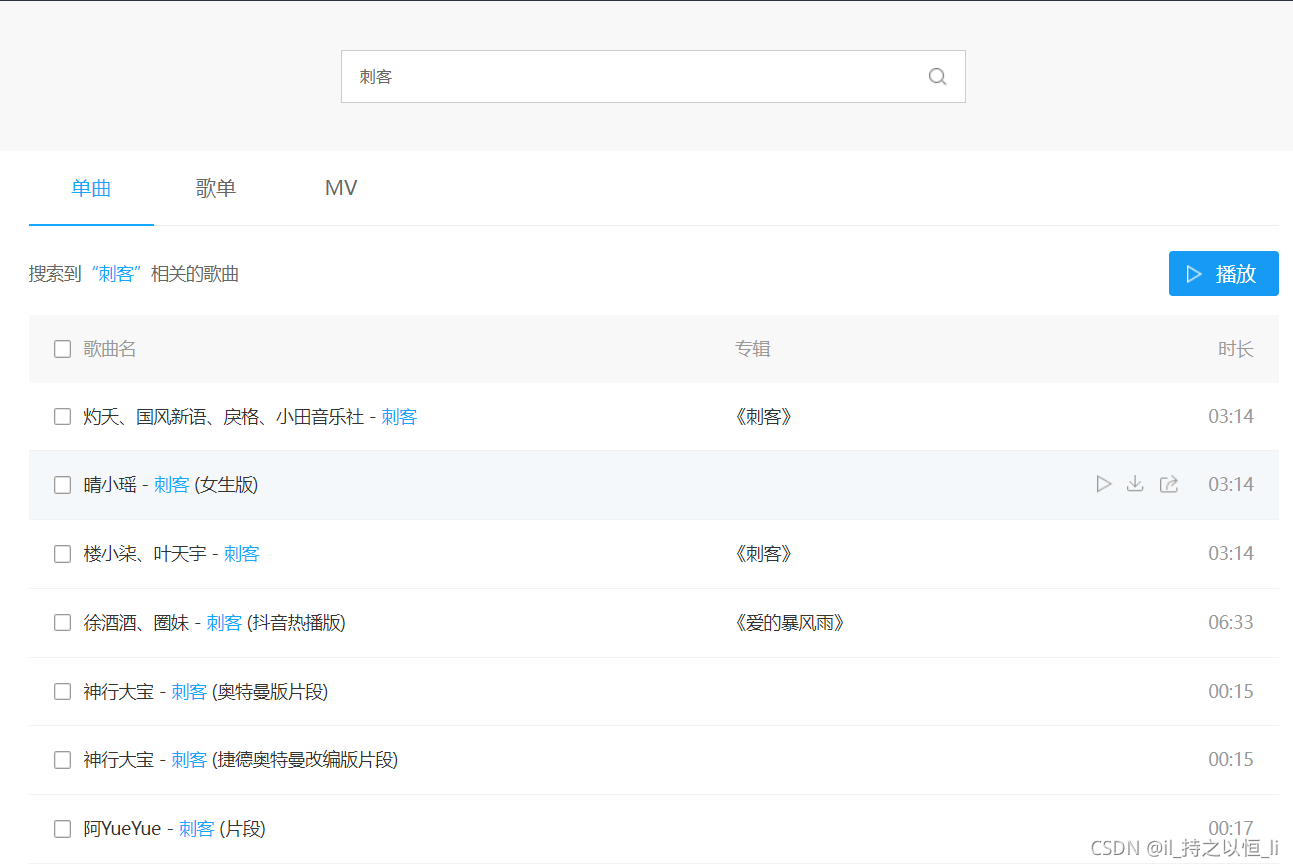
- 是不是看到了一系列音乐,怎样得到这些音乐的一些信息呢?(这里指的音乐信息是指音乐的hash值和音乐的album_id值【这两个参数在获取音乐的下载链接那里会用到】,当然还包括音乐的名称【不然怎么区别呢?】)。
- 由于这一系列音乐是动态加载出来的,也就是如果直接解析这个界面的数据,根本得不到,这个时候我们就应该来到如下这个界面了。
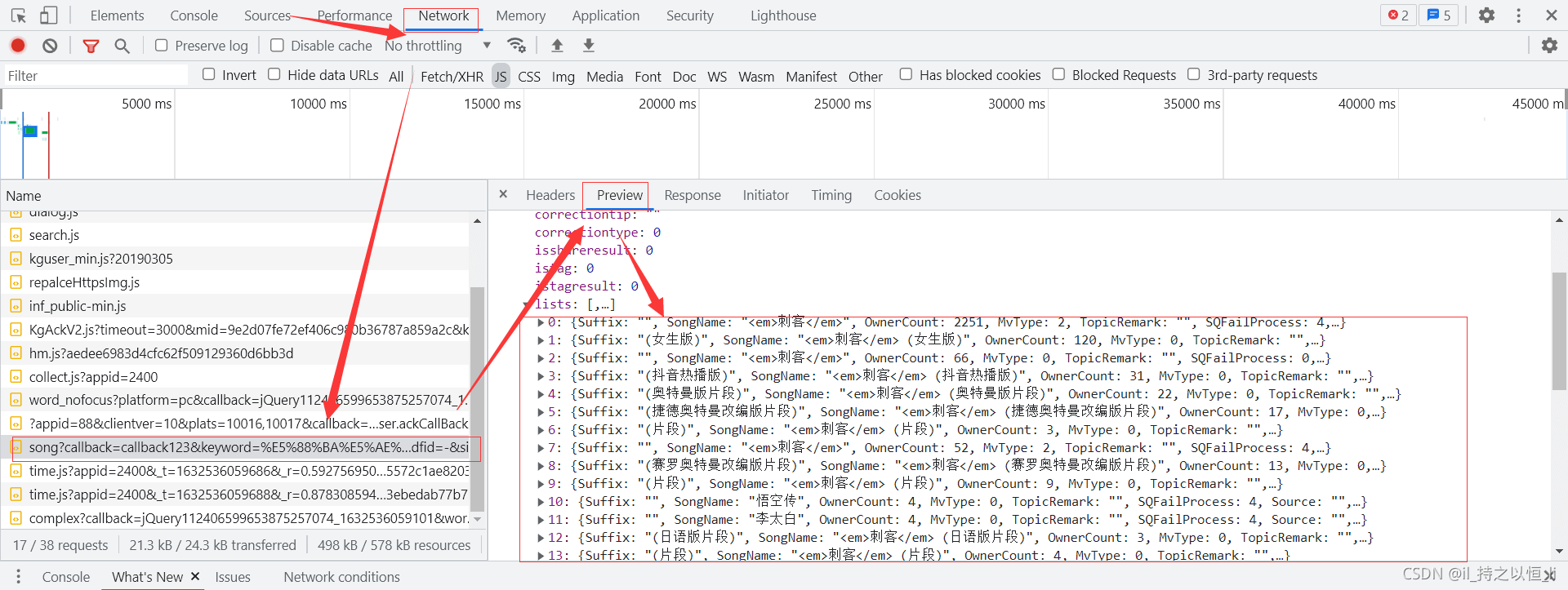
是不是可以看到我们刚才看到的那些音乐了,而且展开其中一首音乐,可以发现上述小编讲的哪些信息好像都有了呀!
我们看一下这个请求的网址吧!发现这是一个get请求,请求数据如下:

- 小编搜索了多首歌曲,发现它们的请求参数有一个共同点,那就是除了keyword、clienttime、mid、uuid和signature这几个参数值不同之外,其他的都差不多,而clienttime本意就是客户端时间,它的值是一个时间戳,mid和uuid的值和clienttime一样的,keyword它的值就是我们搜索的关键词,现在我们需要的就是搞懂signature这个参数值到底是什么呀!
- 小编得到这个signature参数值的长度为32,觉得应该是使用了加密,将一些初始数据,把它加密得到的,那么怎样得到这个初始数据呢?
- 小编点击了这个网站所有的js文件,发现这个参数值在这个js文件下
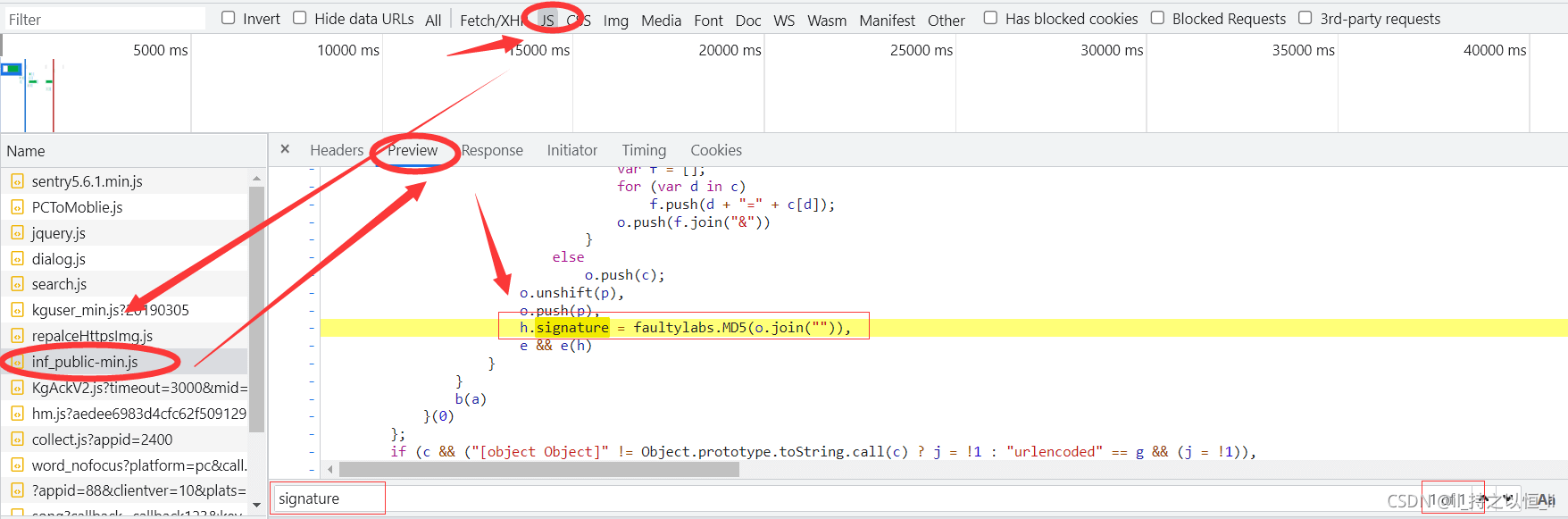
- 是不是看到了md5这个函数呀!这应该就是那个加密函数了吧!而o.join("")就应该是那个初始数据了,o是一个js数组。
- 现在知道要获取o的值,怎样获取呢?肯定是使用断点呀!我们在signature周围打上相应的断点,然后执行断点操作(这个小编就不一一赘述了,小编使用js断点还是有一点懵逼的,就不在这里误导大家了)。
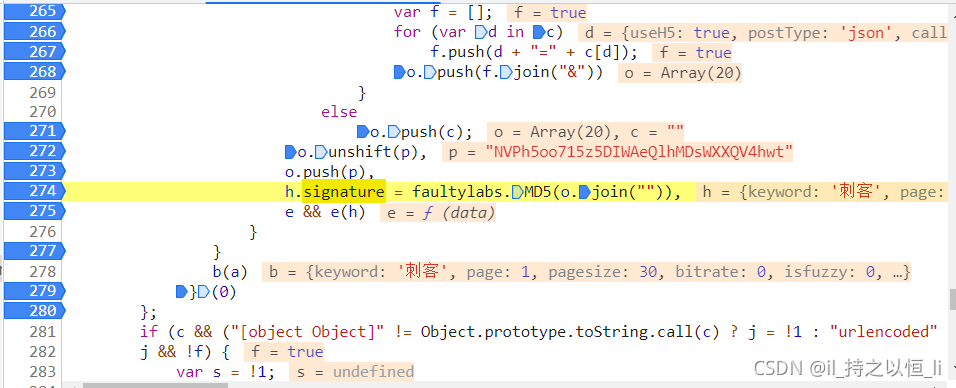

- 上述图片就是那个js数组o中的值了,经过对这些数据进行分析,发现其实这其中绝大部分值就是我们请求网址的哪些参数值,读者觉得呢?

- 整个加密算法如下:
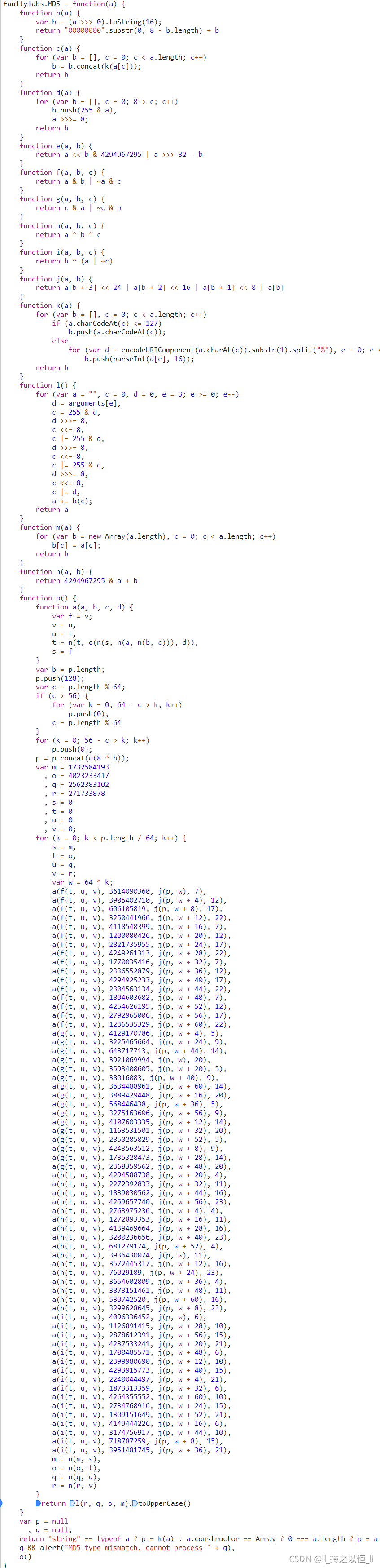
- 这也太长了吧!原本小编打断使用python来模拟这个加密过程,但是现在小编看到这么长,放弃了,但是并不代表加密过程就无法实现,小编查阅资料,发现原来python可以执行js语句,我们是不是只需结合python和js,就能实现这个加密了呢?开干!
- 代码如下:
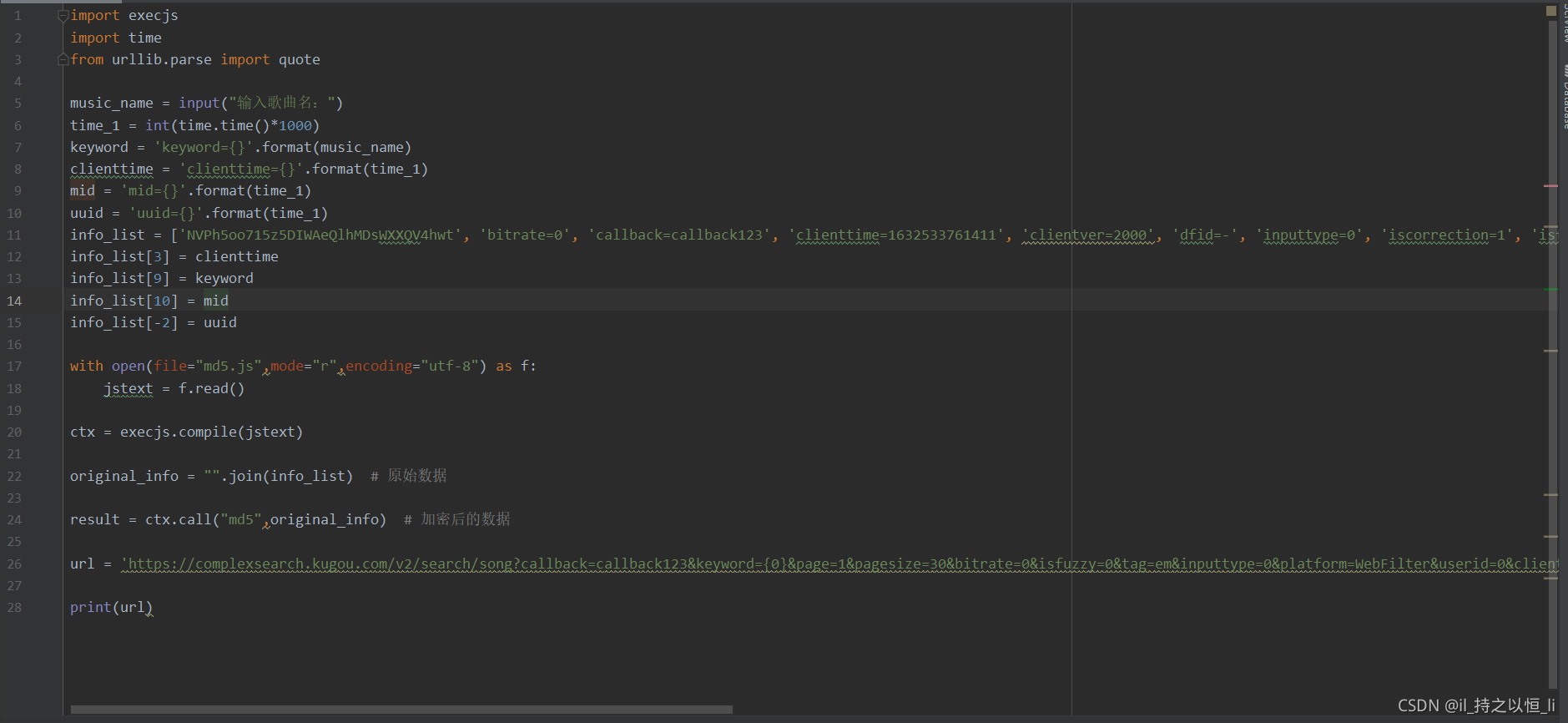
- 看看运行结果吧!

- 是不是这样就获取我们想要的数据了呀!我们只需使用json解析这些数据,就可以获取小编在上面提到的那两个参数了。【音乐的hash值和音乐的album_id值】
3. 得到歌曲的下载链接
- 在上述第二点那里讲到音乐的hash值和音乐album_id值,为什么要提到它们俩呢?当然是为了给第第三点这里做铺垫的哈!

- 这个过程小编不会讲的很详细,因为小编今天讲的重点是这个加密哈!
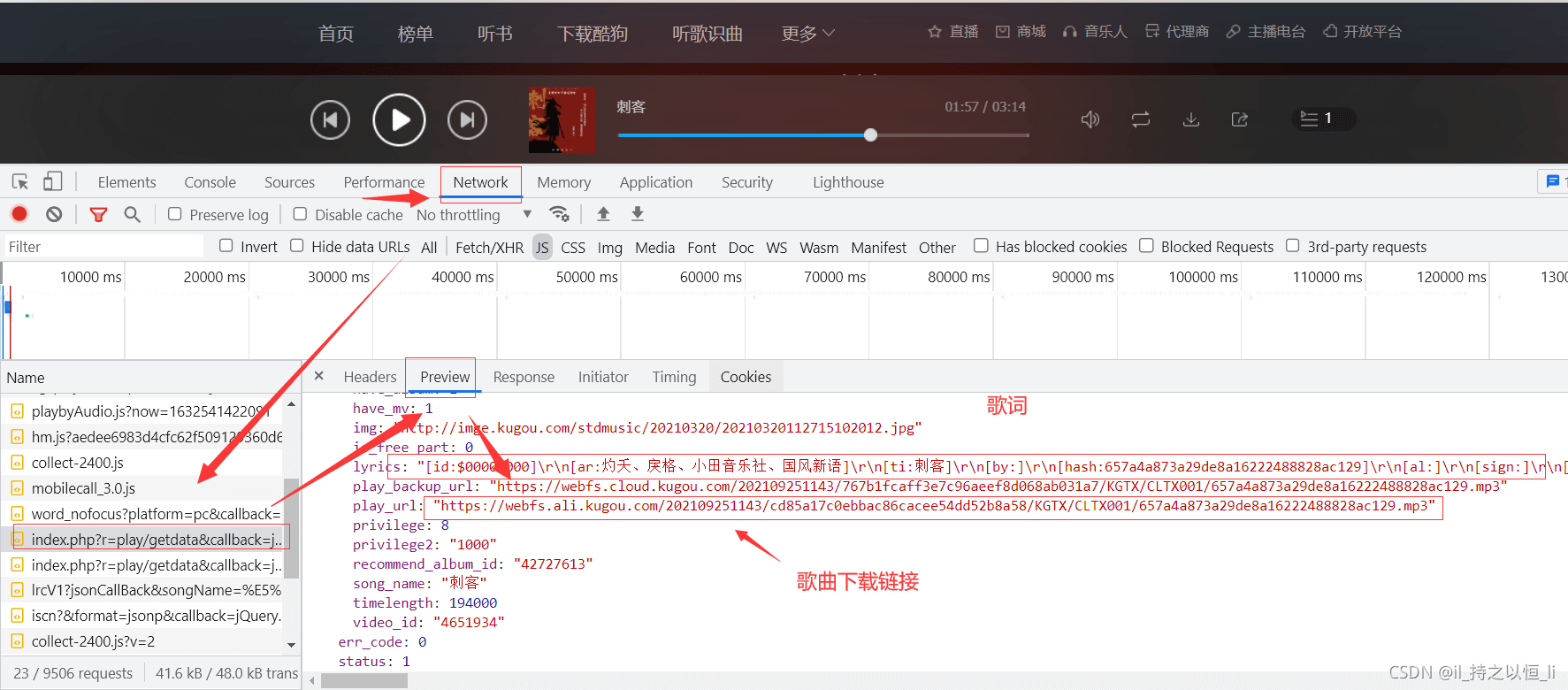
我们点击一首歌播放,来到上述界面,可以看到歌曲的下载链接,这个请求的参数如下:

- 这些请求参数中是不是看到我提到的那两个参数呀!
- 通过分析发现,其实只需以下三个参数即可请求成功!如下
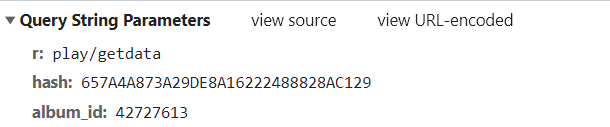
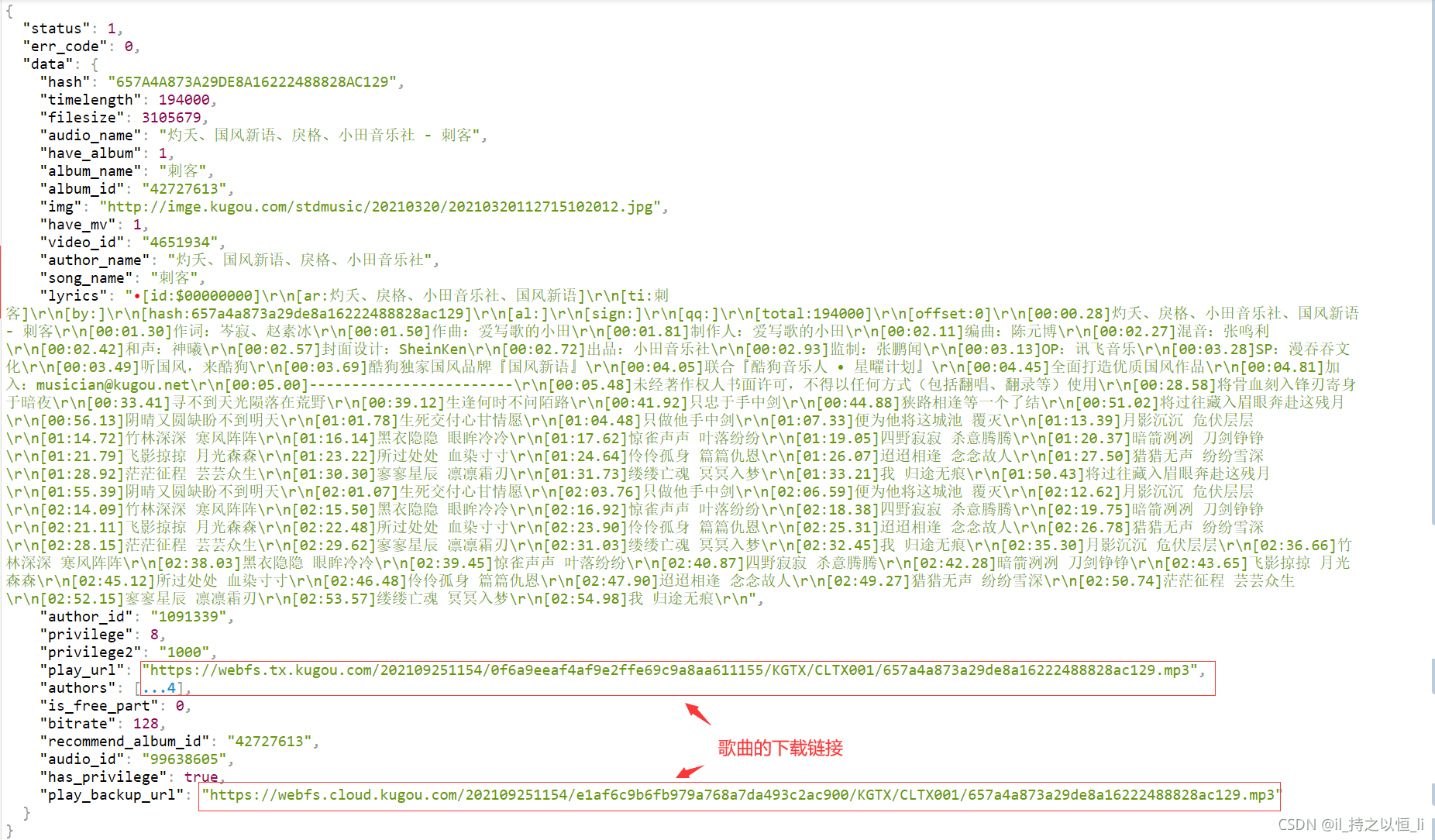
- 相应的代码小编就不一一发出来了,相信聪明的读者看了小编的本篇博客,定然可以实现酷狗音乐的下载
到此这篇关于Python爬虫实战项目掌握酷狗音乐的加密过程的文章就介绍到这了,更多相关Python 酷狗音乐的加密过程内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python使用beautifulsoup4爬取酷狗音乐代码实例
这篇文章主要介绍了python使用beautifulsoup4爬取酷狗音乐代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, 安装方法:pip install beautifulsoup4 完整代码如下:双击就能直接运行 from bs4 import BeautifulSoup
-

python获取酷狗音乐top500的下载地址 MP3格式
下面先给大家介绍下python获取酷狗音乐top500的下载地址 MP3格式,具体代码如下所示: # -*- coding: utf-8 -*- # @Time : 2018/4/16 # @File : kugou_top500.py # @Software: PyCharm # @pyVer : python 2.7 import requests,json headers={ 'UserAgent' : 'Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 lik
-
Python爬取酷狗MP3音频的步骤
分析问题 音频url 点入某个音乐的播放界面,通过F12-Network,分析数据,可以看到有一个index.php?..返回数据中有一个play_url,打开后正是我们需要的音频. 查看该url的headers,其params参数如下,通过反复不同的几次尝试,得知r.callback.dfid.mid.platid这几项不变,而通过初步的requests尝试,发现最后一项'_'可有可无,改变的只有hash和album_id两项. r: play/getdata callback: jQuery
-
python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下 #coding=utf-8 from pymongo import MongoClient import time import requests from lxml import etree client = MongoClient() #连接mongo hello = client.hello #连接数据库 user = hello.song #连接表 headers = { 'User-Agent': 'M
-
Python爬虫实战项目掌握酷狗音乐的加密过程
1.前言 小编在这里讲一下,下面的内容仅供学习参考,切莫用于商业活动,一经被相关人员发现,本小编概不负责!读者切记切记. 2.获取音乐播放列表 其实,这就是小编要讲的重点,因为就是这部分用到了加密. 我们在搜索栏上输入我们想听的音乐,小编输入:刺客 是不是看到了一系列音乐,怎样得到这些音乐的一些信息呢?(这里指的音乐信息是指音乐的hash值和音乐的album_id值[这两个参数在获取音乐的下载链接那里会用到],当然还包括音乐的名称[不然怎么区别呢?]). 由于这一系列音乐是动态加载出来的,也就是
-
Python反爬实战掌握酷狗音乐排行榜加密规则
目录 效果展示 爬取目标 工具使用 项目思路解析 简易源码分享 效果展示 爬取目标 网址:酷我音乐 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,re 项目思路解析 找到需要解析的榜单数据 随意点击一个歌曲获取到音乐的详情数据 通过抓包的方式获取到音乐播放数据 找到MP3的数据提交地址 mp3数据来自于这个url地址 提交数据的网址: https://wwwapi.kugou.com/yy/index.php?r=play/
-
python爬虫实战项目之爬取pixiv图片
自从接触python以后就想着爬pixiv,之前因为梯子有点问题就一直搁置,最近换了个梯子就迫不及待试了下. 爬虫无非request获取html页面然后用正则表达式或者beautifulsoup之类现成工具截取我们想要的页面,pixiv也不例外. 首先我们来实现模拟登陆,虽然大多数情况不需要我们实现模拟登录,但如果你是会员之类的,登录和不登录网页就有区别.思路是登录时抓包抓到post请求,看pixiv构建的post的数据表格是什么格式,我们根据这个格式构建form,然后调用post方法去请求,再
-
python爬取酷狗音乐Top500榜单
目录 网页情况 python 代码 运行效果 总结 网页情况 爬取数据包含 歌曲排名.歌手.歌曲名.歌曲时长 python 代码 import requests #请求网页获取网页数据 from bs4 import BeautifulSoup #解析网页数据 import time #时间库 #user-Agent,伪装成浏览器,便于爬虫的稳定性 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64;
-
Python爬虫实战之网易云音乐加密解析附源码
目录 环境 知识点 第一步 第二步 开始代码 先导入所需模块 请求数据 提取我们真正想要的 音乐的名称 id 导入js文件 保存文件 完整代码 环境 python3.8 pycharm2021.2 知识点 requests >>> pip install requests execjs >>> pip install PyExecJS 第一步 打开这个网站 在里面去分析我们需要的数据 每个音乐的名称 id 去网页源代码查找数据,发现并没有,这个网页 并不是一个静态页面
-
Python爬虫实战:分析《战狼2》豆瓣影评
刚接触python不久,做一个小项目来练练手.前几天看了<战狼2>,发现它在最新上映的电影里面是排行第一的,如下图所示.准备把豆瓣上对它的影评做一个分析. 目标总览 主要做了三件事: 抓取网页数据 清理数据 用词云进行展示 使用的python版本是3.5. 一.抓取网页数据 第一步要对网页进行访问,python中使用的是urllib库.代码如下: from urllib import request resp = request.urlopen('https://movie.douban.co
-
Vue 全家桶实现移动端酷狗音乐功能
Vue 已经用了不少时间,最近抽空把以前的未完成的酷狗音乐做完了,过来分享下,也可以直接点这里预览,注意切换成手机模式. 技术栈: vue-router.eventBus.vuex.vue-awesome-swiper 整体功能 vs 酷狗官网: 总体模拟官网,原来的亮点保留,如: 图片懒加载 除此之外,增加了 加了全局的 Loading 组件,根据不同页面调整 Loading 尺寸 搜索页面做了优化,可以在刷新时保留之前的搜索结果 播放页面单独做了一个路由,可以在刷新时保留当前歌曲页面 播放器