python中pandas输出完整、对齐的表格的方法
今天使用python计算数据相关性,但是发现计算出的表格中间好多省略号,而且也不对齐。
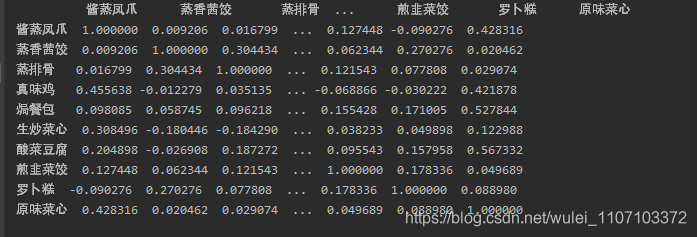
这也太难看了。
于是在程序里加了三行:
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
输出结果如下,输出结果已经全部显示了:
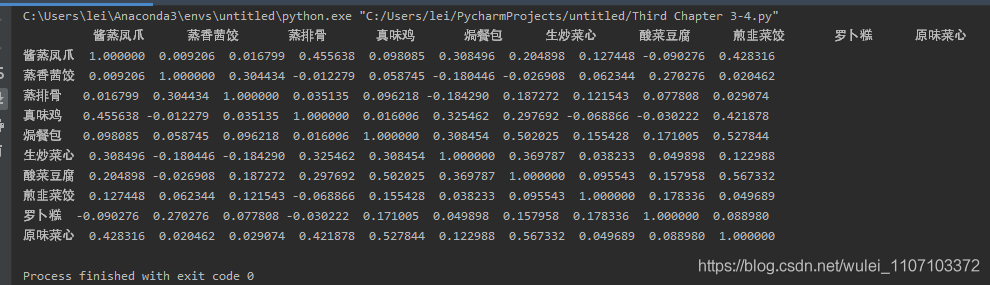
但是依然不对齐。
于是又加了两行:
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
运行结果对齐了,但仍然有瑕疵,不过已经好多了:
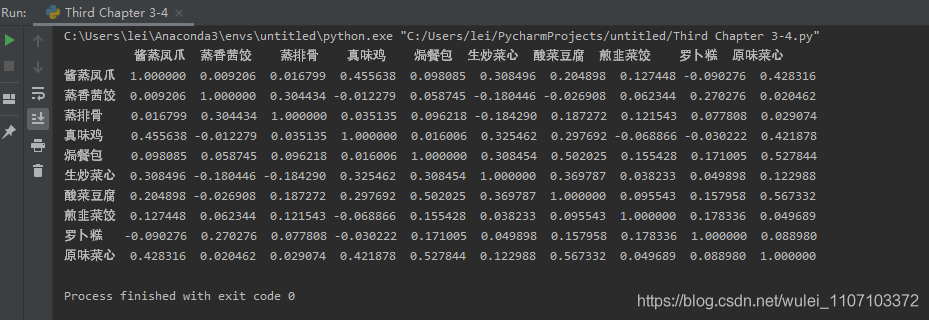
到此这篇关于python中pandas如何输出完整、对齐的表格的文章就介绍到这了,更多相关pandas输出完整、对齐的表格内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
解决Python pandas plot输出图形中显示中文乱码问题
解决方式一: import matplotlib #1. 获取matplotlibrc文件所在路径 matplotlib.matplotlib_fname() #Out[3]: u'd:\\Anaconda2\\lib\\site-packages\\matplotlib\\mpl-data\\matplotlibrc' #修改此配置文件,一劳永逸,不用在每个脚本中写代码解决中文显示问题 修改 'font.sans-serif' 的配置,在最前面加你本地电脑已有的字体family. 参看方式二.
-
浅析Python pandas模块输出每行中间省略号问题
关于Python数据分析中pandas模块在输出的时候,每行的中间会有省略号出现,和行与行中间的省略号....问题,其他的站点(百度)中的大部分都是瞎写,根本就是复制黏贴以前的版本,你要想知道其他问题答案就得去读官方文档吧. #!/usr/bin/python # -*- coding: UTF-8 -*- import numpy as np import pandas as pd import MySQLdb df = pd.read_csv('C:\\Users\\Administrato
-

python中pandas输出完整、对齐的表格的方法
今天使用python计算数据相关性,但是发现计算出的表格中间好多省略号,而且也不对齐. 这也太难看了. 于是在程序里加了三行: pd.set_option('display.max_columns', 1000) pd.set_option('display.width', 1000) pd.set_option('display.max_colwidth', 1000) 输出结果如下,输出结果已经全部显示了: 但是依然不对齐. 于是又加了两行: pd.set_option('display.u
-
在python中pandas读文件,有中文字符的方法
后面要加encoding='gbk' import pandas as pd datt=pd.read_csv('D:\python_prj_1\data_1.txt',encoding='gbk') print(datt) 以上这篇在python中pandas读文件,有中文字符的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python使用pandas按照行数分割表格
目录 问题 思路 代码实现 测试效果 问题 一张excel表格,大概1万行,需要录入系统 系统每次最多只能录入500行表格数据,一旦超过500行,就会录入失败 需要把1万行的数据按照500行分割,形成20个表格,这样才能录入系统 思路 使用pandas得到总行数,比如10002行,分割表格的时候,要保留一行表头 第一张表,是1-500行,第二张表是 501-1000,以此类推 最后一张表应该是1000-10002行,生成的表格数量是10000/500+1,21张 生成的表格按照顺序保存到一个目录
-
Python 中pandas索引切片读取数据缺失数据处理问题
引入 numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢? numpy能够帮我们处理处理数值型数据,但是这还不够 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等 比如:我们通过爬虫获取到了存储在数据库中的数据 比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等 所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我
-
python中pandas库中DataFrame对行和列的操作使用方法示例
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是S
-
python中pandas.read_csv()函数的深入讲解
这里将更新最新的最全面的read_csv()函数功能以及参数介绍,参考资料来源于官网. pandas库简介 官方网站里详细说明了pandas库的安装以及使用方法,在这里获取最新的pandas库信息,不过官网仅支持英文. pandas是一个Python包,并且它提供快速,灵活和富有表现力的数据结构.这样当我们处理"关系"或"标记"的数据(一维和二维数据结构)时既容易又直观. pandas是我们运用Python进行实际.真实数据分析的基础,同时它是建立在NumPy之上的
-
一文搞懂Python中pandas透视表pivot_table功能详解
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
一文搞懂Python中Pandas数据合并
目录 1.concat() 主要参数 示例 2.merge() 参数 示例 3.append() 参数 示例 4.join() 示例 数据合并是数据处理过程中的必经环节,pandas作为数据分析的利器,提供了四种常用的数据合并方式,让我们看看如何使用这些方法吧! 1.concat() concat() 可用于两个及多个 DataFrame 间行/列方向进行内联或外联拼接操作,默认对行(沿 y 轴)取并集. 使用方式 pd.concat( objs: Union[Iterable[~FrameOr
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf
-
一文搞懂Python中pandas透视表pivot_table功能
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用